







input_ids仅包含input
问题描述
input_ids = tokenizer.encode(input) 
适用场景
这种方法适用于那些只需要模型理解输入内容并预测输出的任务,如文本分类、情感分析等。在这些任务中,模型的目标是基于输入文本来预测一个标签或类别,而不是生成与输入文本相关的输出文本。
input_ids包含input和output
问题描述
input_ids = tokenizer.encode(input+output) 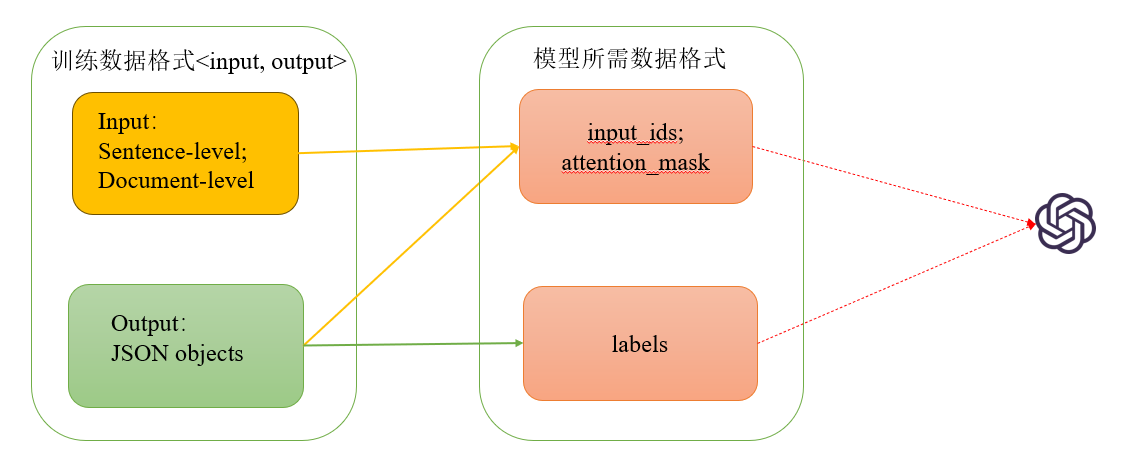
适用场景
这种方法适用于序列到序列的任务,如机器翻译、文本摘要、问答系统等。在这些任务中,模型需要根据输入文本生成相应的输出文本,因此
input_ids需要包含完整的输入和输出序列,以便模型可以学习如何从输入映射到输出。
hugging face 代码示例
1. tokenizer分别处理input_ids、attention_mask、labels
数据格式:
{"input": "我爱中华", "output": "是的"}
{"input": "明天会更好", "output": "没错"}
{"input": "天气不错", "output": "阳光明媚"}
测试代码(只供理解,不为真实代码)
from transformers import (
LlamaForCausalLM,
LlamaTokenizer,
LlamaConfig,
default_data_collator,
)
tokenizer = LlamaTokenizer.from_pretrained(train_config.model_name)
# 逐行读取 JSONL 文件
with open(data_path, 'r', encoding='utf-8') as f:
data = [json.loads(line.strip()) for line in f]
max_words = 1024
for item in data:
input_text = item['input']
output_text = item['output']
# input部分单独编码
input = torch.tensor(self.tokenizer.encode(input_text), dtype=torch.int64)
print("input torch.tensor: ", input)
print("input shape: ", input.shape)
print("input shape[0]: ", input.shape[0])
# input_ids: input、output拼接编码
combined_text = input_text + output_text
example = self.tokenizer.encode(combined_text)
example.append(self.tokenizer.eos_token_id) # 结束标记
print("example encode: ", example)
example = torch.tensor(example, dtype=torch.int64)
print("example torch.tensor: ", example)
print("example shape: ", example.shape)
print("example shape[0]: ", example.shape[0])
print("\n")
# 统一长度
padding = self.max_length - example.shape[0]
print('padding: ', padding)
if padding > 0:
example = torch.cat((example, torch.zeros(padding, dtype=torch.int64) - 1)) # 不足补-1
elif padding < 0:
example = example[: self.max_words] # 超出截断
print("after padding, example torch.tensor: ", example)
print("after padding, example shape: ", example.shape)
print("after padding, example shape[0]: ", example.shape[0])
# labels: 复制input_ids,input部分改为-1,output部分不变
labels = copy.deepcopy(example)
print("labels = copy.deepcopy(example): ", labels)
labels[: len(input)] = -1
print("labels tensor: ", labels)
print("\n")
# 将labels中为-1的置为-100
label_mask = labels.ge(0)
labels[~label_mask] = -100
print("final labels tensor: ", labels)
# attention_mask:
example_mask = example.ge(0) # ge(0): PyTorch 操作,表示 greater than or equal to 0(大于等于0), 如果值大于等于 0,结果是 True。 example_mask = tensor([True, True, False, False]),True 和 False 的值分别是 1 和 0
print("example_mask ge(0): ", example_mask)
example[~example_mask] = 0 # ~example_mask: 按位取反运算。 example_mask = tensor([True, True, 0, 0])=[1, 1, 0, 0]
print("example[~example_mask]: ", example)
example_mask = example_mask.float()
print("example_mask: ", example_mask)
print("\n")
tokenized_ids = {
"input_ids": example,
"labels": labels,
"attention_mask": example_mask,
}
# 只供理解,不为真实代码
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_ids,
)
理解输出(input_ids、labels、attention_mask)
dataset count: 3
input torch.tensor: tensor([ 101, 1855, 100, 1746, 100, 102])
input shape: torch.Size([6])
input shape[0]: 6
example encode: [101, 1855, 100, 1746, 100, 100, 1916, 102]
example torch.tensor: tensor([ 101, 1855, 100, 1746, 100, 100, 1916, 102])
example shape: torch.Size([8])
example shape[0]: 8
padding: 8
after padding, example torch.tensor: tensor([ 101, 1855, 100, 1746, 100, 100, 1916, 102, -1, -1, -1, -1,
-1, -1, -1, -1])
after padding, example shape: torch.Size([16])
after padding, example shape[0]: 16
labels = copy.deepcopy(example): tensor([ 101, 1855, 100, 1746, 100, 100, 1916, 102, -1, -1, -1, -1,
-1, -1, -1, -1])
labels tensor: tensor([ -1, -1, -1, -1, -1, -1, 1916, 102, -1, -1, -1, -1,
-1, -1, -1, -1])
final labels tensor: tensor([ -100, -100, -100, -100, -100, -100, 1916, 102, -100, -100, -100, -100,
-100, -100, -100, -100])
example_mask ge(0): tensor([ True, True, True, True, True, True, True, True, False, False,
False, False, False, False, False, False])
example[~example_mask]: tensor([ 101, 1855, 100, 1746, 100, 100, 1916, 102, 0, 0, 0, 0,
0, 0, 0, 0])
example_mask: tensor([1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0.])
2. 自定义处理函数FineTuneDataset():tokenizer一次性处理input_ids、attention_mask、labels
import copy
import json
import torch
from torch.utils.data import Dataset
from transformers import BertTokenizer
class FineTuneDataset(Dataset):
def __init__(self, dataset_config, tokenizer, max_words=1024):
with open(data_path, 'r', encoding='utf-8') as f:
self.data = [json.loads(line.strip()) for line in f]
self.max_words = max_words
self.tokenizer = tokenizer
def __len__(self):
return len(self.data)
def __getitem__(self, index):
IGNORE_INDEX = -100 # The default setting in CrossEntropyLoss
item = self.data[index]
prompt = item['input']
# example = input+ output
example = prompt + item["output"]
# print(example)
prompt = torch.tensor(self.tokenizer.encode(prompt), dtype=torch.int64)
# example = input_ids + output_ids
example = self.tokenizer.encode(example) # input+output
# print(example)
# example = input_ids + output_ids + <eos>
# example.append(self.tokenizer.eos_token_id)
example = torch.tensor(example, dtype=torch.int64)
padding = self.max_words - example.shape[0]
# 用 -1 填充
if padding > 0:
example = torch.cat((example, torch.zeros(padding, dtype=torch.int64) - 1))
# 截断
elif padding < 0:
example = example[: self.max_words]
# labels = example
labels = copy.deepcopy(example)
# labels = input(-1) + output
# 复制 example,并将 example 中与 prompt 对应的部分设置为 -1。这样,模型在训练时只会关注 output 部分作为标签,而忽略掉输入部分。
labels[: len(prompt)] = -1
# 创建一个 mask,用于标记 example 中不为 -1(即有效)的部分。
example_mask = example.ge(0)
# 创建一个 mask,用于标记 labels 中不为 IGNORE_INDEX(即有效)的部分。
label_mask = labels.ge(0)
# 将无效的部分(填充部分)置为 0,这样它们不会对损失计算产生影响。
example[~example_mask] = 0
labels[~label_mask] = IGNORE_INDEX
example_mask = example_mask.float()
label_mask = label_mask.float()
return {
"input_ids": example, # example = input_ids + output_ids + <eos>
"labels": labels, # labels = input(-1) + output,输入部分被替换为 -1,只保留 output 部分作为目标标签。
"attention_mask": example_mask, # 返回一个 mask,指示哪些位置是有效的(即不是填充部分)。
}
# 示例使用
if __name__ == '__main__':
BERT_PATH = "./model/bert_base_uncased"
tokenizer = BertTokenizer.from_pretrained(BERT_PATH)
# 数据路径
data_path = './train.jsonl' # JSON 格式数据路径,包含 'input' 和 'output'
# 创建数据集
dataset = FineTuneDataset(data_path, tokenizer, max_words=16)
print('dataset count: ', len(dataset))
# 数据示例
for data in dataset:
print("Input IDs:", data['input_ids'])
print("Attention Mask:", data['attention_mask'])
print("Labels:", data['labels'])
3. tokenizer自动一次性处理input_ids、attention_mask、labels
attention_mask、input_ids和labels长度一样。
import json
from transformers import AutoModelForCausalLM, AutoTokenizer
# 加载 LLaMA 模型和分词器
model_name = "meta-llama/Llama-2-7b-hf" # 替换为适合的模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_8bit=True)
# 加载 JSONL 数据
dataset = load_dataset("json", data_files="path_to_your_file.jsonl")
# 数据预处理函数,tokenizer() 自动生成每条数据的input_ids、labels、attention_mask
def tokenizer_function(examples):
return tokenizer(
examples["input"]+examples["output"],
padding="max_length",
truncation=True,
max_length=1024,
)
# train_dataset[input_ids、labels、attention_mask]
train_dataset = dataset.map(tokenizer_function, batched=True, remove_columns=["input", "output"])
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
data_collator=DataCollatorForSeq2Seq(tokenizer, padding=True), # 数据批处理器
)DataCollatorForSeq2Seq 是 Hugging Face transformers 库中提供的一个数据整理工具,专门为序列到序列(Seq2Seq)任务设计的。它的主要作用是动态地对输入和输出数据进行填充,并生成适合训练的 input_ids、labels 和 attention_mask。
Trainer中的train_dataset已经是经过token化了,为什么还需要data_collator来生成input_ids、labels 和 attention_mask。
为什么需要 data_collator
-
动态批处理:
虽然train_dataset已经包含了input_ids、labels和attention_mask,但这些是按样本粒度存储的,Trainer需要以批次为单位将这些样本拼接成张量。如果不使用data_collator,则必须手动编写批处理逻辑。 -
动态填充:
即使在tokenizer_function中指定了padding="max_length",但通常不推荐对所有样本统一填充到max_length,因为这会浪费内存和计算资源。- 使用
data_collator可以根据每个批次中最长样本的长度动态调整填充长度。 - 在大规模训练中,动态填充可以显著减少填充引入的计算开销。
- 使用
-
目标序列(
labels)的处理:
特别是在因果语言模型(如 LLaMA)中,labels可能需要额外的填充值(如-100)来避免填充值的部分参与损失计算。- 如果
tokenizer_function没有处理好填充值(label_pad_token_id),data_collator可以为目标序列动态填充正确的值。
- 如果
-
简化批处理代码:
data_collator提供了现成的功能,无需手动编写批处理逻辑。这使得代码更加简洁和易于维护。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









