










摘 要
基于深度学习在图像分类领域的优异性能,本文研究基于图像识别技术的辛普森角色自动识别方法。首先采集18个角色的16503幅辛普森角色图像数据集,然后在CNN模型框架下,修改最顶端的全连接层与分类输出层组成卷积网络主体结构,并采用数据增强和Dropout技术防止过拟合。实验结果验证了卷积神经网络在辛普森角色品种图像识别任务上具有优越性能,在测试集上的卷积神经网络识别准确率达到96%。
关键词 图像识别;辛普森角色;卷积神经网络;特征学习;
引言
《辛普森一家》是由马特·格勒宁创作,经美国福克斯广播公司出品的一部家庭动画情景喜剧片。该剧通过展现霍默、玛姬、巴特、丽莎和麦琪一家五口的生活,从多个角度对美国文化及人们的生活方式进行幽默地讽刺,其深刻的社会意义和风趣的表现方式吸引了大批剧迷。除主角一家五口之外,在已播出的34季的故事中,该剧一共出现了近百个角色。基于剧中角色构建一个人物识别的神经网络确是一项有趣且典型的计算机视觉项目。
此前,有一位忠实粉丝Alexandre Attia首先提出该项目并且已经花时间对每个人物的多张照片进行手动标注,目前已经形成了第一版数据集于Kaggle平台并持续更新。
随着深度学习在感知数据建模上的优异表现,以卷积神经网络为代表的图像分类方法逐渐成为计算机视觉领域的主流方法之一。针对《辛普森一家人》的角色识别问题,从辛普森剧集视频中逐帧截取并分析图片,采集到20个角色且每个角色拥有400~2000张图片,以TensorFlow作为后端,使用Keras训练构建卷积神经网络,逐层学习人物特征来识别角色。
出于对该剧集的喜爱和对本学期《人工智能导论》课程的学习总结,本文基于Kaggle平台已有数据集,实现对《辛普森一家》20类人物角色的识别。特此说明,由于所学知识的浅薄和能力的欠缺,本文仅是对于Alexandre Attia工作的复现与整合。主要工作有:
(1) 在《辛普森一家人》视频中逐帧分析并采集16503幅图片,并对20类角色进行人工标注,建立分布广泛的辛普森角色图像数据集。
(2) 实验分析了卷积神经网络方法在辛普森人物识别上的准确率,并对卷积神经网络的泛化性能进行了实验分析。
1 数据预处理
辛普森角色图像采集与人工标记是建立辛普森人物角色识别模型的基础。本节主要介绍辛普森人物角色图像数据集的构建过程。
1.1 数据采集
辛普森一家数据集主要从《辛普森一家》第4至第24季节中提取,包含20个角色,具体信息如表1所示,每个角色包括大约1000张图像,角色可能不是在每张图像都居中的,有时也会与其他角色在一起,但还是图像中最重要的部分。
表1 不同角色图像个数


图1. 20个角色实例图像
1.2 数据增强
为了提高卷积神经网络模型的泛化能力,对每幅角色图像通过旋转、平移、扭曲、缩放、翻转等传统数字图像处理方法进行随机变换以扩充样本个数。通过随机变换生成的角色图像大量扩充了数据集,使样本分布更广泛。
2 神经网络模型
2.1 网络结构
本文采用具有ReLU激活的前馈4个卷积层。如图2所示。然后是一个完全连接的隐藏层的网络构建《辛普森一家》角色识别模型,使用dropout层来正则化并避免过度拟合,输出层使用softmax激活来输出每个类的概率。
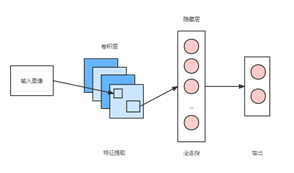
图2 模型整体结构图
2.2 损失函数
辛普森角色识别属于多分类任务,本文选用交叉熵函数作为模型的损失函数,用于评估卷积神经网络预测输出的类别概率分布与真实分布之间的差异,交叉熵损失函数对于不均衡的样本对网络的准确率的消极影响具有较好的抑制作用。
3 实验
为了验证本文建立的卷积神经网络模型的有效性,在展开实验时,除基本模型训练外,还对其进行改进与优化。
3.1 基本模型训练
在本次实验训练中,将迭代200个epoch的训练集批次,每个批处理大小为32。由于数据集规模限制,采用数据增强对图片进行一些随机变化,确保模型不会有相同图片重复出现的问题。这样也更好地防止过拟合,帮助模型实现更优地泛化。
实验编程开发环境为Python3.8.8, 计算设备为个人计算机,CPU为Intel i5-9300H,主频为2.40GHz,内存为16GB,显卡为GTX 1650,显存为8GB。训练数据和测试数据的划分比例为9:1。
3.2 实验结果与算法改进
3.2.1 基本训练结果
通过sklearn输出分类结果如图xx
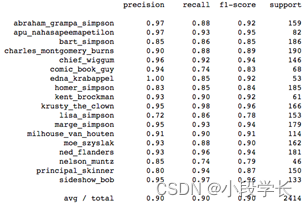
图3-1 四层卷积网

图3-2 准确度可视化
如图所示,每个角色的准确率都在90%以上。但其中丽萨的精度是82%。根据猜测和推理,由于丽萨经常和巴特总是同时出现,因此丽萨的图片中常会有巴特的身影,导致影响结果的精准度。
3.2.2 增加阈值
为提高精确度,通过增加一个阈值来适当降低召回率。
首先对丽萨和巴特两个角色的数据集分别计算最大概率预测、最佳候选对象和标准结果之间的概率差,即正确预测和错误预测结果。
同时,为避免出现预测角色的概率过低、预测的标准差太高或者两个最可能的角色之间的概率差太低的情况,我们对测试集绘制以上三个值,以找到一条线或超平面来区分正确和错误的预测结果。同样对两个角色都进行相同工作,如图所示。

图3-3正误预测及分割超平面
如图上图所示,在正确和错误的预测之间不可能找到完全的线性分离超平面,并且不可能找到一个简单的阈值。当然,我们可以看到每张图片的左下角部分,正确预测的概率很大,因此我们可以在这部分选取一个阈值。为了提高准确度且对召回率影响较小,可以对每个角色或者低精度的角色(如丽萨)绘制如上图表。同样,对数据集中任何一类角色都适用。
通常,召回率和精确度无法同时达到最佳,需要根据不同结果有不同侧重面。对于预测类的最小概率,我们可以绘制F1score和召回率、精确度。由于我们关注角色丽萨,那么我们为该类预测添加概率最小值,但这个个性化的阈值并非适用于大众。因此我们的结论是,可以为预测类的概率最小值添加一个大约0.2~0.4的阈值。
3.2.3 改进CNN模型
上述实验我们构建了一个四卷积层模型,为了使神经网络学习更多的细节和复杂性,我们尝试深入增加更多的卷积层,构建六个卷积层并深入。
具体的,输出空间的维度为32,64,512vs32,64,256,1024。改进后的模型提高了精度和召回率,如下图所示。
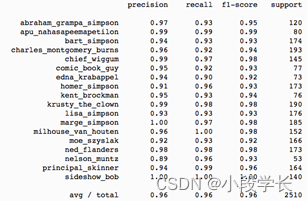
图3-4六层卷积网
3.2.4 实验结果

图3-5 12类角色的预测结果和真实结果
如图所示,本实验对数据集中图像有很好的预测结果且预测速度足够快。同样,在视频中预测角色也呈现出不错的结果。
4 结论
本文采用卷积神经网络模型建立辛普森角色识别模型,用于自动识别《辛普森一家》中每个角色。首先,在《辛普森一家》第4至第24季节中逐帧截取20个角色图像共16503幅,并标记每个图片的角色;使用Keras训练构建卷积神经网络,因为辛普森一家人中人物过于相似且人物形态不一,人脸分布在不同的区域,所以需要我们细致的提取特征,以达到区分的能力,最终能得到给定一个角色的图片,模型返回此图像上的字符的结果,测试集上的识别准确度可达96%,神经网络在识别和分类字符方面非常准确。然后,预测视频中的人物,预测速度足够快(预测图片不到0.1秒),每秒可以预测多帧。
但是该CNN模型每次只能识别单个人物,且不能指出该人物的图片位置。为了提高角色识别的准确率,下一步工作将继续优化卷积神经网络结构和参数,完善数据集内容,使用基本网络层定义人物分类器,构建区域提案网络,建立新的模型,对模型进行测试,可以达到能正确定位图中人物并对其进行分类,同时还能预测每个定位人物的边界框坐标的结果。
参 考 文 献
[1] Alexandre Attia. The Simpsons characters recognition and detection usingKeras (Part 1)[EB/OL]. Jun 2, 2017[]. .
[2] Alexandre Attia. . Role Identification and Detection of the Simpsons (Part 2)[EB/OL]. July 1, 2017[]. .
[3]颜冰.基于卷积神经网络人脸识别实现策略[J].网络安全技术与应用,2022,(06):47-49.
[4] Zhichao Xian. Survey of image recognition technology based on convolution neural network[P]. 2020 4th International Conference on Computer Engineering, Information Science & Application Technology,2020.
[5] Chen Yuanyi. Research on Convolutional Neural Network Image Recognition Algorithm Based on Computer Big Data[J]. Journal of Physics: Conference Series,2021,1744(2).
[6] 何超,侯明.基于改进卷积神经网络的人脸表情识别方法[J].信息技术,2022(05):107-111+117.DOI:10.13274/j.cnki.hdzj.2022.05.018.
[7] 姬壮伟.基于深度全卷积神经网络的图像识别研究[J].山西大同大学学报(自然科学版),2022,38(02):27-29+74.
[8] Shiyan Gong, Libo Xue, Yuxi Pu , Xuanping Fan. Research on computer intelligent image recognition algorithm[J]. Scientific Journal of Intelligent Systems Research,2021,3(12).
[9] Tokarev K E,Zotov V M,Khavronina V N,Rodionova O V. Convolutional neural network of deep learning in computer vision and image classification problems[J]. IOP Conference Series: Earth and Environmental Science,2021,786(1).
[10] Jafar Tavoosi. Designing a new recurrent convolutional neural network for face detection and recognition in a color image[J]. Iran Journal of Computer Science,2021(prepublish).
[11]靳晶晶,王佩.基于卷积神经网络的图像识别算法研究[J].通信与信息技术,2022(02):76-81.
[12] 叶建龙,胡新海. 基于卷积神经网络的图像识别算法研究[J]. 安阳师范学院学报,2021(05):14-18.DOI:10.16140/j.cnki.1671-5330.
2021.05.005.
欢迎大家加我微信交流讨论(请备注csdn上添加)




















 1959
1959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











