







Python数据分析与展示
第一周 数据分析之表示
NumPy库入门
ndarray对象的属性

ndarray数组的元素类型


 非同质的ndarray对象
非同质的ndarray对象
- ndarray数组可以由非同质对象构成
- 非同质ndarray元素为对象类型
- 非同质ndarray对象无法有效发挥NumPy优势,尽量避免使用
ndarray数组的创建
(1)从Python中的列表、元组等类型创建ndarray数组

x = np.array([0,1,2,3]) #从列表类型创建
x = np.array((4,5,6,7)) #从元组类型创建
x = np.array([[1,2],[9,8],(0.1,0.2)]) #从列表和元组混合类型创建
print(x)
[[1. 2.]
[9. 8.]
[0.1 0.2]](2)使用NumPy中函数创建ndarray数组


(3)使用NumPy中其他函数创建ndarray数组
ndarray数组的变换
ndarray数组的维度变换

ndarray数组的类型变换
new_a = a.astype(new_type)
#astype()方法一定会创建新的数组(原始数据的一个拷贝),即使两个类型一致
ls = a.tolist()#ndarray数组向列表的转换例如: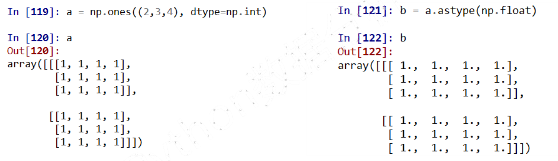

ndarray数组的操作

多维数组

ndarray数组的运算
(1)数组与标量之间的运算作用于数组的每一个元素
例如计算a与元素平均值的商 a = a/a.mean()
(2)对ndarray中的数据执行元素级运算的函数

(3)NumPy一元函数
(4)NumPy二元函数
NumPy数据存储与函数
数据CSV文件存取
- frame:文件、字符串或产生器,可以是.gz或.bz2的压缩文件
- array:存入文件的数组
- dtype:数据类型,可选
- delimiter:分割字符串,默认是任何空格
- unpack:如果True,读入属性将分别写入不同变量
CSV文件的局限性 - CSV只能有效存储一维和二维数组
- np.savetxt(frame,array,fmt=’%.18e’,delimiter=None) np.loadtxt(frame,dtype=np.float,delimiter=None,unpack=False)只能有效存取一维和二维数据数组


多维数据的存取
- frame:文件、字符串
- dtype:读取的数据类型
- count:读入元素个数,-1表示读入整个文件
- sep:数据分割字符串,如果是空串,写入文件为二进制
- format:写入数据的格式
需要注意
该方法需要读取时知道存入文件时数组的维度和元素类型
a.tofile(frame,sep=’’,format=’%s’)
np.fromfile(frame,dtype=float,count=-1,sep=’’)
需要配合使用可以通过元数据文件来存储额外信息


NumPy的便捷文件存取
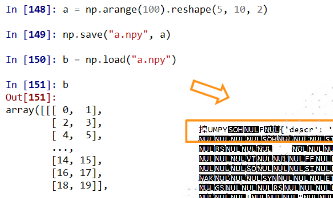
np.save(fname,array)或np.savez(fname,array)
np.load(fname)
- fname:文件名,以.npy为扩展名,压缩扩展名为.npz
- array:数组变量
NumPy的随机数函数




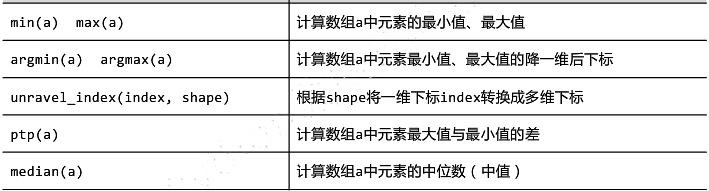
NumPy的统计函数



NumPy的梯度函数



实例1:图像的手绘效果
from PIL import Image
import numpy as np
a = np.asarray(Image.open('./beijing.jpg').convert('L')).astype('float')
#array和asarray都可将结构数据转换为ndarray类型。主要区别就是当数据源是ndarray时,array仍会copy出一个副本,占用新的内存,但asarray不会。
depth = 10. # (0-100)
grad = np.gradient(a) #取图像灰度的梯度值
grad_x, grad_y = grad #分别取横纵图像梯度值
grad_x = grad_x*depth/100.
grad_y = grad_y*depth/100.
A = np.sqrt(grad_x**2 + grad_y**2 + 1.)
uni_x = grad_x/A
uni_y = grad_y/A
uni_z = 1./A
vec_el = np.pi/2.2 # 光源的俯视角度,弧度值
vec_az = np.pi/4. # 光源的方位角度,弧度值
dx = np.cos(vec_el)*np.cos(vec_az) #光源对x 轴的影响
dy = np.cos(vec_el)*np.sin(vec_az) #光源对y 轴的影响
dz = np.sin(vec_el) #光源对z 轴的影响
b = 255*(dx*uni_x + dy*uni_y + dz*uni_z) #光源归一化
b = b.clip(0,255)
im = Image.fromarray(b.astype('uint8')) #重构图像
im.save('./beijingHD.jpg')第二周 数据分析之展示
Matplotlib库入门
Matplotlib库的效果
import matplotlib.pyplot as plt
plot.plot()只有一个输入列表或数组时,参数被当作Y轴,X轴以索引自动生成
plt.savefig(‘test’,dpi=600)将输出图形储存为文件,默认PNG格式,可以通过dpi修改输出质量
plt.subplot(nrows,ncols,plot_number)在全局绘图区域创建一个分区体系,并定位到一个子绘图区域
plt.plot(x,y,format_string,**kwargs)



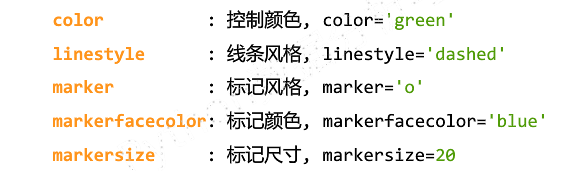
- x:可选
- y
- format_string:控制曲线的格式字符串,可选
- **kwargs:第二组或更多(x,y,format_string)
Matplotlib基础绘图函数示例(5个)
实例2:引力波的绘制
import numpy as np#科学计算
import matplotlib.pyplot as plt#绘图
from scipy.in import wavfile#读取波形文件
rate_h, hstrain= wavfile.read(r"H1_Strain.wav","rb")#字符串前添加r表示原始的字符串
rate_l, lstrain= wavfile.read(r"L1_Strain.wav","rb")
reftime, ref_H1 = np.genfromtxt('GW150914_4_NR_waveform_template.txt').transpose()
reftime, ref_H1 = np.genfromtxt('wf_template.txt').transpose() #使用python123.io下载文件
#np.genfromtxt主要执行两个运算循环,第一个循环是将文件的每一行都转换成字符串序列,第二个循环是将每个字符串序列转化为sin的数据类型。读取出来的是两行的矩阵,再用transpose转秩,再分别赋给两个变量
htime_interval = 1/rate_h#得到波形的时间间隔
ltime_interval = 1/rate_l
#使用来自"H1"探测器的数据作图
fig = plt.figure(figsize=(12, 6))#创建一个大小为12*6的绘图空间
# 丢失信号起始点
htime_len = hstrain.shape[0]/rate_h
htime = np.arange(-htime_len/2, htime_len/2 , htime_interval)
plth = fig.add_subplot(221)
plth.plot(htime, hstrain, 'y')
plth.set_xlabel('Time (seconds)')#画出以时间为X轴,应变数据为Y轴的图像并设置标题和坐标轴的标签
plth.set_ylabel('H1 Strain')
plth.set_title('H1 Strain')
ltime_len = lstrain.shape[0]/rate_l
ltime = np.arange(-ltime_len/2, ltime_len/2 , ltime_interval)
pltl = fig.add_subplot(222)
pltl.plot(ltime, lstrain, 'g')
pltl.set_xlabel('Time (seconds)')
pltl.set_ylabel('L1 Strain')
pltl.set_title('L1 Strain')
pltref = fig.add_subplot(212)
pltref.plot(reftime, ref_H1)
pltref.set_xlabel('Time (seconds)')
pltref.set_ylabel('Template Strain')
pltref.set_title('Template')
fig.tight_layout()#自动调整图像外部边缘
#显示并保存图像
plt.savefig("Gravitational_Waves_Original.png")
plt.show()
plt.close(fig)第三周 数据分析之概要
Pandas库入门
import pandas as pd
两个数据类型:Series,DataFrame
基于上述数据类型的各种操作:基本操作、运算操作、特征类操作、关联类操作
Pandas 扩展数据类型、关注数据的应用表达、数据与索引间关系
Pandas库的Series类型
series类型由一组数据及与之相关的数据索引组成
可由如下类型创建:
- Python列表
- 标量值
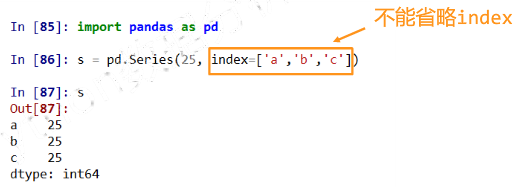
- Python字典

- ndarray

- 其他函数,range()函数等
Series类型的基本操作
- Series类型包括index和values两部分


- Series类型的操作类似ndarray类型
- 索引方法相同,采用[]
- NumPy中运算和操作可用于Series类型
- 可以通过自定义索引的列表进行切片
- 可以通过自动索引进行切片,如果存在自定义索引,则一同被切片
- Series类型的错做类似Python字典类型
- 通过自定义索引访问
- 保留字in操作,返回True或False
- 使用.get()方法
- Series类型对其操作Series+Series
- Series类型在运算中会自动对齐不同索引的数据

- Series类型的name属性
- Series对象和索引都可以有一个名字,存储在属性.name中

- Series类型的修改
- Series对象可以随时修改并即可生效

- Series类型
- Series是一维带“标签”数组 index_0–>data_a
- Series基本操作类似ndarray和字典,根据索引对齐
Pandas库的DataFrame类型
-
DataFrame类型由共用相同索引的一组列组成
-
是一个表格型的数据类型,每列值类型可以不同
-
既有行索引、也有列索引
-
DataFrame类型可以由如下类型创建:
-
二维ndarray对象

-
由一维ndarray、列表、字典、元组或Series构成的字典

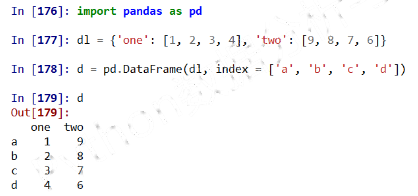 例子
例子

-
Series类型
-
其他的DataFrame类型
Pandas库的数据类型操作
-
重新索引.reindex(index=None,columns=None,…)的参数


-
索引类型
-
Series和DataFrame的索引是Index类型,Index对象是不可修改类型
-
索引类型的常用方法

-
删除指定索引对象

Pandas库的数据类型运算
- 算术运算法则
- 算术运算根据行列索引,补齐后运算,运算默认产生浮点数补齐时缺项填充NaN(空值)
- 二维和一维、一维和零维间为广播运算
- 采用±*/符号进行的二元运算产生新的对象
- 数据类型的算术运算

- 方法形式的运算




- 比较运算法则
- 比较运算只能比较相同索引的元素,不进行补齐
- 二维和一维、一维和零维间为广播运算
- 采用><>=<= == !=等符号进行的二元运算产生布尔对象


Pandas数据特征分析
数据的排序
- .sort_index(axis=0,ascending=True)方法在指定轴上根据索引进行排序,默认升序
- .sort_values(axis=0,ascending=True)
- DataFrame.sort_values(by,axis=0,ascending=True)
- by:axis轴上的某个索引或索引列表















 998
998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









