







一、前言
- 本文将介绍在YARN集群中如何终止正在运行的任务。通过掌握这些技巧,可以有效管理和优化YARN集群资源,确保任务的及时完成和系统的高效运行。
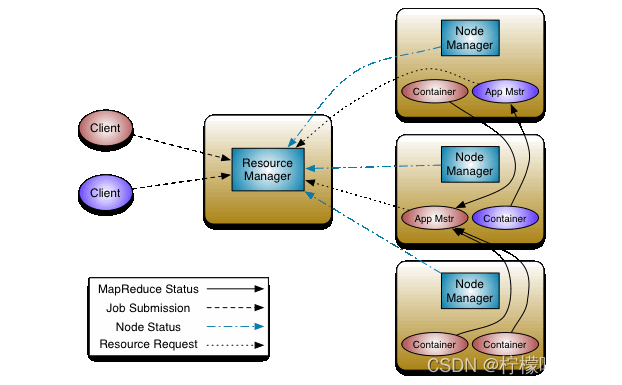
- 在大规模数据处理和分布式计算中,YARN(Yet Another Resource Negotiator)作为Apache Hadoop的资源管理器,扮演着关键的角色。YARN允许用户将任务提交到集群中,并有效地分配和管理资源,以实现高性能的数据处理。然而,有时候我们可能需要终止正在运行的YARN任务,可能是由于任务执行时间过长、资源占用过高或其他原因。
二、方法一:使用YARN Web界面
- YARN提供了一个Web界面,通过该界面可以方便地查看和管理正在运行的应用程序。以下是通过YARN Web界面终止任务的步骤
- 打开的Web浏览器,
并导航到YARN集群的ResourceManager的URL,通常,默认情况下,URL为http://:8088,其中是ResourceManager的主机名或IP地址。 - 在YARN Web界面中,
导航到"Applications"或"应用程序"部分,这里将显示所有正在运行的应用程序。 - 在应用程序列表中,找到要终止的
application任务,并点击该任务的链接,以查看更多详细信息。 - 在应用程序详细信息页面,
将找到一个"Kill"或"终止"按钮或链接。点击该按钮将终止选定的任务。
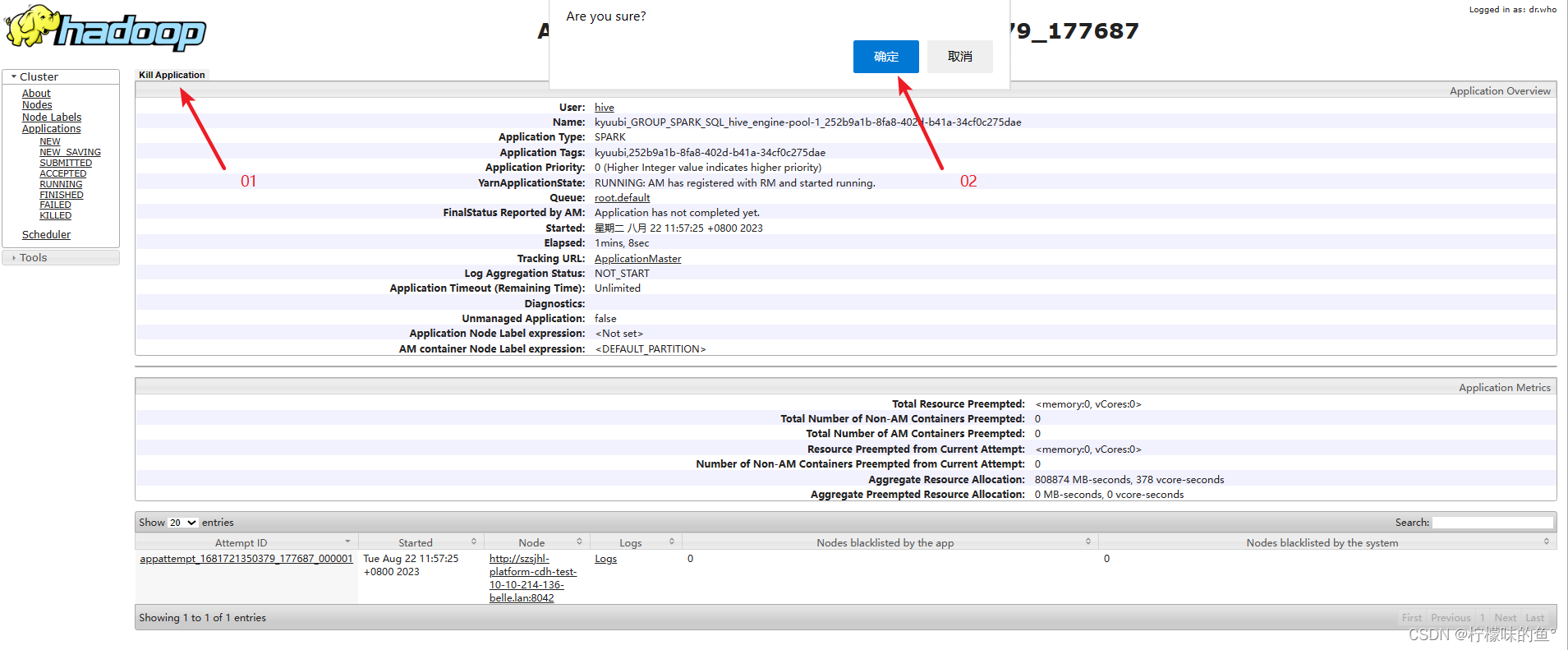
请注意,使用YARN Web界面终止任务只适用于较少数量的任务或简单操作。对于大规模的YARN集群和复杂的任务管理,我们可以使用命令行工具或API进行更高级的操作。
三、方法二:使用YARN命令行工具
- YARN提供了一组命令行工具,可以在命令行界面或终端中使用这些工具来管理YARN任务。以下是使用命令行工具终止任务的步骤:
- 打开终端或命令行界面,
并登录到YARN集群的任一节点。 - 运行以下命令以获取正在运行的应用程序列表:
yarn application -list
这将列出所有正在运行的应用程序及其相关信息,包括应用程序ID。
- 找到要终止的任务的应用程序ID,并运行以下命令终止任务:
yarn application -kill <application_id>
将<application_id>替换为要终止的任务的应用程序ID。
使用YARN命令行工具可以批量处理任务,同时提供了更多灵活性和控制选项。可以将这些命令行工具结合脚本使用,以实现自动化的任务管理。
四、方法三:使用YARN REST API
- 如果希望通过编程方式自动终止任务,YARN提供了REST API接口,可以使用HTTP请求来管理任务。以下是使用YARN REST API终止任务的步骤:
-
构造一个HTTP PUT请求,目标URL为
http://<resourcemanager>:8088/ws/v1/cluster/apps/<application_id>/state,其中是的ResourceManager的主机名或IP地址,<application_id>是要终止的任务的应用程序ID。 -
设置请求的Content-Type为application/json,并在请求体中传递一个JSON对象,指定任务的状态为"KILLED":
{"state":"KILLED"} -
发送HTTP PUT请求到目标URL,终止任务。
#shell
curl -X PUT -H "Content-Type: application/json" -d '{"state":"KILLED"}' http://192.168.200.105:8088/ws/v1/cluster/apps/application_1681721350379_176229/state
#python
import requests
url = 'http://192.168.200.105:8088/ws/v1/cluster/apps/application_1681721350379_176229/state'
headers = {'Content-Type': 'application/json'}
data = '{"state": "KILLED"}'
response = requests.put(url, headers=headers, data=data)
if response.status_code == 200:
print('Request successful.')
else:
print('Request failed. Status code:', response.status_code)
使用YARN REST API可以灵活地集成YARN任务管理到自己的应用程序或脚本中,以实现更高级的任务管理和自动化。
五、结语
- 通过以上方法,可以在YARN集群中有效地终止正在运行的任务。无论是通过YARN Web界面、命令行工具还是REST API,选择适合需求的方法,可以帮助更好地管理和优化YARN集群资源,确保任务的及时完成和系统的高效运行。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









