









一、前言
| 名称 | 版本 |
|---|---|
| ClickHouse | 21.9.5.16 |
| Prometheus | 2.32.1 |
| Grafana | 9.2.4 |
| prom2click | 0.2 |
1、概述
我们都知道,Prometheus的数据存储一般都是存放本地的 TSDB (时序数据库)中,使得Prometheus部署方便快捷,然而原生的 TSDB 对于大数据量的保存及查询支持不太友好,该数据库不能保证可靠性,且无法支持Prometheus集群架构。
对于这方面的完善,Prometheus提供了remote_write和remote_read的特性,支持将数据存储到远端和从远端读取数据的功能。当配置remote_write特性后,Prometheus会将采集到的指标数据通过HTTP的形式发送给适配器(Adaptor),由适配器进行数据的写入。而remote_read特性则会向适配器发起查询请求,适配器根据请求条件从第三方存储服务中获取响应的数据。

2、Metrics的持久化
其实监控不仅仅是体现在可以实时掌握系统运行情况,及时报警这些。而且监控所采集的数据,在以下几个方面是有价值的
- 资源的审计和计费。这个需要保存一年甚至多年的数据的。
- 故障责任的追查
- 后续的分析和挖掘,甚至是利用AI,可以实现报警规则的设定的智能化,故障的根因分析以及预测某个应用的qps的趋势,提前HPA等,当然这是现在流行的AIOPS范畴了。
3、Prometheus 数据持久化方案
- AppOptics: write
- AWS Timestream: read and write
- Azure Data Explorer: read and write
- Azure Event Hubs: write
- Chronix: write
- Cortex: read and write
- CrateDB: read and write
- Elasticsearch: write
- Gnocchi: write
- Google BigQuery: read and write
- Google Cloud Spanner: read and write
- Grafana Mimir: read and write
- Graphite: write
- InfluxDB: read and write
- Instana: write
- IRONdb: read and write
- Kafka: write
- M3DB: read and write
- New Relic: write
- OpenTSDB: write
- PostgreSQL/TimescaleDB: read and write
- QuasarDB: read and write
- SignalFx: write
- Splunk: read and write
- Sysdig Monitor: write
- TiKV: read and write
- Thanos: read and write
- VictoriaMetrics: write
- Wavefront: write
- clickhouse: read and write
选型方案需要具备以下几点
1、满足数据的安全性,需要支持容错,备份
2、写入性能要好,支持分片
3、技术方案不复杂
4、用于后期分析的时候,查询语法友好
5、grafana读取支持,优先考虑
6、需要同时支持读写
- 基于以上的几点,clickhouse满足我们使用场景。
Clickhouse是一个高性能的列式数据库,因为侧重于分析,所以支持丰富的分析函数。
下面是Clickhouse官方推荐的几种使用场景:
- Web and App analytics
- Advertising networks and RTB
- Telecommunications
- E-commerce and finance
- Information security
- Monitoring and telemetry
- Time series
- Business intelligence
- Online games
- Internet of Things
4、Prometheus设计架构
- 将prometheus的metric监控及告警数据存入到clickhouse里面,存储的prometheus数据主要是做统计汇总,采用GraphiteMergeTree 引擎。它能减少存储空间,同时能提高Graphite数据的查询效率。
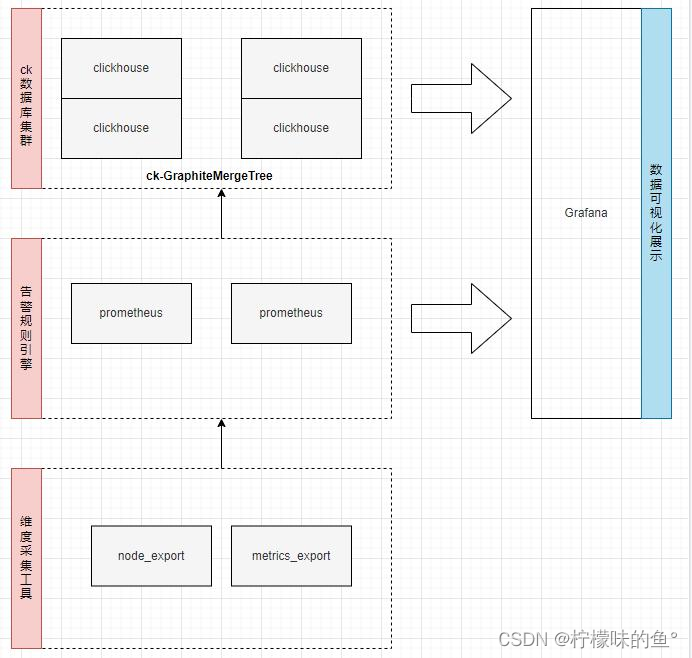
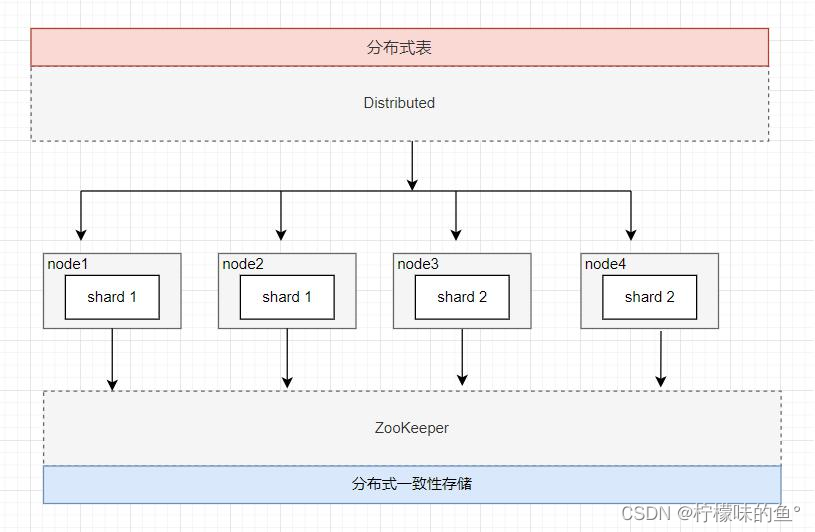
5、ClickHouse 双分片双副本
- 在每个节点创建一个数据表,作为一个数据分片,分布表同时负责分片和副本的数据写入工作。分布从2个Shard中随机取一个节点进行访问。其中任何单节点异常时,写入和查询都能保障数据完整性,高可用,业务无感知。
二、Prometheus Store ClickHouse
1、ClickHouse配置
- 这里主要是讲ClickHouse配置,以及Prometheus 如何配置,至于搭建请各位小伙伴自行搭建环境
编辑ClickHouse config.xml配置文件,添加配置一个配置一个graphite_rollup (如果不配置的话,创表语句会执行失败的),具体参数含义参考clickhouse官方文档:GraphiteMergeTree
<graphite_rollup>
<path_column_name>tags</path_column_name>
<time_column_name>ts</time_column_name>
<value_column_name>val</value_column_name>
<version_column_name>updated</version_column_name>
<default>
<function>avg</function>
<retention>
<age>0</age>
<precision>10</precision>
</retention>
<retention>
<age>86400</age>
<precision>30</precision>
</retention>
<retention>
<age>172800</age>
<precision>300</precision>
</retention>
</default>
</graphite_rollup>
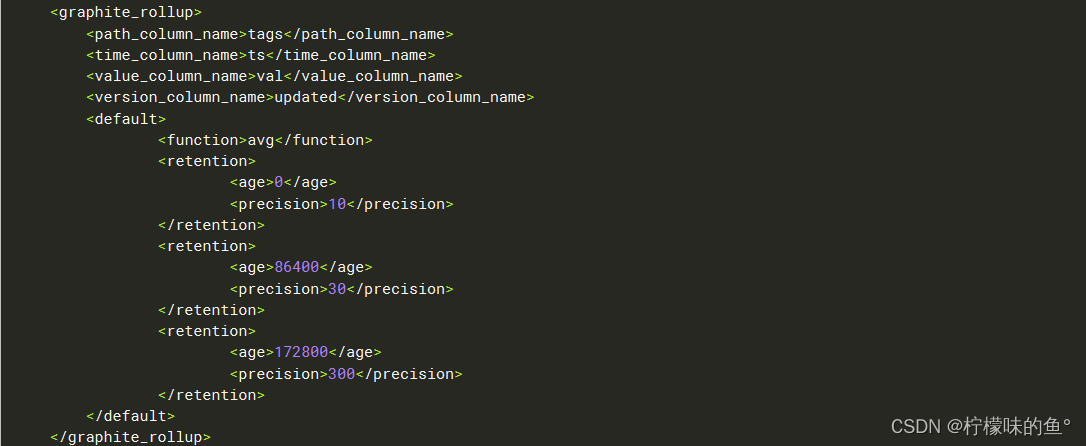
完整 ClickHouse 配置见:
链接:https://pan.baidu.com/s/1BJYgwEnhTBmF-dD36cSS6Q
提取码:C2hp
2、ClickHouse 创建存储表
需要将prometheus的metric数据存入到clickhouse里面,首先需要做的是创建一张表,将metric数据存入到表内,prometheus的数据格式是key-value格式。
-- 创建 metrics库
CREATE DATABASE IF NOT EXISTS metrics ON CLUSTER default ;
-- 创建 samples存储表(新的SQL建表语法)
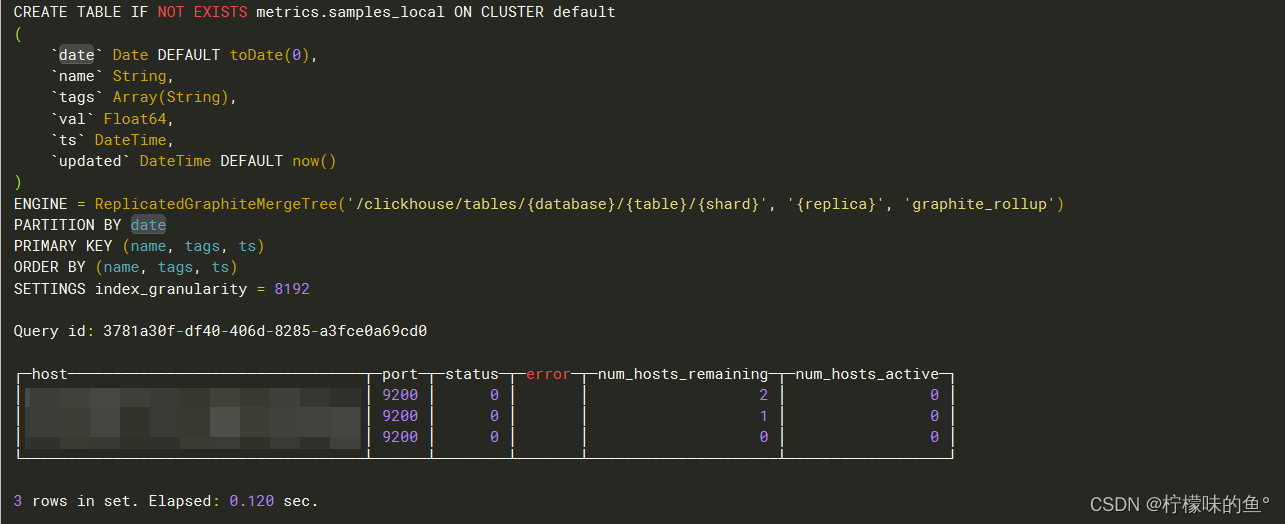
CREATE TABLE IF NOT EXISTS metrics.samples ON CLUSTER default
(
`date` Date DEFAULT toDate(0),
`name` String,
`tags` Array(String),
`val` Float64,
`ts` DateTime,
`updated` DateTime DEFAULT now()
)
ENGINE = ReplicatedGraphiteMergeTree('/clickhouse/tables/{database}/{table}/{shard}', '{replica}','graphite_rollup')
PARTITION BY (date)
ORDER BY (name, tags, ts)
PRIMARY KEY (name, tags, ts)
SETTINGS index_granularity = 8192;
-- 创建 samples存储表(弃用SQL建表语法)
CREATE TABLE IF NOT EXISTS metrics.samples ON CLUSTER default
(
`date` Date DEFAULT toDate(0),
`name` String,
`tags` Array(String),
`val` Float64,
`ts` DateTime,
`updated` DateTime DEFAULT now()
)
ENGINE = ReplicatedGraphiteMergeTree('/clickhouse/tables/{database}/{table}/{shard}', '{replica}', date, (name, tags, ts), 8192, 'graphite_rollup');
--- 创建samples 分布式表SQL:
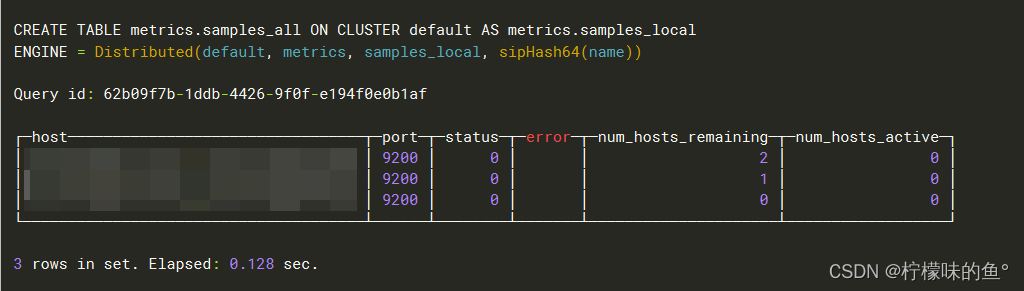
CREATE TABLE metrics.samples_all ON CLUSTER default
AS metrics.samples
ENGINE = Distributed(default, metrics, samples, sipHash64(name));
以上建表需注意,我这边环境是ClickHouse 集群版,ON CLUSTER 集群名称;
三、Prometheus 配置
安装Prometheus并配置远程读写url,这里需要注意ip写prome2click安装机器的ip和端口。
remote_write:
- url: "http://localhost:9201/write"
remote_read:
- url: "http://localhost:9201/read"

四、Prome2click 配置
1、下载源码编译
- 安装 go 和 glide
wget https://github.com/iyacontrol/prom2click.git
make get-deps
make build
./bin/prom2click
- 由于编译中很容易出现各种问题,而且要准备go环境,这边已经编译好,需要的小伙伴自行下载,详见百度网盘
链接:https://pan.baidu.com/s/1BJYgwEnhTBmF-dD36cSS6Q
提取码:C2hp
2、创建ClickHouse 相关账号
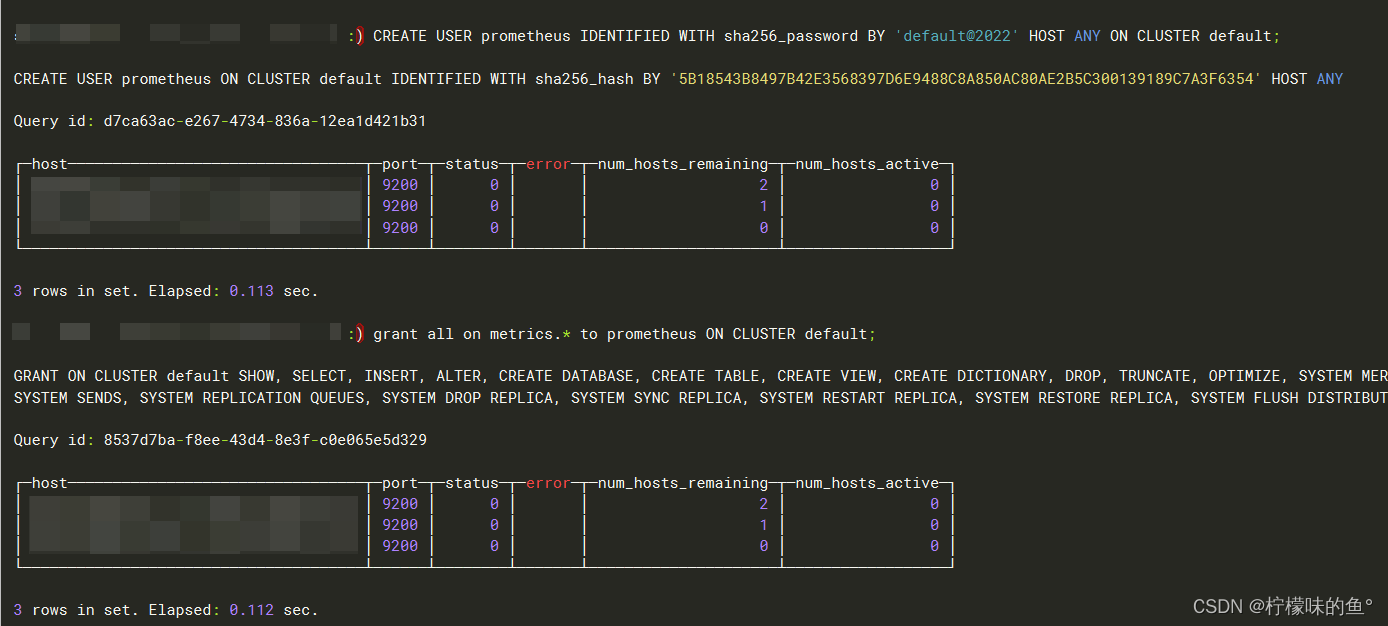
-- 创建Prometheus账号
CREATE USER prometheus IDENTIFIED WITH sha256_password BY 'default@2022' HOST ANY ON CLUSTER default;
-- 授权
grant all on metrics.* to prometheus ON CLUSTER default;
3、启动 Prome2click
1、创建目录,将 prom2click 包拷贝过去
mkdir -p /app/prom2
2、创建system管理脚本,方便管理(ck如果设置的是无分片,也就是1分片,写local本地表),需修改clickhouse 的ip地址和端口
- List item
cat << EOF >/usr/lib/systemd/system/prom2click-server.service
[Unit]
Description=prom2click-server
After=syslog.target
After=network.target
[Service]
Type=simple
User=prometheus
Group=prometheus
WorkingDirectory=/app/prom2
ExecStart=/app/prom2/prom2click -ch.dsn=tcp://172.17.209.4:9200?database=metrics&username=prometheus&password=default@2022&read_timeout=10&write_timeout=20&alt_hosts=172.17.209.5:9200
Restart=always
[Install]
WantedBy=multi-user.target
EOF
3、reload systemctl
systemctl daemon-reload
4、授权
chmod 754 /usr/lib/systemd/system/prom2click-server.service
5、启动
systemctl start prom2click-server.service
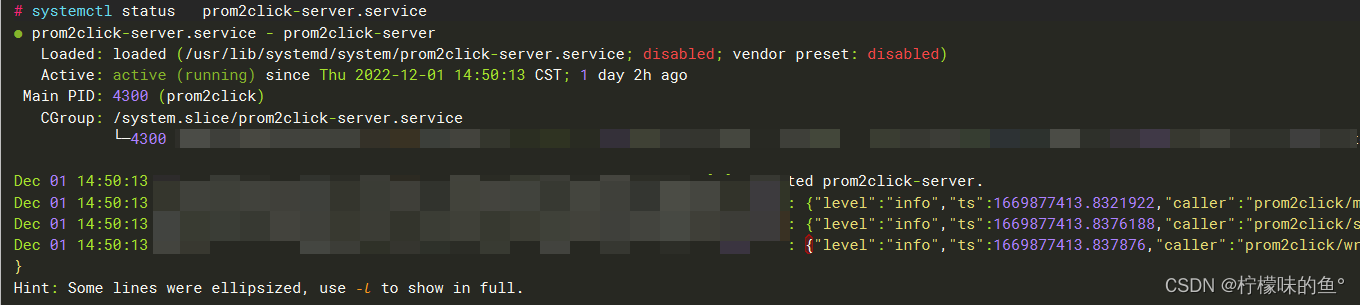
5、查看启动状态
-- 查看状态是否 running
systemctl status prom2click-server.service
-- 查看端口是否监听
netstat -lntp|grep 9201
五、验证
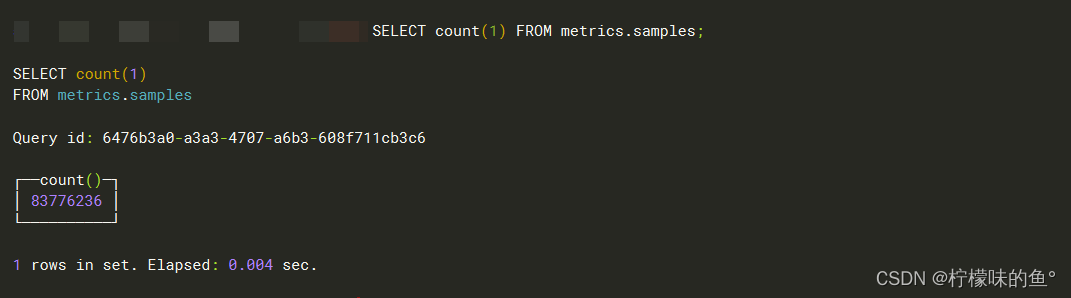
- 写入验证
1、查询clickhouse metrics.samples表中数据是否有数据进去
SELECT count(1) FROM metrics.samples;
- 读取验证
数据呈现一致之后,我们可以试着停止Prometheus服务,同时删除本地data目录的监控数据,模拟Promthues数据丢失的情况后重启服务。重新打开Prometheus后,如果还可以正常查询到本地存储已删除的历史数据记录,则代表配置正常。
六、总结
Prometheus-Clickhuse-Adapter(Prom2click) 是一个将clickhouse作为prometheus 数据远程存储的适配器。
prometheus-clickhuse-adapter,该项目缺乏日志,对于一个实际生产的项目,是不够的,此外一些数据库连接细节实现的也不够完善
在实际使用过程中,要注意并发写入数据的数量,及时调整启动参数
1、 Table is in readonly mode ?
问题现象:由于存在大数据量的数据写入(200MB/s以上的写入速度),时常会在clickhouse-server的日志中看到Table is in readonly mode的告警信息。
问题原因:大体原因和zk的处理性能相关,随着写入数据量的增多,zk的log和snapshot文件会不断膨胀,有时就会出现zk服务不可用的情况,而clickhouse的ReplicatedMergeTree又强依赖于zk,一旦zk不可用,为了保证数据的一致性,系统就会进行“写保护”,出现上述提示。
解决办法
-
方案1:调整use_minimalistic_part_header_in_zookeeper参数; 网上有些朋友说是调整这个参数可以减少写入zk日志的数据量,但因为我们使用的是21的版本,此版本默认这个参数已经是开启了,因此这个方案对我们实际无效。
-
方案2:一个CH集群使用多个zk集群来提供服务; 这属于压力转移的策略,我们最后也无奈使用了这种办法,当然能解决问题,但带来的副作用就是zk集群运维管理成本的上升。
2、优化
1、表大小
-- 查看 samples 表占用大小,以及压缩大小
SELECT
table AS `表名`,
sum(rows) AS `总行数`,
formatReadableSize(sum(data_uncompressed_bytes)) AS `原始大小`,
formatReadableSize(sum(data_compressed_bytes)) AS `压缩大小`,
round((sum(data_compressed_bytes) / sum(data_uncompressed_bytes)) * 100,
0) AS `压缩率`
FROM
system.parts
WHERE
table IN ('samples')
GROUP BY
table;
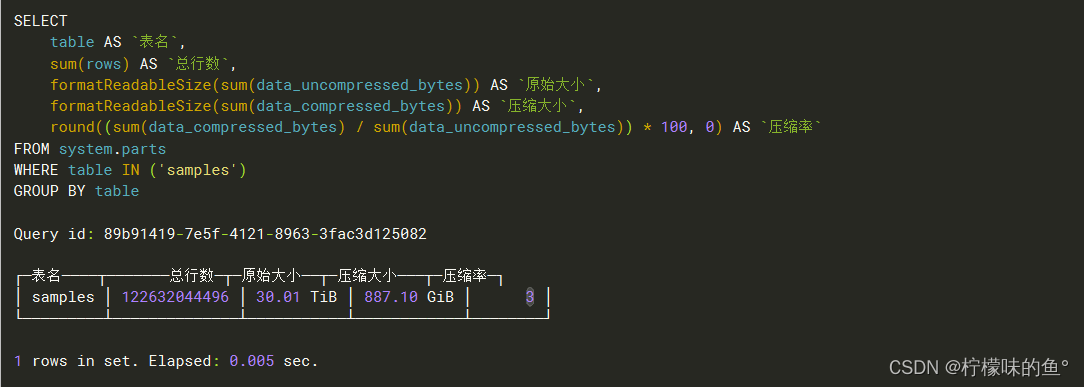
这个只是看的单台分片机器的大小(我们生产环境是 2shard x 2replica),可以看到压缩效率很大,实际占用才800G左右,这还是存储了2021-当前的数据。可以适当的清理一下之前老的数据。
2、清理分区
1、查看分区大小
-- 查看分区详细占用大小
SELECT
partition AS `分区`,
sum(rows) AS `总行数`,
formatReadableSize(sum(data_uncompressed_bytes)) AS `原始大小`,
formatReadableSize(sum(data_compressed_bytes)) AS `压缩大小`,
round((sum(data_compressed_bytes) / sum(data_uncompressed_bytes)) * 100,
0) AS `压缩率`
FROM
system.parts
WHERE
(database IN ('metrics'))
AND (table IN ('samples'))
AND (partition LIKE '202%')
GROUP BY
partition
ORDER BY
partition ASC;
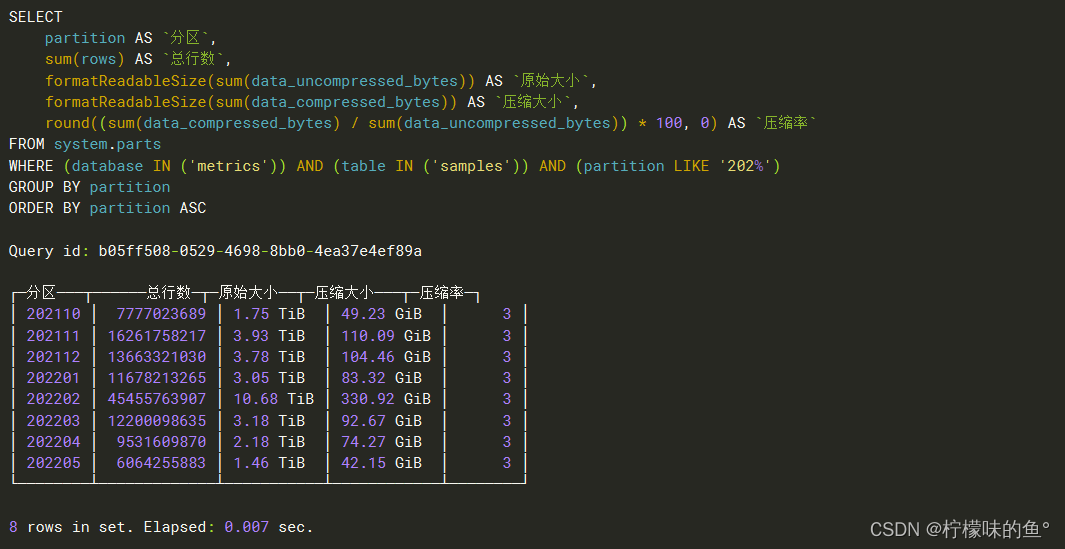
删除 2021 年整年的分区,只保存 2022年就可以,理论上也不需要用到这么久,可适当清理历史数据(我们在使用时候发现,如果历史监控数据保存时间过长,会给clickhouse带来压力,查询以前的历史数据会很慢,而且ck所在物理服务器CPU、磁盘io压力会非常大,所以有能力可以使用SSD,而且clickhouse最好没有其它业务使用,只单独给 Prometheus 这一套业务使用,不然很容易影响其它业务。)
2、删除历史分区
-- 删除指定分区
ALTER TABLE metrics.samples ON CLUSTER bdmp_ck_cluster DROP PARTITION (202110);
ALTER TABLE metrics.samples ON CLUSTER bdmp_ck_cluster DROP PARTITION (202111);
ALTER TABLE metrics.samples ON CLUSTER bdmp_ck_cluster DROP PARTITION (202112);
-- 批量删除分区,数据量太大了删除会报错,还是用上面的方法吧...
ALTER TABLE metrics.samples ON CLUSTER bdmp_ck_cluster DELETE WHERE date <= (202201);
3、如果觉得每次都要删除分区太麻烦,可以给表加上 ttl过期时间
-- 保存一年
ALTER TABLE metrics.samples ON CLUSTER bdmp_ck_cluster MODIFY TTL date + INTERVAL 1 YEAR;
-- 保存 90天
ALTER TABLE metrics.samples ON CLUSTER bdmp_ck_cluster MODIFY TTL date + INTERVAL 90 DAY;
-- 保存6个月
ALTER TABLE metrics.samples ON CLUSTER bdmp_ck_cluster MODIFY TTL date + INTERVAL 6 MONTH;
-- 或者是在建表的时候加上 (保存1年)
CREATE TABLE IF NOT EXISTS metrics.samples ON CLUSTER bdmp_ck_cluster
(
`date` Date DEFAULT toDate(0),
`name` String,
`tags` Array(String),
`val` Float64,
`ts` DateTime,
`updated` DateTime DEFAULT now()
)
ENGINE = ReplicatedGraphiteMergeTree('/clickhouse/tables/{database}/{table}/{shard}', '{replica}','graphite_rollup')
PARTITION BY (date)
ORDER BY (name, tags, ts)
TTL date + toIntervalYEAR(1)
PRIMARY KEY (name, tags, ts)
SETTINGS index_granularity = 8192;

















 1231
1231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









