






随机森林分类器在Business Analysis中的运用
随机森林分类器的运用(Udacity 毕业设计星巴克项目思路)
1 背景介绍
通过分析用户行为与特征来决策商业战略已成为快消行业巨头们的标准动作,一套合理的预测模型可以为企业带来巨大的营收。本毕业设计致力于通过分析星巴克的客户行为与客户社会特征的关联性,提高锁定目标客户的精度、扩大潜在客户的群体并降低成本。因涉及多特征下的复杂分类问题,故本项目采用搭建机器学习模型的方式来根据客户特征数据、客户与推送信息的交互和消费记录来预测潜在顾客是否会对特定推送做出反应。
2 数据集
2.1 数据描述
这个数据集是一些模拟 Starbucks rewards 移动 app 上用户行为的数据。每隔几天,星巴克会向 app 的用户发送一些推送。这个推送可能仅仅是一条饮品的广告或者是折扣券或 BOGO(买一送一)。一些顾客可能一连几周都收不到任何推送。 请注意这个数据集是从星巴克 app 的真实数据简化而,模拟器仅产生了一种饮品,而实际上星巴克的饮品有几十种。
每种推送都有有效期。例如,买一送一(BOGO)优惠券推送的有效期可能只有 5 天。如果一条推送的有效期是 7 天,无论消息类型是否涉及实际金额奖励,我们都认为该顾客在这 7 天都可能受到这条推送的影响。数据集中还包含 app 上支付的交易信息,交易信息包括购买时间和购买支付的金额。交易信息还包括该顾客收到的推送种类和数量以及看了该推送的时间。顾客做出了购买行为也会产生一条记录。需要注意的是,顾客可能购买了商品,但没有收到或者没有看推送。
2.2 数据输入
一共有三个数据文件:
- portfolio.json – 包括推送的 id 和每个推送的元数据(持续时间、种类等等)
- profile.json – 每个顾客的人口统计数据
- transcript.json – 交易、收到的推送、查看的推送和完成的推送的记录
portfolio.json
- id (string) – 推送的id
- offer_type (string) – 推送的种类,例如 BOGO、打折(discount)、信息(informational)
- difficulty (int) – 满足推送的要求所需的最少花费
- reward (int) – 满足推送的要求后给与的优惠
- duration (int) – 推送持续的时间,单位是天
- channels (字符串列表)
profile.json
- age (int) – 顾客的年龄
- became_member_on (int) – 该顾客第一次注册app的时间
- gender (str) – 顾客的性别(注意除了表示男性的 M 和表示女性的 F 之外,还有表示其他的 O)
- id (str) – 顾客id
- income (float) – 顾客的收入
transcript.json
- event (str) – 记录的描述(比如交易记录、推送已收到、推送已阅)
- person (str) – 顾客id
- time (int) – 单位是小时,测试开始时计时。该数据从时间点 t=0 开始
- value - (dict of strings) – 推送的id 或者交易的数额
3 项目定义
3.1 问题描述
本项目的基本任务是通过分析客户的统计信息、移动 App 上的交易信息,以及促销广告信息,来对星巴克的顾客进行细分,从而识别特定客户群的推送喜好、并使用这些推送来激发顾客消费。所以本项目的研究问题是:
如何锁定星巴克目标客户并定向推送其感兴趣的信息以促进消费?
3.2 解决思路
3.2.1 锁定目标客户
如图所示,包含在transcript.json中的用户行为可以可以根据推送状态分位以上几种。其中接收到推送且在时限内产生消费的被定义为目标客户(target customer),是本项目作为模型训练集的客户群体;而没有任何激励就有购买记录的被称为韭菜客户,这类客户将在训练集中被标注为不需任何推送就能产生消费的群体。

3.2.2 目标客户特征解析
同时,profile.json中记录了所有客户的特征信息,包括年龄、收入、性别、成为member的日期。根据已筛选出的目标客户和韭菜客户的特征构建量化特征表,包括清洗数据、日期数据和categorical variable转换,为下一步的模型训练做准备。
3.2.3 机器学习模型训练
利用客户特征表和客户对应的反应one-hot表(目标客户的消费行为由哪一种推送消息驱动,则在那一个推送下标‘1’,其它为‘0’),生成训练集和测试集,用机器学习分类器训练、预测并评估模型精度,形成一套能根据客户特征输入精准判定哪一类推送会对其产生消费驱动力的预估模型。
3.2.4 模型评估思路
我们可以容忍假负例(FN), 但要避免假正例(FP) , 因为我们不一定必须找出所有对星巴克推送感兴趣的客户,但要防止把推送发给不感兴趣的客户。结合星巴克推送问题的特点,这里将精确率(precision)作为此模型的评价指标。
4 数据分析&可视化
旨在报告有关问题的特征和计算统计量,讨论了有关数据集的特征和计算统计量,并且完整描述输⼊数据。明确了所⽤数据或输⼊的异常或特点,并构建数据可视化来更好地展⽰数据探索性分析时的发现。
4.1.1 portfolio
通过gorupby函数了解每一类推荐消息(及它的子类的占比是多少):
# portfolio exploration:offer types
df_por_stat=portfolio.groupby('offer_type').count()
这个是可视化的饼状图:
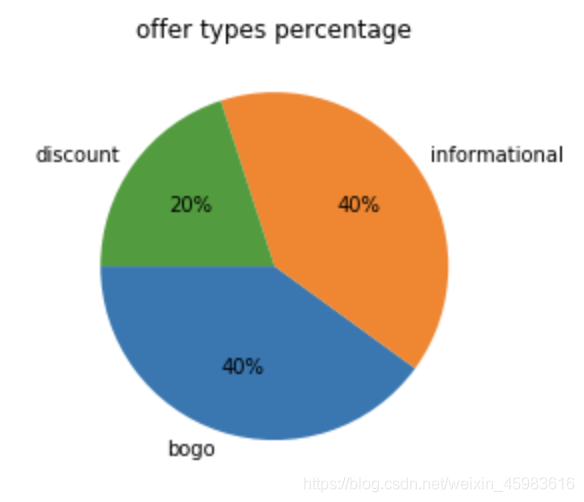
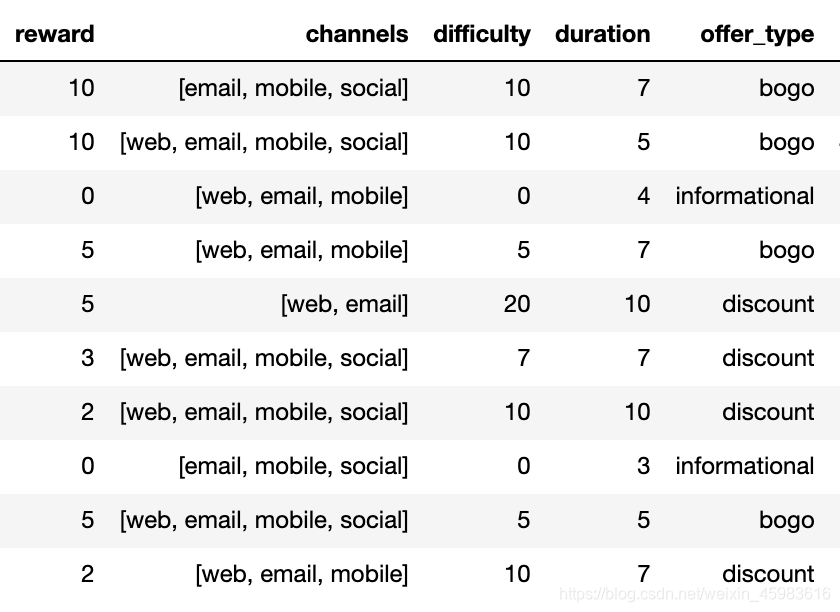
portfolio.json是一个较小的数据集,三类推送根据回馈金额、派送渠道、消费难度和有效期限进一步细化成了十类,如下表所示:
4.1.2 profile
首先由于客户信息‘became_member_on’也是潜在的消费预测特征,故这里对日期数据进行清洗(str变成日期)和计算(‘2020/06/01’为止成为member的天数),形成新的特征‘loyalty_day’。
#基于'became_member_on'计算 loyalty_day':到今天‘2020/06/01’为止成为member的天数
start_date=datetime.strptime('2020/06/01', '%Y/%m/%d')
def str_list(x):
b=str(x[0])+str(x[1])+str(x[2])+str(x[3])+'/'+str(x[4])+str(x[5])+'/'+str(x[6])+str(x[7])
return b
profile['loyalty_day']=profile['became_member_on'].apply(lambda x: str_list('a'.join(str(x)).split('a'))).apply(lambda x: str(start_date-datetime.strptime(x,'%Y/%m/%d')).split(' ')[0])
profile['loyalty_day']=profile['loyalty_day'].apply(lambda x:int(x))
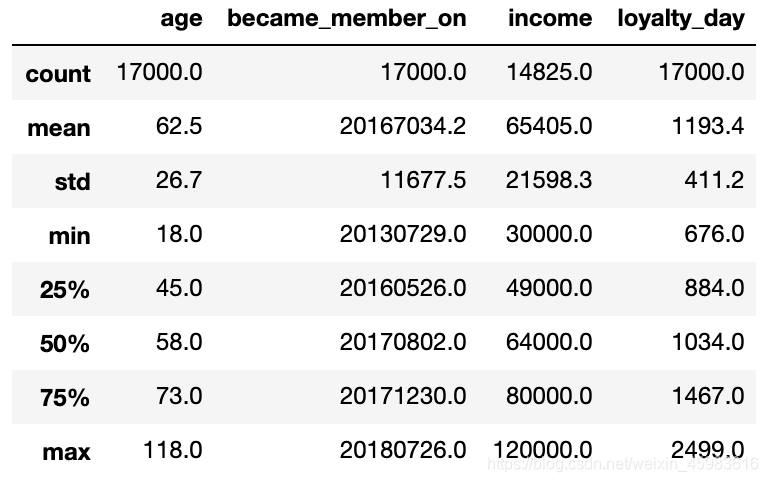
计算完毕统计一下本表的综合特征:
#综合统计用户特征
format = lambda x:'%.1f' % x
profile.describe().applymap(format)
为了进一步了解样本客户特征的分布情况,这里对年龄和收入的分布进行可视化:
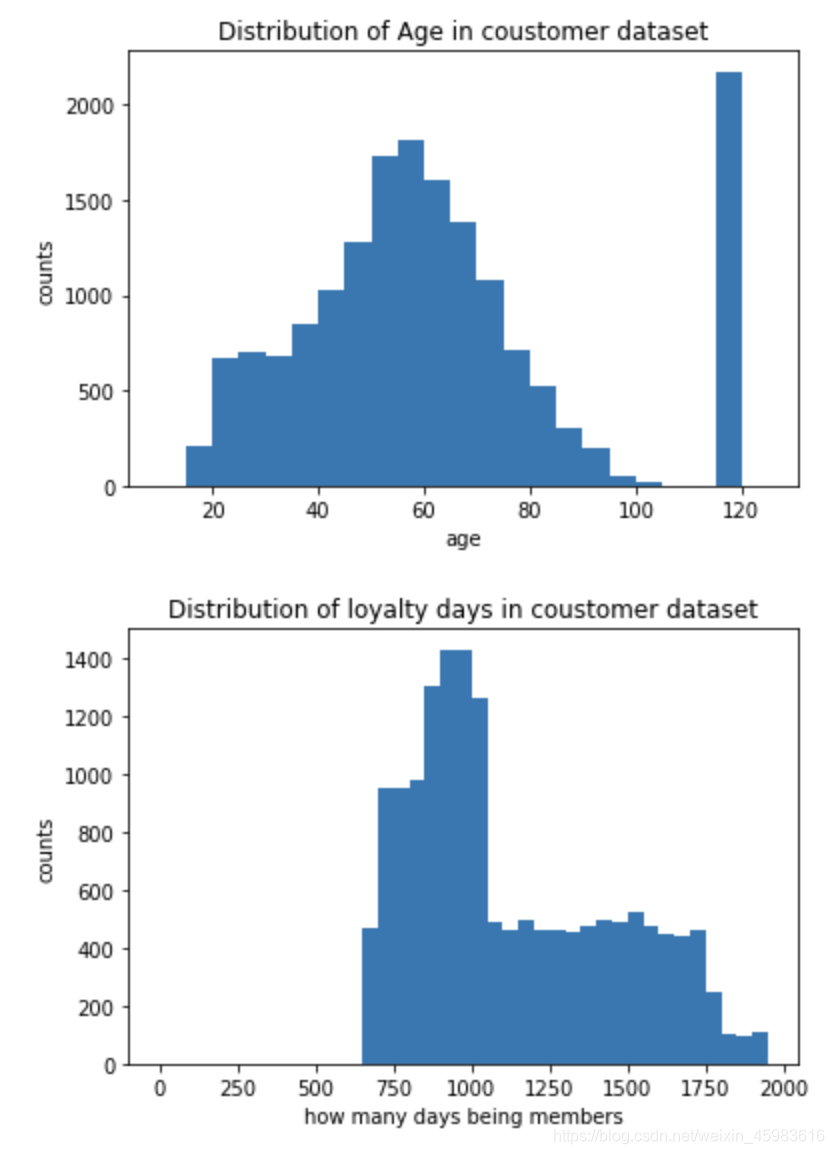
基于年龄分布图和统计表可以发现,有超过2000个用户年龄大于110岁,以下为进一步精确信息:
print('profile中用户信息没有重复:{}'.format(profile.shape[0]==len(profile.person.unique())))
print('总共有 {} 人登记年龄超过110岁'.format(len(np.where(profile['age']>110)[0])))
##results
>> profile中用户信息没有重复:True
>> 总共有 2175 人登记年龄超过110岁
因为年龄也会作为本项目的重要训练特征,所以这里删除这2175人的记录:
profile['age_error']=np.where(profile['age']>110,np.nan,1)
profile=profile.dropna(axis=0)
4.1.3 transcript
#plot the distribution of offers in datasets.
df_tg=transcript.groupby('event')[['person']].count()
这是event数据的分布图:
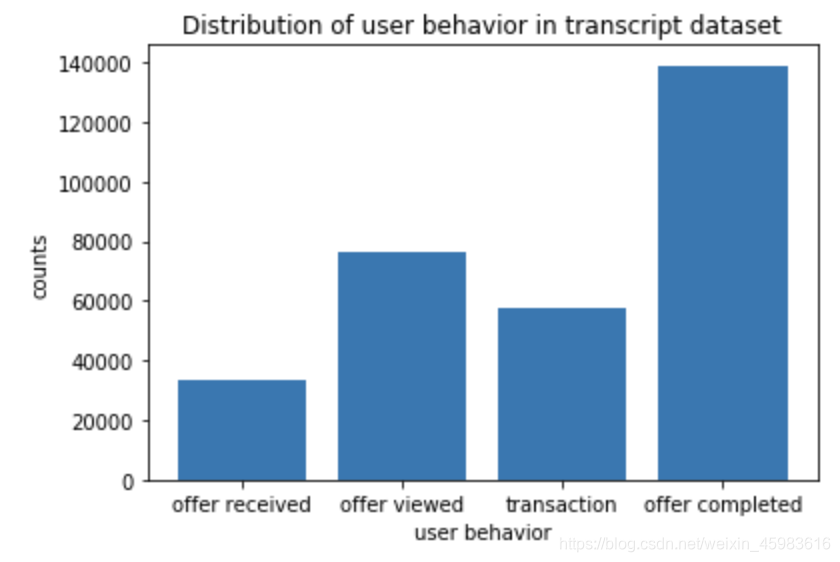
我们将在下一部分构建训练集时讨论如何利用event数据锁定产生消费且受推送影响的客户群。
5 机器学习模型搭建
5.1 数据集预处理
5.1.1 目标客户数据筛选&预处理
如图所示,我们需要清洗收到推送、在有效期内看了、且在有效期内消费了的用户群数据,作为目标客户训练数据输入模型:
- 首先合并portfolio和transcript生成新表,筛选已读用户
- 筛选产生消费的事件与已读事件合并为新表,保留已读且消费的客户数据
- 筛选出消费行为在已读行为之后的客户数据
- 筛选出有效期限内产生消费的客户数
- 整理消费金额数据,将其提取出字典作为可计算变量
在这一步产生124173条潜在可利用数据。
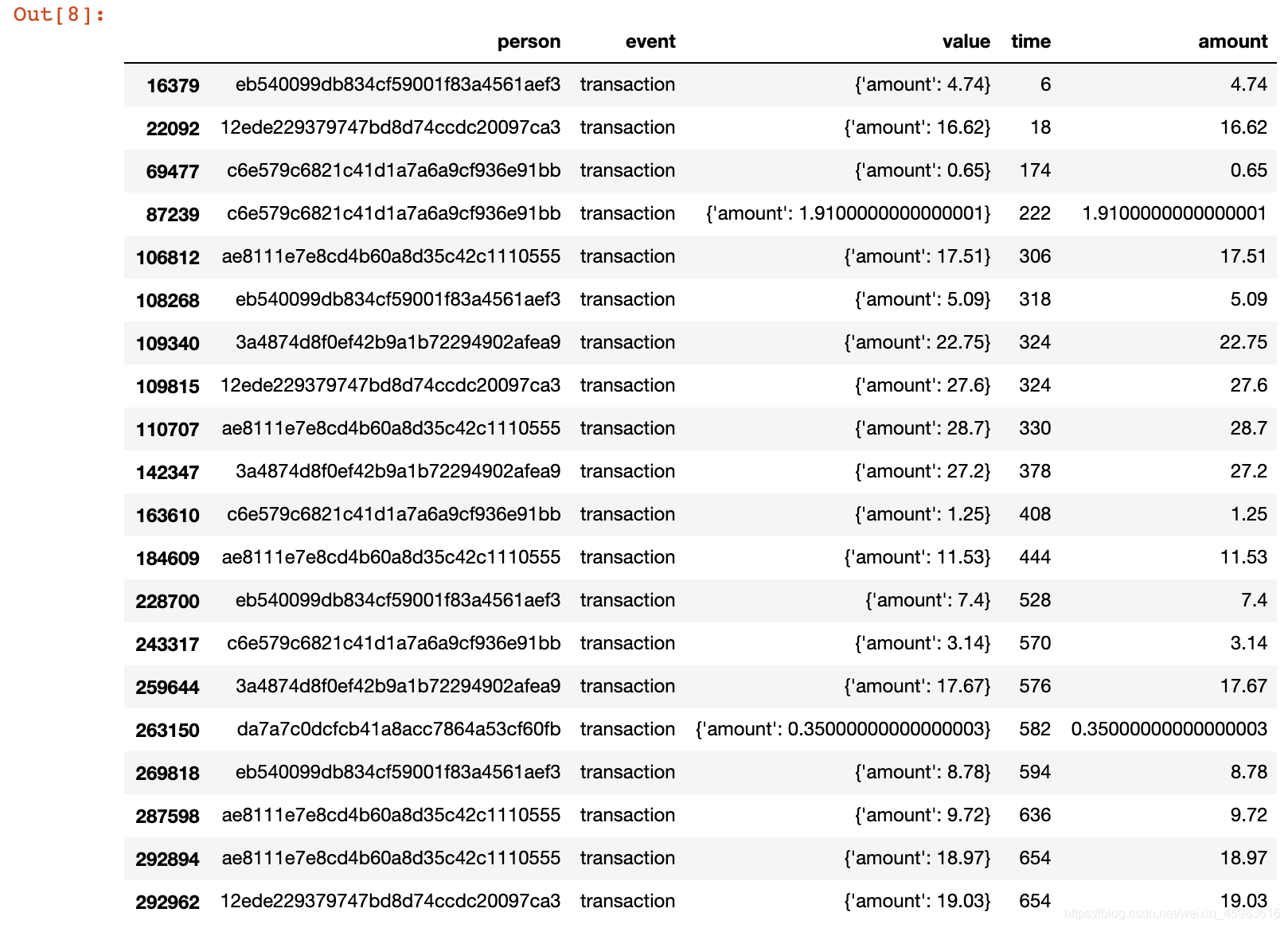
5.1.2 韭菜客户数据筛选&预处理
这一步清洗没收到推送or没被推送、且消费了的用户群数据(韭菜客户),基本实现的代码原理同目标客户筛选方式相同,筛选结果如下图。结果显示韭菜客户的数据量非常少,这一类客户在训练模型中三个target(bogo、discount、infomational)全被标记为‘0’。
5.1.3 训练集数据清洗
5.1.1和5.1.2部分完成了训练样本的筛选,这一部分合并两类sample为一个训练数据表,并对每个sample进行target标注。数据清洗步骤为:
- 合并两类客户sample成为一个pd.DataFrame
- 将数据中的categorical variable(i.e. ‘offer_type’,‘gender’)转化为one-hot 表格格式,这里用get_dummies函数实现
df_training_dummy=pd.get_dummies(df_training_frame, dummy_na=False,
columns=['offer_type','gender'], drop_first=False).drop(['gender_O','age_error'],axis=1)
- 去除用户特征中含nan值的sample,对于taget标注中出现的nan值.fillna(0)。
5.2 模型搭建、训练和评估
本模型旨在运用随机森林算法根据客户特征(年龄、性别、收入、加入会员的时长)来预测客户对某一种推送是否会有激励反应(bogo、discount、informational)。本模型通过sklearn.metrics.classification_report打印模型评估报告,对本课题来说,准确预测target的‘1’是充要任务(预测100个客户对推送感兴趣,其中有80个真实产生消费是关键任务,毕竟预测错了也只是多发了推送而已,仅产生边际损失),而对‘0’的准确预测并不是特别重要(就目前的数据量也无法完整地筛选出所有的目标客户)。换句话来说,在本次试验中precision是比recall重要很多模型评估参数,故本模型以precision分数作为评价标准。
5.2.1 多分类器模型尝试
在运用随机森林算法作为分类器之前,本项目也平行尝试了多款常用分类器:
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier,AdaBoostClassifier
from sklearn.multioutput import MultiOutputClassifier
其中DecisionTreeClassifier和KNeighborsClassifier的基础设置尝试能使平均精确度达到0.6左右、处理速度较快,在正规商业级项目中十分值得对它们做更多参数调优尝试。SVM的RBF模式下对测试集的分类精度仅达到0.4,故并不适用于本业务场景,不做讨论。和随机森林同作为集成模型热门分类器的AdaBoostClassifier在本业务场景下的默认设置表现的十分糟糕(precision<0.3),并不适用于本业务场景也不做讨论。
RandomForestClassifier是机器学习分类器中的‘多面手’,不需要非常多的设置就能‘暴力’分类出较优的结果,在上文也提到过,target标注数据有少量缺省值,而随机森林对这一类问题的包容性很高。随机森林的基础设置对discount和bogo的分类均能达到0.7左右的精度,接下来对对个别参数进行调优。
5.2.2 随机森林分类器
本模块实现随机森林实现功能并得到evaluation report,观察随机森林如下设置的分类情况:
- n_estimators=500
- n_jobs=2
- oob_score=True
- min_samples_split=50
- class_weight=‘balanced’
随机森林的分类机制:每棵决策树都是一个分类器,那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出。所以这里可以较为简单地认为,estimator的数量越多,决策对噪音的灵敏度较低。本项目尝试了[50,100,200,500,700]的分类器个数,最终发现n_estimators=500 能产生最大精度。 n_jobs是并行工作量,默认值为1这边进行翻倍以达到简易提速的效果。oob_score这边设置为True,旨在希望模型运用袋外样本来泛化精度,从而提升模型泛化能力。这里class_weight从不考虑targrt权重改成’balanced’模式,在训练集清洗时也讨论过,我们的训练数据中一个充要条件是客户产生消费,而看到informational数据产生消费的记录远远低于看到discount和bogo产生消费的记录,所以在target标注中‘informational’==1的情况十分稀少,这里利用’balanced’模式给target class增加对应的权重。对决策树剪枝的相应参数这里仅考虑了min_samples_split,默认值是2,这里改成50以求获得更具泛化能力的模型。
值得注意的是,划分训练集与测试集时本项目测试集的比例为5%,因为仅看到informational推送就产生消费的客户群远少于bogo与discount,所以多分布一些训练集以求得到稳健的模型去预测。划分训练与测试集的代码如下:
X=df_training_dummy[['age','income','gender_F','gender_M','loyalty_day']]
Y=df_training_dummy[['offer_type_bogo', 'offer_type_discount', 'offer_type_informational']]
X_train, X_test, Y_train, Y_test = train_test_split(X, Y,test_size=0.05)
5.2.3 结果
下图为打印出来的模型预测的精度:可以看到效果一般。RandomForestClassifier的分类器对bogo和discount的预测准确度勉强合格(bogo=0.7;discount=0.82),可能归结于训练集中有购买倾向的客人受bogo和discount的正向影响较大。同时,结果发现模型对informational的预测精度十分差(precision=0.23),但recall率却较高,说明对informational的positive case预测准确率还是可以的。informational预测精度极低的原因可能有两点:1)informational相应的训练集较少;2)无法通过现有客户特征模拟出看到消息类推送就会发生购买行为的特征模型。
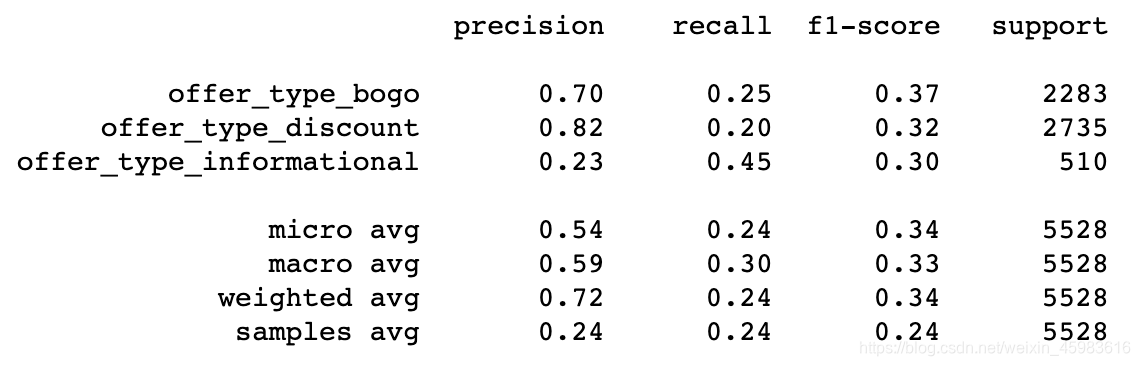
由此可以推断,模型的过拟合度较低、鲁棒性较好,但由于数据量不足和硬件训练资源不足(调参优化程度有限)等客观原因导致一些不理想的精度。
3.5 结论
3.5.1 反思
本项目利用随机森林模型,把目标客户的年龄、收入、性别和成为member的日期天数作为训练集特征,构建了机器学习模型去预测某一客户对哪一种推送会产生消费反应,从而定向地向这一类客户推送消息。由于训练数据有限、计算资源有限、模型对不同推送消息的预测精度有待提高。本项目的工作流程可以总结为:
- 初步观摩客户信息、推送信息和系统记录event,了解样本数量和质量;
- 对输入数据变量进行解析和理解;
- 定义项目目标:如何锁定星巴克目标客户并定向推送其感兴趣的信息以促进消费?
- 根据目标分解解决思路,提出初版解决方案;
- 根据项目目标对输入数据进行统计分析和可视化,以甄别和处理问题数据、优化数据结构;
- 锁定目标样本数据并清洗整理成训练集;
- 多款分类器尝试评估合适选项;
- 确定随机森林分类器并进行模型调优;
- 生成预测结果和validation结果,计算precision进行模型评估。
本项目十分贴近真实business analysis 的场景,其中消费劵有期限和消费者是否看到消费劵产生消费行为的数据清洗让我觉得十分有挑战性,也是让我最获益匪浅的地方。
3.5.2 改进
由于电脑算力有限,无法进行最优参数组合的网格搜索算法,这是一个潜在导致分类精度不佳的原因;且本模型并没有过多考虑剪枝优化,故这里将调优组合参数设置如下:
parameters = {'n_estimators': [100, 200,350,500],'min_samples_split': [2,.01,.1,.5,.8],
'class_weight':['balanced',None],'max_features':['auto','log2',None],
'max_leaf_nodes':[None,10,50,100,200]}
其中max_features是寻找最佳分割时考虑的最大特征量,其定义较为黑盒,故需要尝试多种情况;以最优的方法使用max_leaf_nodes来生长树,最好的节点被定义为不纯度上的相对减少(如果为None,那么不限制叶子节点的数量)。
参考博客:
[1]:https://blog.csdn.net/weixin_41988628/article/details/83098130
[2]: https://blog.csdn.net/JohnsonSmile/article/details/88801246?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522159141725919724848359610%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=159141725919724848359610&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_click~default-2-88801246.nonecase&utm_term=DecisionTreeClassifier
[3]: https://blog.csdn.net/yangyin007/article/details/82385967
[4]: https://blog.csdn.net/edogawachia/article/details/79357844

















 284
284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









