



 本文详细介绍了SpringBoot的优特点,包括快速构建独立应用、自动化配置、内嵌web服务器等。内容涵盖SpringBoot2的入门步骤,如Maven配置、搭建、测试,以及配置文件值注入、YAML语法、目录结构、核心注解、Web开发(Thymeleaf模板引擎)、日志系统、项目属性配置、全局异常处理、自定义异常、数据统一响应、MyBatis/MyBatis-Plus集成、事务配置管理、使用拦截器、集成Redis和Shiro等方面,旨在全面解析SpringBoot的使用和实战技巧。
本文详细介绍了SpringBoot的优特点,包括快速构建独立应用、自动化配置、内嵌web服务器等。内容涵盖SpringBoot2的入门步骤,如Maven配置、搭建、测试,以及配置文件值注入、YAML语法、目录结构、核心注解、Web开发(Thymeleaf模板引擎)、日志系统、项目属性配置、全局异常处理、自定义异常、数据统一响应、MyBatis/MyBatis-Plus集成、事务配置管理、使用拦截器、集成Redis和Shiro等方面,旨在全面解析SpringBoot的使用和实战技巧。
1、SpringBoot优点
Create stand-alone Spring applications
创建独立Spring应用
Embed Tomcat, Jetty or Undertow directly (no need to deploy WAR files)
内嵌web服务器
Provide opinionated 'starter' dependencies to simplify your build configuration
自动starter依赖,简化构建配置
Automatically configure Spring and 3rd party libraries whenever possible
自动配置Spring以及第三方功能
Provide production-ready features such as metrics, health checks, and externalized configuration
提供生产级别的监控、健康检查及外部化配置
Absolutely no code generation and no requirement for XML configuration
无代码生成、无需编写XML
2、SpringBoot2入门
2.1、配置好 maven
2.2、搭建boot
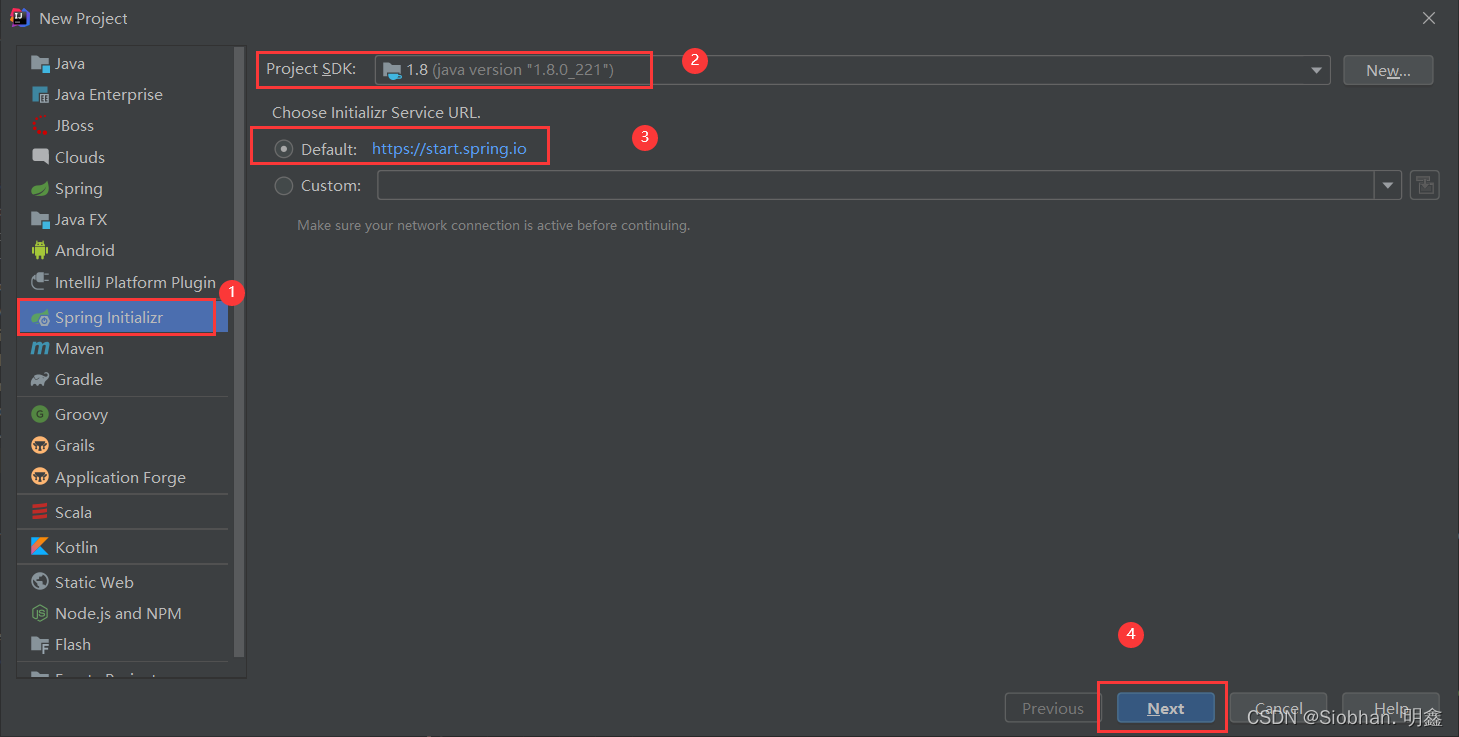
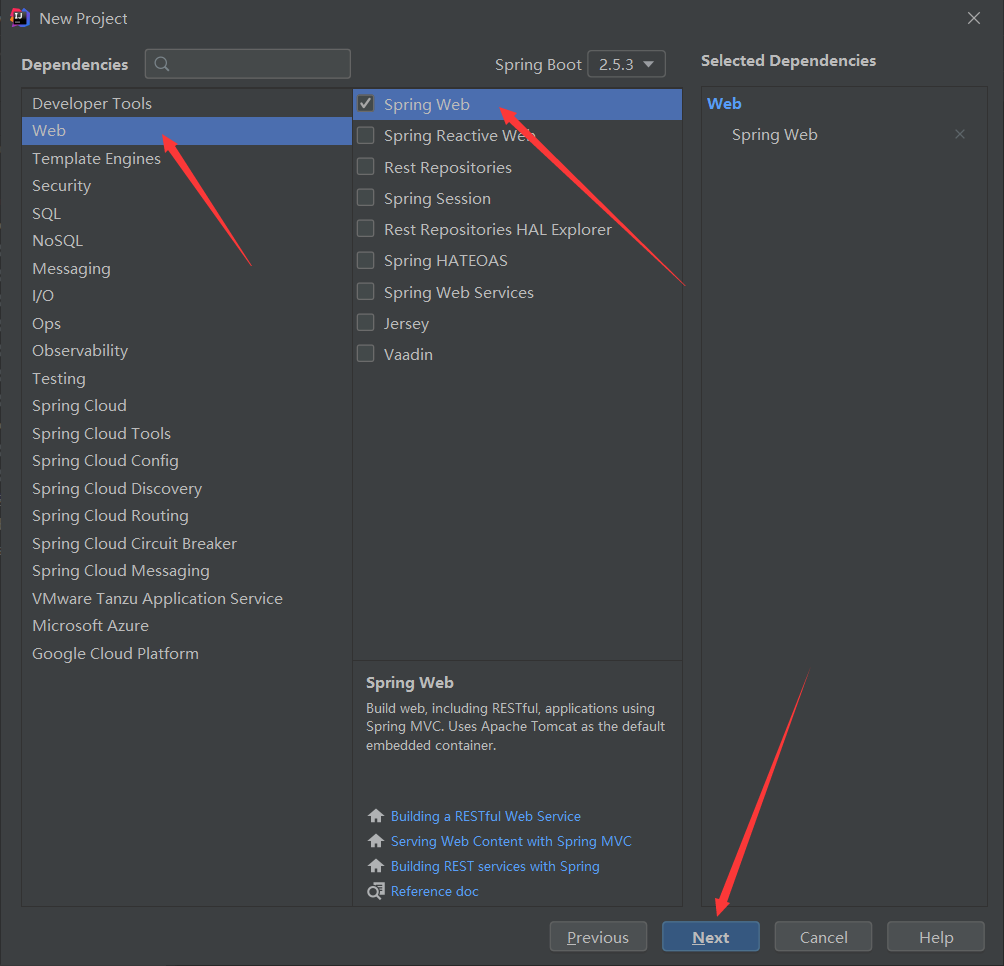
2.3、测试
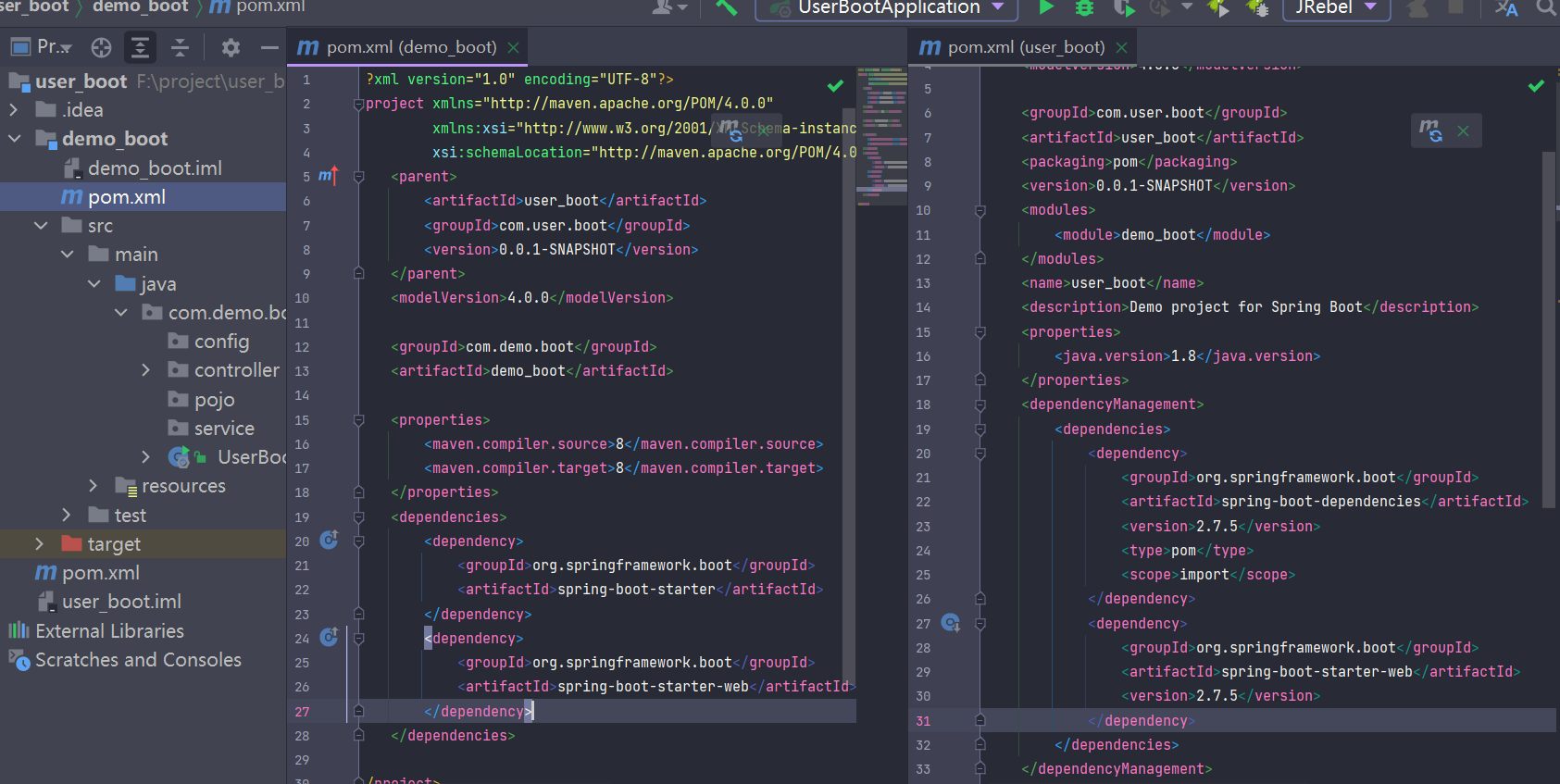
2.3.1、引入依赖 (测试版)
父项目:负责管理管理,控制版本
子项目:不用设置版本号
<!--fu-->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.7.5</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.24</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- 配置文件处理器,配置文件进行绑定就会有提示,让有些注解生效-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
</dependencyManagement><!--zi-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<!--配置文件处理器,配置文件进行绑定就会有提示,让有些注解生效-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
</dependency>2.3.2、配置文件 (测试)
application.yml
server:
# 配置tomcat的端口号 默认是8080
port: 80802.3.3、创建HelloWorld测试
需求:浏览发送/hello请求,响应 Hello,Spring Boot 2
2.3.4、创建主程序 启动类
@SpringBootApplication
public class UserSpringBootApplication {
public static void main(String[] args) {
SpringApplication.run(UserSpringBootApplication.class, args);
}
}2.3.5、编写业务 Controller层
@RestController
public class HelloController {
@RequestMapping("/hello")
public String handle01(){
return "Hello, Spring Boot 2!";
}
}2.4、配置文件值注入
//只有这个组件是容器中的组件,才能使用容器提供的@ConfigurationProperties功能
//@ConfigurationProperties告诉springboot将本类中的所有属性和配置文件中相关的配置进行绑定
//prefix表示与配置文件中哪个下面的所有属性进行映射
@Component
//prefix里面的配置只能小写
@ConfigurationProperties(prefix ="userpo")
//不能起名User,否则会拿到 user.getName() 只会拿到电脑的用户名
@Data
public class UserPO {
private int age;
private String name;
}<!-- 配置文件处理器,配置文件进行绑定就会有提示-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
</dependency>避免application.properties的配置太多可以新建配置文件来进行值的注入
即:userpro.properties 文件配置
UserPro.name=boot
UserPro.age=24@PropertySource和@importResource(重点)
value是字符串数组可以同时支持多个配置文件用逗号隔开;
//只有这个组件是容器中的组件,才能使用容器提供的@ConfigurationProperties功能
//@ConfigurationProperties告诉springboot将本类中的所有属性和配置文件中相关的配置进行绑定
//prefix表示与配置文件中哪个下面的所有属性进行映射
@Component
//prefix里面的配置只能小写
@ConfigurationProperties(prefix ="userpro")//重点
@PropertySource("classpath:user.properties")//重点
@Data
public class UserPro {
private int age;
private String name;
}spring配置文件beans.xml
<bean id="getUser" class="com.demo.boot.service.User"></bean>@importResource:导入spring的配置文件.让配置文件生效;
我们编写的spring配置文件需要导入才能生效;
@importResource:标识在配置类上location也是一个字符串数组
@ImportResource(locations = {"classpath:beans.xml"})
@SpringBootApplication
public class UserBootApplication {
public static void main(String[] args) {
SpringApplication.run(UserBootApplication.class, args);
}
}springBoot推荐的给容器添加组件的方式;推荐使用全注解的方式(使用配置类)
//表明这是配置类,springboot会扫描这个类,将它的组件加入容器
@Configuration
public class UserProConfig {
@Autowired
private UserPro userPro;
//将方法的返回值加入到容器中,容器中的组件名默认为方法名
@Bean
public User getUser() {
System.out.println("加入成功");
System.out.println(userPro);
return new User();
}
}结果: UserPro.name=bootUserPro.age=24
3、配置文件解析
3.1、配置文件
springBoot使用一个全局配置文件,配置文件名字是固定的;
application.properties;
application.yml
配置文件的作用:对springBoot的自动配置哪里不满意可以修改springBoot的自动配置;
application.yml
#自定义常量
#file:
#COS访问域名
# URL: https://chain-1313314084.cos.ap-shanghai.myqcloud.com/
#图片上传路径
# uploadURL: bilibili/userImages/
# search: https://chain-1313314084.cos.ap-shanghai.myqcloud.com/
# localURL: C:\Users\ASUS\Desktop\images\
server:
# 配置tomcat的端口号 默认是8080
port: 8080
spring:
datasource:
# //43.142.172.23 云端服务器
# url: jdbc:mysql://43.142.172.23:3306/boot?
url: jdbc:mysql://ljdbc:mysql://localhost:3306/boot?
serverTimezone=UTC&characterEncoding=UTF-8
username: root
password: 123456
servlet:
multipart:
max-request-size: 500MB
max-file-size: 500MB
thymeleaf:
cache: false
encoding: UTF-8
redis:
#linux 安装Redis的主机 ip地址 192.168.159.130
host: 192.168.159.130
port: 6379
database: 0
password: 123456
timeout: 30000
mybatis:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: true
mapper-locations: classpath:mapper/*.xml
type-aliases-package: com.lanou.bilibili.domain
pagehelper:
helperDialect: mysql
reasonable: true
supportMethodsArguments: true
params: count=countSql
3.2、YAML语法
1.格式
(空格):属性和值之间必须有空格;
1、大小写敏感
2、使用缩进表示层级关系
3、禁止使用tab缩进,只能使用空格键
4、缩进长度没有限制,只要元素对齐就表示这些元素属于一个层级。
5、使用#表示注释
6、字符串可以不用引号标注
2.写法
server:
port: 8081
#值的写法
#字面量:数字,字符串,布尔
name:lisi
#对象:Map:
age : 12
name : huang
#行内写法:
{age:12,name:huang}
#list,数组 :
[a,b,c]
#或者
ch:
- a
- b
- c
#对象里面嵌套对象:
Userpo:
age: 15
name: zhangsan
son:
age: 1
name: lisi
#list嵌套list:
lang:
-
- Ruby
- Perl
- Python
-
- c
- c++
- java
#list嵌套map
man:
-
id: 1
name: huang
-
id: 2
name: liao3.2.1、profile
profile为spring对不同环境提供不同功能的支持
1.使用application.{profile}.properties多文件配置
如:application.properties
application.dev.properties(开发环境)
application.prod.properties(生产环境)
spring.profiles.active=dev激活开发环境
2.使用application.yml可以实现单文件多环境切换
YAML中—表示文档分块只需要使用active激活所需环境即可;
server:
port: 8080
spring:
profiles:
active: dev
---
server:
port: 8082
spring:
profiles: dev
---
server:
port: 8081
spring:
profiles: prod
4、目录结构:

5、注解
@SpringBootApplication
@SpringBootApplication 注解表明该类是springBoot的主配置类,应运行该类的主方法启动SpringBoot应用
@SpringBootConfiguration
SpringBoot的配置类;
标注在一个类上,说明该类是一个springBoot的配置类;
@Configuration
配置类注解是spring的底层注解;
配置类也是一个组件;@Component
@EnableAutoConfiguration
@EnableAutoConfiguration:开启自动配置功能;
以前需要配置的东西,现在springBoot帮我们自动配置,通过这个注解开启自动配置
@AutoConfigurationPackage
自动配置包,将主配置类(@SpringBootApplication标注的类)的所在包下的所有子包内的所有组件全部加入到spring容器中;
@Import({AutoConfigurationImportSelector.class})
spring底层注解@import,给容器导入一个组件;导入的组件由AutoConfigurationImportSelector.class提供
AutoConfigurationImportSelector:决定导入哪些组件;
将所有需要导入的组件以全类名的方式返回(String【】);这些组件就会被添加到容器中;
6、web开发
6.1.模板引擎thymeleaf
1.依赖导入
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>2.Thymeleaf相关配置
Thymeleaf 中已经有默认的配置了,我们不需要再对其做过多的配置,有一个需要注意一下,
Thymeleaf 默认是开启页面缓存的,所以在开发的时候,需要关闭这个页面缓存,配置如下。
spring.thymeleaf.cache= false #关闭缓存3.thymeleaf的命名空间(加入有语法提示)
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<html lang="en">4、使用案例
后端
Spring Boot 中会自动识别模板目录(templates/)下的success.html
@Controller
public class HelloController {
@RequestMapping("/success")
public String success(Map<String,String>map) {
map.put("hello","你好");
return "success";
}前端
<div th:text="${hello}"></div>5、注意:
使用thymeleaf不能在controller层使用 @RestController注解,方法上也不能使用 @RespondBody注解,该注解会以json格式将数据还回,这样模板引擎就不能进行解析,结果就会将success直接打印到浏览器;
7、日志系统
在开发中,我们经常使用 System.out.println() 来打印一些信息,但是这样不好,因为大量的使用 System.out 会增加资源的消耗。我们实际项目中使用的是 slf4j 的 logback 来输出日志,效率挺高的,
Spring Boot 提供了一套日志系统,logback 是最优的选择。
springboot项目的最佳实践就是采用slf4j+logback;
SLF4J,即简单 日志门面(Simple Logging Facade for Java),不是具体的日志解决方案,它只 服务于各种各样的日志系统。按照官方的说法,SLF4J是一个用于日志系统的简单Facade,允许 最终用户在部署其应用时使用其所希望的日志系统。
yaml配置
logging.config 是用来指定项目启动的时候,读取哪个配置文件,这里指定的是日志配置文件是
根路径下的 logback.xml 文件,关于日志的相关配置信息,都放在 logback.xml 文件中了。 logging.level 是用来指定具体的 mapper 中日志的输出级别,上面的配置表示 com.user.boot.dao 包下的所有 mapper
日志输出级别为 trace,会将操作数据库的 sql 打印出来,开发 时设置成 trace 方便定位问题,在 生产环境上,将这个日志级别再设置成 error 级别即可
#日志配置
logging:
config: classpath:config/logback.xml
level:
com.user.boot.dao: tracelogback.xml里的配置(开发环境)
<configuration>
<property name="LOG_PATTERN" value="%date{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n"/>
<property name="FILE_PATH" value="D:/logs/ssoService/ssoService.%d{yyyy-MM- dd}.%i.log"/>
<property name="ERROR_FILE_PATH" value="D:/logs/ssoService/error/ssoServiceError.%d{yyyy-MM-dd}.%i.log"/>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder> <!-- 按照上面配置的LOG_PATTERN来打印日志 -->
<pattern>${LOG_PATTERN}</pattern>
</encoder>
</appender>
<appender name="INFO" class="ch.qos.logback.core.rolling.RollingFileAppender">
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>ERROR</level>
<onMatch>DENY</onMatch> <!-- 如果命中就禁止这条日志 -->
<onMismatch>ACCEPT</onMismatch> <!-- 如果没有命中就使用这条规则 -->
</filter>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <!-- 按照上面配置的FILE_PATH路径来保存日志 -->
<fileNamePattern>${FILE_PATH}</fileNamePattern> <!-- 日志保存15天 -->
<maxHistory>15</maxHistory>
<timeBasedFileNamingAndTriggeringPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"> <!-- 单个日志文件的最大,超过则新建日志文件存储 -->
<maxFileSize>10MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
</rollingPolicy>
<encoder> <!-- 按照上面配置的LOG_PATTERN来打印日志 -->
<pattern>${LOG_PATTERN}</pattern>
</encoder>
</appender>
<!-- error日志 -->
<appender name="ERROR" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 过滤日志 -->
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>ERROR</level>
</filter>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <!-- 按照上面配置的FILE_PATH路径来保存日志 -->
<fileNamePattern>${ERROR_FILE_PATH}</fileNamePattern> <!-- 日志保存15天 -->
<maxHistory>14</maxHistory>
<timeBasedFileNamingAndTriggeringPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"> <!-- 单个日志文件的最大,超过则新建日志文件存储 -->
<maxFileSize>10MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
</rollingPolicy>
<encoder> <!-- 按照上面配置的LOG_PATTERN来打印日志 -->
<pattern>${LOG_PATTERN}</pattern>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="INFO"/>
<appender-ref ref="ERROR"/>
</root>
</configuration>logback-pro.xml里的配置(生产环境)
<configuration>
<property name="LOG_PATTERN" value="%date{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n"/>
<property name="FILE_PATH" value="/data/logs/ssoService/ssoService.%d{yyyy-MM- dd}.%i.log"/>
<property name="ERROR_FILE_PATH" value="/data/logs/ssoService/error/ssoServiceError.%d{yyyy-MM-dd}.%i.log"/>
<!--正式环境-->
<!--<property name="FILE_PATH" value="/data/logs/draw.%d{yyyy-MM- dd}.%i.log"/>-->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder> <!-- 按照上面配置的LOG_PATTERN来打印日志 -->
<pattern>${LOG_PATTERN}</pattern>
</encoder>
</appender>
<appender name="INFO" class="ch.qos.logback.core.rolling.RollingFileAppender">
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>ERROR</level>
<onMatch>DENY</onMatch> <!-- 如果命中就禁止这条日志 -->
<onMismatch>ACCEPT</onMismatch> <!-- 如果没有命中就使用这条规则 -->
</filter>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <!-- 按照上面配置的FILE_PATH路径来保存日志 -->
<fileNamePattern>${FILE_PATH}</fileNamePattern> <!-- 日志保存15天 -->
<maxHistory>15</maxHistory>
<timeBasedFileNamingAndTriggeringPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"> <!-- 单个日志文件的最大,超过则新建日志文件存储 -->
<maxFileSize>10MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
</rollingPolicy>
<encoder> <!-- 按照上面配置的LOG_PATTERN来打印日志 -->
<pattern>${LOG_PATTERN}</pattern>
</encoder>
</appender>
<!-- error日志 -->
<appender name="ERROR" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 过滤日志 -->
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>ERROR</level>
</filter>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <!-- 按照上面配置的FILE_PATH路径来保存日志 -->
<fileNamePattern>${ERROR_FILE_PATH}</fileNamePattern> <!-- 日志保存15天 -->
<maxHistory>14</maxHistory>
<timeBasedFileNamingAndTriggeringPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"> <!-- 单个日志文件的最大,超过则新建日志文件存储 -->
<maxFileSize>10MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
</rollingPolicy>
<encoder> <!-- 按照上面配置的LOG_PATTERN来打印日志 -->
<pattern>${LOG_PATTERN}</pattern>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="INFO"/>
<appender-ref ref="ERROR"/>
</root>
</configuration>测试代码:
private final static Logger logger = LoggerFactory.getLogger(HelloController.class);
@RequestMapping("logger")
//测试日志
public String testLogger() {
logger.debug("debug测试");
logger.info("info 测试");
logger.error("error 测试");
logger.warn("warn测试");
//占位符
String s1="hahaha";
String s2="hehehe";
logger.info("我{};你{}", s1, s2);
return "success";
}打印参数必须使用{};
8、项目属性配置
1、少量配置
在微服务架构中,最常见的就是某个服务需要调用其他服务来获取其提供的相关信息,那么 在该服务的配置文件中需要配置被调用的服务地址,比如在当前服务里,我们需要调用订单微服务获取 订单相关的信息,假设 订单服务的端口号是 8002,那我们可以做如下配置:
# 配置微服务的地址
url:
# 订单微服务的地址
orderUrl: http://localhost:8002 @Value("${url.orderUrl}")
private String orderUrl;
@RequestMapping("/config")
public String testUrl() {
logger.info("orderUrl:{}",orderUrl);
return "success";
}2、多个配置
随着业务复杂度的增加,一个项目中可能会有越来越多的微服务,某个模块可能 需要调用多个微服务获取不同的信息,那么就需要在配置文件中配置多个微服务的地址。可是,在需要 调用这些微服务的代码中,如果这样一个个去使用 @Value 注解引入相应的微服务地址的话,太过于繁 琐,也不科学。
所以,在实际项目中,业务繁琐,逻辑复杂的情况下,需要考虑封装一个或多个配置类。举个例子:假 如在当前服务中,某个业务需要同时调用订单微服务、用户微服务和购物车微服务,分别获取订单、用 户和购物车相关信息,然后对这些信息做一定的逻辑处理。那么在配置文件中,我们需要将这些微服务 的地址都配置好:
例子:
yaml配置:
# 配置多个微服务的地址
url:
# 订单微服务的地址
orderUrl: http://localhost:8002
# 用户微服务的地址
userUrl: http://localhost:8003
# 购物车微服务的地址
shoppingUrl: http://localhost:8004配置类:
省去get,set方法;
@Component
@ConfigurationProperties(prefix = "url")
public class MicroServiceUrl {
private String orderUrl;
private String userUrl;
private String shoppingUrl;
}测试类:
@Resource
private MicroServiceUrl microServiceUrl;
@RequestMapping("urls")
public String testConfig() {
logger.info("OrderUrl{}",microServiceUrl.getOrderUrl());
logger.info("userUrl{}",microServiceUrl.getUserUrl());
logger.info("shoppingUrl{}",microServiceUrl.getShoppingUrl());
return "success";
}@ConfigurationProperties和@Resource(注解详情
使用@ConfigurationProperties 注解并且使用 prefifix 来指定一个前缀, 然后该类中的属性名就是 配置中去掉前缀后的名字,一 一 对应即可。
即:前缀名 + 属性名 就是配置文件 中定义的 key。
同时,该类上面需 @Component 注解,把该类作为组件放到Spring容器中,让 Spring 去管理,我们使用的时候直接注入即可。
@Resource(这个注解属于J2EE的),默认安照名称进行装配,名称可以通过name属性进行指定,
如果没有指定name属性,当注解写在字段上时,默认取字段名进行按照名称查找,如果注解写在setter方法上默认取属性名进行装配。
找不到与名称匹配的bean时才按照类型进行装配。
但是需要注意的是,如果name属性一旦指定,就只会按照名称进行装配。
推荐使用:@Resource注解在字段上,且这个注解是属于J2EE的,减少了与spring的耦合。最重要的这样代码看起就比较优雅。
集成 Swagger3
Swagger2依赖
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.9.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/io.springfox/springfox-swagger-ui -->
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.9.2</version>
</dependency>9.1、Swagger3简介
API构建工具
优点:
对使用接口的人 来说,开发人员不需要给他们提供文档,只要告诉他们一个 Swagger 地址,即可展示在线的 API 接口 文档,除此之外,调用接口的人员还可以在线测试接口数据,同样地,开发人员在开发接口时,同样可以利用 Swagger 在线接口文档测试接口数据,这给开发人员提供了便利。
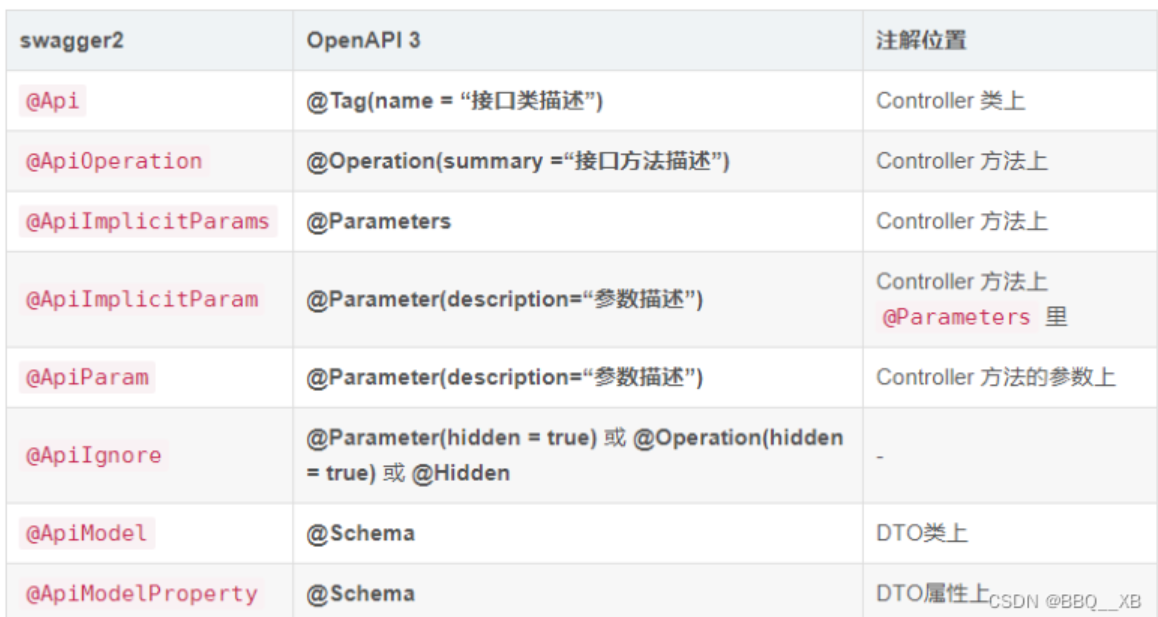
常用注解
9.2 、Swagger3的使用:
9.2.1、maven导入依赖
springboot项目整合swagger要注意两者的版本,springboot项目的版本低,相应的swagger版本不能太高,反之亦然,避免项目报如下错误。
Parameter 0 of method linkDiscoverers in org.springframework.hateoas.config.HateoasConfiguration required a single bean, but 15 were found:
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-boot-starter</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-spring-boot-starter</artifactId>
<version>3.0.2</version>
</dependency>9.2.2、application.yml 配置
启动报 Failed to start bean ‘documentationPluginsBootstrapper’; nested exception is信息报错原因:由于Spring Boot 2.6.x 请求路径与 Spring MVC 处理映射匹配的默认策略从AntPathMatcher更改为PathPatternParser。所以需要设置spring.mvc.pathmatch.matching-strategy为ant-path-matcher来改变它。
加入如下配置:
spring:
profiles:
active: test
# ===== 避免springboot 版本和 swagger版本不一致报错 ===== #
mvc:
pathmatch:
matching-strategy: ant_path_matcher
knife4j:
production: false
enable: true9.2.3、Swagger的配置类
@Configuration
@EnableOpenApi
public class SwaggerConfig {
//Swagger实例Bean 是Docket,所以通过配置Docket实例来 配置Swagger
@Bean
public Docket docket(Environment environment) {
// 设置要显示swagger的环境
Profiles of = Profiles.of("dev", "test");
// 判断当前是否处于该环境
// 通过 enable() 接收此参数判断是否要显示
boolean b = environment.acceptsProfiles(of);
return new Docket(DocumentationType.SWAGGER_2)
//通过apiInfo()属性配置文档信息
.apiInfo(apiInfo())
//配置是否启用Swagger,如果是false,在浏览器将无法访问
.enable(b)
// 配置分组
.groupName("lc")
// 通过.select()方法,去配置扫描接口
.select()
// RequestHandlerSelectors 配置如何扫描接口(包路径)
.apis(RequestHandlerSelectors.basePackage("com.demo.boot.controller"))
// 配置接口扫描过滤: 通过.any() 扫描所有,项目中的所有接口都会被扫描到
.paths(PathSelectors.any())
.build();
}
private ApiInfo apiInfo() {
return new ApiInfoBuilder()
.title("学生管理系统")
.description("这是一个学生管理系统")
.contact(new Contact("lc", "http://localhost:8088", "作者Email"))
.version("3.0")
.build();
}
}9.2.4、Controller层
package com.demo.boot.controller;
import com.demo.boot.mapper.StudentMapper;
import com.demo.boot.pojo.Student;
import com.demo.boot.vo.Result;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.Parameter;
import io.swagger.v3.oas.annotations.Parameters;
import io.swagger.v3.oas.annotations.tags.Tag;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/stu")
@Tag(name = "学生信息管理", description = "学生数据增删改查")
public class StudentController {
@Autowired
private StudentMapper studentMapper;
@Operation(summary = "新增学生")
@Parameters({@Parameter(name = "param", description = "学生信息")})
@PostMapping("/save")
public Result saveStudent(@Parameter(description = "学生对象", required = true)
@RequestBody Student param) {
Result result = new Result();
int i = studentMapper.insert(param);
result.setStatus(1);
result.setData(i);
return result;
}
@Parameters({@Parameter(name = "id", description = "学生id")})
@Operation(summary = "删除学生", description = "删除学生信息")
@DeleteMapping("/delete")
public Result deleteStudent(@RequestBody Integer id) {
Result result = new Result();
int i = studentMapper.deleteById(id);
result.setStatus(1);
result.setData(i);
return result;
}
@Parameters({@Parameter(name = "param", description = "学生对象")})
@Operation(summary = "更新学生", description = "更新学生信息")
@PutMapping("/update")
public Result updateStudent(@RequestBody Student param) {
Result result = new Result();
int i = studentMapper.updateById(param);
result.setStatus(1);
result.setData(i);
return result;
}
@Parameters({@Parameter(name = "id", description = "学生id")})
@Operation(summary = "查询学生", description = "查询学生信息")
@GetMapping("/get")
public Result getStudent(@RequestBody Integer id) {
Result result = new Result();
Student student = studentMapper.selectById(id);
result.setStatus(0);
result.setData(student);
return result;
}
}9.2.5、实体类
@Data
@Schema(name = "学生对象实体")
public class Student {
@Schema(description = "id",required = true,example = "001")
private long id;
@Schema(description = "姓名",required = true,example = "老6")
private String name;
@Schema(description = "年龄",required = true,example = "24")
private long age;
@Schema(description = "性别",required = true,example = "男")
private String sex;
}
@Data
@Schema(name = "状态码实体")
public class Result {
@Schema(description = "code码",required = true,example = "1 / 0")
private Integer status;
@Schema(description = "响应消息",required = true,example = "success")
private String msg;
@Schema(description = "统计",required = true,example = "10")
private long count;
@Schema(description = "响应数据",required = true,example = "json")
private Object data;
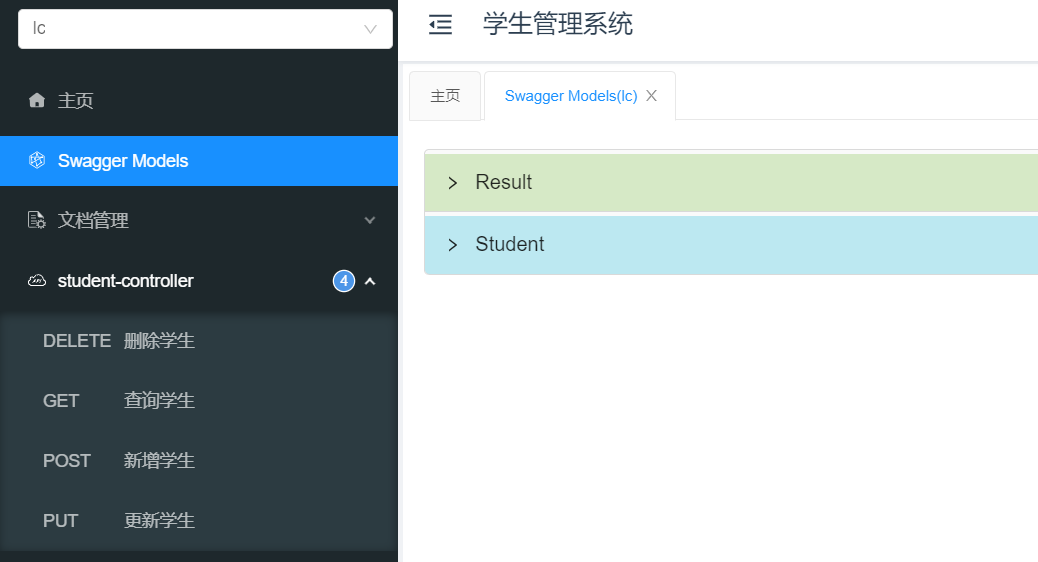
}在浏览器中输入 localhost:8088/doc.html 看一下 Swagger 页面的接口状态。
10、json格式的处理
10.1、jackson对json格式进行去null值处理
在实际项目中,我们难免会遇到一些 null 值出现,我们转 json 时,是不希望有这些 null 出现的,比如 我们期望所有的 null 在转 json 时都变成 “” 这种空字符串
1.新建一个json配置类
@Configuration
public class JsonConfig {
@Bean
@Primary
@ConditionalOnMissingBean(ObjectMapper.class)
public ObjectMapper jacksonObjectMapper(Jackson2ObjectMapperBuilder builder) {
ObjectMapper objectMapper = builder.createXmlMapper(false).build();
objectMapper.getSerializerProvider().setNullValueSerializer(new JsonSerializer<Object>() {
@Override
public void serialize(Object o, JsonGenerator jsonGenerator, SerializerProvider serializerProvider) throws IOException {
jsonGenerator.writeString("");
}
});
return objectMapper;
}
}测试类:
@RestController
@RequestMapping("/json")
public class JsonController {
@RequestMapping("/testJson")
public Map testJson() {
Map<Integer, UserPO> map=new HashMap<Integer,UserPO>();
UserPO userPO = new UserPO();
userPO.setName("lisi");
userPO.setAge(15);
map.put(1,userPO);
return map;
}
}结果:{"1":{"age":15,"name":"lisi"}}
10.2、定义统一的 json 结构
@Getter
public class JsonUtil<T> {
private T data;
private String code;
private String msg;
/*** 若没有数据返回,默认状态码为0,提示信息为:操作成功! */
public JsonUtil() {
this.code = "0";
this.msg = "操作成功!";
}
/*** 若没有数据返回,可以人为指定状态码和提示信息 * @param code * @param msg */
public JsonUtil(String code, String msg) {
this.code = code;
this.msg = msg;
}
/*** 有数据返回时,状态码为0,默认提示信息为:操作成功! * @param data */
public JsonUtil(T data) {
this.data = data;
this.code = "0";
this.msg = "操作成功!";
}
/*** 有数据返回,状态码为0,人为指定提示信息 * @param data * @param msg */
public JsonUtil(T data, String msg) {
this.data = data;
this.code = "0";
this.msg = msg;
}
}测试类:
@RestController
@RequestMapping("/json")
public class JsonController {
@RequestMapping("jsonresult")
public JsonUtil<Map> jsonresult() {
Map<Integer, UserPO> map = new HashMap<Integer,UserPO>();
UserPO userPO = new UserPO();
userPO.setName("lisi");
userPO.setAge(15);
map.put(1,userPO);
return new JsonUtil<Map>(map);
}
}
}结果:{"data":{"1":{"age":15,"name":"lisi"}},"code":"0","msg":"操作成功!"}
参数校验
一个接口一般对参数(请求数据)都会进行安全校验,参数校验的重要性自然不必多说,那么如何对参数进行校验就有讲究了。
Validator + BindResult进行校验
导入依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>Validator可以非常方便的制定校验规则,并自动帮你完成校验。首先在入参里需要校验的字段加上注解,每个注解对应不同的校验规则,并可制定校验失败后的信息:
@Data
@TableName("user")
public class User {
@TableId(value = "id",type = IdType.AUTO)
private Integer id;
@NotEmpty(message = "用户名不能为空")
@Size(min = 2,max = 4,message = "用户名必须是2-4个字符")
@TableField("name")
private String name;
@NotEmpty(message = "密码不能为空")
@Size(min = 6,max = 10,message = "用户名必须是6-10个字符")
@TableField("password")
private String password;
@NotEmpty(message = "用户邮箱不能为空")
@Email(message = "邮箱格式不正确")
private String email;
public MyUser(String name, String password) {
this.name = name;
this.password = password;
}
}校验规则和错误提示信息配置完毕后,接下来只需要在接口需要校验的参数上加上@Valid注解,并添加BindResult参数即可方便完成验证:
@RestController
@RequestMapping("user")
public class UserController {
@Autowired
private UserService userService;
@PostMapping("/addUser")
public String addUser(@RequestBody @Valid User user, BindingResult bindingResult) {
// 如果有参数校验失败,会将错误信息封装成对象组装在BindingResult里
for (ObjectError error : bindingResult.getAllErrors()) {
return error.getDefaultMessage();
}
return userService.addUser(user);
}
}使用Validator+ BindingResult已经是非常方便实用的参数校验方式了,在实际开发中也有很多项目就是这么做的,不过这样还是不太方便,因为你每写一个接口都要添加一个BindingResult参数,然后再提取错误信息返回给前端。
这样有点麻烦,并且重复代码很多(尽管可以将这个重复代码封装成方法)。我们能否去掉BindingResult这一步呢?当然是可以的!
2、Validator + 自动抛出异常
我们完全可以将BindingResult这一步给去掉:
@PostMapping("/addUser")
public String addUser(@RequestBody @Valid User user) {
return userService.addUser(user);
}去掉之后会发生什么事情呢?直接来试验一下,还是按照之前一样故意传递一个不符合校验规则的参数给接口。
此时我们观察控制台可以发现接口已经引发MethodArgumentNotValidException异常了:
那参数校验失败了会响应什么数据给前端呢?
我们来看一下刚才异常发生后接口响应的数据:
没错,是直接 将整个错误对象相关信息都响应给前端了!这样就很难受,不过解决这个问题也很简单,就是我们接下来要讲的 全局异常处理!
11、全局异常处理
基本使用
首先,我们需要新建一个类,在这个类上加上@ControllerAdvice或@RestControllerAdvice注解,这个类就配置成全局处理类了。(这个根据你的Controller层用的是@Controller还是@RestController来决定)
然后在类中新建方法,在方法上加上@ExceptionHandler注解并指定你想处理的异常类型,接着在方法内编写对该异常的操作逻辑,就完成了对该异常的全局处理!
演示一下对参数校验失败抛出的MethodArgumentNotValidException全局处理:
@RestControllerAdvice
public class ExceptionControllerAdvice {
@ExceptionHandler(MethodArgumentNotValidException.class)
public String MethodArgumentNotValidExceptionHandler(MethodArgumentNotValidException e) {
// 从异常对象中拿到ObjectError对象
ObjectError objectError = e.getBindingResult().getAllErrors().get(0);
// 然后提取错误提示信息进行返回
return objectError.getDefaultMessage();
}
}这次返回的就是我们制定的错误提示信息!我们通过全局异常处理优雅的实现了我们想要的功能!
以后我们再想写接口参数校验,只需在 入参的成员变量上加上Validator校验规则注解,然后在 参数上加上 @Valid注解 即可完成校验,校验失败会自动返回错误提示信息
12、自定义异常
全局处理当然不会只能处理一种异常,用途也不仅仅是对一个参数校验方式进行优化。在实际开发中,如何对异常处理其实是一个很麻烦的事情。传统处理异常一般有以下烦恼:
是捕获异常(try…catch)还是抛出异常(throws)
是在controller层做处理还是在service层处理又或是在dao层做处理
处理异常的方式是啥也不做,还是返回特定数据,如果返回又返回什么数据
不是所有异常我们都能预先进行捕捉,如果发生了没有捕捉到的异常该怎么办?
在很多情况下,我们需要手动抛出异常,比如在业务层当有些条件并不符合业务逻辑,我这时候就可以手动抛出异常从而触发事务回滚。
拿手动抛出异常最简单的方式就是throw new RuntimeException("异常信息")了,不过使用自定义会更好一些:
自定义异常可以携带更多的信息,不像这样只能携带一个字符串。
项目开发中经常是很多人负责不同的模块,使用自定义异常可以统一了对外异常展示的方式。
自定义异常语义更加清晰明了,一看就知道是项目中手动抛出的异常。
我们现在就来开始写一个自定义异常:
@Getter //只要getter方法,无需setter
public class APIException extends RuntimeException {
private int code;
private String msg;
public APIException() {
this(1001, "接口错误");
}
public APIException(String msg) {
this(1001, msg);
}
public APIException(int code, String msg) {
super(msg);
this.code = code;
this.msg = msg;
}
}在刚才的全局异常处理类中记得添加对我们自定义异常的处理:
@RestControllerAdvice
public class ExceptionControllerAdvice {
@ExceptionHandler(MethodArgumentNotValidException.class)
public String MethodArgumentNotValidExceptionHandler(MethodArgumentNotValidException e) {
// 从异常对象中拿到ObjectError对象
ObjectError objectError = e.getBindingResult().getAllErrors().get(0);
// 然后提取错误提示信息进行返回
return objectError.getDefaultMessage();
}
@ExceptionHandler(APIException.class)
public String APIExceptionHandler(APIException e) {
return e.getMsg();
}
}这样就对异常的处理就比较规范了,当然还可以添加对Exception的处理,这样无论发生什么异常我们都能屏蔽掉然后响应数据给前端,不过建议最后项目上线时这样做,能够屏蔽掉错误信息暴露给前端,在开发中为了方便调试还是不要这样做。
现在全局异常处理和自定义异常已经弄好了,不知道大家有没有发现一个问题,就是当我们抛出自定义异常的时候全局异常处理只响应了异常中的错误信息msg给前端,并没有将错误代码code返回。这就要引申出我们接下来要讲的东西了:数据统一响应
13、数据统一响应
现在我们规范好了参数校验方式和异常处理方式,然而还没有规范响应数据!比如我要获取一个分页信息数据,获取成功了呢自然就返回的数据列表,获取失败了后台就会响应异常信息,即一个字符串,就是说前端开发者压根就不知道后端响应过来的数据会是啥样的!所以,统一响应数据是前后端规范中必须要做的!
1、自定义统一响应体
统一数据响应第一步肯定要做的就是我们自己自定义一个响应体类,无论后台是运行正常还是发生异常,响应给前端的数据格式是不变的!那么如何定义响应体呢?关于异常的设计:如何更优雅的设计异常
可以参考我们自定义异常类,也来一个响应信息代码code和响应信息说明msg:
@Getter
public class ResultVO<T> {
/**
* 状态码,比如1000代表响应成功
*/
private int code;
/**
* 响应信息,用来说明响应情况
*/
private String msg;
/**
* 响应的具体数据
*/
private T data;
public ResultVO(T data) {
this(1000, "success", data);
}
public ResultVO(int code, String msg, T data) {
this.code = code;
this.msg = msg;
this.data = data;
}
}然后我们修改一下全局异常处理那的返回值:
@RestControllerAdvice
public class ExceptionControllerAdvice {
@ExceptionHandler(APIException.class)
public ResultVO<String> APIExceptionHandler(APIException e) {
// 注意哦,这里返回类型是自定义响应体
return new ResultVO<>(e.getCode(), "响应失败", e.getMsg());
}
@ExceptionHandler(MethodArgumentNotValidException.class)
public ResultVO<String> MethodArgumentNotValidExceptionHandler(MethodArgumentNotValidException e) {
ObjectError objectError = e.getBindingResult().getAllErrors().get(0);
// 注意哦,这里返回类型是自定义响应体
return new ResultVO<>(1001, "参数校验失败", objectError.getDefaultMessage());
}
}此时如果发生异常了会响应什么数据给前端:
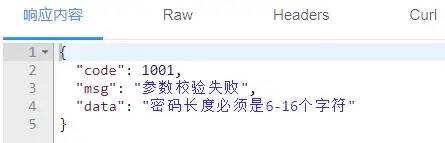
OK,这个异常信息响应就非常好了,状态码和响应说明还有错误提示数据都返给了前端,并且是所有异常都会返回相同的格式!异常这里搞定了,
别忘了我们到 接口那也要修改返回类型,我们新增一个接口好来看看效果:
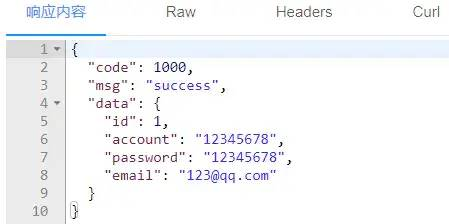
@GetMapping("/getUser")
public ResultVO<User> getUser() {
User user = new User();
user.setId(1L);
user.setAccount("12345678");
user.setPassword("12345678");
user.setEmail("123@qq.com");
return new ResultVO<>(user);
}看一下如果响应正确返回的是什么效果:
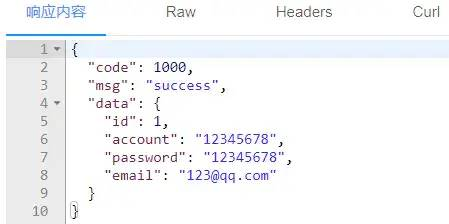
这样无论是正确响应还是发生异常,响应数据的格式都是统一的,十分规范!
数据格式是规范了,不过响应码code和响应信息msg还没有规范呀!大家发现没有,无论是正确响应,还是异常响应,响应码和响应信息是想怎么设置就怎么设置,要是10个开发人员对同一个类型的响应写10个不同的响应码,那这个统一响应体的格式规范就毫无意义!所以,必须要将响应码和响应信息给规范起来。
2、响应码枚举
要规范响应体中的响应码和响应信息用枚举简直再恰当不过了,我们现在就来创建一个响应码枚举类:
@Getter
public enum ResultCode {
SUCCESS(1000, "操作成功"),
FAILED(1001, "响应失败"),
VALIDATE_FAILED(1002, "参数校验失败"),
ERROR(5000, "未知错误");
private int code;
private String msg;
ResultCode(int code, String msg) {
this.code = code;
this.msg = msg;
}
}然后修改响应体的构造方法,让其只准接受响应码枚举来设置响应码和响应信息:
public ResultVO(T data) {
this(ResultCode.SUCCESS, data);
}
public ResultVO(ResultCode resultCode, T data) {
this.code = resultCode.getCode();
this.msg = resultCode.getMsg();
this.data = data;
}然后同时修改全局异常处理的响应码设置方式:
@RestControllerAdvice
public class ExceptionControllerAdvice {
@ExceptionHandler(APIException.class)
public ResultVO<String> APIExceptionHandler(APIException e) {
// 注意哦,这里传递的响应码枚举
return new ResultVO<>(ResultCode.FAILED, e.getMsg());
}
@ExceptionHandler(MethodArgumentNotValidException.class)
public ResultVO<String> MethodArgumentNotValidExceptionHandler(
MethodArgumentNotValidException e) {
ObjectError objectError = e.getBindingResult().getAllErrors().get(0);
// 注意哦,这里传递的响应码枚举
return new ResultVO<>(ResultCode.VALIDATE_FAILED, objectError.getDefaultMessage());
}
}这样响应码和响应信息只能是枚举规定的那几个,就真正做到了响应数据格式、响应码和响应信息规范化、统一化!这些可以参考:Java项目构建基础:统一结果,统一异常,统一日志
3、全局处理响应数据
接口返回统一响应体 + 异常也返回统一响应体,其实这样已经很好了,但还是有可以优化的地方。要知道一个项目下来定义的接口搞个几百个太正常不过了,要是每一个接口返回数据时都要用响应体来包装一下好像有点麻烦,有没有办法省去这个包装过程呢?当然是有滴,还是要用到全局处理。
首先,先创建一个类加上注解使其成为全局处理类。然后继承ResponseBodyAdvice接口重写其中的方法,即可对我们的controller进行增强操作,具体看代码和注释
@RestControllerAdvice(basePackages = {"com.rudecrab.demo.controller"}) // 注意哦,这里要加上需要扫描的包
public class ResponseControllerAdvice implements ResponseBodyAdvice<Object> {
@Override
public boolean supports(MethodParameter returnType, Class<? extends HttpMessageConverter<?>> aClass) {
// 如果接口返回的类型本身就是ResultVO那就没有必要进行额外的操作,返回false
return !returnType.getGenericParameterType().equals(ResultVO.class);
}
@Override
public Object beforeBodyWrite(Object data, MethodParameter returnType, MediaType mediaType, Class<? extends HttpMessageConverter<?>> aClass, ServerHttpRequest request, ServerHttpResponse response) {
// String类型不能直接包装,所以要进行些特别的处理
if (returnType.getGenericParameterType().equals(String.class)) {
ObjectMapper objectMapper = new ObjectMapper();
try {
// 将数据包装在ResultVO里后,再转换为json字符串响应给前端
return objectMapper.writeValueAsString(new ResultVO<>(data));
} catch (JsonProcessingException e) {
throw new APIException("返回String类型错误");
}
}
// 将原本的数据包装在ResultVO里
return new ResultVO<>(data);
}
}重写的这两个方法是用来在controller将数据进行返回前进行增强操作,supports方法要返回为true才会执行beforeBodyWrite方法,所以如果有些情况不需要进行增强操作可以在supports方法里进行判断。对返回数据进行真正的操作还是在beforeBodyWrite方法中,我们可以直接在该方法里包装数据,这样就不需要每个接口都进行数据包装了,省去了很多麻烦。
@GetMapping("/getUser")
public User getUser() {
User user = new User();
user.setId(1L);
user.setAccount("12345678");
user.setPassword("12345678");
user.setEmail("123@qq.com");
// 注意哦,这里是直接返回的User类型,并没有用ResultVO进行包装
return user;
}
成功对数据进行了包装!
注意:beforeBodyWrite方法里包装数据无法对String类型的数据直接进行强转,所以要进行特殊处理
总结
自此整个后端接口基本体系就构建完毕了
通过Validator + 自动抛出异常来完成了方便的参数校验
通过全局异常处理 + 自定义异常完成了异常操作的规范
通过数据统一响应完成了响应数据的规范
14、切面AOP处理
1、什么是AOP
AOP:Aspect Oriented Programming 的缩写,意为:面向切面编程。面向切面编程的目标就是分离 关注点。
核心思想: 就是你只需要关心你需要关心的核心业务的实现,而像日志,权限管理等 系统功能会在程序运行时织入进去;
2、 Spring Boot 中的 AOP 处理
导入AOP依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
<version>2.7.2</version>
</dependency>实现 AOP 切面
Spring Boot 中使用 AOP 非常简单,假如我们要在项目中打印一些 log,在引入了上面的依赖之后,我
们 新建一个类 LogAspectHandler,用来定义切面和处理方法。只要在类上 加个 @Aspect 注解 即可。
@Aspect 注解用来描述一个切面类,定义切面类的时候需要打上这个注解。 @Component 注解 让该类
交给 Spring 来管理。
1、这里主要介绍几个常用的注解及使用:
@Pointcut:定义一个切面,即上面所描述的关注的某件事入口。
@Before:在做某件事之前做的事。
@After:在做某件事之后做的事。
@AfterReturning:在做某件事之后,对其返回值做增强处理。
@AfterThrowing:在做某件事抛出异常时,处理。
2、@Pointcut 注解
@Pointcut 注解:用来定义一个切面(切入点),即上文中所关注的某件事情的入口。切入点决定了
连接点关注的内容,使得我们可以控制通知什么时候执行。
@Pointcut 注解指定一个切面,定义需要拦截的东西,这里介绍两个常用的表达式:一个是使用 execution() ,另一个是使用 annotation() 。
以 @Pointcut(“execution(* com.example.controller….(…))”)表达式为例,语法如下:
execution() 为表达式主体
第一个 * 号的位置:表示返回值类型, * 表示所有类型
包名:表示需要拦截的包名,后面的两个句点表示当前包和当前包的所有子包,
com.example.controller包、子包下所有类的方法
第二个 * 号的位置:表示类名, * 表示所有类
*(…) :这个星号表示方法名, * 表示所有的方法,后面括弧里面表示方法的参数,两个句点
表示任何参数
annotation() 方式是针对某个注解来定义切面,比如我们对具有 @GetMapping 注解的方法做切面,
可以如下定义切面:
@Pointcut("@annotation(org.springframework.web.bind.annotation.GetMapping)")publicvoidannotationCut() {}然后使用该切面的话,就会切入注解是 @GetMapping 的方法。因为在实际项目中,可能对于不同的注
解有不同的逻辑处理,比如 @GetMapping 、 @PostMapping 、 @DeleteMapping 等。所以这种按照注
解的切入方式在实际项目中也很常用。
3、@Before 注解
前置通知(Before advice):在某连接点(join point)之前执行的通知,但这个通知不能阻止连接点前的执行(除非它抛出一个异常)
@Aspect
@Component
public class LogAspectHandler {
private final Logger logger = LoggerFactory.getLogger(LogAspectHandler.class);
/*** 定义一个切面,拦截com.example.controller包和子包下的所有方法 */
@Pointcut("execution(* com.example.controller..*.*(..))")
public void pointcut() {
}
@Before("pointcut()")
public void testAfter(JoinPoint joinPoint) {
logger.info("testAfter方法进入!");
Signature signature = joinPoint.getSignature();
String methodName = signature.getName();
String declaringTypeName = signature.getDeclaringTypeName();
logger.info("包名为:{},方法名为:{}", declaringTypeName, methodName);
// 也可以用来记录一些信息,比如获取请求的url和ip
ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletRequest request = attributes.getRequest();
//获取URL
String requestURL = request.getRequestURL().toString();
//获取ip地址
String remoteAddr = request.getRemoteAddr();
logger.info("请求的url地址为:{},ip地址为:{}",requestURL,remoteAddr);
}
}JointPoint 对象很有用,可以用它来获取一个签名,然后利用签名可以获取请求的包名、方法名,包括
参数(通过 joinPoint.getArgs() 获取)等等。
4、@Afert 注解
后通知(After (finally) advice):当某连接点退出的时候执行的通知(一定执行)。
@After("pointcut()")
public void testAfter(JoinPoint joinPoint) {
logger.info("after方法进入");
Signature signature = joinPoint.getSignature();
String name = signature.getName();
logger.info("方法{}执行完成", name);
}5、@AfterReturning 注解
返回后通知(After returning advice):在某连接点(join point)正常完成后执行的通知:例如,一个方法没有抛出任何异常,正常返回。
@AfterReturning(value = "pointcut()", returning = "result")
public void testAfterReturning(JoinPoint joinPoint, Object result) {
logger.info("afterReturning方法进入,返回参数为:{}", result);
logger.info("增强后的返回值为:{}", result + "增强");
}需要注意的是:在 @AfterReturning 注解 中,属性 returning 的值必须要和参数保持一致,否则会
检测不到。该方法中的第二个入参就是被切方法的返回值,在 doAfterReturning 方法中可以对返回
值进行增强,可以根据业务需要做相应的封装。
6、@AfterThrowing 注解
抛出异常后通知(After throwing advice):在方法抛出异常退出时执行的通知。 (它和返回后通知总是只执行一个)
@AfterThrowing(value = "pointcut()", throwing = "ex")
public void testAfterThrowing(JoinPoint joinPoint, Throwable ex) {
logger.info("testAfterThrowing方法进入");
Signature signature = joinPoint.getSignature();
String name = signature.getName();
logger.info("方法{}执行出错,异常为:{}", name,ex.getMessage());
}从上述结果看注解的执行顺序为 @Before -> @After -> @AfterReturning/ @AfterThrowing(这两个注解的方法任何时候只有一个生效,无异常则@AfterReturning生效,有异常则@AfterThrowing生效)
15、整合mybatis/mybatis-plus
1、导入依赖
尤其注意mysql依赖的版本,如果不设置可能由于你自己mysql安装版本太低而无法适应springboot默认配置的高版本,会使得数据库连接失败
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.29</version>
</dependency>2、yaml配置
配置完要检查属性是否配置成功,否则后序出问题很难发现;
datasource:
url: 47.98.240.115:3306/ssm
#localhost:3306/movies
spring:
#关闭thymeleaf的缓存
thymeleaf:
cache: false
# 整合mybatis
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://${datasource.url}?serverTimezone=UTC&characterEncoding=UTF-8
username: root
password: 123456
hikari:
maximum-pool-size: 10 # 最大连接池数
max-lifetime: 1770000
mybatis:
mapper-locations: classpath:mapping/*Mapper.xml #xml配置路径
# 设定别名
type-aliases-package: com.example.po
configuration:
map-underscore-to-camel-case: true #驼峰法命名
mybatis-plus:
type-aliases-package: com.example.docker.bean
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: true
mapper-locations: classpath:mapper/*.xml #xml配置路径3、mybatis
1、xxmapper.java配置
public interface FilmInfoMapper {
public FilminfoPO findById(Integer id);
public int updateById(int id);
}2、xxmapper.xml配置
namespace(命名空间)的作用:
1.隔离sql语句,同一个命名空间的sql彼此可见,不同的命名空间彼此不可见,也就是说同一命名空间不能有相同id的sql语句,不同命名空间可以有;
2.通过命名空间可以找到与之对应的xxmapper接口;
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.mapper.FilmInfoMapper">
<!-- public FilminfoPO findById(Integer id);-->
<select id="findById" resultType="com.example.po.FilminfoPO" parameterType="Integer">
select *from tb_filminfo where filmid=#{id}
</select>
<!-- public int updateById(int id);-->
<update id="updateById">
update tb_filminfo set ticketprice=20 where filmid=#{id}
</update>
</mapper>4、mybatis-plus
注意:只能实现简单的业务
1、实体类
@Data
@TableName("myuser")
public class MyUser {
@TableId(value = "id",type = IdType.AUTO)
private Integer id;
@NotEmpty(message = "用户名不能为空")
@Size(min = 2,max = 4,message = "用户名必须是2-4个字符")
@TableField("name")
private String name;
@NotEmpty(message = "密码不能为空")
@Size(min = 6,max = 10,message = "用户名必须是6-10个字符")
@TableField("password")
private String password;
public MyUser(String name, String password) {
this.name = name;
this.password = password;
}
}2、controller
@RestController
public class SysUserController {
@Autowired
private UserMapper userMapper;
@Autowired
private StringRedisTemplate redisTemplate;
@GetMapping("/insert")
@CrossOrigin
public String insert(String name,String password) {
MyUser myUser = new MyUser(name,password);
if (1 == userMapper.insert(myUser)) {
redisTemplate.opsForValue().set("user",myUser.toString());
return "ok";
}
return "fail";
}
@PostMapping("/upload")
@CrossOrigin
public String upload(@RequestPart("file") MultipartFile multipartFile) throws Exception {
return OssUtil.uploadImg(multipartFile);
}
}3、mapper层
@Mapper
public interface UserMapper extends BaseMapper<MyUser> {
}5、启动类加扫描mapper接口的注解
如果不加 @MapperScan注解,那么每个mapper接口都得加 @Mapper注解否则Spring Boot 找不到 Mapper
@SpringBootApplication
@MapperScan("com.demo.boot.mapper")
public class UserBootApplication {
public static void main(String[] args) {
SpringApplication.run(UserBootApplication.class, args);
}
}测试类
@RunWith(SpringRunner.class)
@SpringBootTestclass FilmInfoTest {
@Autowired
FilmInfoMapper mapper;
@Testpublicvoid findByIdTest() {
Integer i=1;
System.out.println("FilmInfoPO:"+mapper.findById(i));
}
}16、事务配置管理
我们在开发企业应用时,由于数据操作在顺序执行的过程中,线上可能有各种无法预知的问题,
任何一步操作都有可能发生异常,异常则会导致后续的操作无法完成。此时由于业务逻辑并未正确的完
成,所以在之前操作过数据库的动作并不可靠,需要在这种情况下进行数据的回滚
1、导入依赖
springboot的事务管理需要导入spring-boot-starter-jdbc;而我们导入的mybatis-spring-boot-starter包含了它,所以无需重复导入;
2、@Transactional注解
@Service
public class FilmInfoServiceImpl implements IFilmInfoService {
@Resource
private FilmInfoMapper mapper;
@Transactional
@Override
public int insert(FilminfoPO po) {
return mapper.insert(po);
}
}当没有异常抛出时添加成功,有异常出现添加失败;
3、事务处理的一些特殊情况
1、异常并没有被捕获到
异常并没有被 ”捕获“ 到,导致事务并没有回滚。
Spring Boot 默认的事务规则是遇到运行异常(RuntimeException)和程序 错误(Error)才会回滚。但是抛出 SQLException 就无法回滚了。
1.1、解决方案:
针对非运行时异常,如果要进行事务回滚的话,可以在 @Transactional 注解中使用 rollbackFor 属性来指定异常,比如 @Transactional(rollbackFor = Exception.class) ,这样就没有问题了,所以在实际项目中,一定要指定异常。
@Transactional(rollbackFor = Exception.class)
@Override
public void insert(FilminfoPO po) throws SQLException {
// 手动抛出异常
mapper.insert(po);
throw new SQLException("数据库异常");
}2、异常在方法中被捕获导致事务回滚失败
我们在处理异常时,有两种方式, 要么抛出去,让上一层来捕获处理;要么把异常 try catch 掉,在异常出现的地方给处理掉。就因为有 这中 try…catch,所以导致异常被 ”吃“ 掉,事务无法回滚。
@Transactional
@Override
public int insert(FilminfoPO po) {
try {
int i = 1 / 0;
} catch (Exception e) {
e.getMessage();
}
return mapper.insert(po);
}2.1解决方法:直接往上抛,给上一层来处理即可
3、事务的范围 冲突导致回滚失败
许多业务需要在高并发的情况下保证数据唯一性所比要加synchronized关键字如一个数据库中,针对某个用户,只有一条记录,下一个插入动作过来,会先判断该数据库 中有没有相同的用户,如果有就不插入,就更新,没有才插入,所以理论上,数据库中永远就一条同一 用户信息,不会出现同一数据库中插入了两条相同用户的信息。
@Transactional(rollbackFor = Exception.class)
@Override
public synchronized void insert(FilminfoPO po) throws SQLException {
// 手动抛出异常
mapper.insert(po);
}但是在压测时,数据库中确实可能有两条同一用户的信息,分析其原因,在于事务的范围和锁的范围问题。
在执行该方法开始时,事务启动,执行 完了后,事务关闭。但是 synchronized 没有起作用,其实根本原因是因为事务的范围比锁的范围大。 也就是说,在加锁的那部分代码执行完之后,锁释放掉了,但是事务还没结束,此时另一个线程进来 了,事务没结束的话,第二个线程进来时,数据库的状态和第一个线程刚进来是一样的。即由于mysql Innodb引擎的默认隔离级别是可重复读(在同一个事务里,SELECT的结果是事务开始时时间点的状 态),线程二事务开始的时候,线程一还没提交完成,导致读取的数据还没更新。第二个线程也做了插 入动作,导致了脏数据。
3.1、解决方案:
1.把事务去掉即可(不推荐);
2. 在调用该 service 的地方加锁,保证锁 的范围比事务的范围大即可。
17、使用拦截器
1、应用场景:
拦截器是 AOP 的一种实现,专门 拦截对动态资源的后台请求,即 拦截对控制层的请求。使用场景比较多的
是判断用户是否有权限请求后台,更拔高一层的使用场景也有,比如拦截器可以 结合 websocket 一起使用,用来
拦截 websocket 请求,然后做相应的处理 等等。
拦截器不会拦截静态资源,Spring Boot 的默认静态目录为 resources/static,该目录下的静态页面、js、css、图片等等, 不会被拦截.
2、定义拦截器
定义拦截器,只需要实现 HandlerInterceptor 接口, 该接口中有三个方法:
preHandle(……) 、 postHandle(……) 和 afterCompletion(……) 。
preHandle(……) 方法:该方法的执行时机是,当某个 url 已经匹配到对应的 Controller 中的某
个方法,且在这个方法执行之前。所以 preHandle(……) 方法可以决定是否将请求放行,这是通
过返回值来决定的,返回 true 则放行,返回 false 则不会向后执行。
postHandle(……) 方法:该方法的执行时机是,当某个 url 已经匹配到对应的 Controller 中的某
个方法,且在执行完了该方法,但是在 DispatcherServlet 视图渲染之前。所以在这个方法中有
个 ModelAndView 参数,可以在此做一些修改动作。
afterCompletion(……) 方法:顾名思义,该方法是在整个请求处理完成后(包括视图渲染)执
行,这时做一些资源的清理工作,这个方法只有在 preHandle(……) 被成功执行后并且返回 true
才会被执行。
2.1、自定义拦截类实现HandlerInterceptor接口
public class UserInterceptor implements HandlerInterceptor {
private Logger logger = LoggerFactory.getLogger(MyInterceptor.class);
/**
* 在请求处理之前进行调用(Controller方法调用之前)
*/
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
HandlerMethod handlerMethod = (HandlerMethod) handler;
Method method = handlerMethod.getMethod();
String methodName = method.getName();
logger.info("方法{}被拦截", methodName);
//从session中获取user的信息
User user =(User)request.getSession().getAttribute("user");
//判断用户是否登录
if (null==user){
response.sendRedirect(request.getContextPath()+"/user/error");
return false;
}
return true;
}
/**
* 请求处理之后进行调用,但是在视图被渲染之前(Controller方法调用之后)
*/
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
logger.info("方法被执行,但是视图还未渲染");
}
/**
* 在整个请求结束之后被调用,也就是在DispatcherServlet 渲染了对应的视图之后执行
* (主要是用于进行资源清理工作)
*/
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
logger.info("方法执行完毕,进行资源清理");
}
}2.2、实现WebMvcConfigurer接口进行拦截配置
实现WebMvcConfigurer的这种配置会自动过滤静态资源;
@Configuration//定义此类为配置类
public class InterceptorConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
//addPathPatterns拦截的路径
String[] addPathPatterns = {
"/user/**"
};
//excludePathPatterns排除的路径
String[] excludePathPatterns = {
"/user/login","/user/noLg","/user/error"
};
//创建用户拦截器对象 并指定其拦截的路径和 排除的路径
registry.addInterceptor(new UserInterceptor()).addPathPatterns(addPathPatterns).excludePathPatterns(excludePathPatterns);
}
}编写Controller类
@RestController
@RequestMapping("/user")
public class MyController {
//用户登录
@RequestMapping("login")
public Object login(HttpServletRequest request){
//将已经登录的用户信息添加到session中
request.getSession().setAttribute("user",new User(1,"张三",20));
return "Login Success";
}
//不需要登录也能访问的请求
@RequestMapping("/noLg")
public Object noLg(){
return "Everyone Can See";
}
//必须要登录才能访问的请求
@RequestMapping("/mustLg")
public Object mustLg(){
return "Only User Can See";
}
//如果用户未登录访问了需要登录才能访问的请求会跳转到这个错误提示页面
@RequestMapping("/error")
public Object error(){
return "You Must Login";
}
}3、定义哪些不用拦截
取消拦截操作
如果我要拦截所有 /admin 开头的 url 请求的话,需要在拦截器配置中添加这个前缀,但是 在实际项目中,可能会有这种场景出现:某个请求也是 /admin 开头的,但是不能拦截,比如 /admin/login 等等
解决方案:
1.使用excludePathPatterns(“/adminUser/login”)
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new MyInterceptor()).addPathPatterns("/**").excludePathPatterns("/adminUser/login");
}2.可以定义一个注解
该注解专门用来取消拦截操作,如果某个 Controller 中的方法我们 不需要拦截掉,即可在该方法上加上我们自定义的注解即可,下面先定义一个注解:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface UnInterception {
}interceptor拦截类
public class UserInterceptor implements HandlerInterceptor {
private Logger logger = LoggerFactory.getLogger(MyInterceptor.class);
/**
* 在请求处理之前进行调用(Controller方法调用之前)
*/
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
HandlerMethod handlerMethod = (HandlerMethod) handler;
Method method = handlerMethod.getMethod();
String methodName = method.getName();
if (method.getAnnotation(UnInterception.class)!=null) {
logger.info("方法{}不被拦截", methodName);
return true;
}
logger.info("方法{}被拦截", methodName);
//从session中获取user的信息
User user =(User)request.getSession().getAttribute("user");
//判断用户是否登录
if (null==user){
response.sendRedirect(request.getContextPath()+"/user/error");
return false;
}
return true;
}
/**
* 请求处理之后进行调用,但是在视图被渲染之前(Controller方法调用之后)
*/
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
logger.info("方法被执行,但是视图还未渲染");
}
/**
* 在整个请求结束之后被调用,也就是在DispatcherServlet 渲染了对应的视图之后执行
* (主要是用于进行资源清理工作)
*/
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
logger.info("方法执行完毕,进行资源清理");
}
}测试
controller类
@RestController
@RequestMapping("/intercept")
public class IntercepController {
@UnInterception
@RequestMapping("/hello")
public String test() {
return "success";
}
}18、集成Redis
1、简介:
redis是一款高性能的NOSQL系列的非关系型数据库
非关系型数据库的优势:
1)性能NOSQL是基于键值对的,可以想象成表中的主键和值的对应关系,而且不需要经过SQL层的解析,所以性能非常高。
2)可扩展性同样也是因为基于键值对,数据之间没有耦合性,所以非常容易水平扩展。
关系型数据库的优势:
1)复杂查询可以用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询。
2)事务支持使得对于安全性能很高的数据访问要求得以实现。对于这两类数据库,对方的优势就是自己的弱势,反之亦然。
2、使用场景
•缓存(数据查询、短连接、新闻内容、商品内容等等)
• 聊天室的在线好友列表
• 任务队列。(秒杀、抢购、12306等等)
• 应用排行榜
• 网站访问统计
• 数据过期处理(可以精确到毫秒
• 分布式集群架构中的session分离
3、redis为什么要序列化
序列化最终的目的是 为了对象可以跨平台存储,和进行网络传输。 而我们进行跨平台存储和网络传输的方式就是IO,而我们的IO支持的数据格式就是字节数组。
通过上面我想你已经知道了凡是需要进行“跨平台存储”和”网络传输”的数据,都需要进行序列化。
本质上存储和网络传输 都需要经过 把一个对象状态保存成一种跨平台识别的字节格式,然后其他的平台才可以通过字节信息解析还原对象信息。
1、redis序列化方式对比:
redis的默认方式是JdkSerializationRedisSerializer
JdkSerializationRedisSerializer: 使用JDK提供的序列化功能。
优点是反序列化时不需要提供类型信息(class),但缺点是需要实现Serializable接口, 还有序列化后的结果非常庞大,是JSON格式的5倍左右,这样就会消耗redis服务器的大量内存。
Jackson2JsonRedisSerializer: 使用Jackson库将对象序列化为JSON字符串。
优点是速度快,序列化后的字符串短小精悍,不需要实现Serializable接口。
但缺点也非常致命,那就是此类的构造函数中有一个类型参数,必须提供要序列化对象的类型信息(.class对象)。 通过查看源代码,发现其只在反序列化过程中用到了类型信息。
问题:使用默认的JDK序列化方式,在RDM工具中查看k-v值时会出现“乱码”,不方便查看。
解决:自定义系列化方式,使用Jackson2JsonRedisSerializer
4、redis下载安装
通过docker去拉取镜像,开启容器
5、集成redis
1、依赖导入
<<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>2.7.4</version>
</dependency>
<!--springboot 2.x 使用的Lettuce 依赖org.apache.commons-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.11.1</version>
</dependency>
<!--阿里巴巴fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>2、yaml配置文件
redis:
database: 3
# 配置redis的主机地址,需要修改成自己的 我这里是阿里云服务器地址
host: 47.98.240.115
port: 6379
timeout: 5000
password: 123456
lettuce:
pool:
# 连接池中的最大空闲连接,默认值也是8。
max-idle: 50
# 连接池中的最小空闲连接,默认值也是0。
min-idle: 0
# 如果赋值为-1,则表示不限制;如果pool已经分配了maxActive个jedis实例,则此时pool 的状态为exhausted(耗尽)
max-active: 50
# 等待可用连接的最大时间,单位毫秒,默认值为-1,表示永不超时。如果超过等待时间,则直接 抛出JedisConnectionException
max-wait: 13、redis配置类
import org.springframework.cache.annotation.CachingConfigurerSupport;
import org.springframework.cache.interceptor.KeyGenerator;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.cache.RedisCacheWriter;
import org.springframework.data.redis.connection.lettuce.LettuceConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import javax.annotation.Resource;
import java.lang.reflect.Method;
import java.time.Duration;
import java.util.Arrays;
@Configuration
public class RedisConfiguration extends CachingConfigurerSupport {
@Resource
private LettuceConnectionFactory lettuceConnectionFactory;
@Bean
public RedisTemplate<String, Object> redisTemplate() {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(lettuceConnectionFactory);
GenericJackson2JsonRedisSerializer serializer = new GenericJackson2JsonRedisSerializer();
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
template.setConnectionFactory(lettuceConnectionFactory);
//key序列化方式
template.setKeySerializer(redisSerializer);
//value序列化
template.setValueSerializer(serializer);
//value hashmap序列化
template.setHashValueSerializer(serializer);
template.afterPropertiesSet();
return template;
}
@Bean("myKeyGenerator")
@Override
public KeyGenerator keyGenerator() {
return (Object target, Method method, Object... objects) -> method.getName() + "(" + Arrays.toString(objects) + ")";
}
@Bean
public RedisCacheManager redisCacheManager(RedisTemplate redisTemplate) {
RedisCacheWriter redisCacheWriter = RedisCacheWriter.nonLockingRedisCacheWriter(lettuceConnectionFactory);
RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofDays(3))//只有通过注解的方式设置缓存才生效
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(redisTemplate.getValueSerializer()))
.disableCachingNullValues();
return new RedisCacheManager(redisCacheWriter, redisCacheConfiguration);
}
}4、常用 api 介绍
Redis提供了StringRedisTemplate和RedisTemplate两种模板,后者需要进行序列化比较麻烦
1、redis:string 类型
新建一个 RedisServiceImpl,注入 StringRedisTemplate,使用 stringRedisTemplate.opsForValue() 可以获取 ValueOperations<String,Object> 对象,通过该对象即可读写 redis 数据库了。
@RestController
public class SysUserController {
@Autowired
private UserMapper userMapper;
@Autowired
private StringRedisTemplate redisTemplate;
@GetMapping("/insert")
@CrossOrigin
public String insert(String name,String password) {
MyUser myUser = new MyUser(name,password);
//只要insert方法 插入数据成功,受影响行数唯一
if (1 == userMapper.insert(myUser)) {
//判断为1,将用户名和密码封装为对象:value = myUser ; key:"user"存入redis
redisTemplate.opsForValue().set("user",myUser.toString());
return "ok";
}
return "fail";
}
public String GetUser(String key) {
return stringRedisTemplate.opsForValue().get(key);
}
}2、redis:hash 类型
hash 类型其实原理和 string 一样的,但是有两个 key,使用 stringRedisTemplate.opsForHash() 可以获取 HashOperations<String, Object, Object> 对象。比如我们要存储订单信息,所有订单 信息都放在 order 下,针对不同用户的订单实体,可以通过用户的 id 来区分,这就相当于两个 key 了。
public void setHash(String key,String filedKey,String value){
stringRedisTemplate.opsForHash().put(key,filedKey,value);
}
public String getHash(String key,String filedKey){
return (String) stringRedisTemplate.opsForHash().get(key,filedKey);
}测试
@Test
public void testHash() {
String key="userId";
String userId="1";
UserPO po=new UserPO();
po.setAge(12);
po.setName("lisi");
redisService.setHash(key,userId, JSON.toJSONString(po));
System.out.println(redisService.getHash(key,userId));
}结果:{"age":12,"name":"lisi"}
3、以java对象的形式取出json格式的对象
UserPO po1 = JSON.parseObject(redisService.getHash(key,userId),UserPO.class);
@Test
public void testHash() {
String key="userId";
String userId="1";
UserPO po=new UserPO();
po.setAge(12);
po.setName("lisi");
redisService.setHash(key,userId, JSON.toJSONString(po));
UserPO po1 = JSON.parseObject(redisService.getHash(key,userId),UserPO.class);
System.out.println("po1:"+po1);
}结果:po1:UserPO{age=12, name='lisi'}
4、redis:list 类型
list 类型左右两边都可以进行添加,可以用来模拟消息队列;
stringRedisTemplate.opsForList().range(key,start,end) 是获取对应key的start到end下标的所有者,
当start为0,end为-1时表示对应key的所有值
public void leftPushList(String key, String value) {
stringRedisTemplate.opsForList().leftPush(key,value);
}
public String rightPopList(String key) {
return stringRedisTemplate.opsForList().rightPop(key);
}
public List<String> getRange(String key, int start, int end) {
return stringRedisTemplate.opsForList().range(key,start,end);
}测试
@Test
public void TestList() {
String key="lisi";
// redisService.leftPushList(key,"1");
// redisService.leftPushList(key,"2");
// redisService.leftPushList(key,"3");
System.out.println(redisService.rightPopList(key));
System.out.println("all:"+redisService.getRange(key,0,-1));
}19、集成Shiro
1、shiro简介
Apache Shiro是一个功能强大且灵活的开源安全框架,可以干净地处理身份验证,授权,企业会话管理和加密。
2、shiro功能介绍
Apache Shiro是具有许多功能的全面的应用程序安全框架。下图显示了Shiro核心功能
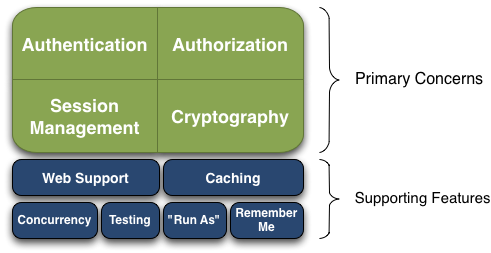
Shiro以Shiro开发团队所谓的“应用程序安全性的四个基石”为目标-身份验证,授权,会话管理和密码术:
身份验证:有时称为“登录”,这是证明用户就是他们所说的身份的行为。
授权:访问控制的过程,即确定“谁”有权访问“什么”。
会话管理:即使在非Web或EJB应用程序中,也可以管理用户特定的会话。
密码术:使用密码算法保持数据安全,同时仍然易于使用。
3、shiro核心组件
Subject(org.apache.shiro.subject.Subject)
当前与软件交互的实体(用户,第三方服务,计划任务等)的特定于安全性的“视图”。(把操作交给SecurityManager)
SecurityManager(org.apache.shiro.mgt.SecurityManager)
安全管理器(关联Realm)
Realm(org.apache.shiro.realm.Realm)
领域充当Shiro与应用程序的安全数据之间的“桥梁”或“连接器”。当真正需要与安全性相关的数据(如用户帐户)进行交互以执行身份验证(登录)和授权(访问控制)时,Shiro会从为应用程序配置的一个或多个Realms中查找许多此类内容。您可以根据Realms需要配置任意数量(通常每个数据源一个),并且Shiro会根据需要进行协调,以进行身份验证和授权。
4、shiro实战
4.1 环境构建
1、maven依赖:
<dependency>
<groupId>org.apache.shiro</groupId>
<artifactId>shiro-spring</artifactId>
<version>1.9.1</version>
</dependency>2、自定义Realm
自定义 realm 需要继承 AuthorizingRealm 类,因 为该类封装了很多方法,它也是一步步继承自 Realm 类的,继承了 AuthorizingRealm 类后,需要重写 两个方法:
doGetAuthenticationInfo() 方法:用来验证当前登录的用户,获取认证信息
doGetAuthorizationInfo() 方法:用来为当前登陆成功的用户授予权限和角色
public class MyRealm extends AuthorizingRealm {
@Resource
UserService userService;
@Override
//用来为当前登陆成功的用户授予权限和角色
protected AuthorizationInfo doGetAuthorizationInfo(PrincipalCollection principalCollection) {
return null;
}
@Override
//用来验证当前登录的用户,获取认证信息
protected AuthenticationInfo doGetAuthenticationInfo(AuthenticationToken authenticationToken) throws AuthenticationException {
return null;
}
}
后续实现具体功能再对这两个方法进行具体实现和讲解;
3、shiro配置文件
1 .ShiroFileterFactoryBean : 可以进行权限设置,访问控制等功能,由DefaultWebSecurityManager 对设置进行实现;
2.DefaultWebSecurityManager :根据自定义的Realm进行安全管理;
3.自定义Realm: 自定义验证规则;
@Configuration
public class ShiroConfig {
/*
1.ShiroFileterFactoryBean
* */
@Bean
public ShiroFilterFactoryBean getshShiroFilterFactoryBean(@Qualifier("securityManager") DefaultSecurityManager securityManager) {
ShiroFilterFactoryBean shiroFilterFactoryBean=new ShiroFilterFactoryBean();
//添加shiro内置过滤器
/*
* 常用过滤器:
* anon:无需认证(登录)可以访问
* authc:必须认证才可以访问
* user: 如果使用remmemberMe的功能可以直接访问
* perms: 该资源必须得到资源权限才可以访问
* roles:该资源必须得到角色权限才可以访问
* */
//配置过滤规则
Map<String,String> filter=new LinkedHashMap<>();
filter.put("/user/add","anon");
filter.put("/user/update","authc");
//放行hello.html
filter.put("/hello.html","anon");
//拦截所有请求包括html也会被拦截
filter.put("/*","authc");
//将过滤规则设置到shiroFilterFactoryBean
shiroFilterFactoryBean.setFilterChainDefinitionMap(filter);
//访问被拦截后访问的地址,如/user/update被拦截时就会访问/user/toLogin;
shiroFilterFactoryBean.setLoginUrl("/user/toLogin");
shiroFilterFactoryBean.setSecurityManager(securityManager);
return shiroFilterFactoryBean;
}
/*
* 2.DefaultWebSecurityManager
* */
@Bean(name = "securityManager")
public DefaultSecurityManager getDefaultSecurityManager(@Qualifier("MyRealm")Realm myRealm) {
DefaultSecurityManager securityManager = new DefaultWebSecurityManager(myRealm);
return securityManager;
}
/*
* 3.自定义Realm
* */
@Bean(name = "MyRealm")
public Realm getRealm() {
return new MyRealm();
}
}配置的过滤规则只有访问controller层进行跳转时才能生效,直接访问xxx.html页面是不生效的,也就是说即使你配置了拦截/add,也可以访问add.html;
4、 登入验证
1.创建数据库表
暂时只用到用户表,角色表和权限表用于后续授权;
#角色表
CREATE TABLE `t_role` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `rolename` varchar(20) DEFAULT NULL COMMENT '角色名称', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8
#用户表
CREATE TABLE `t_user` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '用户主键', `username` varchar(20) NOT NULL COMMENT '用户名', `password` varchar(20) NOT NULL COMMENT '密码' ) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8
#权限表
CREATE TABLE `t_permission` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `permissionname` varchar(50) NOT NULL COMMENT '权限名', `role_id` int(11) DEFAULT NULL COMMENT '外键关联role', PRIMARY KEY (`id`), KEY `role_id` (`role_id`), CONSTRAINT `t_permission_ibfk_1` FOREIGN KEY (`role_id`) REFERENCES `t_role` (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8
#用户与权限表
CREATE TABLE `user_role` (
`user_id` int(11) DEFAULT NULL,
`role_id` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;2.自定义Realm的doGetAuthenticationInfo方法添加具体实现
public class MyRealm extends AuthorizingRealm {
@Resource
UserService userService;
@Override
//用来为当前登陆成功的用户授予权限和角色
protected AuthorizationInfo doGetAuthorizationInfo(PrincipalCollection principalCollection) {
return null;
}
@Override
//用来验证当前登录的用户,获取认证信息
protected AuthenticationInfo doGetAuthenticationInfo(AuthenticationToken authenticationToken) throws AuthenticationException {
// 根据token获取用户名,此Token是controller层穿来的,具体看下一步
String userName = (String) authenticationToken.getPrincipal();
// 根据用户名从数据库中查询该用户
User user = userService.getByUsername(userName);
if (user != null) {
//返回SimpleAuthenticationInfo来验证密码,只有user.getPassword()为必填参数,其他的可以填“”; //验证失败 subject.login(token);方法会出现IncorrectCredentialsException异常
return SimpleAuthenticationInfo(user.getUserName(), user.getPassword(), "MyRealm");
} else {
//返回null subject.login(token)方法会报UnknownAccountException异常;
return null;
}
}
}3.编写controller
subject.login(token)这一步会带着存有前端传来的用户信息去自定义的Realm中的doGetAuthenticationInfo验证用户信息;
@Controller
@RequestMapping("/user")
public class UserController {
@RequestMapping("/login")
public String login(User user, Model model) {
if (user == null) {
return "user/login";
} else {
Subject subject = SecurityUtils.getSubject();
UsernamePasswordToken token=new UsernamePasswordToken(user.getUserName(), user.getPassword());
try {
subject.login(token);
} catch (UnknownAccountException e) {
model.addAttribute("msg", "用户不存在");
return "user/login";
} catch (IncorrectCredentialsException e) {
model.addAttribute("msg","密码错误");
return "user/login";
}
}
return "success";
}
}4.前端代码login.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<p style="color: red" th:text="${msg}"></p>
<form action="/user/login" >
<p>请输入userName:</p>
<input type="text" name="userName">
<p>请输入password:</p>
<input type="text" name="password" >
<input type="submit" value="submit">
</form>
</body>
</html>5、添加角色和添加授权
数据库表结构:
t_user:
“id” “username” “password”
“1” “yg1” “a”
“2” “yg2” “a”
“3” “yg3” “a”
t_role
“id” “rolename”
“1” “admin”
“2” “boss”
“3” “user”
t_permission
“id” “permissionname” “role_id”
“1” “user:*” “1”
“2” “user:add” “2”
“3” “user:update” “3”
user_role
“u_id” “r_id”
“1” “1”
“2” “2”
“3” “3”
6、userMapper接口的编写
public interface UserMapper {
public Set<Role> getRoles(String userName);
public Set<Permission> getPermissions(String userName);
public User getByUsername(String userName);
}7、userMapper.xml的编写
<!-- public User getByUsername(String userName);-->
<select id="getByUsername" resultType="User">
select * from t_user where username=#{userName}
</select>
<!-- public Set<Role> getRoles(String userName);-->
<select id="getRoles" resultType="Role">
SELECT tr.* from t_role tr,user_role ur where
tr.id=ur.r_id and ur.u_id in (select id from
t_user where username=#{userName})
</select>
<!-- public Set<Permission> getPermissions(String userName);-->
<select id="getPermissions" resultType="Permission">
SELECT tp.* from t_permission tp,user_role ur
where tp.role_id=ur.r_id AND ur.u_id in (select id
from t_user where username=#{userName})
</select>8、userService编写
@Service
public class UserService {
@Resource
UserMapper userMapper;
public Set<Role> getRoles(String userName) {
if (userName == "" || userName == null) {
return null;
}
Set<Role> roleList = userMapper.getRoles(userName);
return roleList;
}
public Set<Permission>getPermissions(String userName) {
if (userName == "" || userName == null) {
return null;
}
Set<Permission> permissions = userMapper.getPermissions(userName);
return permissions;
}
public User getByUsername(String userName) {
if (userName == "" || userName == null) {
return null;
}
return userMapper.getByUsername(userName);
}
}9、自定义Realm添加角色和添加授权;
AuthorizationInfo方法中添加角色和添加授权;
@Override
//用来为当前登陆成功的用户授予权限和角色
protected AuthorizationInfo doGetAuthorizationInfo(PrincipalCollection principalCollection) {
System.out.println("授权操作");
User user = (User) principalCollection.getPrimaryPrincipal();
String userName=user.getUserName();
SimpleAuthorizationInfo authorizationInfo = new SimpleAuthorizationInfo();
//添加角色
Set<Role> roles = userService.getRoles(userName);
//将roles转为set<String>roleNames
Set<String>roleNames=new HashSet<>();
for (Role role : roles) {
roleNames.add(role.getRoleName());
}
authorizationInfo.setRoles(roleNames);
//添加授权
Set<Permission> permissionSet = userService.getPermissions(userName);
//将roles转为set<String>roleNames
Set<String>permissions=new HashSet<>();
for (Permission permission : permissionSet) {
permissions.add(permission.getPermissionName());
}
authorizationInfo.setStringPermissions(permissions);
return authorizationInfo;
}10、shiroConfig配置文件添加角色认证和权限认证;
在shiroConfig的ShiroFilterFactoryBean方法中添加角色认证和权限认证;
filter.put(“/user/add”,“perms[user:add]”);
filter.put(“/user/update”,“roles[admin,boss]”);
@Bean
public ShiroFilterFactoryBean getshShiroFilterFactoryBean(@Qualifier("securityManager") DefaultSecurityManager securityManager) {
ShiroFilterFactoryBean shiroFilterFactoryBean=new ShiroFilterFactoryBean();
shiroFilterFactoryBean.setSecurityManager(securityManager);
//添加shiro内置过滤器
/*
* 常用过滤器:
* anon:无需认证(登录)可以访问
* authc:必须认证才可以访问
* user: 如果使用remmemberMe的功能可以直接访问
* perms: 该资源必须得到资源权限才可以访问
* roles:该资源必须得到角色权限才可以访问
* */
Map<String,String> filter=new LinkedHashMap<>();
//filter.put("/user/add","anon");
//filter.put("/user/update","authc");
//授权过滤器
filter.put("/user/add","perms[user:add]");
filter.put("/user/update","roles[user,boss]");
//未授权就跳转到该页面
shiroFilterFactoryBean.setUnauthorizedUrl("/user/unAuth");
//拦截所有请求包括html也会被拦截
// filter.put("/*","authc");
shiroFilterFactoryBean.setFilterChainDefinitionMap(filter);
shiroFilterFactoryBean.setLoginUrl("/user/toLogin");
shiroFilterFactoryBean.setSecurityManager(securityManager);
return shiroFilterFactoryBean;
}测试:
yg1有user:权限,yg2中有user:add权限所以可以访问*/user/add**,yg3没有这些权限不能访问,yg1没有被授权user或boss角色所以不能访问/user/update而yg2被授权boss,yg3被授权user所以能访问;
20、 thymeleaf整合shiro
1.导入依赖
<dependency>
<groupId>com.github.theborakompanioni</groupId>
<artifactId>thymeleaf-extras-shiro</artifactId>
<version>2.1.0</version>
</dependency>2.shiroConfig配置类添加bean
@Bean
public ShiroDialect getShiroDialect() {
return new ShiroDialect();
}3.编写前端代码
xmlns:shiro=“http://www.pollix.at/thymeleaf/shiro” 导入后才能有shiro标签提示;
xmlns:th=“http://www.thymeleaf.org” 导入后才能有thymeleaf标签提示;
shirol:标签后面的条件成立才会显示该标签的内容
常用shirol:标签解释
shiro:guest=“” 验证当前用户是否为“访客”,即未认证(包含未记住)的用户。
<p shiro:guest="">Please <a href="login.html">login</a></p>shiro:user=“” 认证通过或已记住的用户
<p shiro:user="">Welcome back </p>shiro:authenticated=“” 已认证通过的用户。不包含已记住的用户,这是与user标签的区别所在
<a shiro:authenticated="" href="update.html">Update your information</a>shiro:principal 输出当前用户信息,通常为登录帐号信息。
<p>Hello, <shiro:principal/>, how are you today?</p>shiro:notAuthenticated=“” 未认证通过用户,与authenticated标签相对应。与guest标签的区别是,该标签包含已记住用户。
shiro:hasRole=“xxx” 验证当前用户是否属于xxx角色
<a shiro:hasRole="admin" href="admin.html">Administer the system</a><!-- 拥有该角色 -->shiro:lacksRole=“xxx” 与hasRole标签逻辑相反,当用户不属于该角色时验证通过
shiro:hasAllRoles=“xx1, xx2” 验证当前用户是否属于以下所有角色
shiro:hasAnyRoles="xx1, xx2 " 验证当前用户是否属于以下任意一个角色
shiro:hasPermission =“” 与Role的使用相同也有对应的lacksPermission等
<!DOCTYPE html>
<html lang="en"
xmlns:shiro="http://www.pollix.at/thymeleaf/shiro"
xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<p th:text="${msg}"></p>
<div shiro:hasPermission="user:update">
<a href="/user/update">更新:</a>
</div>
<div shiro:hasPermission="user:add">
<a href="add">添加:</a>
</div>
</body>
</html>yg1有user:权限所以都能显示,yg2只有user:add权限只能显示添加,yg2只有user:update权限只能显示更新;
只有经过controller层进行模板解析后跳转的html页面shiro标签才会起效;

















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









