






借鉴博客:几张图彻底搞定Seq2Seq
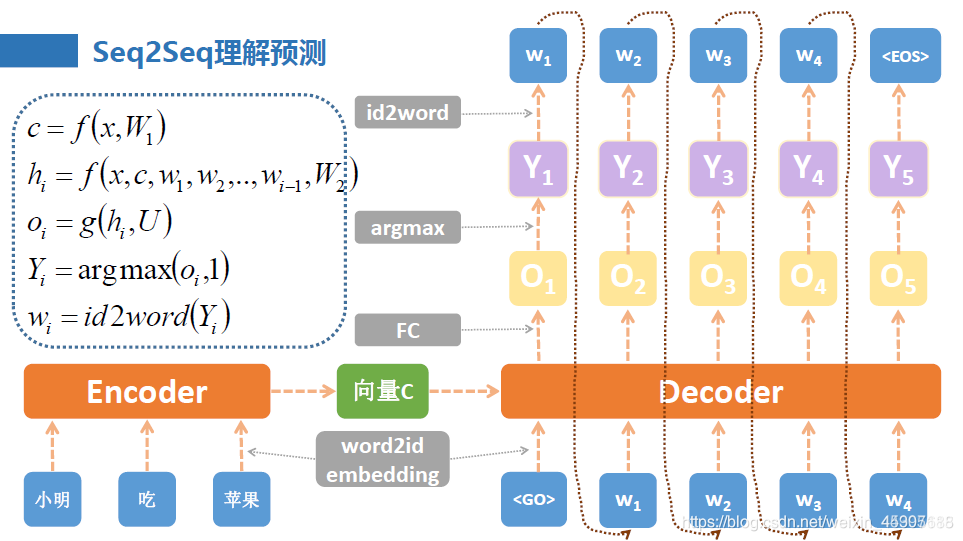
Sequence to Sequence模型由两部分组成:Encoder和Decoder。在机器翻译过程中,假设要将汉语翻译成英语,首先,我们需要两个词典,一个是汉语的词语与数字(index)的一一对应的词典,另一个是英语单词与数字(index)的一一对应的词典,这样,就可以由词语得到数字,也可以由数字得到词语。
1.Encoder部分:对于输入的一句汉语,将其切割成汉语词语,通过查汉语词典得到词语对应的数字,将每个数字转换为一个固定长度的向量,作为循环神经网络RNN的输入,例如
X
1
,
X
2
,
X
3
X_1,X_2,X_3
X1,X2,X3,先输入
X
1
X_1
X1,与初始状态
H
0
H_0
H0一起,得到
H
1
H_1
H1,然后由
X
2
X_2
X2和
H
1
H_1
H1得到
H
2
H_2
H2,再由
H
2
H_2
H2和
X
3
X_3
X3一起得到
H
3
H_3
H3,这个
H
3
H_3
H3即最后一个隐状态作为向量C传入Decoder。
2.Decoder部分:里面也是一个循环神经网络RNN,向量C作为这个RNN的初始隐状态,由英语词典将英语词语转换为数字,并转换为向量作为Decoder中RNN的输入,与初始隐状态一起得到各个时间的隐状态,隐状态与一个数相乘经过softmax之后得到图中的
O
i
O_i
Oi,是一个概率分布,再经过argmax得到一个整数
Y
i
Y_i
Yi,这个数通过英语词典得到其对应的英语单词。
Sequence to Sequence模型理解
最新推荐文章于 2023-02-21 19:42:47 发布
















 367
367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









