






生产者-消费者模型是一种并发编程模型,用于解决多线程或多进程之间的数据共享和同步问题。这种模型通常用于描述生产者和消费者之间的关系,其中生产者生成数据,而消费者消费这些数据。典型的场景包括生产者不断地将数据放入一个共享的缓冲区,而消费者则从缓冲区中取出数据并进行处理。
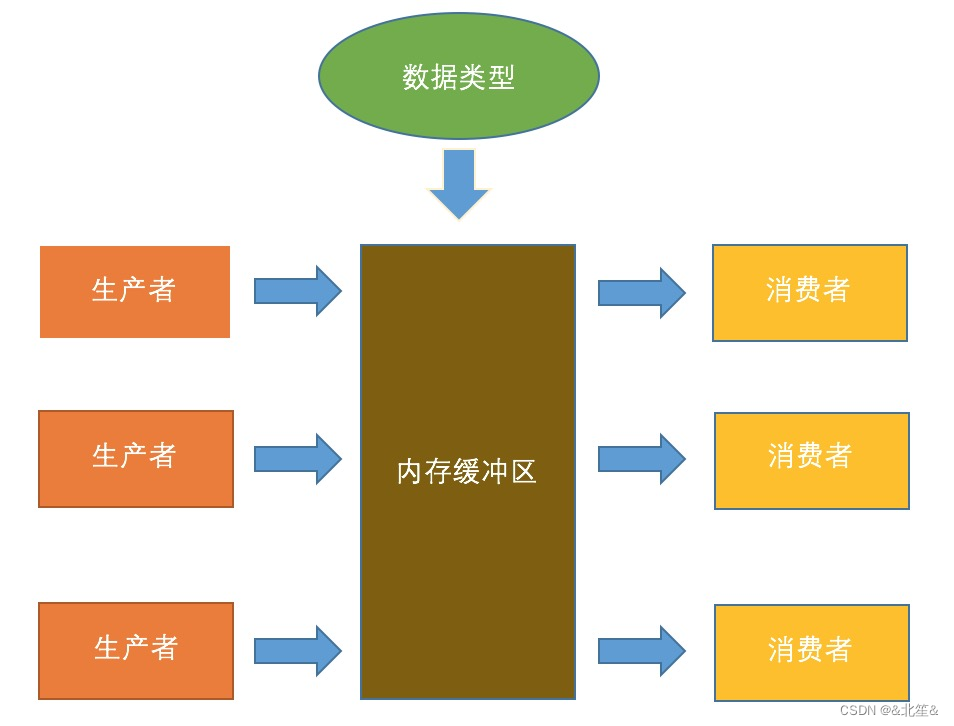
以下是生产者-消费者模型的主要组成部分和运作原理:
-
生产者(Producer):生产者是一个实体,负责生成数据并将数据放入共享的缓冲区。生产者在生成数据后,将数据添加到缓冲区中,并通常会在添加数据后通知消费者,以便消费者可以处理这些数据。
-
消费者(Consumer):消费者是另一个实体,负责从共享缓冲区中取出数据并进行处理。消费者会从缓冲区中获取数据,处理它们,然后可能释放资源或执行其他操作。
-
共享缓冲区(Shared Buffer):共享缓冲区是用于存储生产者生成的数据的数据结构。这个缓冲区的大小通常是有限的,因此在某些情况下,生产者必须等待缓冲区中有可用的空间,而消费者必须等待缓冲区中有数据可供消费。
-
同步机制:为了确保生产者和消费者之间的协同工作,通常需要使用同步机制,如互斥锁、信号量或条件变量。这些机制用于控制对共享缓冲区的访问,以避免竞态条件和数据不一致性。
生产者-消费者模型的核心问题是如何协调生产者和消费者的活动,以避免以下问题:
-
缓冲区溢出:当缓冲区已满时,生产者应该等待,直到有足够的空间。这通常需要使用信号量或条件变量来实现。
-
缓冲区为空:当缓冲区为空时,消费者应该等待,直到有数据可供消费。也需要使用信号量或条件变量来实现。
-
互斥访问:确保生产者和消费者不会同时访问缓冲区,以防止数据损坏。这通常需要使用互斥锁来实现。
生产者-消费者模型的实现方式可以根据具体的编程语言和环境而有所不同,但核心思想是相似的。这种模型有助于解决多线程或多进程编程中的资源共享和同步问题,确保数据一致性和线程安全。















 7459
7459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









