pandas. read_csv( filepath_or_buffer: Union[ str , pathlib. Path, IO[ ~ AnyStr] ] , sep= ',' , delimiter= None ,
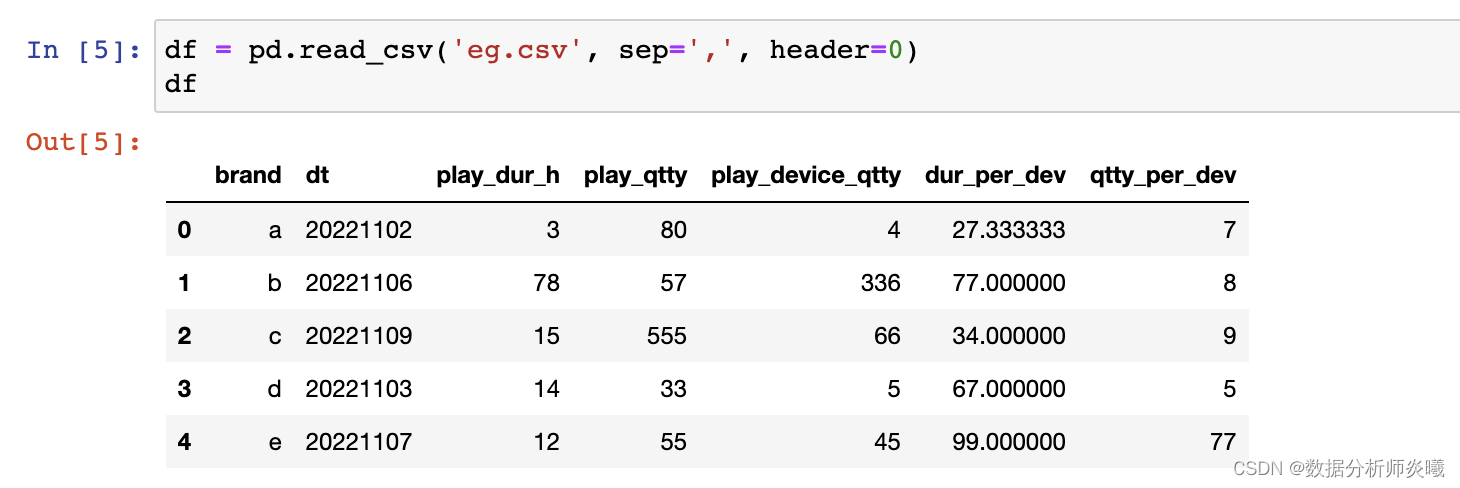
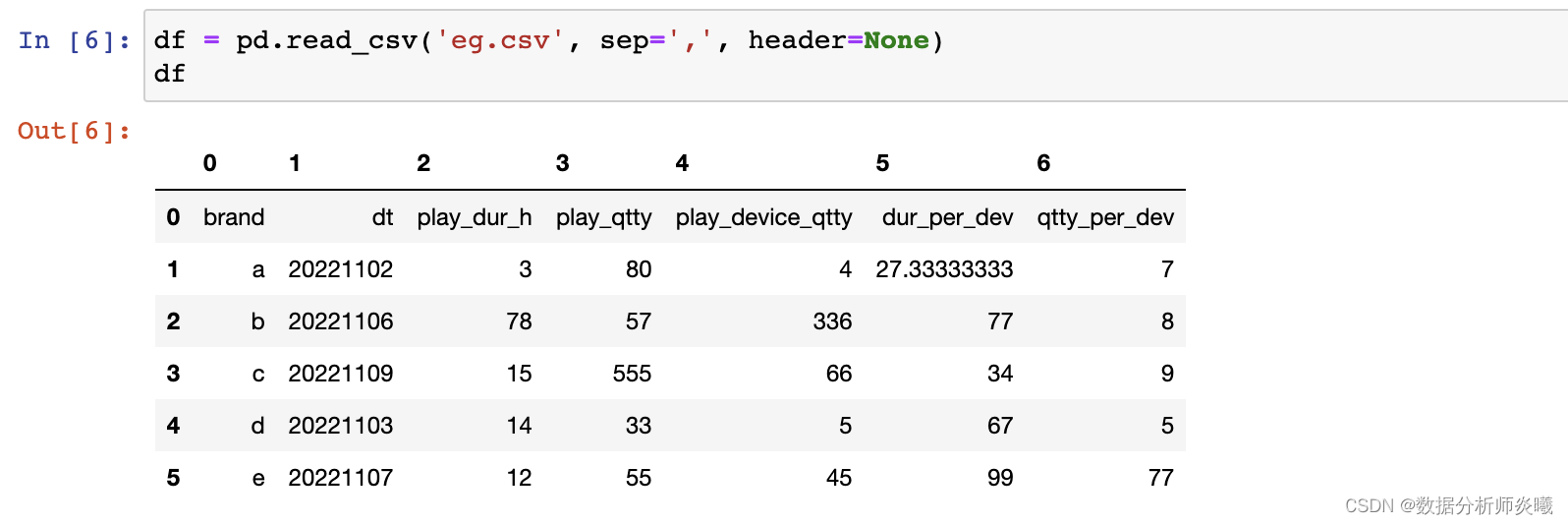
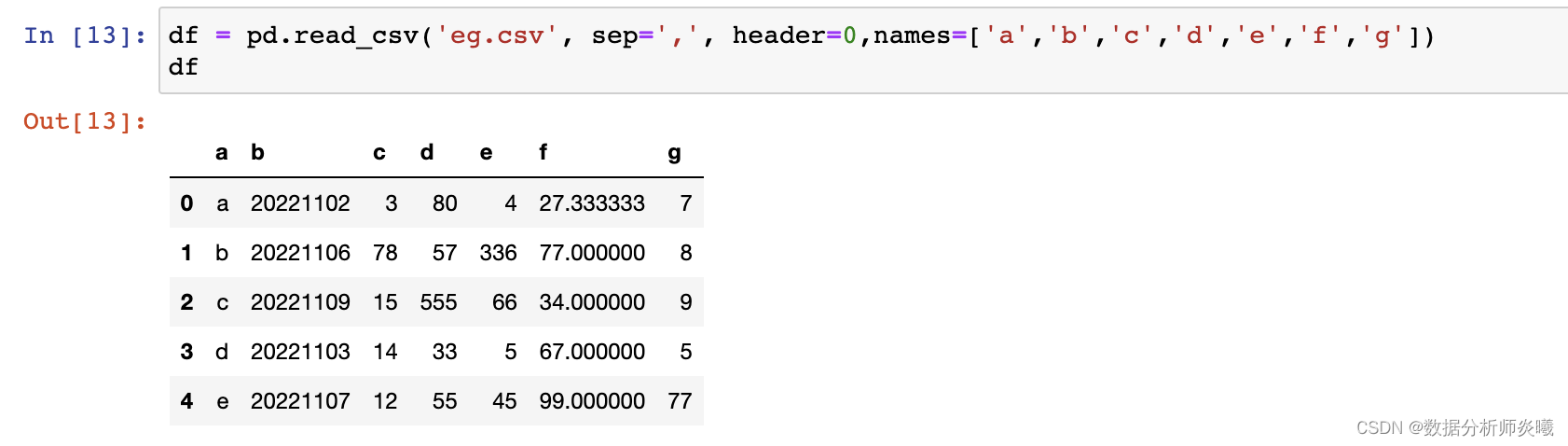
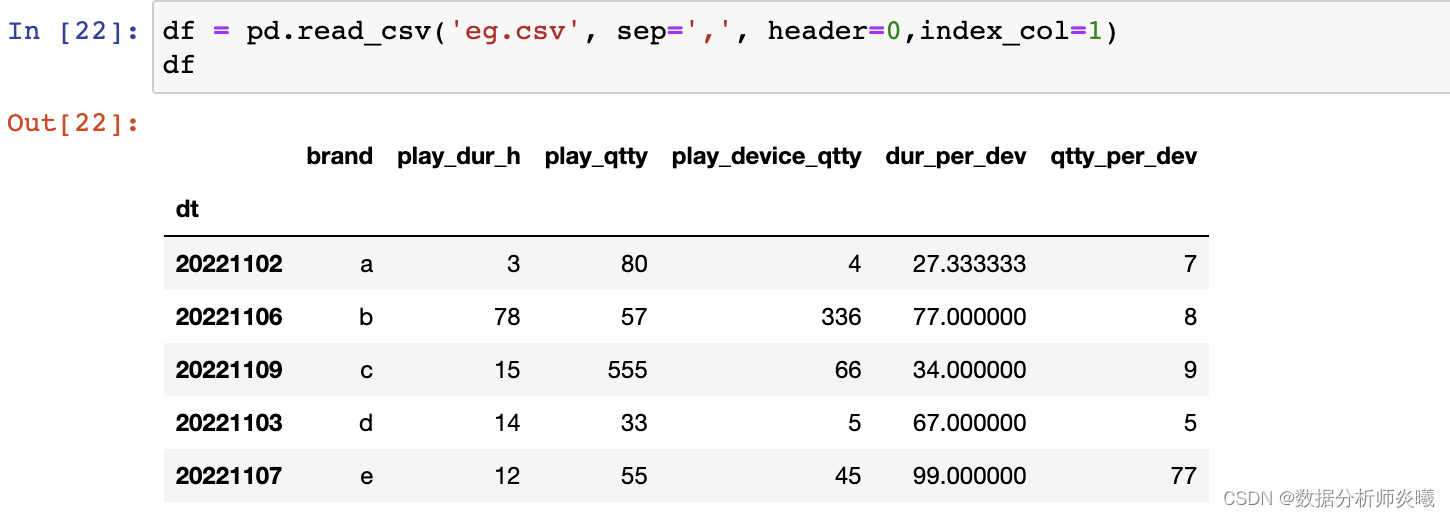
header= 'infer' , names= None , index_col= None , usecols= None , squeeze= False , prefix= None ,
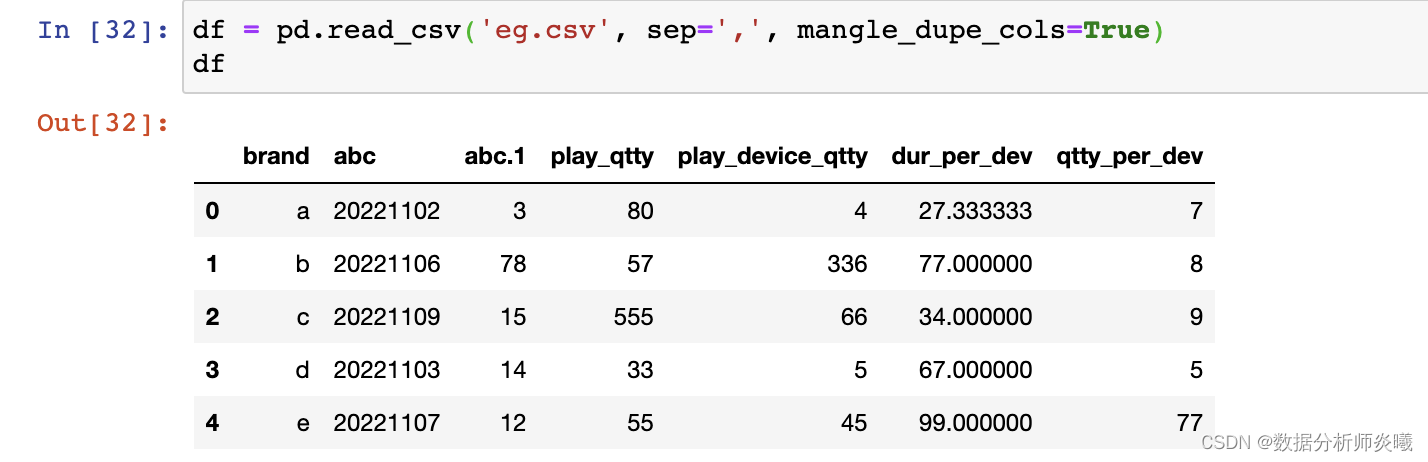
mangle_dupe_cols= True , dtype= None , engine= None , converters= None , true_values= None ,
false_values= None , skipinitialspace= False , skiprows= None , skipfooter= 0 , nrows= None , na_values= None ,
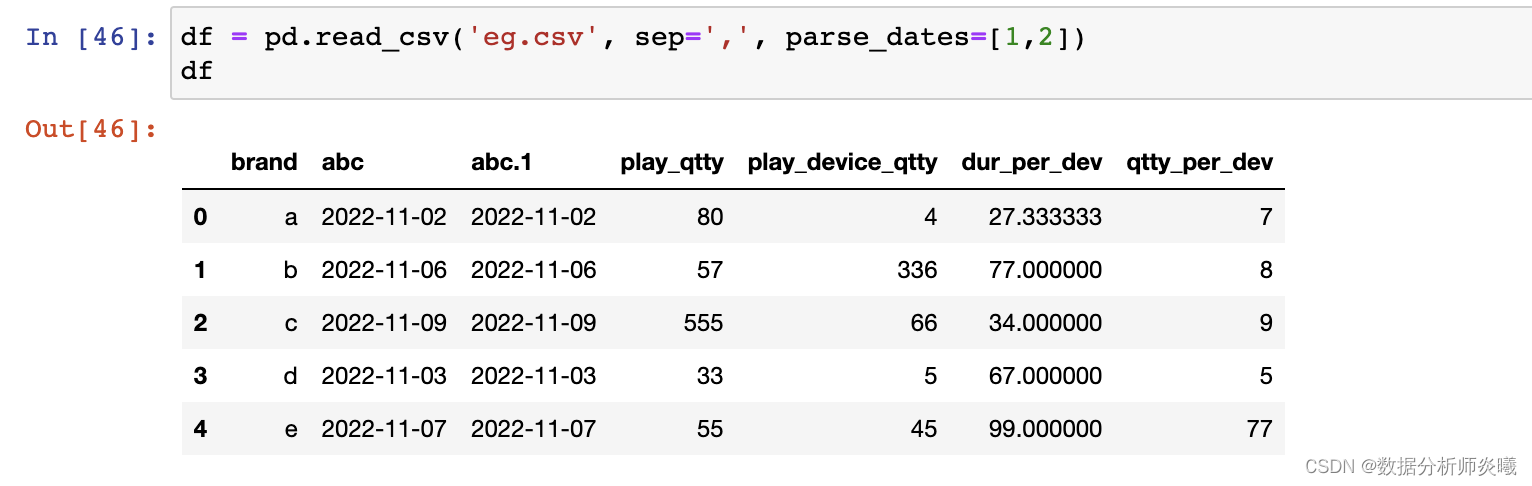
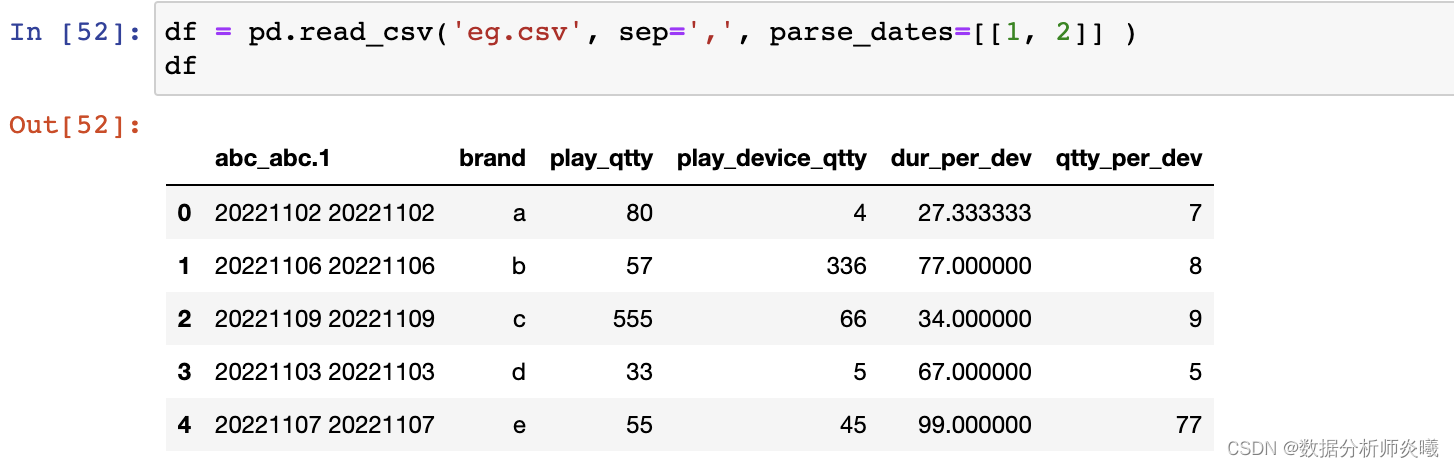
keep_default_na= True , na_filter= True , verbose= False , skip_blank_lines= True , parse_dates= False ,
infer_datetime_format= False , keep_date_col= False , date_parser= None , dayfirst= False , cache_dates= True ,
iterator= False , chunksize= None , compression= 'infer' , thousands= None , decimal: str = '.' , lineterminator= None ,
quotechar= '"' , quoting= 0 , doublequote= True , escapechar= None , comment= None , encoding= None ,
dialect= None , error_bad_lines= True , warn_bad_lines= True , delim_whitespace= False , low_memory= True ,
memory_map= False , float_precision= None )
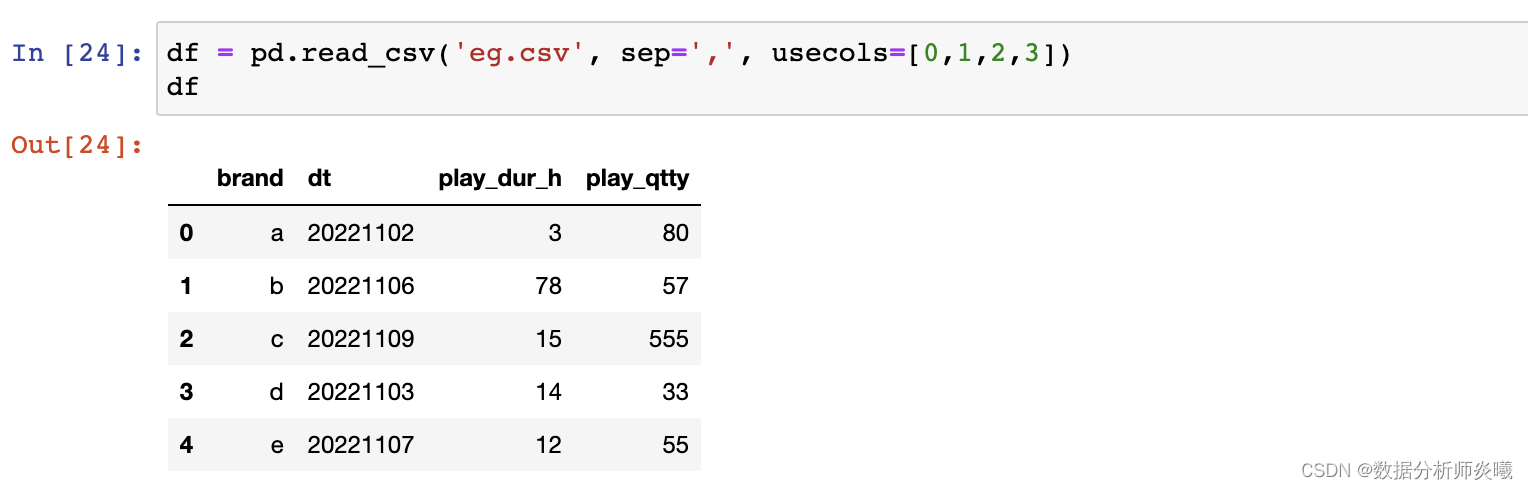
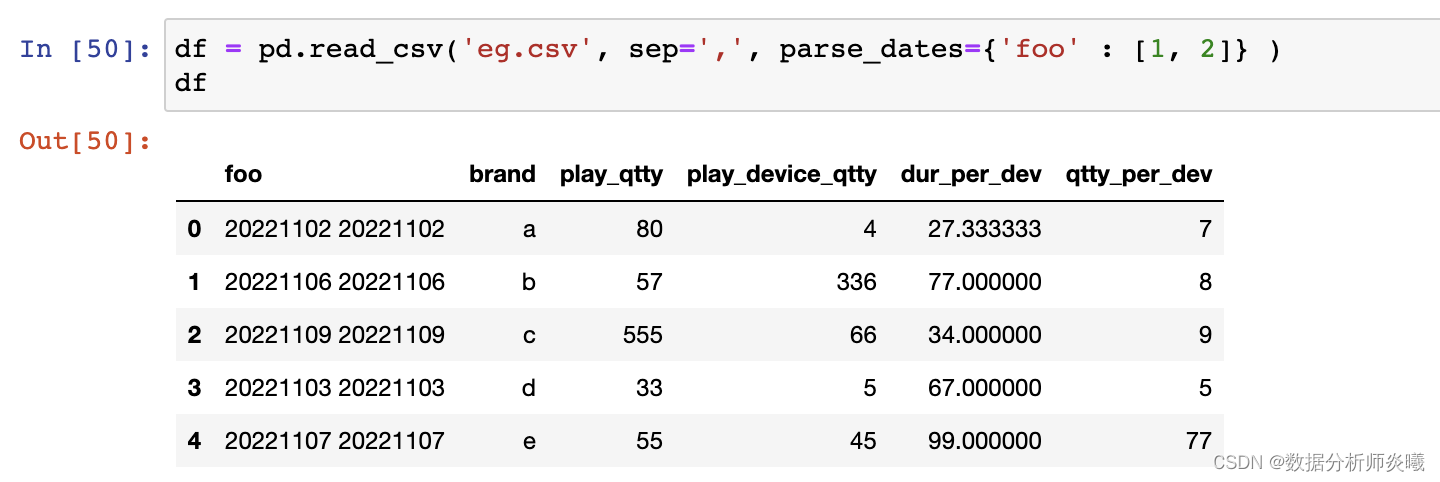
filepath_or_buffe r:字符串或路径对象sep :str, default ‘,’delimiter:sep的别名,也是分隔符 header :int, list of int, default ‘infer’names :array-like, optionalindex_col:int, str, sequence of int / str, or False, default None usecols:list-like or callable, optional squeeze:bool, default False prefix:str, optional mangle_dupe_cols:bool, default True dtype : Type name or dict of column -> type, optionalengine:{‘c’, ‘python’}, optional converters:dict, optional nrows :int, optionalna_values:scalar, str, list-like, or dict, optional na_filter:bool, default True skip_blank_lines:bool, default True parse_dates:bool or list of int or names or list of lists or dict, default False keep_date_col:bool, default False compression:{‘infer’, ‘gzip’, ‘bz2’, ‘zip’, ‘xz’, None}, default ‘infer’ comment: str, optional encoding :str, optionalpandas. read_excel( io, sheet_name= 0 , header= 0 , names= None , index_col= None , usecols= None ,
squeeze= False , dtype= None , engine= None , converters= None , true_values= None , false_values= None ,
skiprows= None , nrows= None , na_values= None , keep_default_na= True , verbose= False , parse_dates= False ,
date_parser= None , thousands= None , comment= None , skipfooter= 0 , convert_float= True ,
mangle_dupe_cols= True , ** kwds)
io:路径 sheet_name:str, int, list, or None, default 0 其他参数都与csv重复。 pandas. read_json( path_or_buf= None , orient= None , typ= 'frame' , dtype= None ,
convert_axes= None , convert_dates= True , keep_default_dates= True , numpy= False ,
precise_float= False , date_unit= None , encoding= None , lines= False , chunksize= None ,
compression= 'infer' )
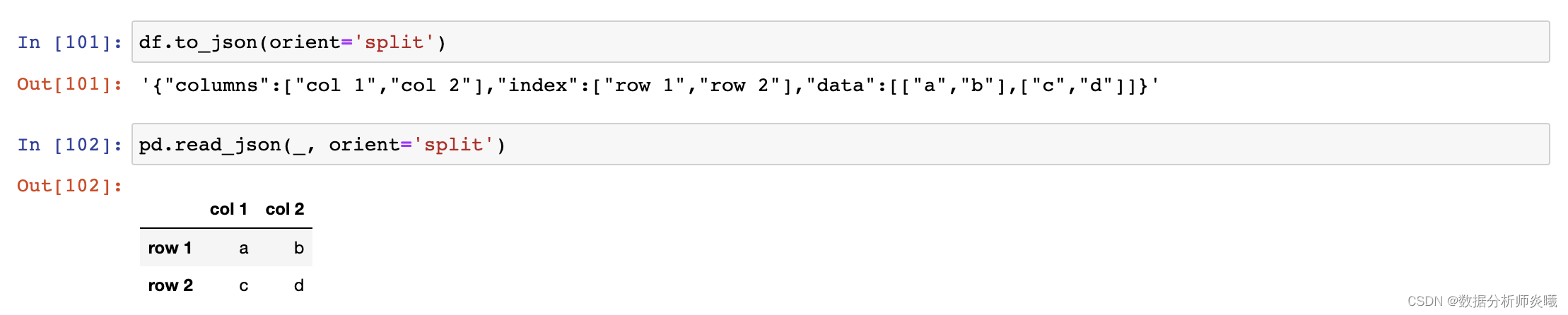
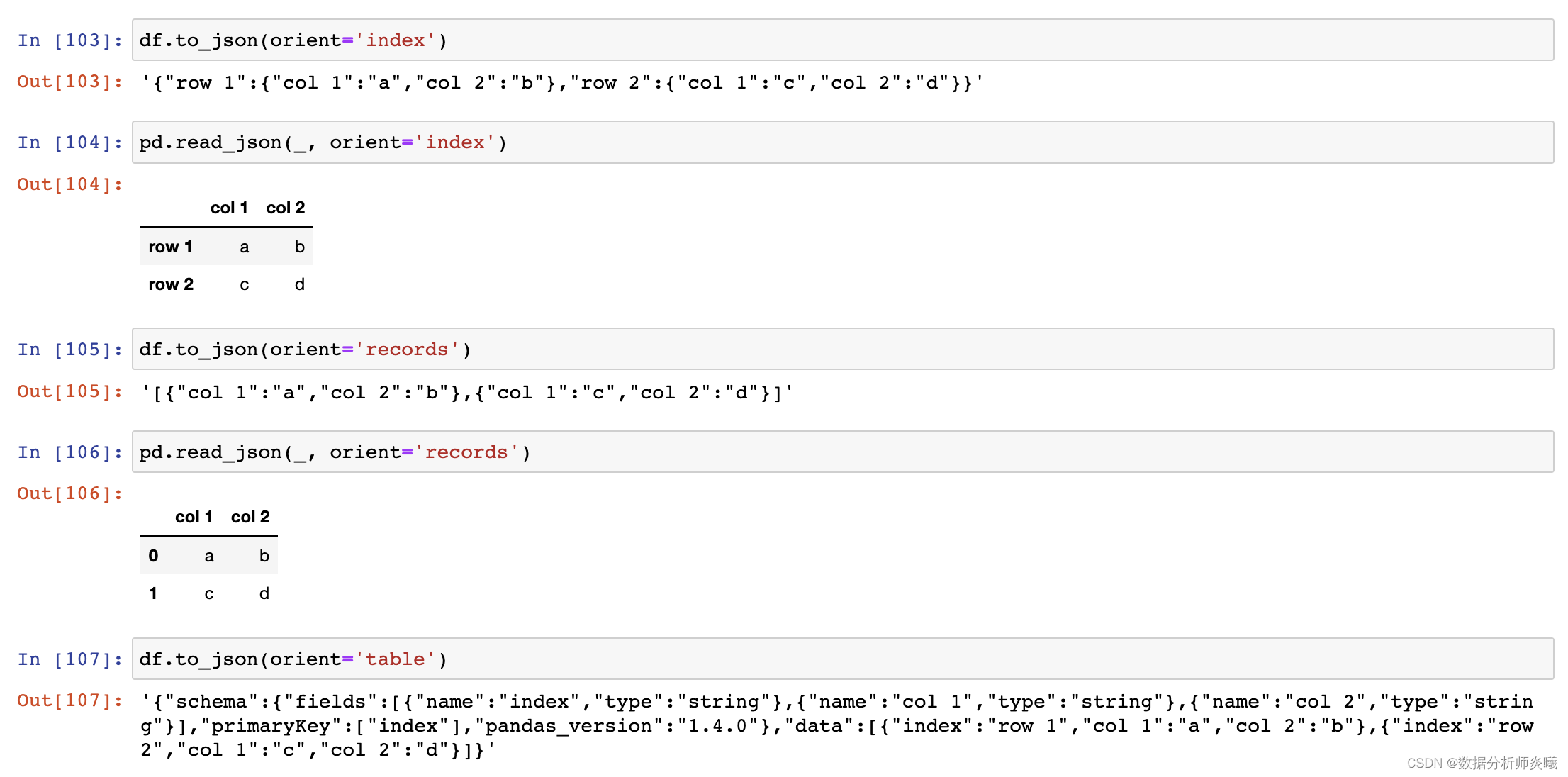
path_or_buf:a valid JSON str, path object or file-like object typ:{‘frame’, ‘series’}, default ‘frame’ orient:str dtype:bool or dict, default None convert_dates:bool or list of str, default True

























 809
809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









