






这一期开始,我们将要深入讨论Spark的结构化API,主要有DataFrame,SQL,Dataset,分享过程中若有错谬,欢迎拍砖。
Part 2.Structured APIs——DataFrames,SQL,and Datasets
Charpter 4.Structured API Overview
这一部分将深入探讨Spark的结构化API。结构化API是处理各种数据类型的工具,从非结构化的日志文件,到半结构化的CSV文件,再到高度结构化的Parquet文件。结构化API一般指如下三种核心的分布式集合类型的API:
- Dataset
- DataFrames
- SQL表和视图
这三种类型在本书的不同部分有所介绍,大多数结构化API均适用于批处理和流处理,这意味着使用结构化API编写代码时,很容易可以在批处理和流处理程序之间相互转换。
结构化API是在编写大部分数据流时会用到的基础抽象概念。在本章中,首先介绍一些需要理解的基本概念:类型化和非类型化的API,及它们的区别;核心术语是什么; Spark如何将结构化API数据流实际应用,并在集群上执行它。然后,我们将提供具体的任务信息来处理某些类型的数据或数据源。
我们先回顾一下第一篇分享中介绍的基本概念和定义。 Spark是一个分布式编程模型,用户可以在其中指定转换操作,多次转换操作会建立起指令的DAG(direct acyclic graph)(有向无环图)。指令图的执行过程中,由一个action操作触发,期间一个作业会被分解为多个stage和task,在集群上执行transformation和action操作的逻辑结构是DataFrame和Dataset,每执行一次transformation会都会创建一个新的DataFrame或Dataset,每一次action则会触发计算,或者将DataFrame和Dataset转换成本地语言类型。
DataFrames and Datasets
按第一期分享所介绍,Spark有两种结构化集合类型:DataFrame和Dataset。接下来我们先了解它们各自的定义,再介绍它们间细小差别。
DataFrame和Dataset具有明确的行和列,类似于分布式数据表的集合。所有列的行数相同(可用null指定缺省值),某列的类型必须和表中的所有行保持一致。 Spark中的DataFrame和Dataset是不可变的数据集合,可以通过它对表中特定行列进行操作,操作将以惰性方式执行。当在DataFrame上执行action时,将触发Spark执行具体的transformation操作并返回结果,这些代表了如何操纵行和列来计算出用户期望结果的执行计划。
表和视图与DataFrame基本相同,所以我们通常在DataFrame上执行SQL操作,而不是用DataFrame专用的执行代码。为了使这些定义更具体,需要先讨论一下Schema数据模式, Schema数据模式定义了该分布式集合中存储的数据类型。
Schemas
Schema定义了DataFrame的列名和类型,可以手动定义或者从数据源读取schema(通常叫做schema on read)。 Schema由类型组成,意味着你需要指定数据列的类型和列的位置顺序。
Overview of Structured Spark Types
Spark实际上有它自己的编程语言, Spark内部使用一个名为Catalyst的引擎,在计划制定和执行作业的过程中维护自身的类型信息,这会带来很大的优化空间,显著提高性能。 Spark类型直接映射到不同语言API,包括Scala、Java、Python、SQL和R语言,都有一个对应的API查找表。比如,下面例子中,不会在Scala或Python中执行加法,实际上仅在Spark中执行加法。

这是因为Spark会将用输入语言编写的表达式转换为相同功能的Spark内部Catalyst表示。然后,它将在内部表示中运行。在讨论为什么会出现这种情况之前,我们先来讨论Dataset。
DataFrames versus Datasets
结构化API包含两类API,即无类型的DataFrame和有类型的Dataset。说DataFrame是无类型可能不太准确,因为它们其实是有类型的,只是Spark完全负责维护它们的类型,仅在运行时检查这些类型是否与schema中指定的类型一致。与之相对应的, Dataset在编译时就会检查类型是否符合规范。 Dataset仅适用于基于JVM的语言(如Scala和Java),并通过case类或Java beans指定类型。
大多情况下,你可能会用到DataFrame。在Scala版本的Spark中,DataFrame就是一些Row类型的Dataset集合。“Row”类型是Spark的内部表示形式,用于内存格式的计算优化。这种格式让计算更高效,因为如果使用JVM的类型,会带来巨大的垃圾回收和对象实例化成本,而Spark可以基于自己的内部格式运行,不会产生这种开销。对于Python或R语言版本的Spark,没有Dataset,一切都是DataFrame,这样我们就能用这种优化的数据格式进行计算处理。
内部Catalyst格式在很多Spark演示中都有详细介绍。充分理解DataFrame,Spark类型,Schema,是要一些时间的,需要强调的是,当用户使用DataFrame时,会大大受益于这种优化过的Spark内部格式。接下来,介绍一些相对来说更熟悉的概念:列和行。
Columns
列可以表示一个简单类型,如整数,字符串,也可以表达一个复杂类型,如数组,map映射,也可以表示空值null。Spark可以记录所有这些类型信息,并提供多种方法来转换列。后面将对列类型进行更广泛的讨论,简单来说,可以将Spark列想象为一个数据表的列。
Rows
一行对应一个数据记录。DataFrame中的每条记录都必须是Row类型。我们可以通过SQL手动创建,也可以从RDD,从数据源,或从头创建这些行。下面我们用range()来创建一个row对象的数组。
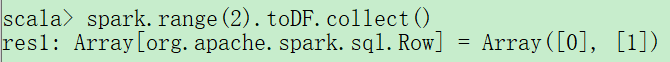
Spark Types
之前我们提到Spark内部有大量内部类型表示。接下来将提供一些方便查阅的参考表,它标示了在用户语言和Spark类型的对应关系。在看到参考表之前,让我们看看如何声明和实例化一个属于某种类型的列。

原文依次列举了Python,Scala,Java语言的对比图,为避免文章过于冗长,这里先展示scala,有其它语言需求可以去原书查阅比较。
Table 4-2. Scala type reference
| Data type | Value type in Scala | API to access or create a data type |
|---|---|---|
| ByteType | Byte | ByteType |
| ShortType | Short | ShortType |
| IntegerType | Int | IntegerType |
| LongType | Long | LongType |
| FloatType | Float | FloatType |
| DoubleType | Double | DoubleType |
| DecimalType | java.math.BigDecimal | DecimalType |
| StringType | String | StringType |
| BinaryType | Array[Byte] | BinaryType |
| BooleanType | Boolean | BooleanType |
| TimestampType | java.sql.Timestamp | TimestampType |
| DateType | java.sql.Date | DateType |
| ArrayType | scala.collection.Seq | ArrayType(elementType, [containsNull]) containsNull默认为true |
| MapType | scala.collection.Map | MapType(keyType, valueType, [valueContainsNull]) valueContainsNull默认为true |
| StructType | org.apache.spark.sql.Row | StructType(fields) fields是包含StructFields的Array,不允许使用同名fields |
| StructField | Scala中的数据类型的值类型,如Int是数据类型IntegerType的StructField | StructField(name, dataType, [nullable]),nullable的默认值为true |
类型会随着Spark SQL版本更新而变化,建议参考最新的Spark官方文档。所有这些类型都很有用,但用户几乎不会用到纯静态的DataFrame对象,而是会一直操作和转换它们。接下来将要介绍结构化API中的执行过程。
Overview of Structured API Execution
本节将演示用户代码是如何在集群上执行的,这对理解编写代码过程和在集群上执行代码的过程都很有帮助,也有助于后期的调试。接下来我们将针对一个结构化API查询任务,逐步分析从用户代码到执行代码的过程。步骤如下:
- 编写DataFrame / Dataset / SQL代码。
- 如果是有效代码, Spark会将其转换为一个逻辑执行计划。
- Spark将此逻辑执行计划转化为一个物理执行计划,并在此过程中检查优化。
- Spark通过RDD操作,在集群上执行该物理执行计划。
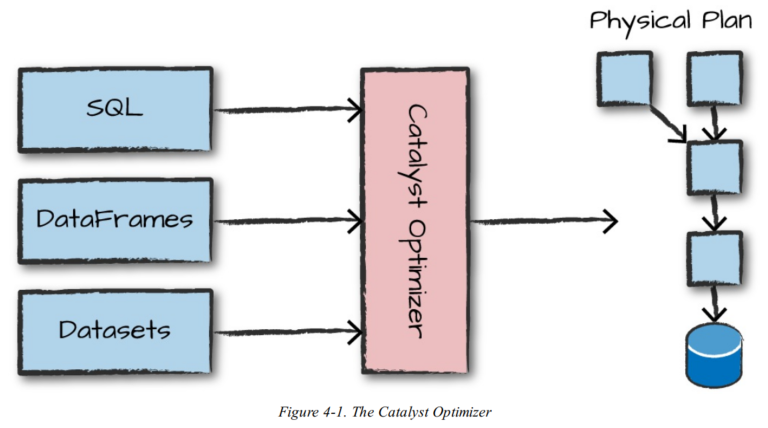
我们编写的代码通过控制台提交给Spark,或以一个Spark作业的形式提交。然后代码将交由Catalyst优化器决定如何执行,并指定一个执行计划。最后代码被运行,并将结果返回给用户。下图展示了整个过程。
Logical Planning
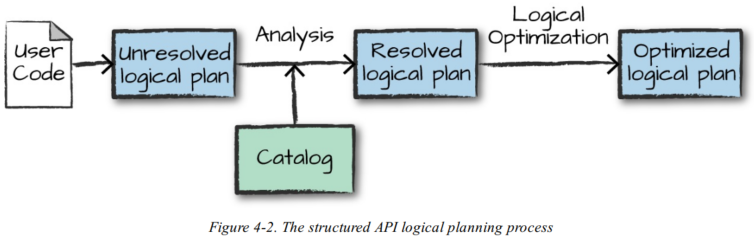
执行的第一阶段旨在获取用户代码并将其转换为逻辑计划。下图展示了该过程。
Physical Planning
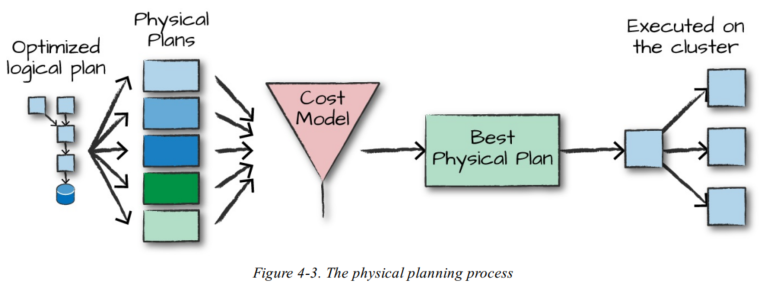
在成功创建优化的逻辑计划后, Spark开始执行物理计划流程。物理计划(通常称为Spark计划)通过生成不同的物理执行策略,并通过代价模型进行比较分析,从而指定如何在集群上执行逻辑计划,具体流程如下图所示。例如执行一个连接操作就会涉及代价比较,它通过分析数据表的物理属性(表的大小或分区的大小),对不同的物理执行策略进行代价比较,选择合适的物理执行计划。
Execution
在选择一个物理计划时, Spark将所有代码运行在底层编程接口RDD上。 Spark在运行时执行进一步优化,生成可以在执行期间优化task或stage的本地Java字节码,最终将结果返回给用户。
Conclusion
在本章中,我们介绍了Spark结构化API,以及Spark如何将你的代码转换为在集群上实际执行的代码。接下来的分享中,将介绍一些核心概念以及如何使用结构化API的关键功能。















 655
655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









