






上一篇分享,我们了解了一些关于Spark架构,应用程序,结构化API,核心概念的内容,有了这些作为基础,这期我们将对Spark工具集的相关内容进行译文和学习,分享过程中若有错谬,欢迎拍砖。
Charpter 3.A Tour of Spark’s Toolset
在第一期分享中,有下述图例,事实上,除了低级API和结构化API,Spark还提供了一系列标准库来实现额外功能,比如图分析,机器学习,流处理,以及其他计算和存储系统的集成能力等。

1、spark-submit;
2、dataset;
3、结构化流处理;
4、机器学习和高级分析;
5、RDD;
6、SparkR;
7、第三方软件包生态系统。
Running Production Applications
Spark让开发和创建大数据程序变得容易,其内置命令行工具 spark-submit,让用户可以将交互式开发程序转变为生产应用程序。spark-submit首先将应用程序发送到集群,然后启动它并在集群中执行。一旦提交,应用程序就会运行至结束或抛出报错。spark-submit支持在所有集群管理器(Standalone,Mesos和YARN)中执行。spark-submit 提供了一些控制选项,用户可以指定applications所需资源,运行应用程序运行方式,命令行参数。用户可以用Spark支持的所有语言编写程序并提交执行,最简单的就是在本地计算机上运行application。
现在我们运行一个Spark的example,它的功能是按一定精度计算pi值,local参数值表示本地运行,通过更改master参数也可以将应用提交给运行着Spark独立集群管理器,Mesos或YARN的集群,10是目标jar包的程序入参。

Datasets:Type-Safe Structured APIs
我们要说的第一个Spark结构化API是Dataset,它是类型安全版本,被用在Java和Scala中编写静态类型代码。它在Python和R中不可用,因为这些语言是动态类型的。上一篇博文分享的DataFrame是Row类型对象的分布式集合,被用来存储各种类型的表格数据。而Dataset API让用户可以用Java / Scala类,去定义DataFrame的每条记录,并将其作为类型对象集合进行操作,如Java的ArrayList,Scala的Seq。 Dataset上可用的API是类型安全的,即Dataset对象不会被视为与初始定义类不相同的另一个类。这在编写大型应用程序时十分有效,不同开发者可通过定义好的接口进行交互。
Dataset类通过内部包含对象的类型进行参数化,如Java的Dataset ,Scala的Dataset [T] 。举个例子,Dataset [Person]只包含Person类的对象。从Spark 2.0开始,受支持的类型遵循Java的JavaBean模式,或Scala的case类。这些类型之所以受限,是因为Spark需要可以自动分析类型T,并为Dataset中的表格数据创建适当模式。
Dataset的一个优点是,只有当你需要时才可以使用它们。下面例子中,我们将定义自己的数据类型,并通过某种map函数和filter函数来操作它。操作完成后, Spark可以将其自动重新转换为DataFrame,且可以用Spark包含的数百个函数对其进行进一步操作,这样可以很容易地降到较低级的API,以便于在必要时执行类型安全的编码,同时,也可以将其升级到更高级的SQL,进行更快速的分析。下面的例子,展示了如何用类型安全函数和类似于DataFrame的SQL表达式来快速编写业务逻辑。


Structured Streaming
结构化流处理是用来处理数据流的高级API,Spark 2.2及之后版本可用。用户可以像在批处理模式下一样,用Spark的结构化API执行结构化流处理,结构化流处理可以减少等待时间,且允许增量处理。它能让用户快速从流式系统中提取有价值的信息,而且几乎不需要更改代码。用户可以按批处理模式进行设计,然后将其转换为流式作业,即增量处理数据,这使得流处理任务变得更简单。
下面举个例子,看如何使用Spark结构化流处理。我们用到销售数据集(/tree/master/data/retail-data),该数据集有特定日期和时间信息,我们将使用按天分组的文件,每个文件代表一天的数据。我们用另外一个进程来模拟持续产生的数据,假设这些数据是由零售商持续生成的,并由我们的结构化流式处理作业进行处理。这里先简单展示一个数据样本,以便看到数据格式。
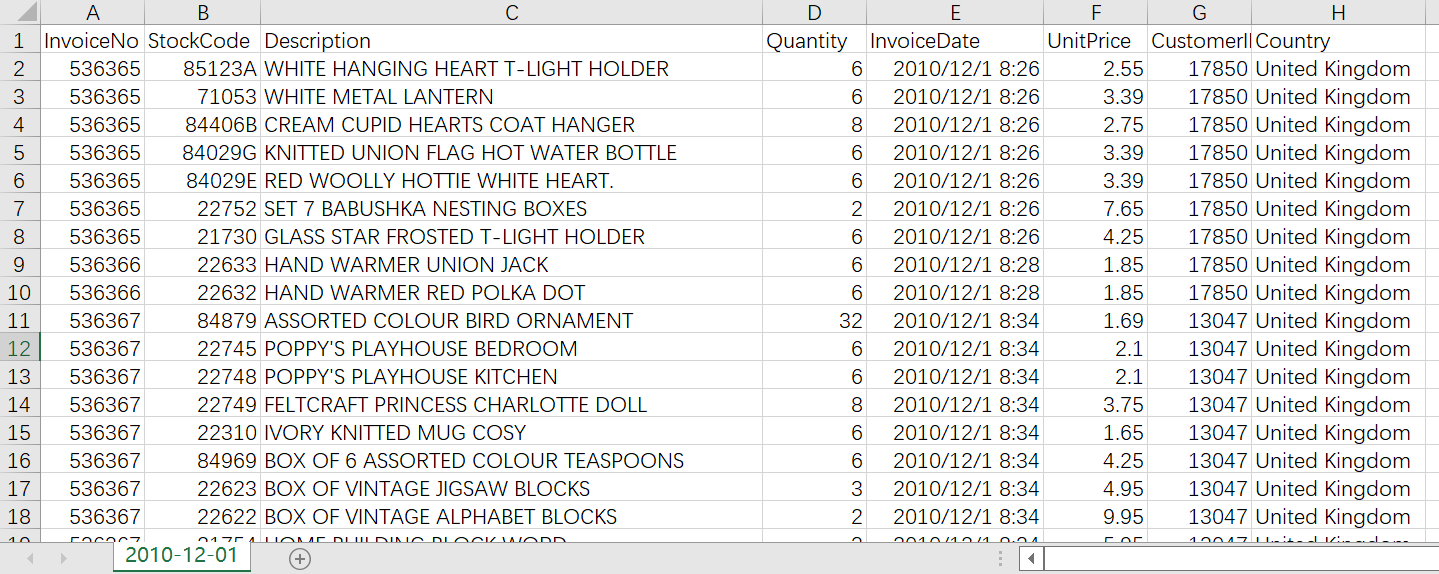
tips:spark-shell中有很多命令都是以:开始,比如退出为:quit。:paste 可以让spark-shell进入复制模式,复制完代码后,按下ctrl + D开始执行代码。(有兴趣可以参考https://blog.csdn.net/Android_xue/article/details/100517574)

由于我们处理的是时间序列数据,因此需要提一下Spark是如何对数据进行分组和聚合的。在下面的例子中,我们将查看特定客户(主键为CustomerId)进行大笔交易的时间。我们会添加一个总费用列,并查看客户花费最多的时间。window函数包含每天的所有数据,它在我们的数据中,充当的是时间序列栏的窗口作用,这是一个用来处理日期和时间戳的有用工具,我们可以通过时间间隔来指定我们的需求,而Spark会把所有数据集合起来传递给用户。
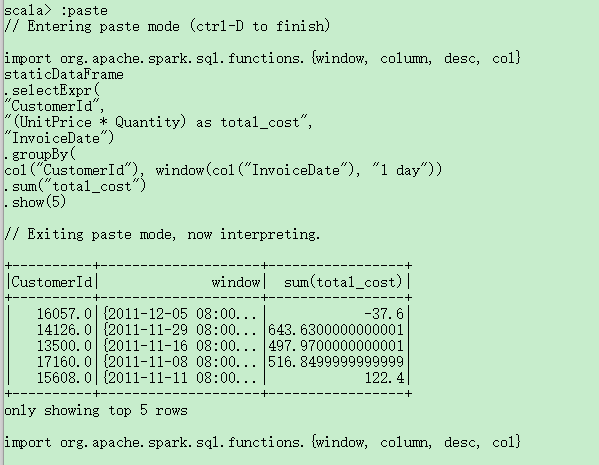
如果是运行在本地模式,最好将shuffle分区数设置为更适合本地模式的数量,该配置指定了在shuffle后,应该创建的分区数量。默认值是200(但由于本书作者机器上没有足够的执行进程,他把分区数减少为5)。


我们对流数据执行与之前静态DF一样的业务逻辑(按时间窗口统计花费)。



Machine Learning and Advance Analysis
Spark使用MLlib机器学习算法内置库,来支持大规模机器学习。Mllib支持对数据进行预处理、整理、模型训练和大规模预测,甚至可以用MLlib中训练的模型在结构化流处理中对流数据进行预测。 Spark提供了一个复杂的机器学习API,用于执行各种机器学习任务,从分类到回归,从聚类到深度学习。为了说明这个功能,我们将使用称为k-means的标准聚类算法对数据执行一些基本的聚类操作。k-means是一种聚类算法。首先从数据中随机选出k个初始聚类中心,最接近某个中心的那些点被分配到一个聚类里,并根据分配到该聚类的点计算它们的中心,这个中心被称为centroid。然后,将最接近该centroid的点标记为属于该centroid的点,并根据分配到某个centroid的点群计算新的中心用来更新centroid。 重复这个过程来进行有限次的迭代,或者直到收敛(中心点停止变化)。
Spark准备了许多内置的预处理方法,下面将演示这些预处理方法,这些预处理方法将原始数据转换为合适的数据格式,它将在之后用于实际训练模型中,并进一步进行预测。
之前的案例,其数据由多种不同类型表示,包括时间戳、整数和字符串等。而MLlib中的机器学习算法要求将数据表示为数值形式,因此我们需要将这些数据进行转换。下面我们将用几个DataFrame转换来处理日期数据。













Lower-Level APIs
Spark包含很多低级原语,以支持用RDD对任意Java和Python对象进行操作,事实上, Spark所有对象都建立在RDD之上。DataFrame操作也是基于RDD的,这些高级操作会被编译到较低级的RDD上执行,以便实现极其高效的分布式执行。有些时候你可能会使用RDD,尤其是在读取或操作原始数据时,但大多时候你应该坚持用高级的结构化API。 RDD比DataFrame更低级,因为它向终端用户暴露物理执行特性(如分区)。可以用RDD来并行化已经存储在驱动器机器内存中的原始数据。例如,让我们并行化一些简单的数字并创建一个DataFrame,我们可以将RDD转换为DataFrame,以便与其他DataFrame一起使用它。

SparkR
SparkR是一个在Spark上运行的R语言工具,它具有与Spark其他支持语言相同的设计准原则。要使用SparkR,只需将SparkR库导入到环境中并运行。它与Python API非常相似,只是它遵循R的语法而不是Python的。大多时候, SparkR支持Python支持的所有功能。
Spark’s Ecosystem and Packages
Spark最好的地方就在于开源社区维护的工具包和支持它的生态系统,工具在成熟并广泛使用后甚至可以直接进入Spark的核心项目。我们可以在https://spark-packages.org/找到Spark Packages的索引,所有用户都可以将自己开发的工具包发布到此代码库中,还可以在网上(如GitHub)找到各种其他项目和工具包。
Conclusion
本章展示了将Spark应用到业务与技术中的多种方法, Spark简单强大的编程模型使其可以轻松应用于各类问题的处理,并且还有大量开发人员创建围绕它的软件包,这帮助Spark可以处理大量的业务问题与挑战。随着生态系统和社区的增长,越来越多的工具包可能会持续出现。















 655
655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









