






 本文介绍了Apache Spark作为大数据处理引擎的核心特性,包括其统一平台的设计哲学,支持的计算引擎和软件库。Spark允许开发人员在多种语言环境下进行并行数据处理,适用于数据科学家和开发人员。文章详细阐述了Spark的DataFrame,Dataset和SQL等结构化API,以及如何在本地或集群上运行Spark。此外,还提及了大数据问题的背景以及启动Spark的交互式控制台的步骤。
本文介绍了Apache Spark作为大数据处理引擎的核心特性,包括其统一平台的设计哲学,支持的计算引擎和软件库。Spark允许开发人员在多种语言环境下进行并行数据处理,适用于数据科学家和开发人员。文章详细阐述了Spark的DataFrame,Dataset和SQL等结构化API,以及如何在本地或集群上运行Spark。此外,还提及了大数据问题的背景以及启动Spark的交互式控制台的步骤。
华罗庚先生说过,“把薄书读厚,把厚书读薄”。厚书读薄是梳理脉络,让整体结构变清晰。薄书读厚则是通过查证思考,对原文加以扩增,甚至达到批驳原文的程度。自小偏爱闲书,但在“生存”和“生活”的哲学问题下,还应多研学技术书籍,不进则退是学生时代起就存在的永恒话题,人总是需要在未雨绸缪地跳出舒适区,这也是《第二曲线》的核心要义。言归正传,今日要研学读薄的主角是《Spark
– The Definitive Guide》,学习分享过程中若有错谬,欢迎拍砖。
于外文书籍,硬怼总归枯燥乏味,力学笃行,学的目的是致用,有兴趣的朋友可以在GitHub数据集(https://github.com/databricks/Spark-The-Definitive-Guide)中,通过实操获取技术成就感,达到寓教于乐之效,为求原汁原味(有时是博主翻译水平有限),部分表述将引用精彩的原文(农夫山泉只是大自然的搬运工)。
Part 1.Gentle Overview of Big Data and Spark
Charpter 1.What Is Apache Spark
好家伙,开篇上来就一灵魂拷问,何为Apache Spark?简而言之,Spark是运行在集群上的开源大数据处理引擎,同时包括一系列可以并行处理数据的软件库(SQL,流处理,机器学习等)。受众是对大数据感兴趣的开发人员和数据科学家。它支持多种语言(Python, Java, Scala和R),可以在本地单机,或大规模服务器集群上运行,着实牛逼。
Apache Spark’s Philosophy
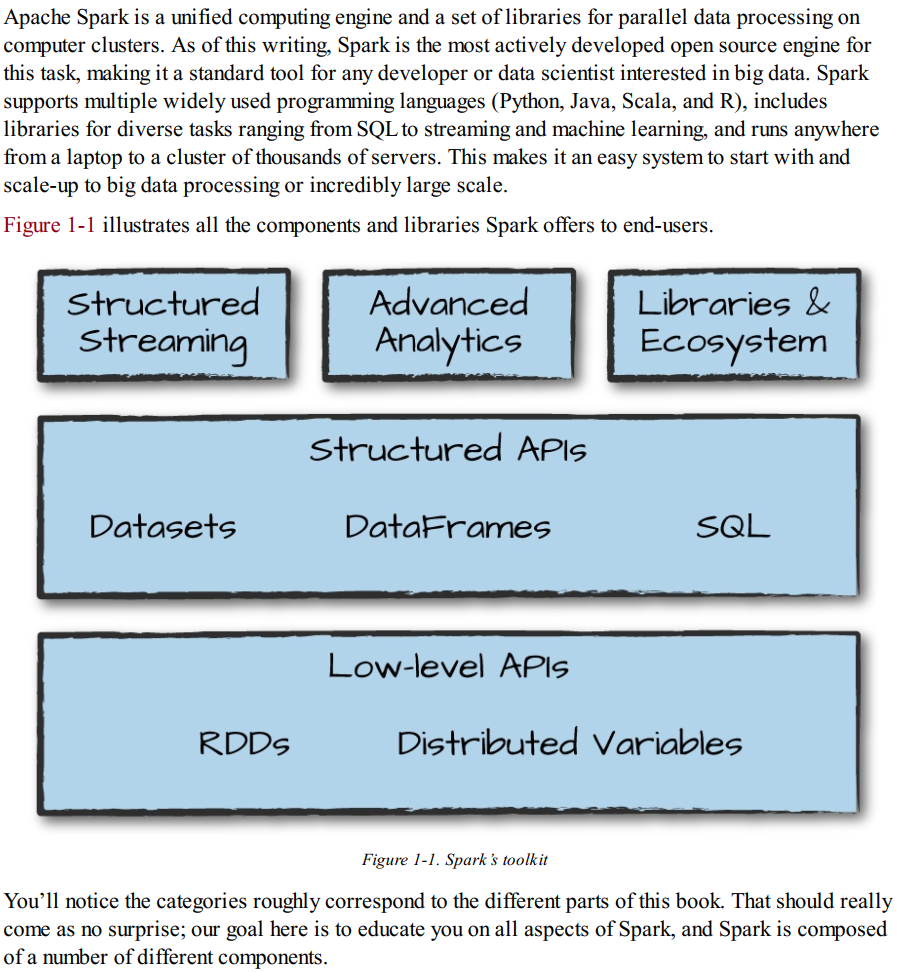
Spark的设计哲学,这小标题直接将段落逼格高高拉起。段落对Spark的关键组件进行了细分,它们依次是Unified(统一平台),Compute engine(计算引擎),Libraries(配套软件库)。
统一平台:由于Spark的设计初衷是为编写大数据应用程序提供一个统一平台(划重点,统一 ),统一的要义在于,Spark的计算引擎和API都是统一的,该设计理念的幕后黑手是,现实世界的数据分析任务中,结合了各种不同的处理类型和软件库。统一的好处是能更标准,更高效地支持广泛的数据分析任务,从数据加载,到SQL查询,再到机器学习,流式计算等。开发者都能用Spark提供的一致且可组合的API,代码块,软件库来构建应用程序,而后,再将不同库和函数进行组合,达到程序优化,高性能实现的目的。在Spark之前,没有任何开源系统为并行处理数据提供统一引擎,因此, Spark这种解脱了用户去拼凑多套API和系统来开发应用程序的平台,就迎来了迅猛发展。
原书在此处提到一个概念,Spark 2.0定义的“结构化API”,分别包括DataFrame, Dataset和SQL,博主也将在后续文章中重墨分享。
计算引擎:Spark从存储系统中加载数据,而后对其执行计算,值得注意的是,Spark本身不负责持久化数据,它主要专注于数据计算,但它兼容多种存储系统,因此可以将持久化存储系统与Spark结合使用。
Spark支持的存储系统有很多种,如Azure,S3、Hadoop、Cassandra,Kafka等。
软件库:Spark提供统一标准库,也支持开源社区中的许多第三方外部库。如今的Spark标准库,已成为一系列开源项目的集成,它的核心引擎自创始之日起其实基本不变,反倒是配套软件库日益强大。
https://spark-packages.org/ 上可以看到一系列外部库索引。
Context:The Big Data Problem
促使数据分析计算引擎发展的主要原因,是大数据问题。在相当长的一段时间里,CPU运行速度都保持逐年增长,应用程序也因此变得更快。可随着时间推移,应用程序需要处理更庞大的数据量,且硬盘散热也遇到瓶颈,硬件开发者们便在2005年左右,改变了提升单核能力的思路,转为开始研究并行计算。这一改变的直接结果,就是使得应用程序也要支持并行计算,这样才能更快运行。同时,从2005年起,数据存储和数据采集技术仍在飞速发展。它们的成本不断下调,使得我们的世界逐步演化成一个数据廉价的世界。想要处理好这些大规模数据,我们需要一种新的编程模型框架,使得程序并行化,计算并行化,Spark就是在这种新形势下应运而生。
Running Spark
Spark本身是用Scala编写的,它运行于JVM,若想在PC或集群上运行Spark,需要事先装好Java。同时,因为Spark支持Python, Java, Scala, R,SQL等语言的缘故,用户也需要装好对应前置依赖,以使用Python API为例,用户需要先安装好Python2.7及以上版本。这里提供了两种使用Spark的方法,它们分别是在个人电脑运行Spark,以及在Databricks Community Edition上运行基于Web的版本。
Downloading Spark Locally
- 首先,我们在本地先装好Java。

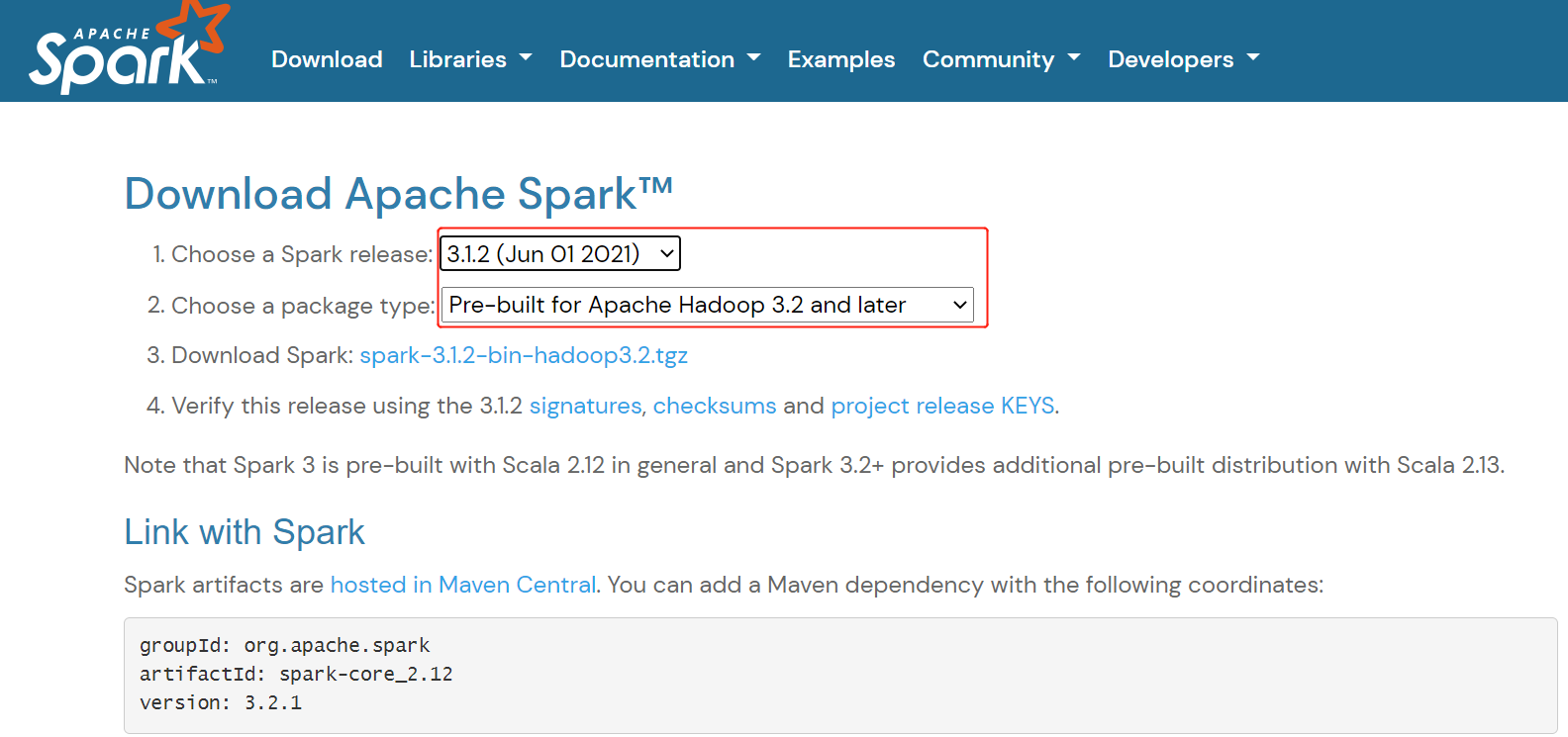
- 建议从Spark官方网址(http://spark.apache.org/downloads.html)拉取Spark。
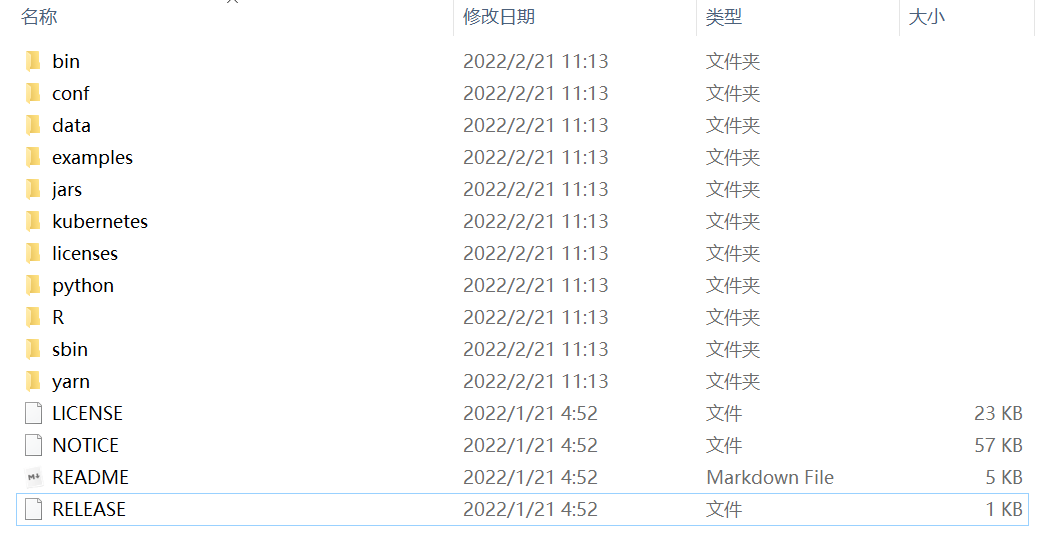
- 下载完毕并解压后,可以看到如下目录,不慌,之后的博文会对目录内容进行详细介绍。
Launching Spark’s Interactive Consoles
Spark支持交互式控制台的语言包括Python,Scala,SQL等。
刚开始运行时,如果有小伙伴遇到类似问题,可以检查hadoop客户端安装是否完善。
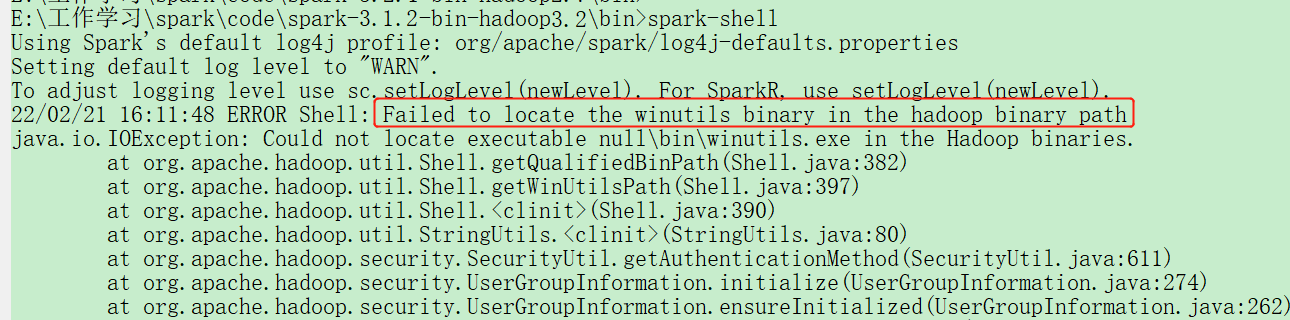
下面对HADOOP安装步骤做一个梳理:
1、下载并解压与Spark版本相对应的HADOOP客户端;
2、安装JDK,并配置JAVA_HOME;
3、检查的bin目录下是否有hadoop.dll,及winutils.exe,没有可以到gitee进行下载,
https://gitee.com/mirrors_cdarlint/winutils?_from=gitee_search;
4、依次配置HADOOP_HOME的系统变量,并添加至Path用户变量;
5、配置HADOOP。
参考链接:https://www.freesion.com/article/47651012308/
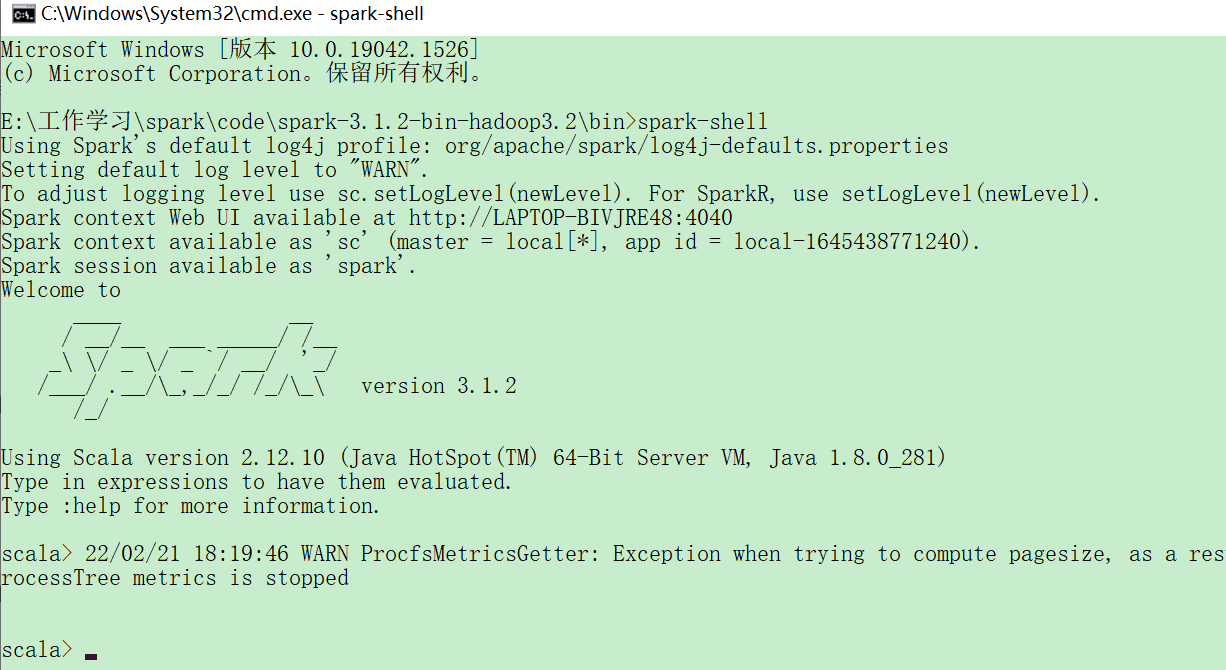
Launching the Scala Consoles
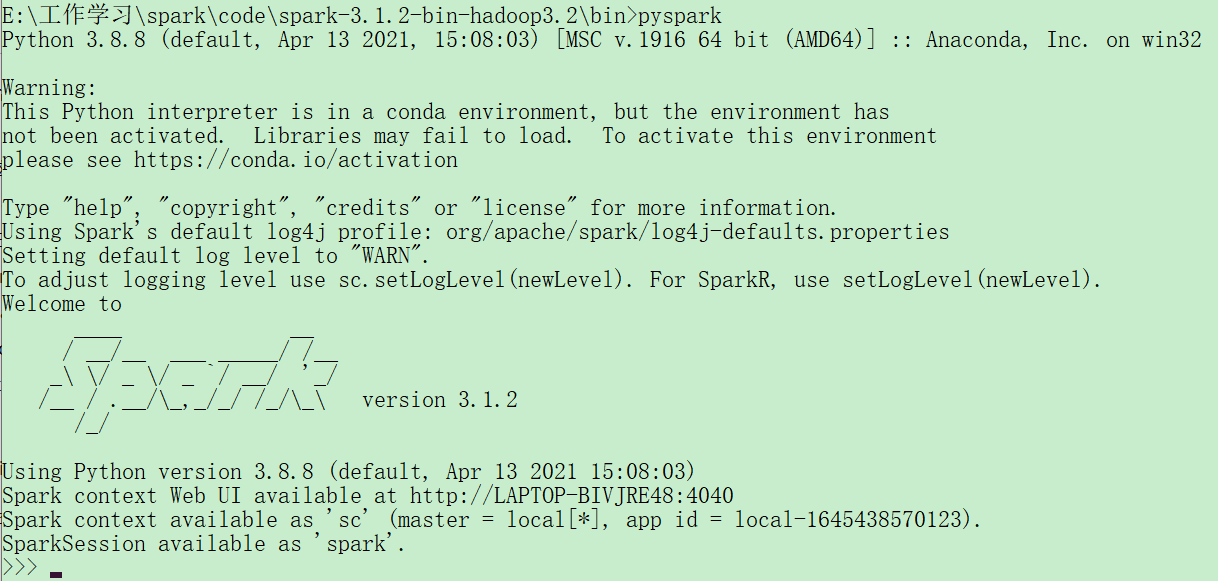
Launching the Python Consoles
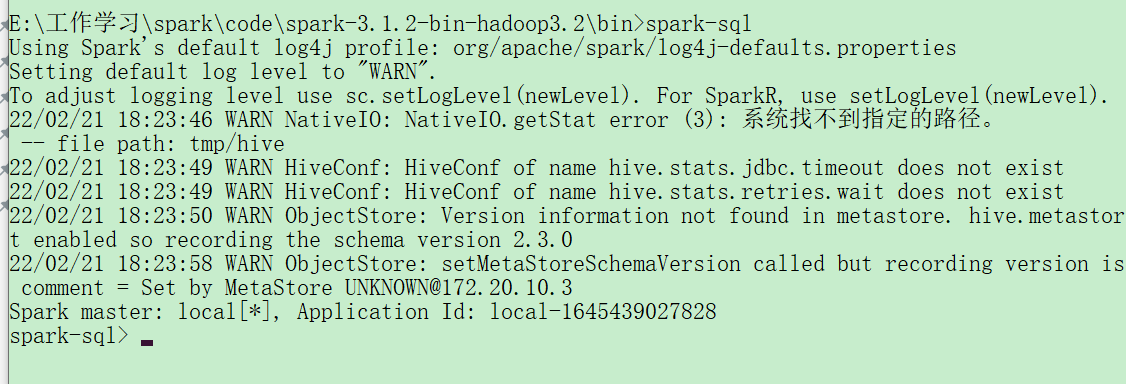
Launching the SQL Consoles
好了,今天的分享到此为止,往后还将有更多精彩片段与实操分享。文末引用著名小品艺术家,白云大妈的一句名言,“还有十万多字就截稿了”,感谢,我们下期再会。

















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









