






回顾
self-attention:
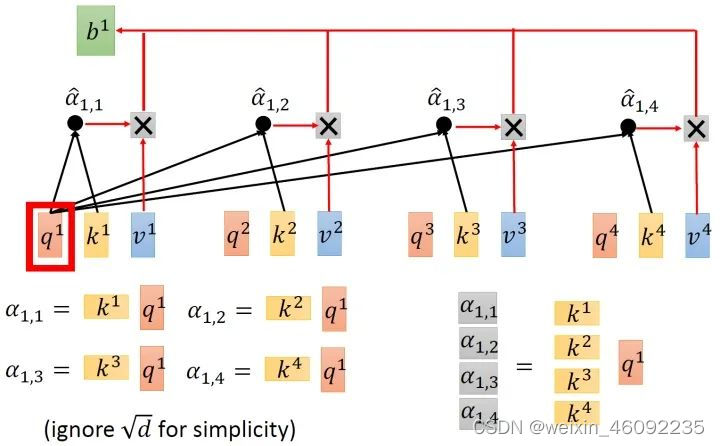
首先对于每一个输入,先进行embedding得到a1-a4,
进入self-attention层,乘以对应矩阵得到transformation matrix
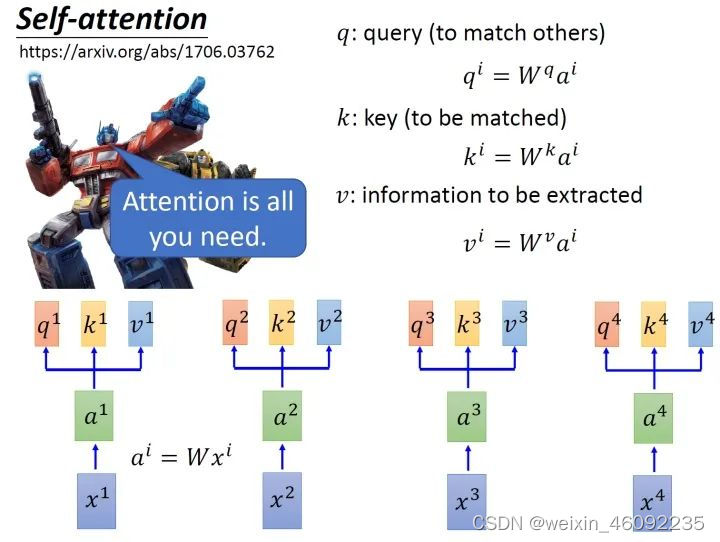
第二步是scaled dot-product attention,计算每一个输入与其他输入之间的关系,得数较大的关系紧密。得到结果之后送入softmax层。
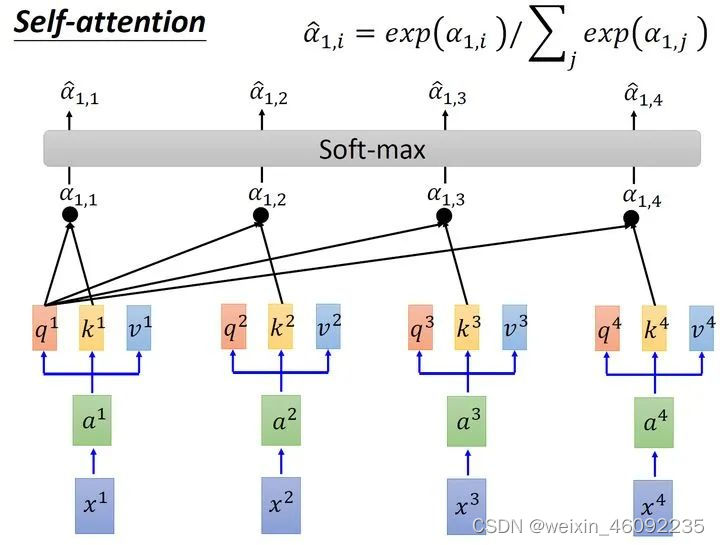
用softmax得到的值相当于一个权重,分别乘以对应的v值并求和就得到了最终结果。
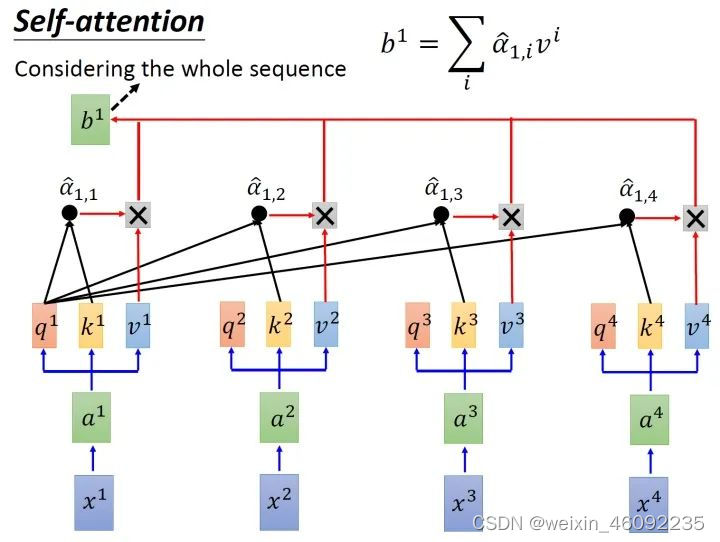
总体来说输出如下。
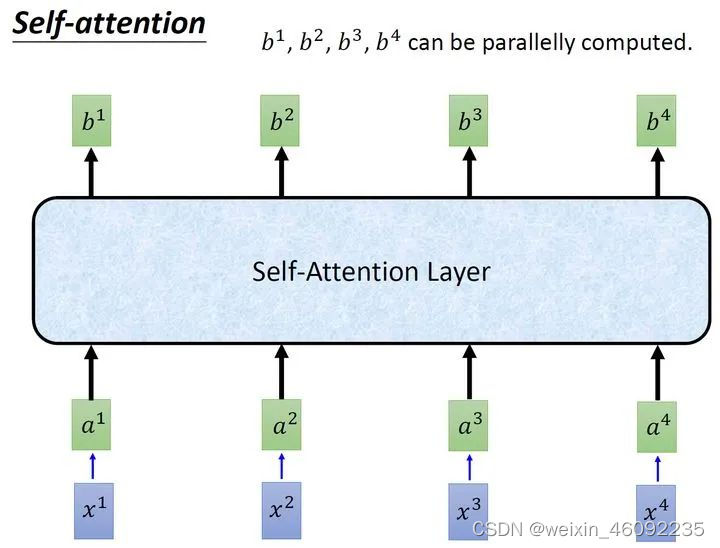
用矩阵来表示:

Multi-head Self-attention
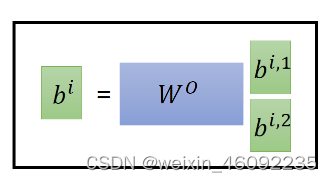
这部分我的理解是,几头注意力机制,每个输入就对应了几对qkv,然后每一个qkv之内计算对应的b。
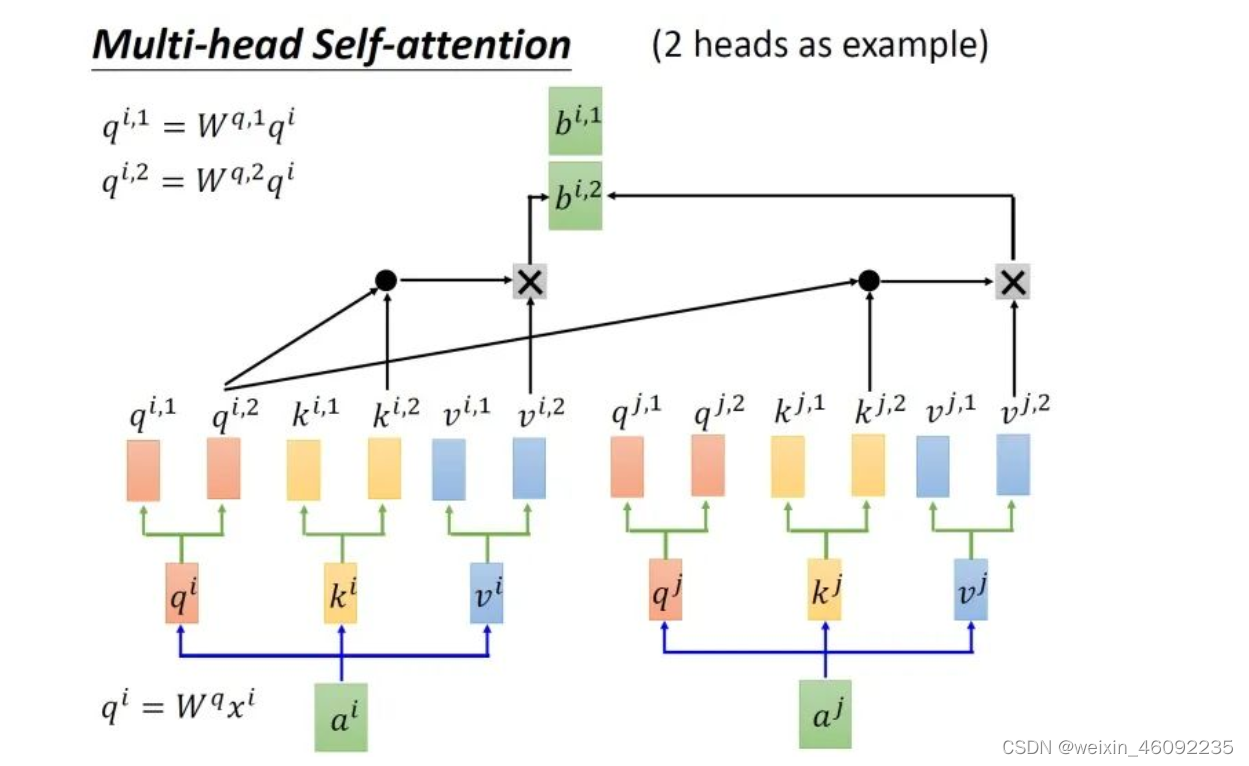
最后将两个输出进行拼接。得到的最终结果维度和单个头的输出结果维度相同。对这种方法我的理解是,对于不同的头,每一个头可以去注重特定部分的信息,比如两头注意力机制,一个头侧重全局的关系,一个侧重个别的输入点关系,这样就得到了多个侧重点不同的结果,并最后进行拼接。
Positional Encoding
上述的注意力机制没有包含输入的位置信息,这样会有问题。于是论文中加入了位置编码进行改进。论文中是将每一个词加入了0ne-hot 编码(这个编码我的理解是展示了该词汇在整个输入中的位置,在该位置处写1)
给每一个位置规定一个表示位置信息的向量 ei,让它与 ai加在一起之后作为新的 参与后面的运算过程,但是这个向量 ei是由人工设定的,而不是神经网络学习出来的。每一个位置都有一个不同的 ei。

文章中位置embedding的做法是运用如下公式:
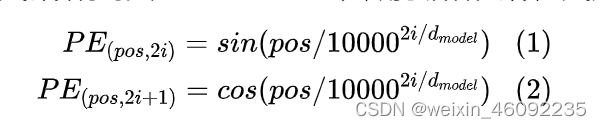
其中pos是该词汇在输入句子中的位置。当刚刚看到这个公示的时候感觉这个位置编码很麻烦,也不理解是为啥,然后看到博客里这样说的:

其实感觉one-hot编码也有这三种的优点,可能是论文作者在实验中发现这种方式效果好一些?也可能是采用one-hot的方式向量过于稀疏?后续准备自己尝试一下one-hot编码计算位置的方式。
核心部分
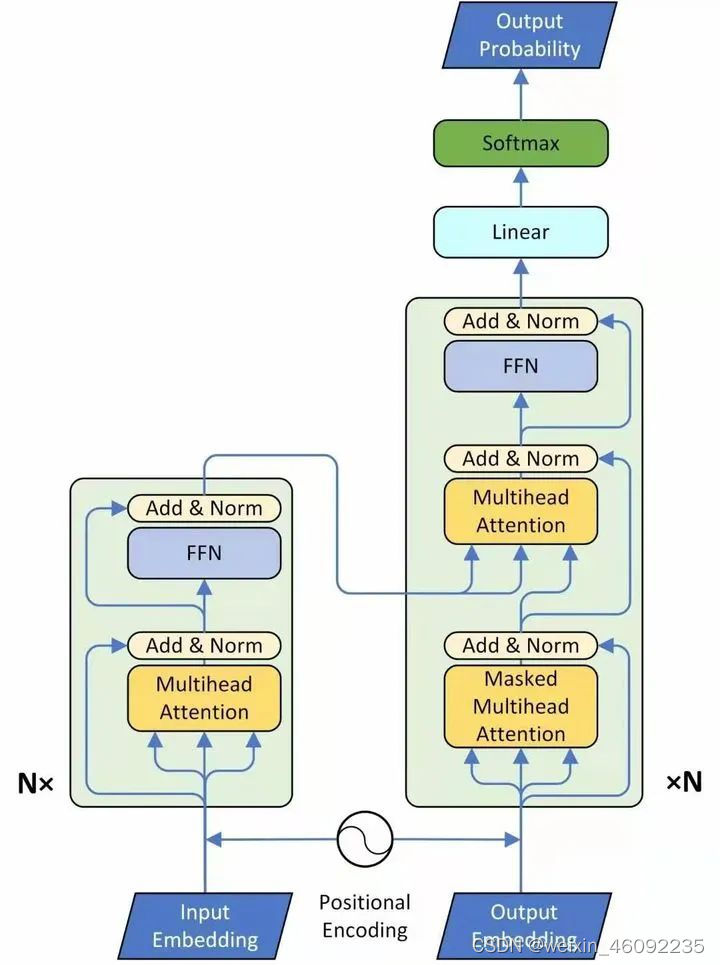
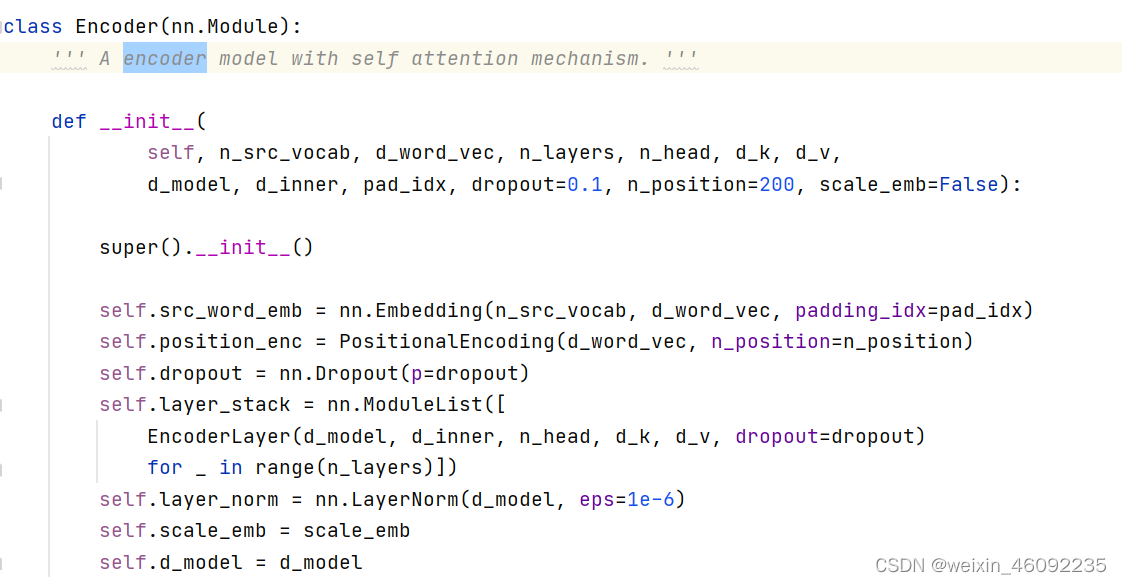
Encoder
总结一下,encoder部分
- 首先拿到已经embedding的输入
- 进入一个multihead Attention,然后加入了一个残差连接,把多头注意力部分的输入输出相加(这两部分维度相同)得到的结果做layer normalization 。
- 然后进入FFN层,这里我认为就是一个全连接层,之后再进行一次layer normalization。
- 整个这部分要重复N次。

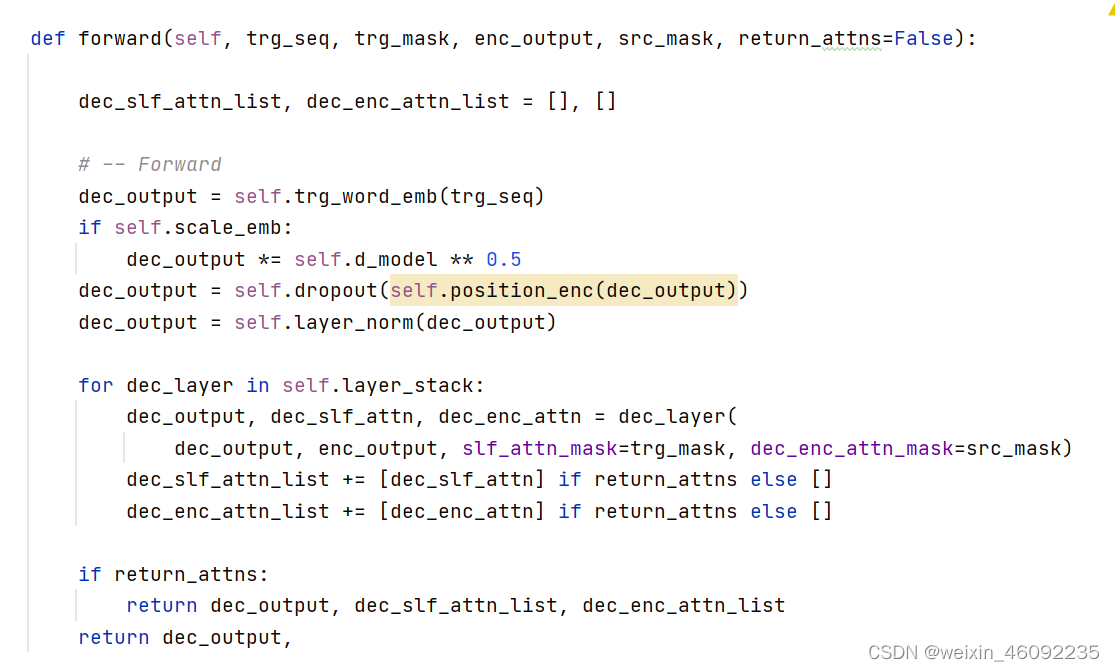
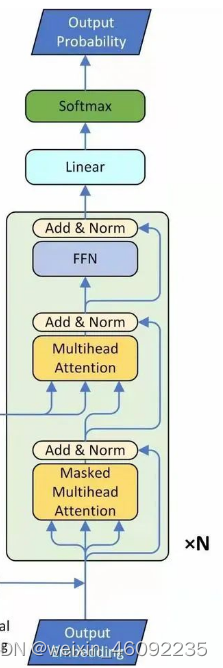 Decoder
Decoder
总结一下这部分内容:
- 首先得到的输入(图中下方的output)是encoder的输出再加上位置编码。送入一个masked的多头注意力模块,mask的原因是注意力只关注已经产生的sequence,没产生的不关注,因此盖住。之后加上一个残差连接,并进入layer normalization。
- 然后进入下一个multihead层,这部分的输入不单纯是上一层
masked multihead Attention,而是加入了它的Key和Value来自encoder,Query来自上一位置decoder的输出。,query部分加入残差连接之后,结合这部分的输出一起送入layer normalization。
- 进入一个全连接层,结合残差连接,再次进行layer normalization。
Masked multihead attention
Mask的原因,如下图可见

根据图片所示,qk相乘之后进行了一个mask操作,这个mask的实质就是将qk相乘后的矩阵再乘以一个矩阵,使得得到的新矩阵部分值为0,这样就盖住了后续的部分。最后乘以v时,0值部分不起作用。
代码部分
ScaledDotProductAttention:

如图,这部分首先将QK相乘,然后除以根号下dk,再进行mask,进行softmax之后,和V相乘。
在这部分开始之前我去学习了一下pytorch的相关知识。
class ScaledDotProductAttention(nn.Module):
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)
def forward(self, q, k, v, mask=None):
attn = torch.matmul(q / self.temperature, k.transpose(2, 3))
#QK相乘再除以根号下的维度
if mask is not None:
attn = attn.masked_fill(mask == 0, -1e9)
#根据要求判断是否需要mask
attn = self.dropout(F.softmax(attn, dim=-1))
#运用了随机失活
output = torch.matmul(attn, v)
return output, attn
#返回结果为计算过的attention(也就是QK相乘),以及加权后的V(V的维度和QK相同)
位置编码
对应公式:
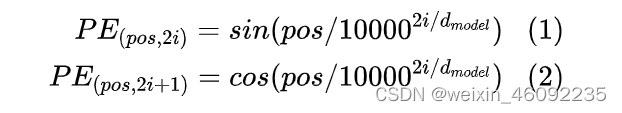
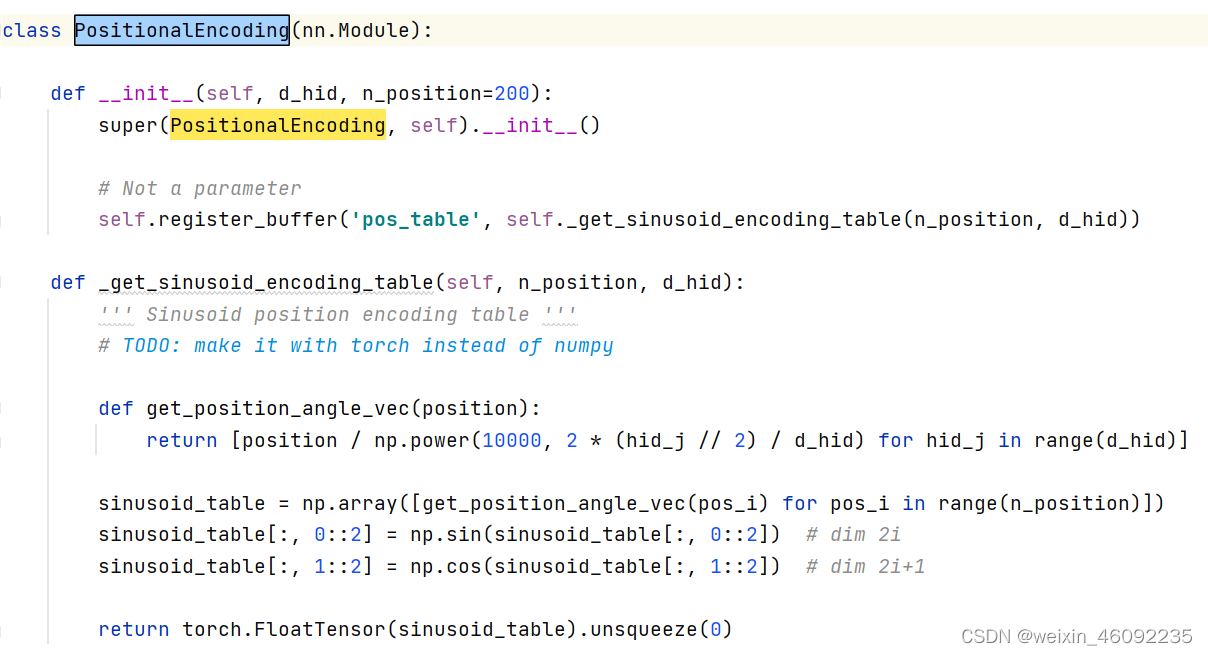
首先get_position_angle_vec(position)函数返回一个列表,列表中每一个值计算的是position/(10000)^(hid_j/hid),其中hid_j指的是遍历hid的每一个值。
然后sinusoid_table这个表格保存的是对于每一个位置下的pos返回一个列表,sinusoid_table[i]指的是pos为i情况下get_position_angle_vec(i)列表。
最后对奇偶位置的表格中每个数值分别求sin和cos值。
这个代码段和官方的有一个差别就是官方的乘方是2i/d,而这个代码段用的是2*hid_j//2。
多头注意力模块
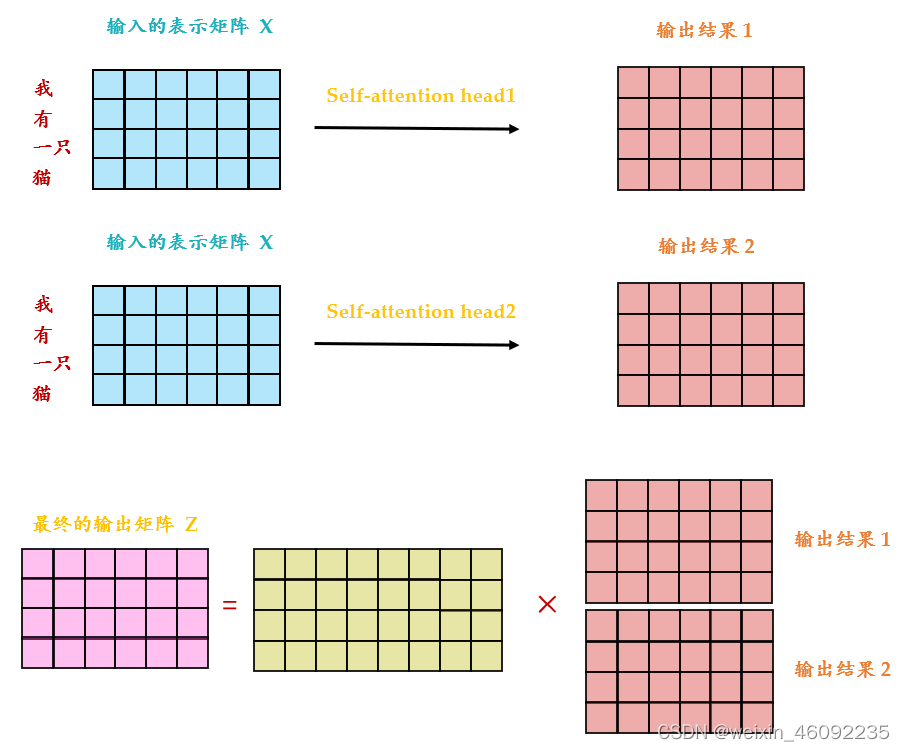
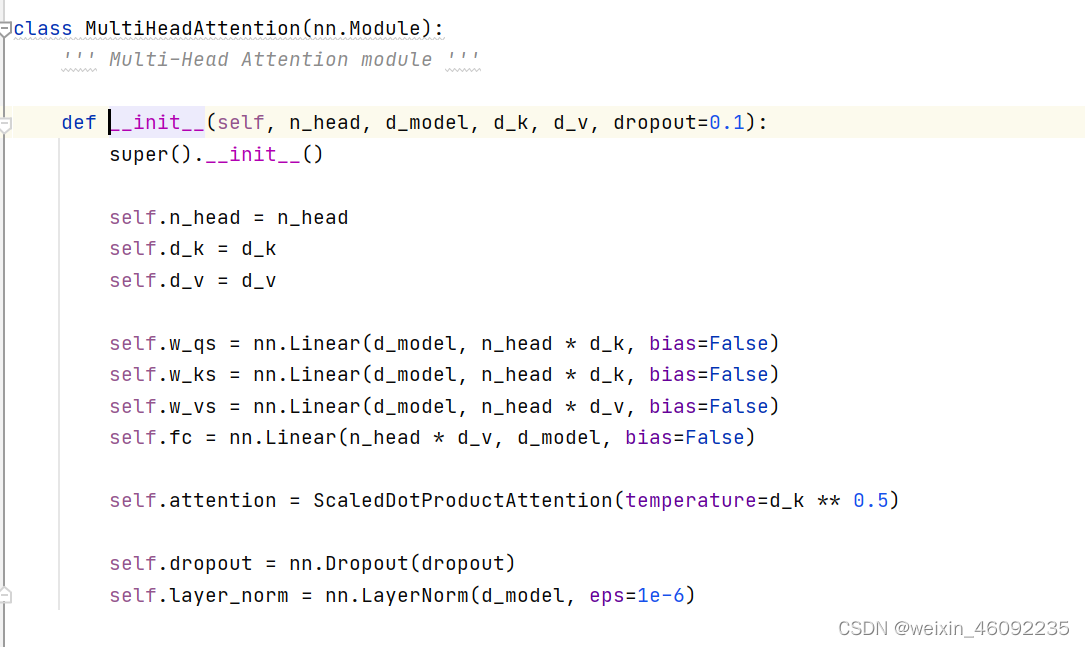
这部分首先书初始化wq,wk,wv这几个矩阵,初始化函数中的参数:
n_head: 几头注意力机制
d_model:输入的维度
d_k: k 矩阵的维度
d_v: v 矩阵的维度
dropout:运用了随机失活
这里我去补习了一下nn.liner函数:
这个函数的原理就是output= weights*input+bias
input: 表示输入的Tensor,可以有多个维度
weights: 表示可学习的权重,shape=(output_feature,in_feature)
bias: 表示科学习的偏置,shape=(output_feature)
in_feature: nn.Linear 初始化的第一个参数,即输入Tensor最后一维的通道数。
out_feature: nn.Linear 初始化的第二个参数,即返回Tensor最后一维的通道数。
output: 表示输入的Tensor,可以有多个维度。
初始化:nn.Linear(in_feature,out_feature,bias)
函数执行:out=nn.Linear(input)
input: 表示输入的Tensor,可以有多个维度
output: 表示输入的Tensor,可以有多个维度

这里执行前向传播
view函数,这里相当于numpy中的resize功能。
>>> import torch>>> t1 = torch.tensor([1,2,3,4,5,6])>>> result = tt1.view(3,2)>>> resulttensor([[1, 2], [3, 4], [5, 6]])transpose函数:
将两个相应的维度进行变换
import torch
X=torch.Tensor([[1,2,3],[4,5,6]])
X=X.transpose(0,1)
print(X)

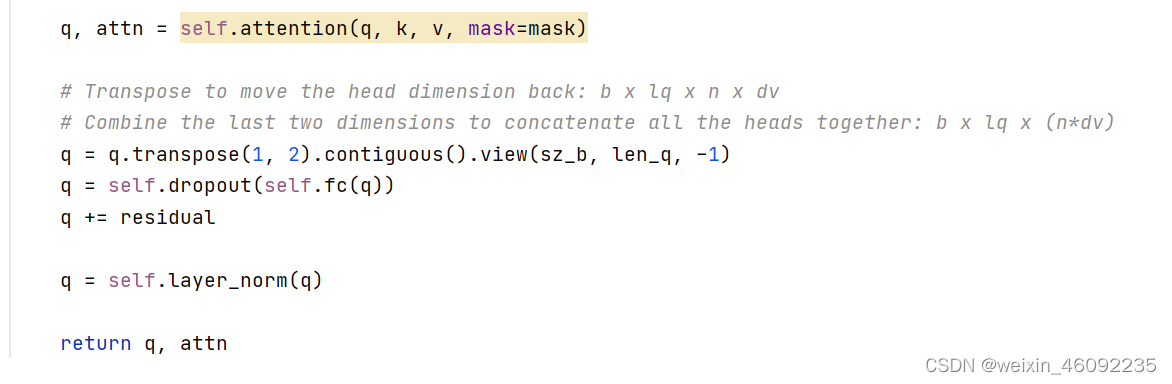
这部分有个问题,首先self.attention是ScaledDotProductAttention的类,然后q, attn = self.attention(q, k, v, mask=mask)这句话显然是想调用self.attention这个类中的forward函数,这样不应该是:
q, attn = self.attention.forward(q, k, v, mask=mask)
前向传播模块Feed Forward Network

这部分就是一个加入了dropout的全连接网络部分。
补习一下dropout函数:
链接:https://www.cnblogs.com/CircleWang/p/16025723.html


Encoder

Decoder
















 1911
1911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











