







分类涉及到的评价指标特别多,不是这个率就是那个率,很容易混淆,这篇文章就梳理下分类模型的评价指标。
为了解释混淆矩阵,先来看看下⾯这个⼆分类的例⼦。
例:有20个病⼈来医院检查,是否患病的预测值和真实值如下表所⽰。
| 病号 | 预测值 | 真实值 | 病号 | 预测值 | 真实值 |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 11 | 0 | 0 |
| 2 | 0 | 0 | 12 | 0 | 0 |
| 3 | 0 | 1 | 13 | 0 | 0 |
| 4 | 1 | 0 | 14 | 1 | 1 |
| 5 | 0 | 0 | 15 | 0 | 0 |
| 6 | 1 | 1 | 16 | 1 | 0 |
| 7 | 0 | 0 | 17 | 1 | 1 |
| 8 | 0 | 0 | 18 | 0 | 0 |
| 9 | 1 | 1 | 19 | 0 | 0 |
| 10 | 0 | 0 | 20 | 0 | 1 |
其中,1表⽰患病,0表⽰不患病。
本⽂档默认⽤0和1来作为⼆分类符号。
你也可以⽤其他符号来表⽰,如1表⽰患病,-1表⽰不患病。只要能区分就⾏。
这样就出现4种结果:
- 预测为1,实际也为1,包括病号1,3,6,14,17,⼀共5个样本;
- 预测为1,实际为0,包括病号16,只有1个样本;
- 预测为0,实际为1,包括病号9,20,只有2个样本;
- 预测为0,实际也为0,包括病号2,4,5,7,8,10,11,12,13,15,18,19,⼀共12个样本。
我们把各个结果的数量填到下⾯这个表格中

这就是病患例⼦的混淆矩阵。
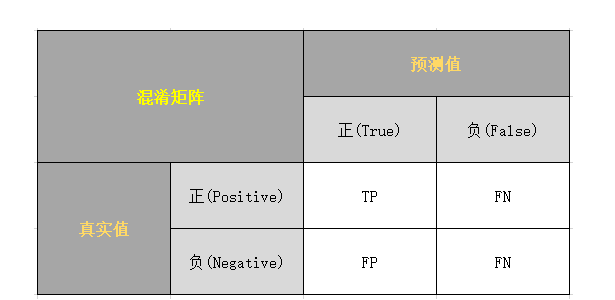
混淆矩阵定义
⼆分类混淆矩阵的⼀般定义只是将1和0叫做正例和负例,把4种结果的样本数量⽤符号来表⽰,⽤什么符号呢?
如果我们⽤P(Positive)代表1,⽤N(Negative)代表0,那这四种结果分别是PP,PN,NP,NN,但这样表⽰有点问 题,譬如,PN的意思是预测为1实际为0还是预测为0实际为1?需要规定好了,还得记住,好⿇烦。
⼲脆再引⼊符号T(True)代表预测正确,F(False)表⽰预测错误,那么之前的P和N代表预测是1还是0,T和F表⽰预测是否正确。
混淆矩阵的定义如下:
-
TP(True Positive): 将真实值 正类 预测为 正类数。
-
FN(False Negative): 将真实值 正类 预测为 负类数。
-
FP(False Positive): 将真实值 负类 预测为 正类数。
-
TN(True Negative): 将真实值 负类 预测为 负类数。
第二个字母代表的都是预测为正还是负。
正确率
准确率(Accuracy)的定义很简单,就是猜对的样本占总样本的⽐例,公式如下:
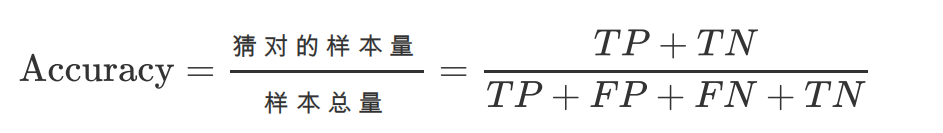
正样本是实际为正例的样本,负样本是实际为负例的样本。
计算正确率可以调⽤sklearn.metrics的accuracy_score函数,代码如下:
from sklearn.metrics import accuracy_score
# 真实值
y_true = [1, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1]
# 预测值
y_pred = [1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0]
mc = accuracy_score(y_true, y_pred)
print('Accuracy: %.2f'%mc)
# 结果:
Accuracy: 0.85
正确率作为评价指标的优点就是能够直观的看到模型的好坏;它致命的缺点,就是样本不平衡时⽆法准确反映模型结果。
举个例⼦,预估某个⽹站上某⼀天⼴告的点击率,假如⼀天有1000个⼈浏览,实际有50个⼈点击⼴告,假如分类
器预测没有⼈会点击,那么这个模型结果的正确率是多少呢?
我们算⼀下:分类器预测正确的有950个样本,⼀共有1000个样本,根据定义 A c c u r a c y = 950 1000 = 0.95 Accuracy = \frac{950}{1000}=0.95 Accuracy=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 483
483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









