






题目
通过Java编写MapReduce程序,统计每个订单中最便宜的商品,最后输出到一个文件中
本题声明:
1.采用Linux系统
2.已搭建好的hadoop集群
3.使用java编写MapReduce程序
题目分析:
1.编写MapReduce程序
2.hadoop调用MapReduce程序的数据源要上传至集群当中
一、首先将该题的数据源上传至集群
我已经将数据源复制到了Linux系统当中

数据源文件内容为:

(1)在集群创建空目录,用于存放该题的数据源文件
命名:hadoop fs -mkdir -p /zs/java/input/input7/

集群中的空目录创建成功

(2)将该题的数据源上传至创建的空目录中
(就在该数据源的文件夹内使用hadoop命名)
命名:
hadoop fs -put order.txt /zs/java/input/input7/

数据源文件上传成功

这道题的数据源已经上传成功了,接下来就是编写MapReduce程序
二、创建java项目编写MapReduce程序
(1)创建java项目并导入连接hadoop的jar包
我创建的是一个名为Seven的java项目(项目名可自行设置)
为该项目导入连接hadoop的jar包
File --> Project Structure --> Modules --> Dependencies
选择右边的+号点击:JARs or directories,找到已准备好的lib包并选中点击ok
(没有lib包的联系我,我发给你,lib包一般存放在 “ /opt/software/ ” 下)


(2)使用java编写MapReduce程序
这道题的MapReduce程序包含以下几个类:OrderBea、Mapper、Reducer、Driver、Partitioer、Comparator
定义一个OrderBean.java类
代码如下:
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class OrderBean implements WritableComparable<OrderBean> {
private String orderId;
private double price;
private String goodsId;
private String idName;
public String getGoodsId() {
return goodsId;
}
public void setGoodsId(String goodsId) {
this.goodsId = goodsId;
}
public OrderBean() {
super();
}
public OrderBean(String orderId, double price, String goodsId, String idName) {
this.orderId = orderId;
this.price = price;
this.goodsId = goodsId;
this.idName = idName;
}
public String getIdName() {
return idName;
}
public void setIdName(String idName) {
this.idName = idName;
}
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public void readFields(DataInput in) throws IOException {
this.orderId = in.readUTF();
this.price = in.readDouble();
this.idName = in.readUTF();
this.goodsId = in.readUTF();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(orderId);
out.writeDouble(price);
out.writeUTF(idName);
out.writeUTF(goodsId);
}
@Override
public int compareTo(OrderBean o) {
// 1 先按订单id排序(从小到大)
int result = this.orderId.compareTo(o.getOrderId());
if (result == 0) {
// 2 再按金额排序(从小到大)
result = price < o.getPrice() ? -1 : 1;
}
return result;
}
@Override
public String toString() {
return orderId +"\t" + getGoodsId() +"\t" +getIdName()+ "\t"+ price ;
}
}
定义一个OrderSortDriver.java类
代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class OrderSortDriver {
public static void main(String[] args) throws Exception {
// 1 获取配置信息
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 设置jar包加载路径
job.setJarByClass(OrderSortDriver.class);
// 3 加载map/reduce类
job.setMapperClass(OrderSortMapper.class);
job.setReducerClass(OrderSortReducer.class);
// 4 设置map输出数据key和value类型
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(NullWritable.class);
// 5 设置最终输出数据的key和value类型
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
// 6 设置输入数据和输出数据路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 10 设置reduce端的分组
job.setGroupingComparatorClass(OrderSortGroupingComparator.class);
// 7 设置分区
job.setPartitionerClass(OrderSortPartitioner.class);
// 8 设置reduce个数
job.setNumReduceTasks(3);
// 9 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
定义一个OrderSortMapper.java类
代码如下:
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class OrderSortMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable>{
OrderBean bean = new OrderBean();
@Override
protected void map(LongWritable key, Text value,
Context context)throws IOException, InterruptedException {
// 1 获取一行数据
String line = value.toString();
// 2 截取字段
String[] fields = line.split("\t");
// 3 封装bean
bean.setOrderId(fields[0]);
bean.setGoodsId(fields[1]);
bean.setIdName(fields[2]);
bean.setPrice(Double.parseDouble(fields[3]));
// 4 写出
context.write(bean, NullWritable.get());
}
}
定义一个OrderSortPartitioner.java类
代码如下:
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class OrderSortPartitioner extends Partitioner<OrderBean, NullWritable>{
@Override
public int getPartition(OrderBean key, NullWritable value, int numReduceTasks) {
return (key.getOrderId().hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
定义一个OrderSortReducer.java类
代码如下:
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
public class OrderSortReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable>{
@Override
protected void reduce(OrderBean bean, Iterable<NullWritable> values,
Context context) throws IOException, InterruptedException {
// 直接写出
context.write(bean, NullWritable.get());
}
}
定义一个OrderSortGroupingComparator.java类
代码如下:
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class OrderSortGroupingComparator extends WritableComparator {
protected OrderSortGroupingComparator() {
super(OrderBean.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean abean = (OrderBean) a;
OrderBean bbean = (OrderBean) b;
// 将orderId相同的bean都视为一组
return abean.getOrderId().compareTo(bbean.getOrderId());
}
}
MapReduce的所有java类已创建成功

三、将编写的MapReduce程序打包并上传至,启动集群的Linux系统中
我这里是:hadoop111,hadoop112
Idea中打包 java程序:
File --> Project Structure --> Artifacts --> + -->JAR --> From modules with dependencies
随后在Main Class中选择 WordcountDriver,随后点击OK

点击Ok后,再点击OK

点击ok后,选择: Build --> Build Artifacts --> Build

然后耐心等待一会
在左侧会自动生成一个out的文件,点击: out —> artifacts —> Seven_ jar
即可查看是否打包成功

打包后在Linux系统中的 /root/ 下面找到 ideaProjects
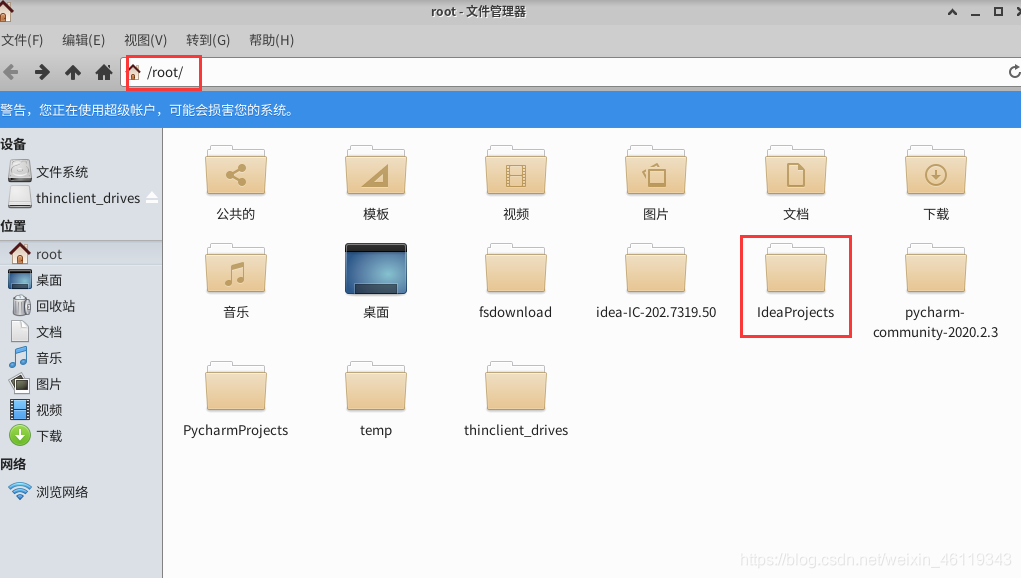
然后点击 IdeaProjects --> Seven --> out --> artifacts -->Seven_jar
找到已打好的jar包
在该目录下,右击打开终端输入scp命名,将jar包上传至启动集群的hadoop111的Linux系统中"/opt/software/" 文件夹下
SCP 命名:scp Seven.jar root@hadoop111:/opt/software/

查看文件是否传输成功

执行zip命名对该包进行删除两个会使程序出错的文件
ZIP命名:
zip -d Seven.jar META-INF/.RSA META-INF/.SF

就在该目录下使用hadoop调用该包,对集群中的数据源文件进行统计每个订单中最便宜的商品,最后输出到一个文件中
hadoop命名:
hadoop jar Seven.jar /zs/java/input/input7/order.txt /zs/java/output/output7
(/zs/java/input/input7/order.txt 代表的是这道题的数据源,数据源在前面已经上传)
(/zs/java/output/output7 代表hadop调用jar包将数据源文件处理后的文件存放位置)

执行结果,执行结果在集群中查看
查看位置为 hadoop调用jar包将数据源文件处理后的文件存放位置
(/zs/java/output/output7)
hadoop调用jar包执行效果为:
















 4471
4471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









