






题目
文件夹中是微信的好友列表数据,冒号前是一个用户,冒号后是该用户的所有好友(数据中的好友关系是单向的),参照笔记,求出哪些人两两之间有共同好友,及他俩的共同好友都有谁?
本题声明:
1.采用Linux系统
2.已搭建好的hadoop集群
3.使用java编写MapReduce程序
题目分析:
1.编写MapReduce程序
2.hadoop调用MapReduce程序的数据源要上传至集群当中
项目流程:
我将该项目分成了两步来做
(1) 首先在文件中找出谁是谁的好友。
(2) 根据(1)中求出谁是谁的好友结果数据文件,求出哪些人两两之间有共同好友,及他俩的共同好友都有谁。
项目实施:
(1) 首先在文件中找出谁是谁的好友。
一、首先将该题的数据源上传至集群
我已经将数据源复制到了Linux系统当中
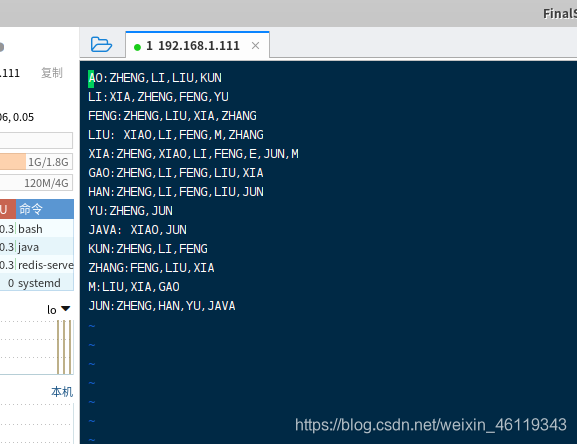
数据源文件内容为:
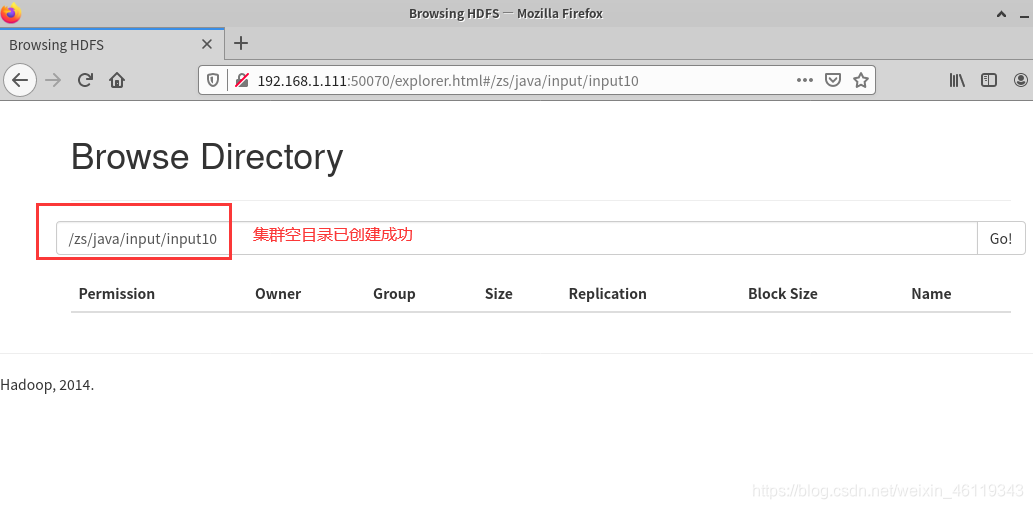
(1)在集群创建空目录,用于存放该题的数据源文件
命名:hadoop fs -mkdir -p /zs/java/input/input10

集群中的空目录创建成功
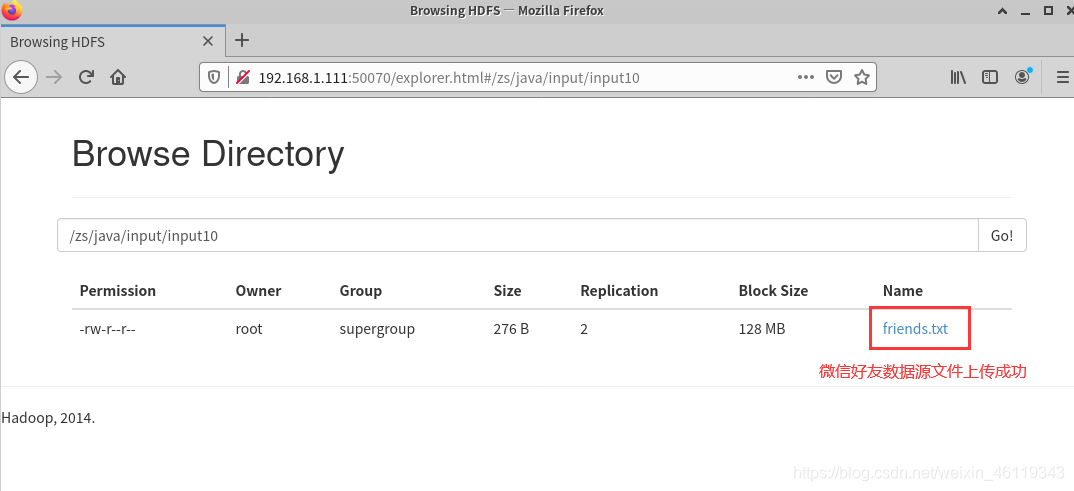
(2)将该题的数据源上传至创建的空目录中
(就在该数据源的文件夹内使用hadoop命名)
命名:
hadoop fs -put friends.txt /zs/java/input/input10

数据源文件上传成功
这道题的数据源已经上传成功了,接下来就是编写MapReduce程序
二、创建java项目编写MapReduce程序
(1)创建java项目并导入连接hadoop的jar包
我创建的是一个名为Ten的java项目(项目名可自行设置)
为该项目导入连接hadoop的jar包
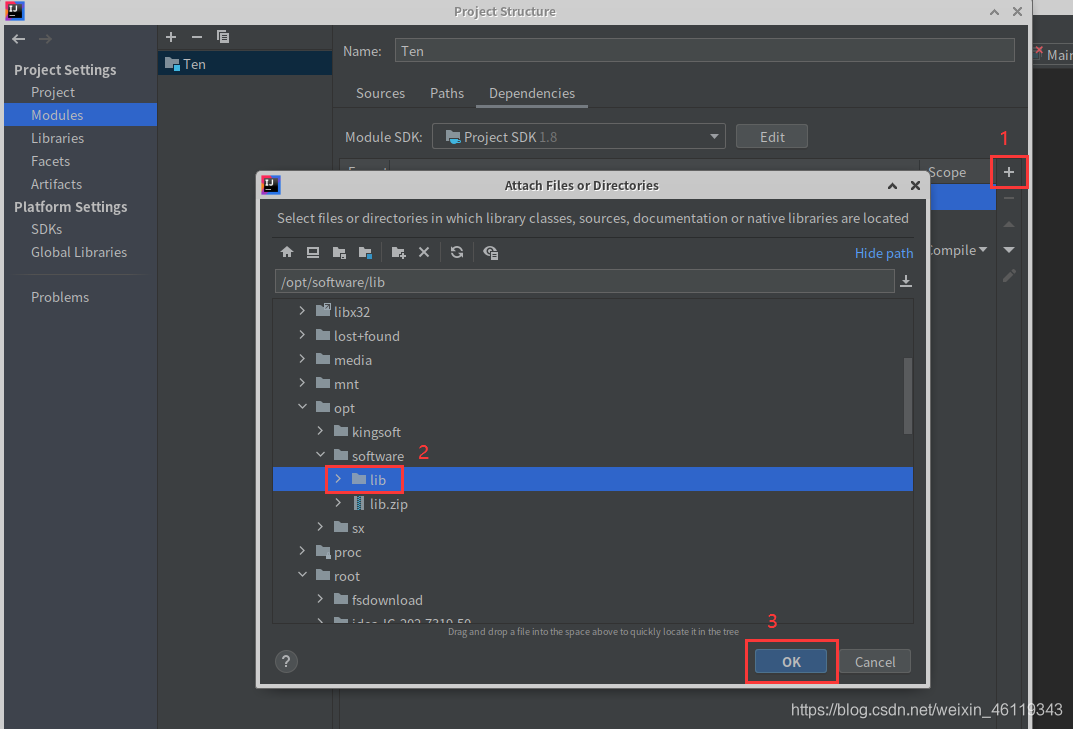
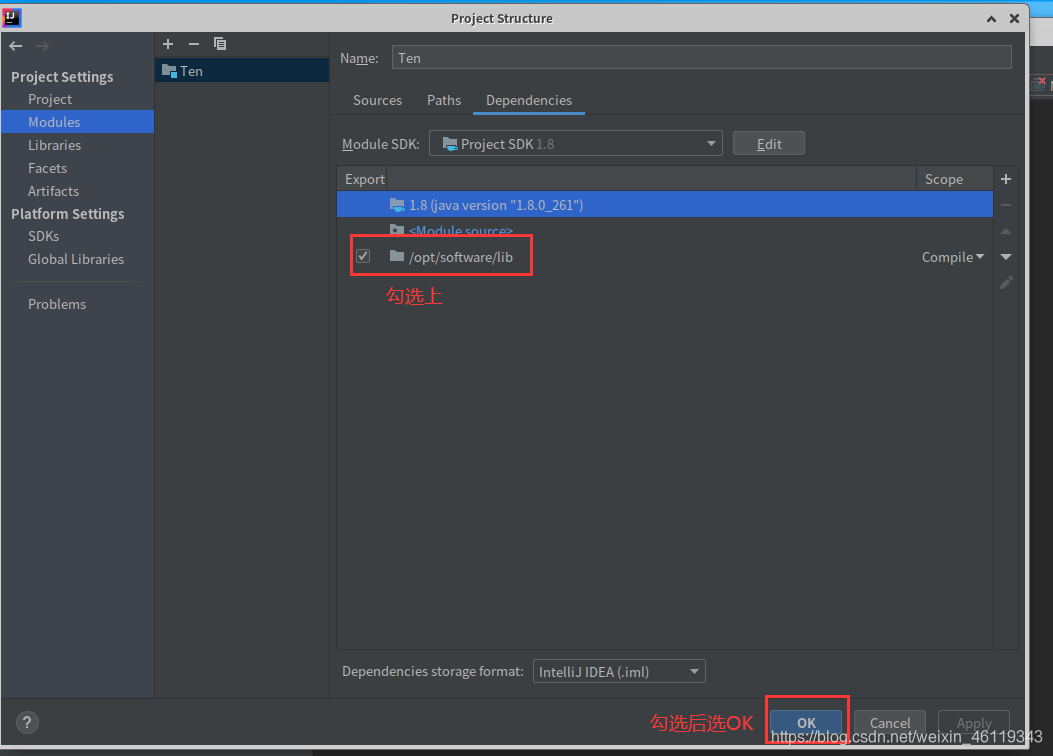
File --> Project Structure --> Modules --> Dependencies
选择右边的+号点击:JARs or directories,找到已准备好的lib包并选中点击ok
(没有lib包的联系我,我发给你,lib包一般存放在 “ /opt/software/ ” 下)
(2)使用java编写MapReduce程序
这次项目的MapReduce程序包含以下几个类:
OneShareFriendsDriver、OneShareFriendsMapper、OneShareFriendsReducer
定义一个OneShareFriendsDriver.java类
代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class OneShareFriendsDriver {
public static void main(String[] args) throws Exception {
// 1 获取job对象
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 指定jar包运行的路径
job.setJarByClass(OneShareFriendsDriver.class);
// 3 指定map/reduce使用的类
job.setMapperClass(OneShareFriendsMapper.class);
job.setReducerClass(OneShareFriendsReducer.class);
// 4 指定map输出的数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 5 指定最终输出的数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 6 指定job的输入原始所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result?1:0);
}
}
定义一个OneShareFriendsMapper.java类
代码如下:
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class OneShareFriendsMapper extends Mapper<LongWritable, Text, Text, Text>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
// 1 获取一行 A:B,C,D,F,E,O
String line = value.toString();
// 2 切割
String[] fileds = line.split(":");
// 3 获取person和好友
String person = fileds[0];
String[] friends = fileds[1].split(",");
// 4写出去
for(String friend: friends){
// 输出 <好友,人>
context.write(new Text(friend), new Text(person));
}
}
}
定义一个OneShareFriendsReducer.java类
代码如下:
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class OneShareFriendsReducer extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
StringBuffer sb = new StringBuffer();
//1 拼接
for(Text person: values){
sb.append(person).append(",");
}
//2 写出
context.write(key, new Text(sb.toString()));
}
}
MapReduce的所有java类已创建成功
三、将编写的MapReduce程序打包并上传至,启动集群的Linux系统中
我这里是:hadoop111,hadoop112
Idea中打包 java程序:
File --> Project Structure --> Artifacts --> + -->JAR --> From modules with dependencies
随后在Main Class中选择 WordcountDriver,随后点击OK
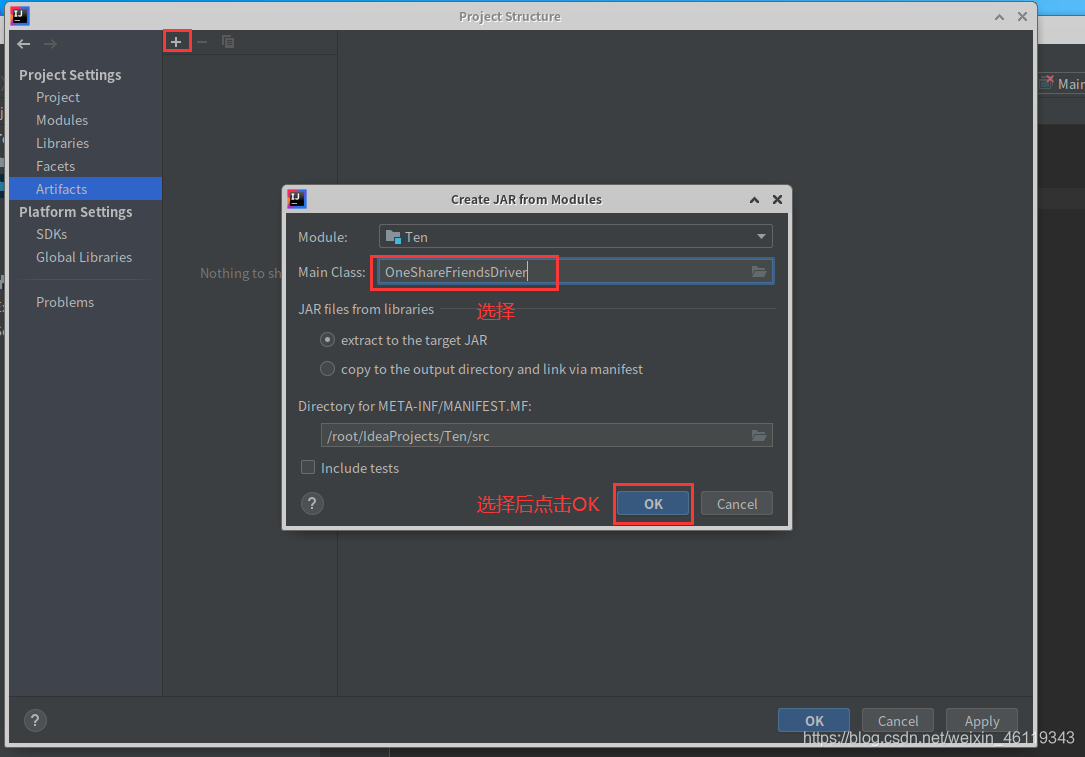
点击Ok后,再点击OK
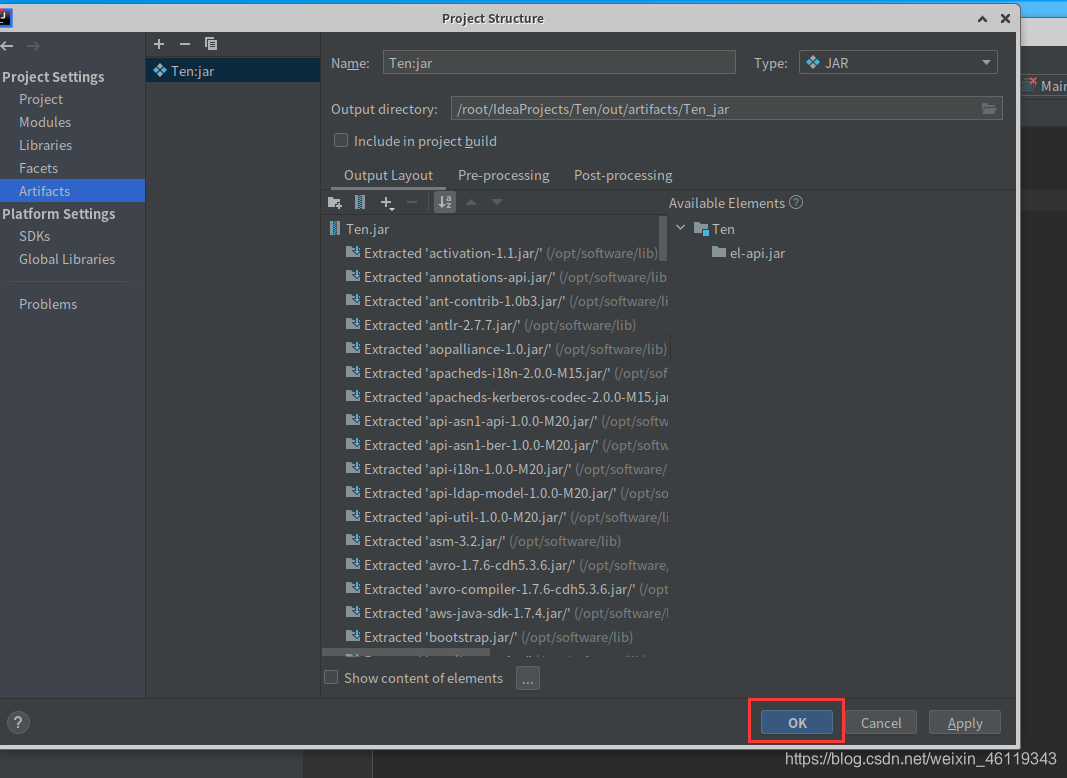
点击ok后,选择: Build --> Build Artifacts --> Build
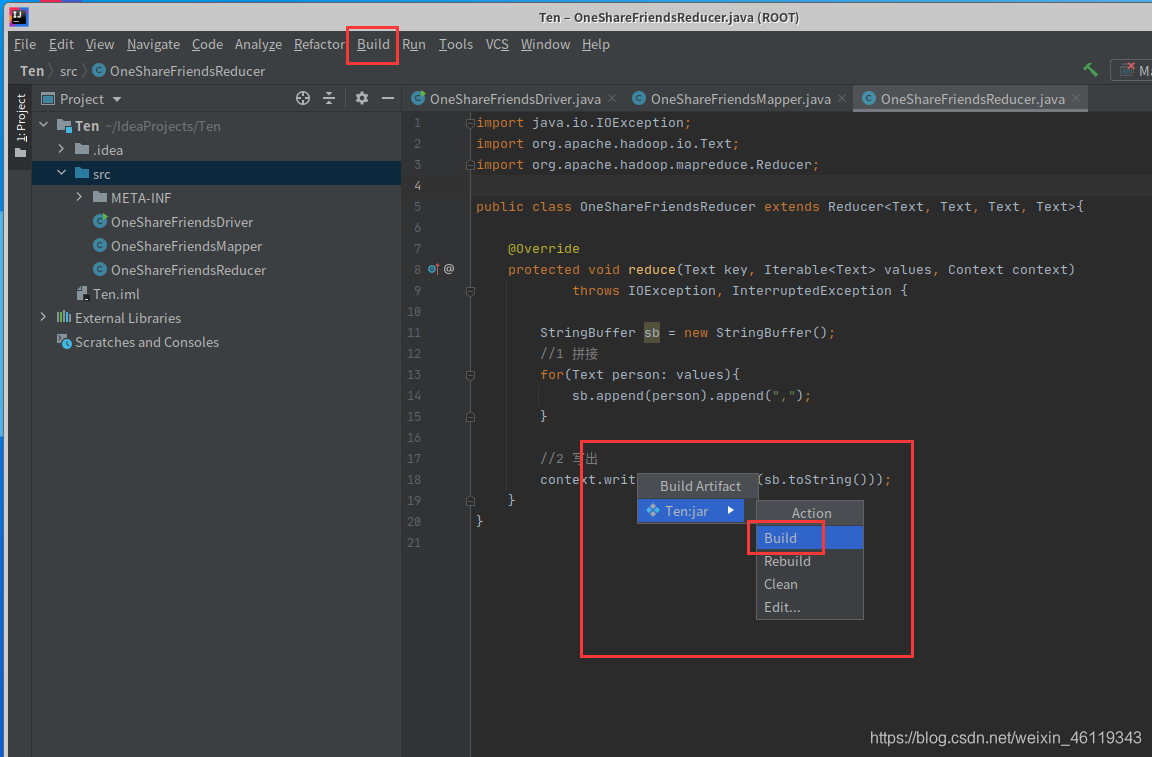
然后耐心等待一会
在左侧会自动生成一个out的文件,点击: out —> artifacts —> Ten_ jar
即可查看是否打包成功
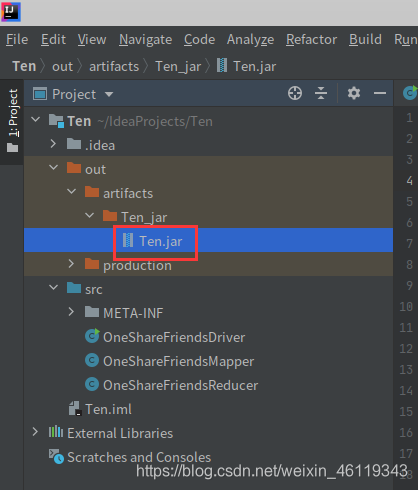
打包后在Linux系统中的 /root/ 下面找到 ideaProjects
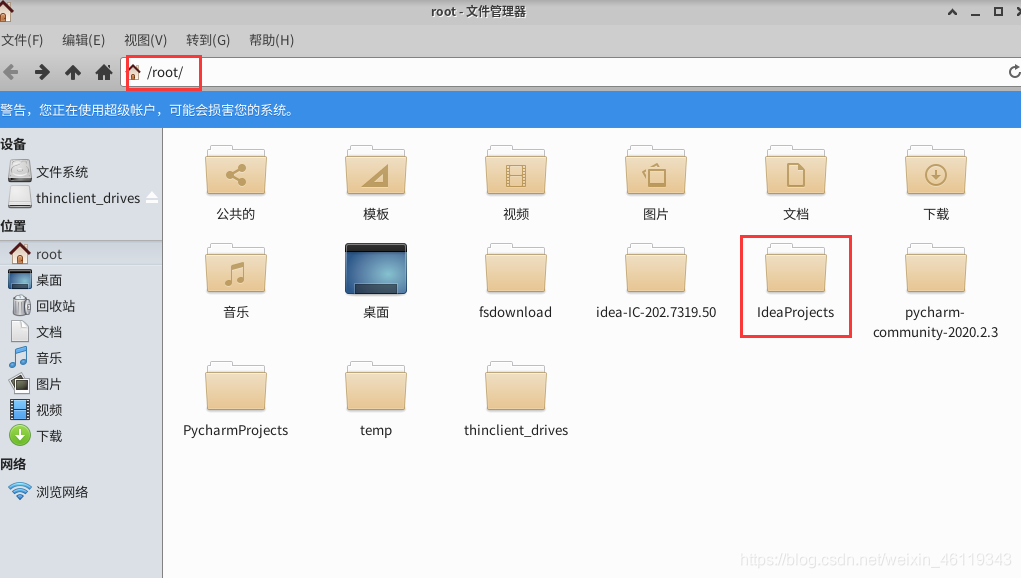
然后点击 IdeaProjects --> Ten --> out --> artifacts -->Ten_jar
找到已打好的jar包
在该目录下,右击打开终端输入scp命名,将jar包上传至启动集群的hadoop111的Linux系统中"/opt/software/" 文件夹下
SCP 命名:scp Ten.jar root@hadoop111:/opt/software/
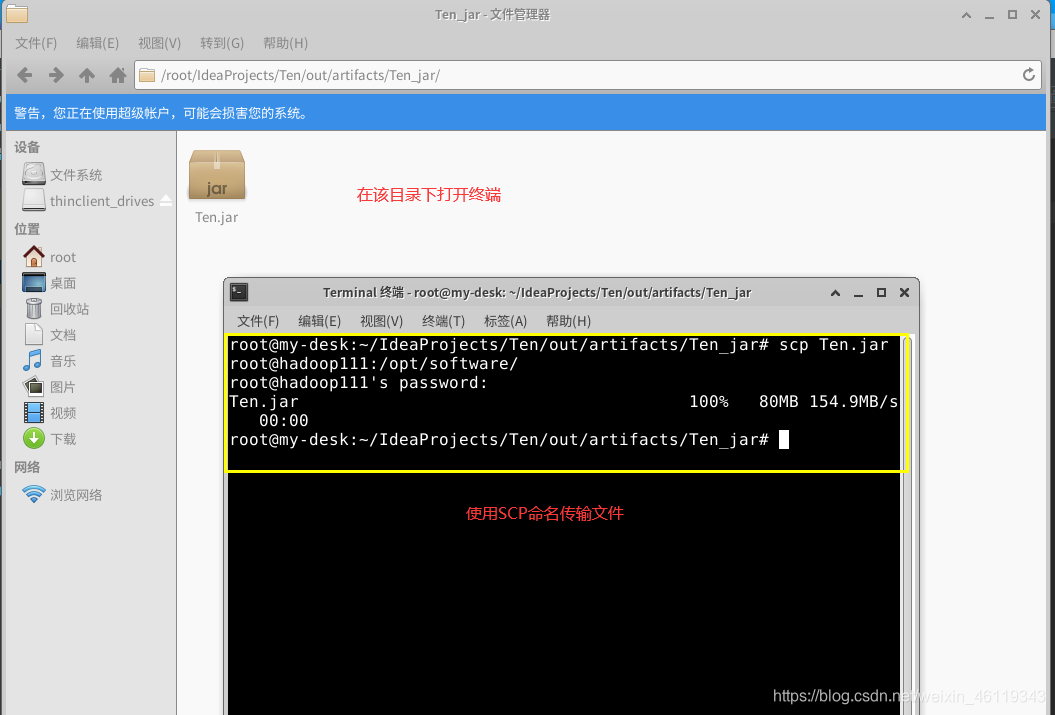
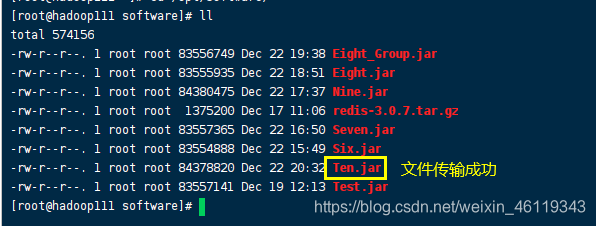
查看文件是否传输成功
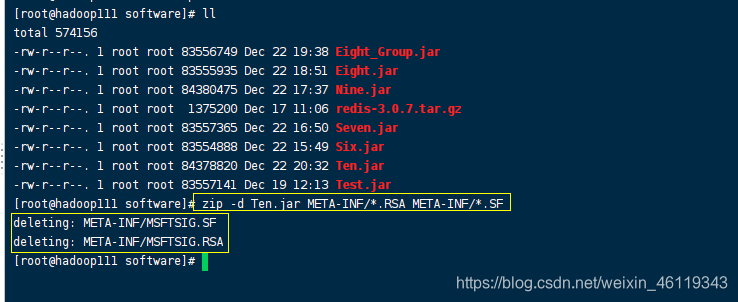
执行zip命名对该包进行删除两个会使程序出错的文件
ZIP命名:
zip -d Ten.jar META-INF/.RSA META-INF/.SF
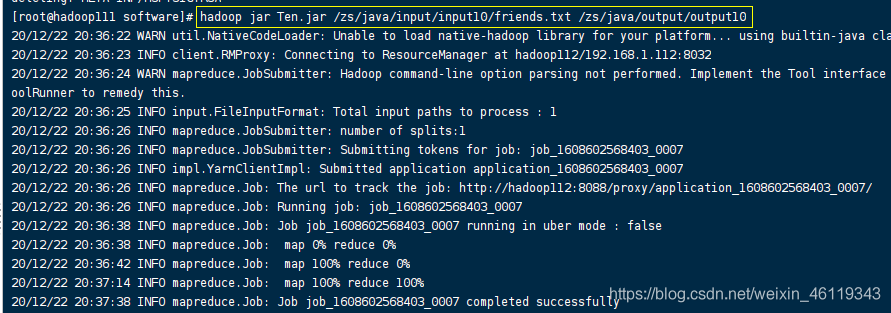
就在该目录下使用hadoop调用该包,通过数据源文件,求出每个手机号的总上行流量、下行流量、总流量。
hadoop命名:
hadoop jar Ten.jar /zs/java/input/input10/friends.txt /zs/java/output/output10
(/zs/java/input/input10/friends.txt 代表的是这道题的数据源,数据源在前面已经上传)
(/zs/java/output/output10 代表hadop调用jar包将数据源文件处理后的文件存放位置)
执行结果,执行结果在集群中查看
查看位置为 hadoop调用jar包将数据源文件处理后的文件存放位置
(/zs/java/output/output10)
hadoop调用jar包执行效果为:
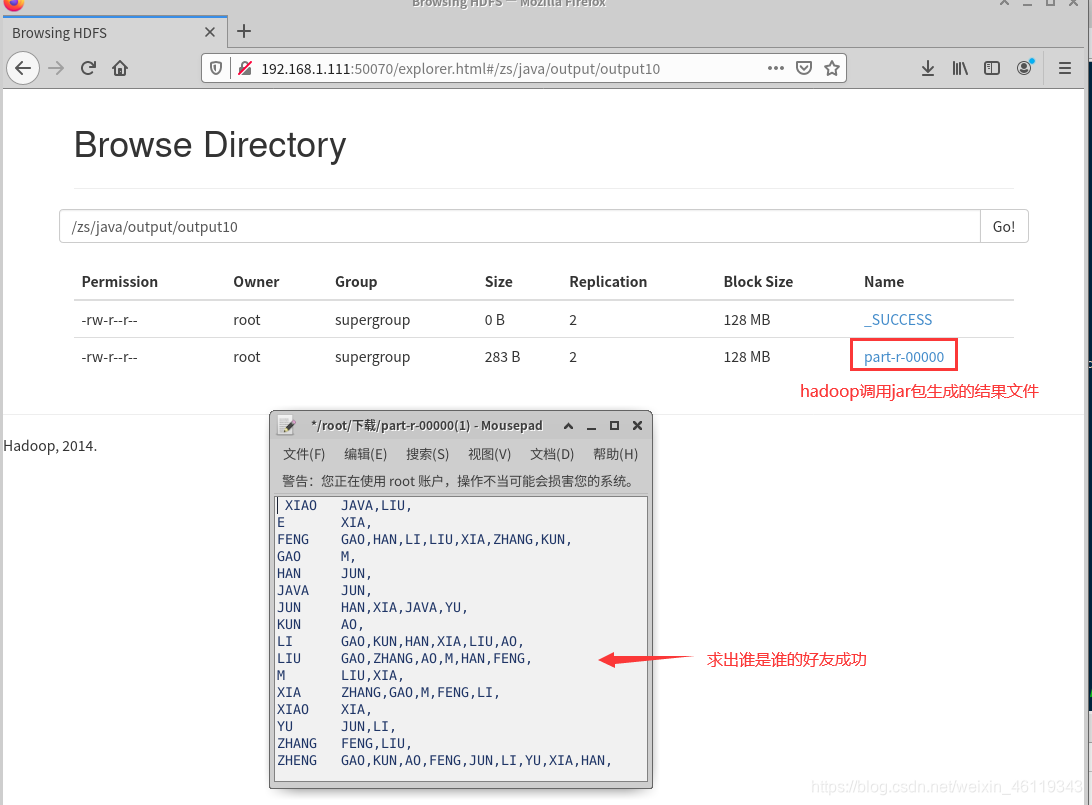
到这儿(1)的要求做好了,已经求出了谁是谁的好友
接下来我们继续做(2)
(2) 根据(1)的手机号流量汇总结果再按照手机号不同归属地进行分组输出到不同的文件中
一、创建java项目编写MapReduce程序**
(1)创建java项目并导入连接hadoop的jar包
我创建的是一个名为Ten_Final的java项目(项目名可自行设置)
为该项目导入连接hadoop的jar包
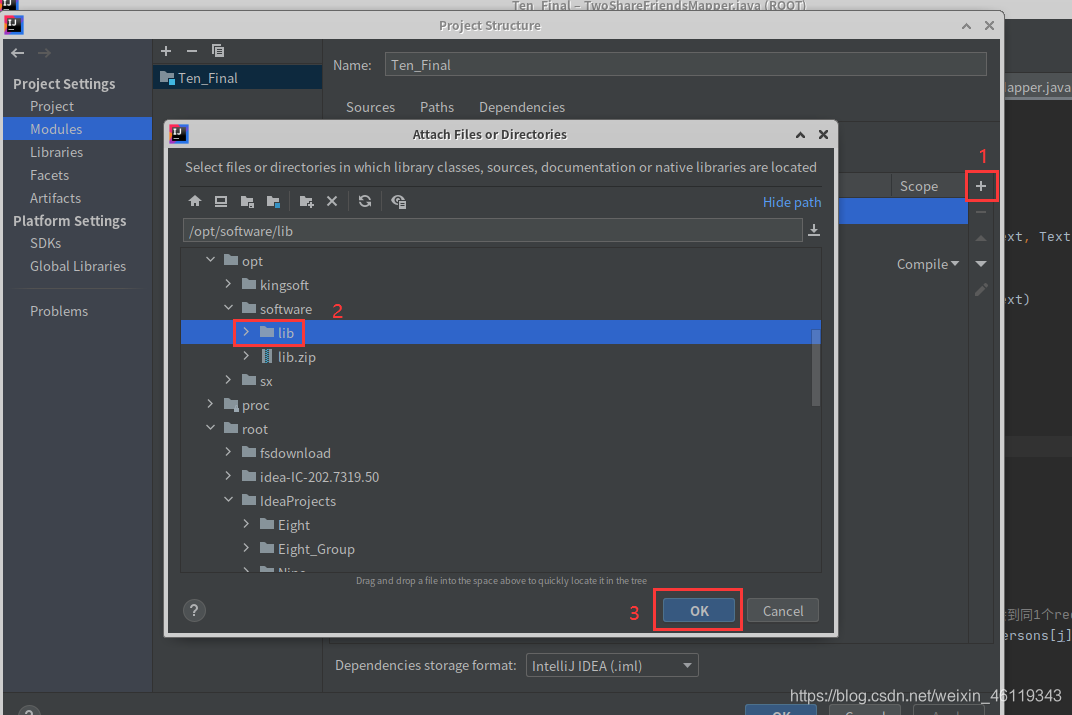
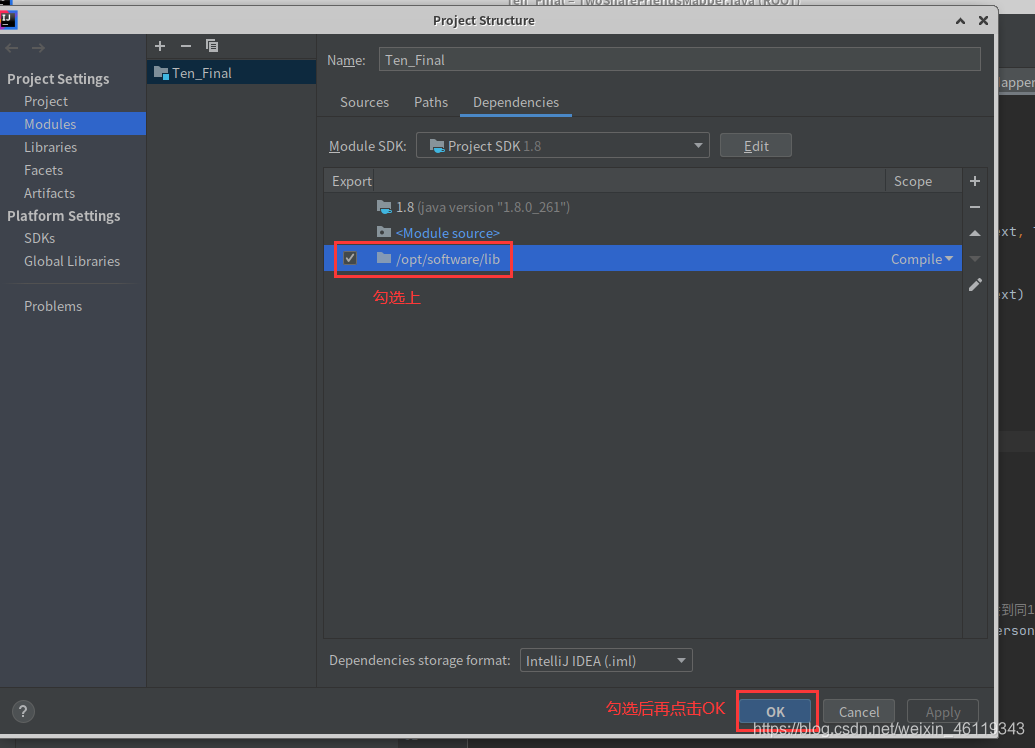
File --> Project Structure --> Modules --> Dependencies
选择右边的+号点击:JARs or directories,找到已准备好的lib包并选中点击ok
(没有lib包的联系我,我发给你,lib包一般存放在 “ /opt/software/ ” 下)
(2)使用java编写MapReduce程序
这道题的MapReduce程序包含以下几个类:
TwoShareFriendsDriver、TwoShareFriendsReducer、TwoShareFriendsReducer
定义一个TwoShareFriendsDriver.java类
代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TwoShareFriendsDriver {
public static void main(String[] args) throws Exception {
// 1 获取job对象
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 指定jar包运行的路径
job.setJarByClass(TwoShareFriendsDriver.class);
// 3 指定map/reduce使用的类
job.setMapperClass(TwoShareFriendsMapper.class);
job.setReducerClass(TwoShareFriendsReducer.class);
// 4 指定map输出的数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 5 指定最终输出的数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 6 指定job的输入原始所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result?1:0);
}
}
定义一个TwoShareFriendsReducer.java类
代码如下:
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class TwoShareFriendsReducer extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
StringBuffer sb = new StringBuffer();
for (Text friend : values) {
sb.append(friend).append(" ");
}
context.write(key, new Text(sb.toString()));
}
}
定义一个TwoShareFriendsReducer.java类
代码如下:
import java.io.IOException;
import java.util.Arrays;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class TwoShareFriendsMapper extends Mapper<LongWritable, Text, Text, Text>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// A I,K,C,B,G,F,H,O,D,
// 友 人,人,人
String line = value.toString();
String[] friend_persons = line.split("\t");
String friend = friend_persons[0];
String[] persons = friend_persons[1].split(",");
Arrays.sort(persons);
for (int i = 0; i < persons.length - 1; i++) {
for (int j = i + 1; j < persons.length; j++) {
// 发出 <人-人,好友> ,这样,相同的“人-人”对的所有好友就会到同1个reduce中去
context.write(new Text(persons[i] + "-" + persons[j]), new Text(friend));
}
}
}
}
MapReduce的所有java类已创建成功
三、将编写的MapReduce程序打包并上传至,启动集群的Linux系统中
我这里是:hadoop111,hadoop112
Idea中打包 java程序:
File --> Project Structure --> Artifacts --> + -->JAR --> From modules with dependencies
随后在Main Class中选择 WordcountDriver,随后点击OK
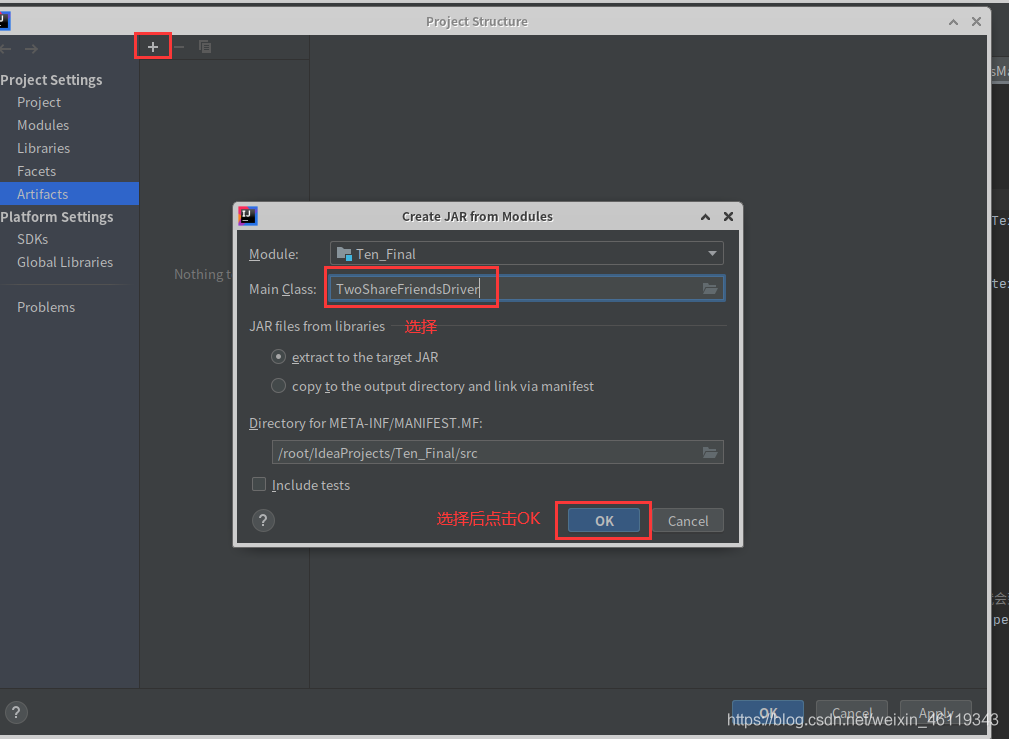
点击Ok后,再点击OK
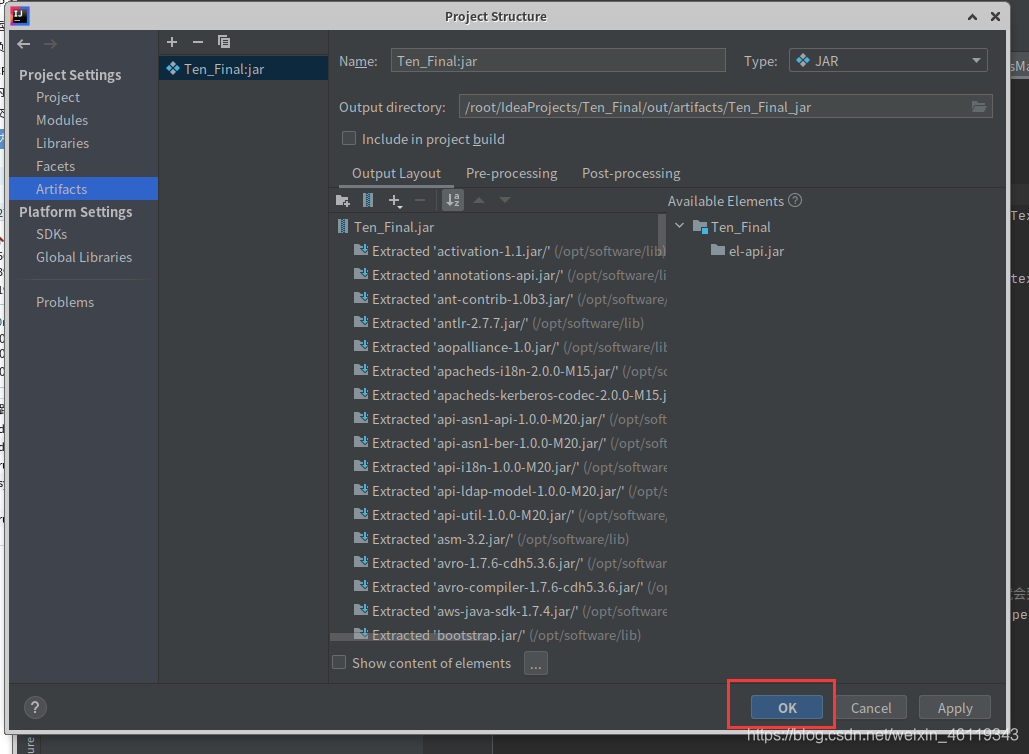
点击ok后,选择: Build --> Build Artifacts --> Build
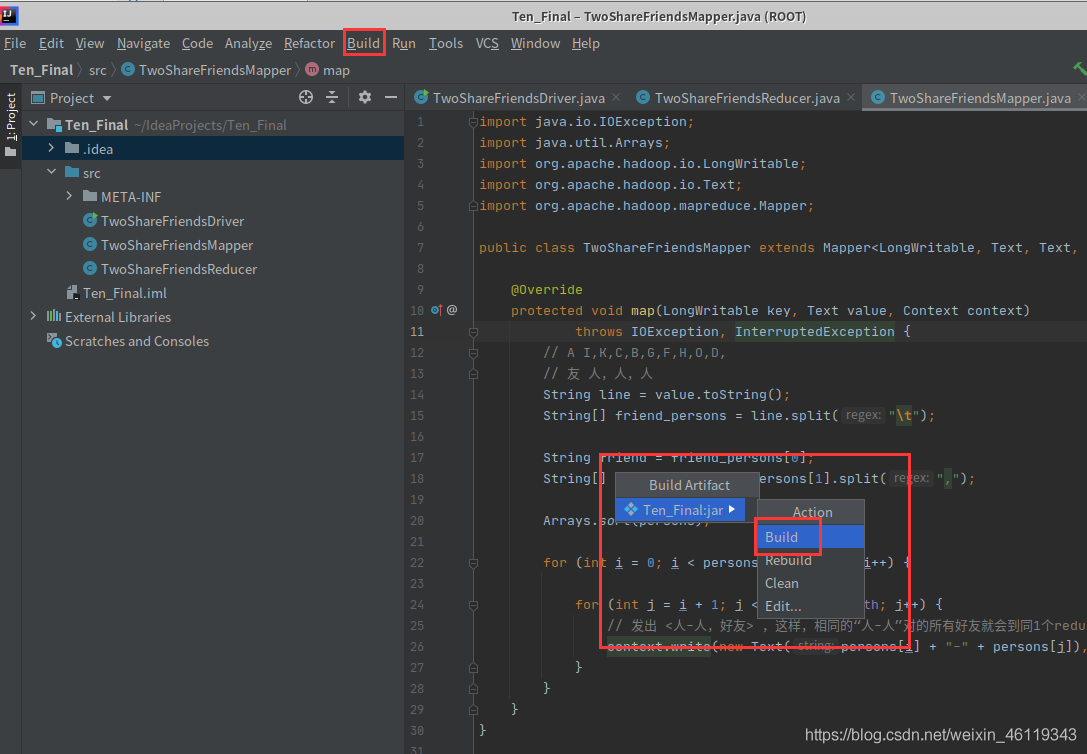
然后耐心等待一会
在左侧会自动生成一个out的文件,点击: out —> artifacts —> Ten_Final_ jar
即可查看是否打包成功
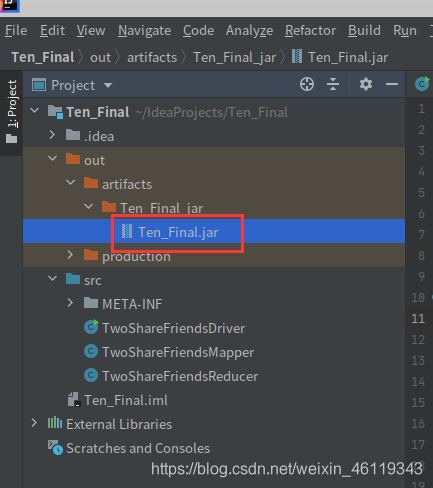
打包后在Linux系统中的 /root/ 下面找到 ideaProjects
然后点击 IdeaProjects --> Ten_Final --> out --> artifacts -->Ten_Final
找到已打好的jar包
在该目录下,右击打开终端输入scp命名,将jar包上传至启动集群的hadoop111的Linux系统中"/opt/software/" 文件夹下
SCP 命名:scp Ten_Final.jar root@hadoop111:/opt/software/
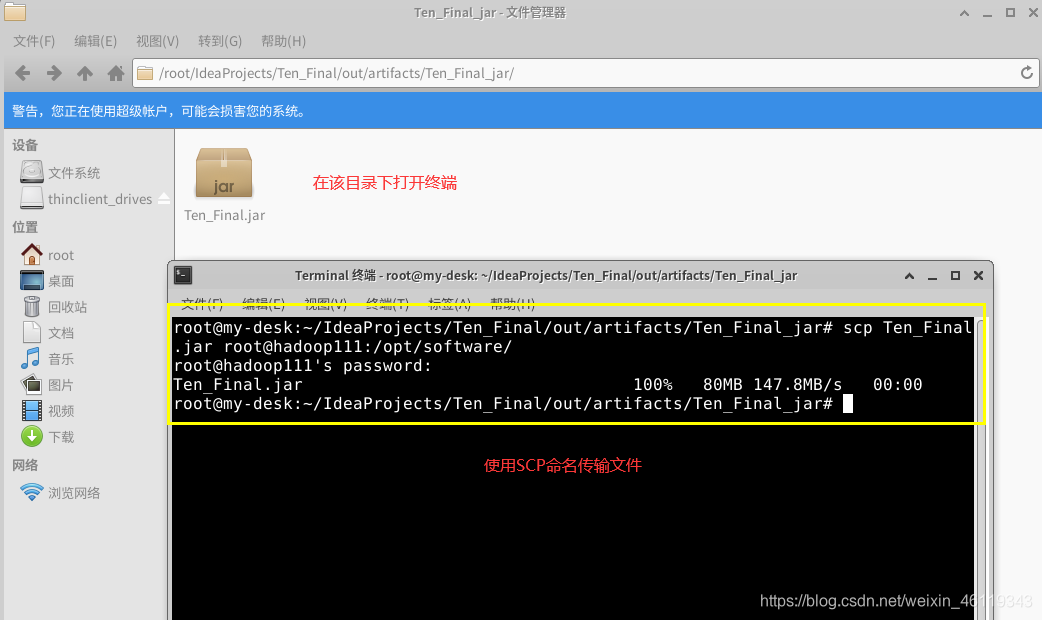
查看文件是否传输成功
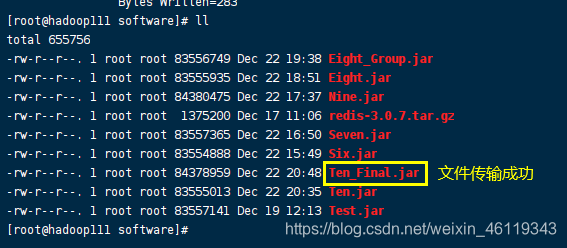
执行zip命名对该包进行删除两个会使程序出错的文件
ZIP命名:
zip -d Ten_Final.jar META-INF/.RSA META-INF/.SF

就在该目录下使用hadoop调用该包,根据(1)的手机号流量汇总结果再按照手机号不同归属地进行分组输出到不同的文件中
hadoop命名:
hadoop jar Ten_Final.jar /zs/java/output/output10/part-r-00000 /zs/java/output/output10_Final
(/zs/java/output/output10/part-r-00000 是(1)求出谁是谁的好友数据结果文件)
(/zs/java/output/output10_Final 代表hadop调用jar包将(1)的结果数据文件处理后的文件存放位置)
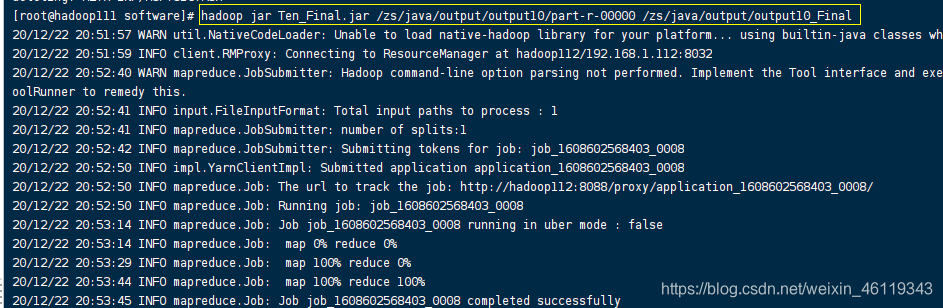
执行结果,执行结果在集群中查看
查看位置为 hadoop调用jar包将数据源文件处理后的文件存放位置
(/zs/java/output/output10_Final)
hadoop调用jar包执行效果为:
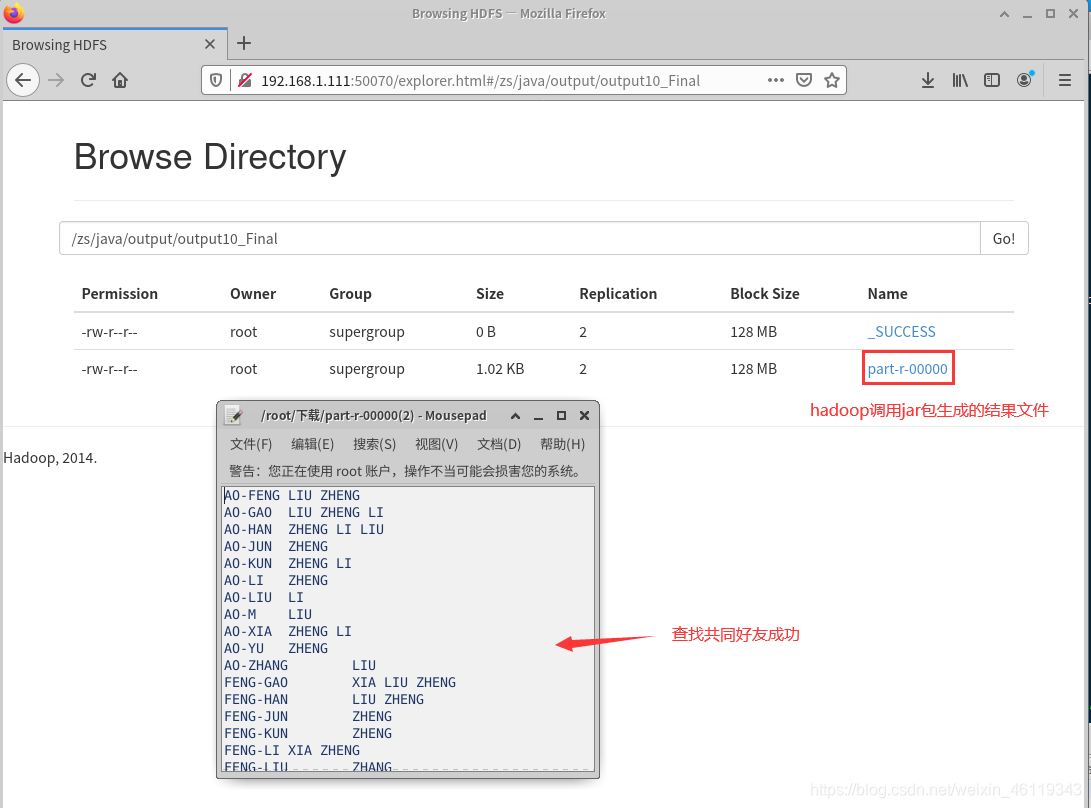















 4890
4890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









