






近期项目涉及到 Docker 底层实现的相关知识,借此机会记录下,方便自己以后翻阅。
本文参考文章链接如下:
浅谈日常使用的 Docker 底层原理-三大底座-腾讯云开发者社区-腾讯云
1. Docker 基本架构图
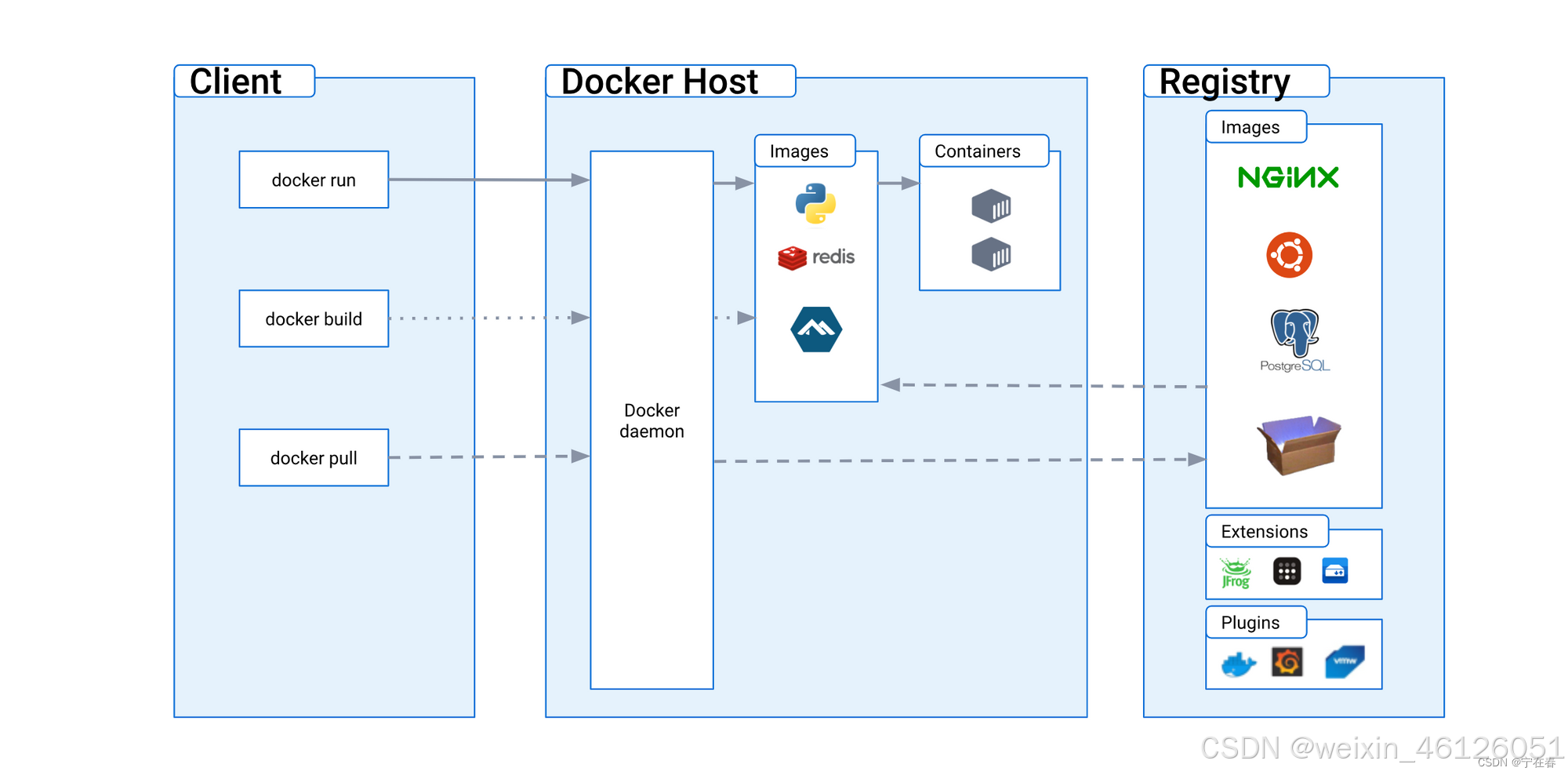
根据上图,可以发现 Docker 采用的是 C/S 架构,包括客户端和服务端。客户端和服务端既可以运行在一个机器上,也可通过 socket 或 RESTful API 来进行通信。
Docker 服务端:有一个守护进程(Daemon)接受来自客户端的请求,并处理这些请求(拉取镜像,运行容器)。Docker 守护进程一般在宿主主机后台运行,等待接收来自客户端的消息。
Docker 客户端:用户通过客户端输入命令实现跟 Docker 守护进程交互。
docker info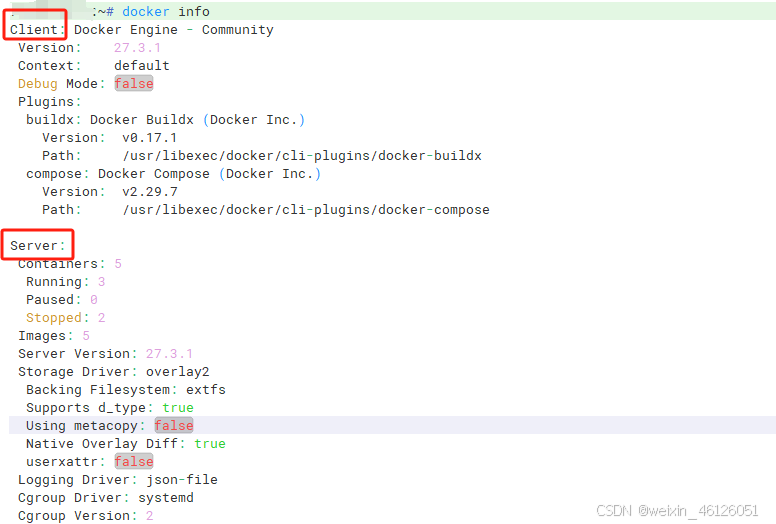
2. Docker 的三大核心原理
- 在容器进程启动之前重新挂载它的整个根目录“/”,用来为容器提供隔离后的执行环境文件系统(rootfs)。
- 通过 namespace 创建隔离,决定进程能够看到和使用哪些东西。
- 通过 cgroups(control groups) 技术来约束进程对资源的使用。
- namespace 和 cgroups 都是 Linux 内核中的技术,Docker 底层原理基于这两个技术。
- 对于 Linux 系统来说,Docker 也只是运行在上面的一个进程。
- 对于 Docker 来说,Cgroups 是制造约束的主要手段,而 Namespace 是用来修改进程视图的主要方法。
2.1 隔离(namespace)
namespace:namespaces 是对全局系统资源的一种封装隔离,使得处于不同 namespace 的进程拥有独立的全局系统资源,改变一个 namespace 中的系统资源只会影响当前 namespace 里的进程,对其他 namespace 中的进程没有影响。在同一个 namespace 下的进程可以感知彼此的变化,而对外界的进程一无所知,从而达到隔离的目的。
实现手段:通过约束和修改进程的动态表现,从而为其创造出一个边界。
执行下面图片中命令,可以查看容器进程的命名空间,发现宿主机上面的两个 docker 容器进程之间的命名空间的编号是不一样的,说明这两个进程不是在一个命名空间的。一个进程的每种 namespace,都在它对应的 /proc/[进程号]/ns 下有一个对应的虚拟文件,并且链接到一个真实的 namespace 文件上。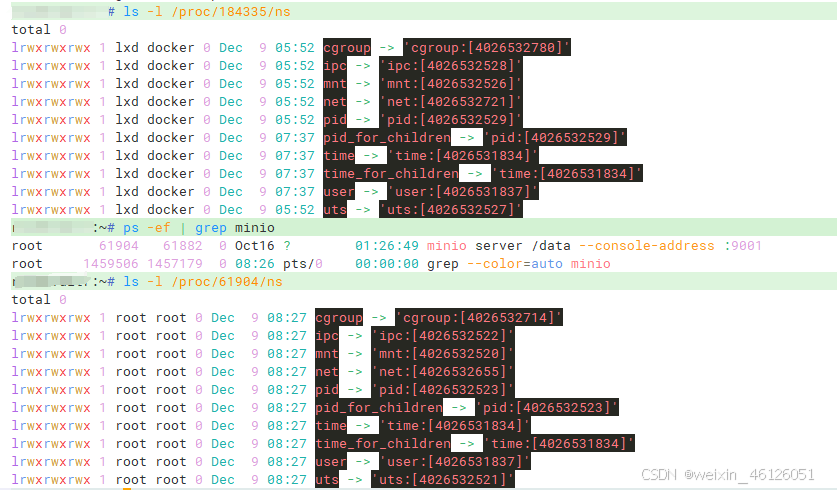
实现原理:
使用 Linux 内核的 namespace 机制。如果我们创建了多个 PID namespace,每个 namespace 里的应用进程,都会认为自己是当前容器里的第 1 号进程,它们既看不到宿主机里真正的进程空间,也看不到其他 PID namespace 里的具体情况。
总结:Docker 容器实际上是在创建容器进程时,指定了这个进程所需要启用的一组 namespace 参数。这样,容器就只能看到当前 namespace 所限定的资源、文件、设备、状态,或者配置。而对于宿主机以及其他不相关的程序,它就完全看不到了。因此,容器只是一个特殊的进程。
docker exec 是怎么进入容器里的?
namespace 创建的隔离空间虽然看不见摸不着,但一个进程的 namespace 信息在宿主机上是确确实实存在的,并且是以一个文件的方式存在(见图片中的命令)。一个进程,可以选择加入到某个进程已有的 namespace 当中,从而达到进入这个进程所在容器的目的。
namespace的分类:
Mount Namespace文件系统隔离。UTS Namespace隔离主机和域名信息。IPC Namespace隔离进程间通信。PID Namespace进程隔离。Network Namespace网络资源隔离。User Namespace用户和用户组隔离。
2.2 限制(Cgroups)
隔离开后面临的问题:
无论 Docker 如何进行隔离,这些容器都运行在我们的宿主机上,它依赖的硬件资源都只是当前机器。另外,其实启动的每一个容器进程,它本身其实就是当前宿主机的进程之一,那么本质上来说,它也会和宿主机中的其他进程进行资源的竞争。
因此,我们就要针对Docker运行的容器进行资源的限制,Cgroups 就是 Linux 内核中用来为进程设置资源的一个技术。
Cgroups:
限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等。 还可以对进程进行优先级设置,审计,挂起和恢复等操作。
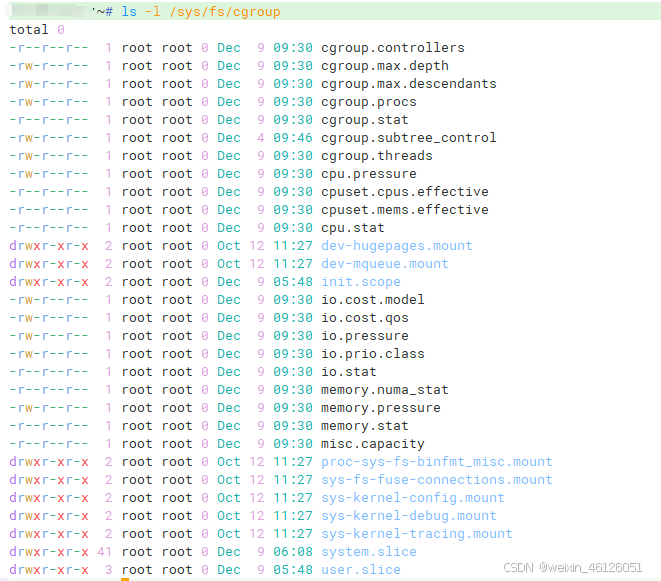
Linxu中为了方便用户使用cgroups,已经把其实现成了文件系统,其目录在 /sys/fs/cgroup 下,在 /sys/fs/cgroup 下面有很多诸如 cpuset、cpu、 memory 这样的子目录,也叫子系统,这些都是我这台机器当前可以被 Cgroups 进行限制的资源种类。
cpu:限制进程在一段时间内能够分配到的 CPU 时间blkio:为块设备设定 I/O 限制,一般用于磁盘等设备cpuset:为进程分配单独的 CPU 核和对应的内存节点memory:为进程设定内存使用的限制
2.3 rootfs
Linux中:rootfs 是一个操作系统所包含的文件、配置和目录,并不包括操作系统内核。在 Linux 操作系统中,这两部分是分开存放的,操作系统只有在开机启动时才会加载指定版本的内核镜像。
Docker中:在 Docker 架构中,当 Docker daemon 为 Docker 容器挂载 rootfs 时,沿用的 liunx 内核启动时的方法,即将 rootfs 设为只读模式。在挂载完毕之后,利用联合挂载(union mount )技术在已有的只读 rootfs 上再挂载一个读写层。这样,可读写层处于Docker容器文件系统的最顶层,其下可能联合挂载了多个只读层,只有在Docker容器运行过程中文件系统发生变化时,才会把变化的文件内容写到可读写层,并且隐藏只读层的老版本文件。
rootfs 组成:
rootfs 由三部分组成,由上往下分别是:可读写层,Init 层,只读层。以 Ubuntu 镜像为例。
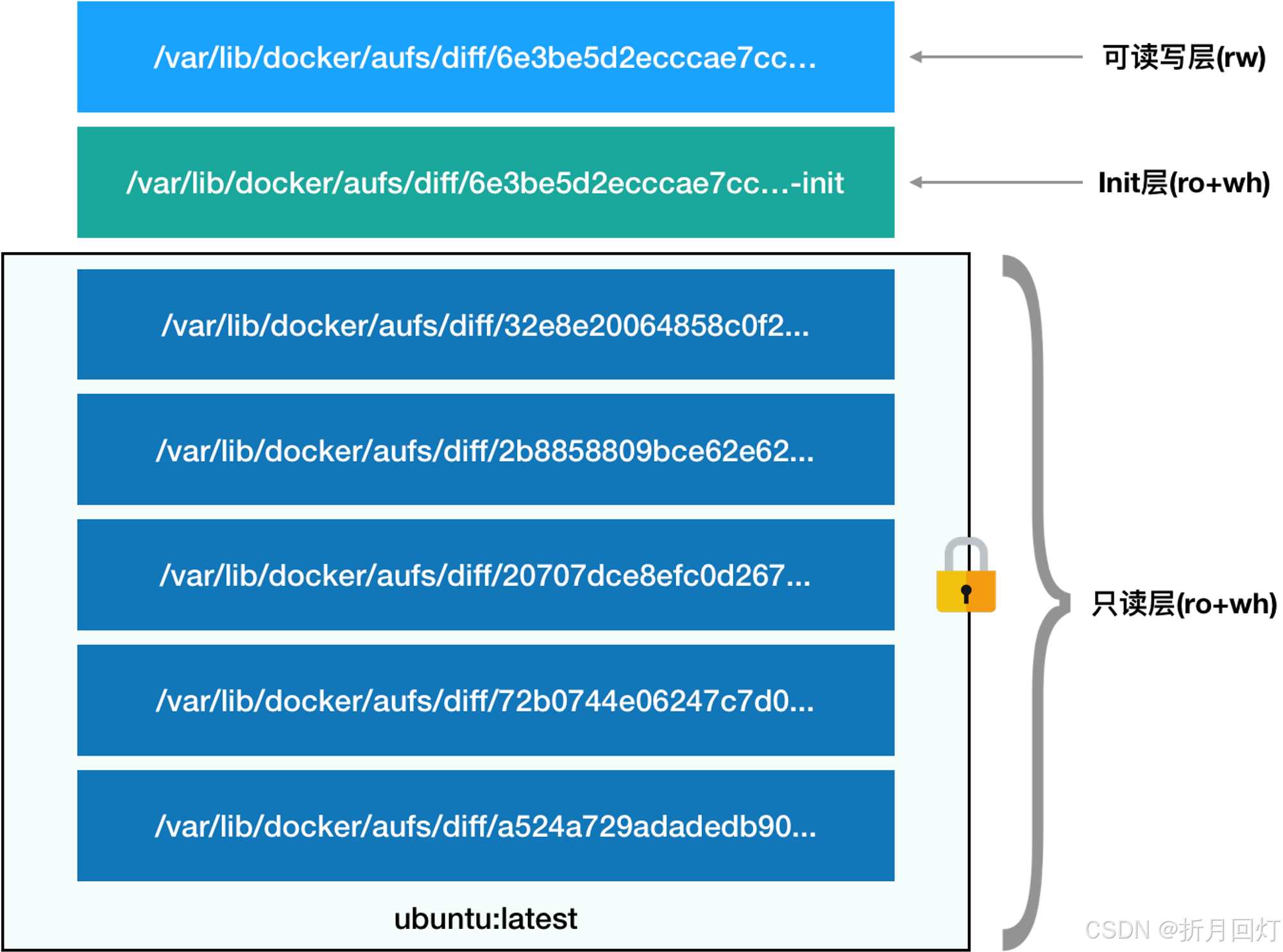
- 只读层:是容器的 rootfs 的下五层,它们的挂载方式都是只读的,可见这些层都以增量的方式分别包含了 Ubuntu 操作系统的一部分。
- 可读写层:是容器的 rootfs 的最上面一层,在没有写入文件之前,这个目录是空的。而一旦在容器里做了写操作,你修改产生的内容就会以增量的方式出现在这个层中。该层专门用来存放你修改 rootfs 后产生的增量,无论是增、删、改,都发生在这里,而原先的只读层里的内容则不会有任何变化。
删除只读层里的一个文件是怎么完成的?
为了实现这样的删除操作,会在可读写层创建一个 whiteout 文件,把只读层里的文件遮挡起来。比如,你要删除只读层里一个名叫 foo 的文件,那么这个删除操作实际上是在可读写层创建了一个名叫.wh.foo 的文件。这样,当这两个层被联合挂载之后,foo 文件就会被.wh.foo 文件遮挡起来,消失了。
- Init 层:在只读层与可读写层的中间,是 Docker 项目单独生成的一个内部层,专门用来存放 /etc/hosts、/etc/resolv.conf 等信息。
需要Init层的原因:
这些文件本来属于只读的 Ubuntu 镜像的一部分,但是用户往往需要在启动容器时写入一些指定的值比如 hostname,所以就需要在可读写层对它们进行修改。可是,这些修改往往只对当前的容器有效,我们并不希望执行 docker commit 时,把这些信息连同可读写层一起提交掉。所以,Docker 做法是,在修改了这些文件之后,以一个单独的层挂载了出来。而用户执行 docker commit 只会提交可读写层,所以是不包含这些内容的。
综上,docker run 命令启动某个容器时,实际上在镜像的顶部添加了一个新的可写层,而这个新的可写层,被我们称为了容器。容器启动后,其内的应用所有对容器的改动,文件的增删改操作都只会发生在容器层(可读写层)中,对容器层(可读写层)下面的所有只读镜像层没有影响。
写在最后:
写到这里,对 Docker 和 Linux 的一些技术有了新的理解,该博客只是一个浅浅开端,希望能够帮助像我一样对容器技术底层实现迷惑的人初步认识容器。我对 Linux 的知识还很匮乏,有很多知识还需要进一步学习,希望能继续和大佬们交流学习。

















 2491
2491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









