







推荐系统设计
1 推荐系统要素
- UI 和 UE(前端界面)
- 数据 (Lambda架构)
- 业务知识
- 算法
2 推荐系统架构
2.1 推荐系统整体架构

2.2 大数据Lambda架构
- 由Twitter工程师Nathan Marz(storm项目发起人)提出
- Lambda系统架构提供了一个结合实时数据和Hadoop预先计算的数据环境和混合平台, 提供一个实时的数据视图
- 分层架构
- 批处理层
- 数据不可变, 可进行任何计算, 可水平扩展
- 高延迟 几分钟~几小时(计算量和数据量不同)
- 日志收集 Flume (不同的数据放到hdfs中,数据搬运的工作)
- 分布式存储 Hadoop hdfs(磁盘阵列?电脑磁盘串联?)
- 分布式计算 Hadoop MapReduce & spark(一个P的数据进行排序)
- 视图存储数据库
- nosql(HBase/Cassandra)
- Redis/memcache
- MySQL
- 实时处理层
- 流式处理, 持续计算
- 存储和分析某个窗口期内的数据
- 最终正确性(Eventual accuracy)
- 实时数据收集 flume & kafka(消息队列,数据来的太快了,需要排队 )
- 实时数据分析 spark streaming/storm(twitter)/flink(阿里)
- 服务层
- 支持随机读
- 需要在非常短的时间内返回结果
- 读取批处理层和实时处理层结果并对其归并
- 批处理层
- Lambda架构图
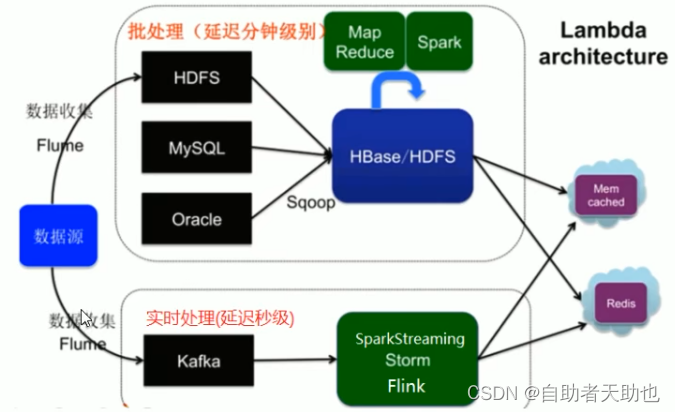
实时计算是基于离线计算的结果基础上的调整
2.3 离线计算
- 数据量很大,pb级别
- 缺点,速度慢,分钟级别延迟
- Hadoop,spark core, spark sql
- hive
2.4 实时计算
- 数据量小
- 响应快,ms级别
- spark streaming
- strom
- flink
2.5 消息中间件
- flume 日志采集系统
- kafka 消息队列
2.6 存储相关
- hbase nosql数据库
- hive sql操作hdfs数据
3 推荐算法架构
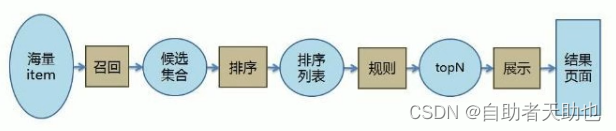
3.1 召回阶段(海选)
- 召回决定了最终推荐结果的天花板
- 常用算法:
- 协同过滤(基于用户 基于物品的) memory base
- 基于内容 (根据用户行为总结出自己的偏好 根据偏好 通过文本挖掘技术找到内容上相似的商品)
- 基于隐语义
3.2 排序阶段
- 逻辑回归
- 召回决定了最终推荐结果的天花板, 排序逼近这个极限, 决定了最终的推荐效果
- CTR预估 (点击率预估 使用LR算法) 估计用户是否会点击某个商品 需要用户的点击数据
3.3 策略调整
oppo手机的微博不要出现华为的广告、华为充钱了
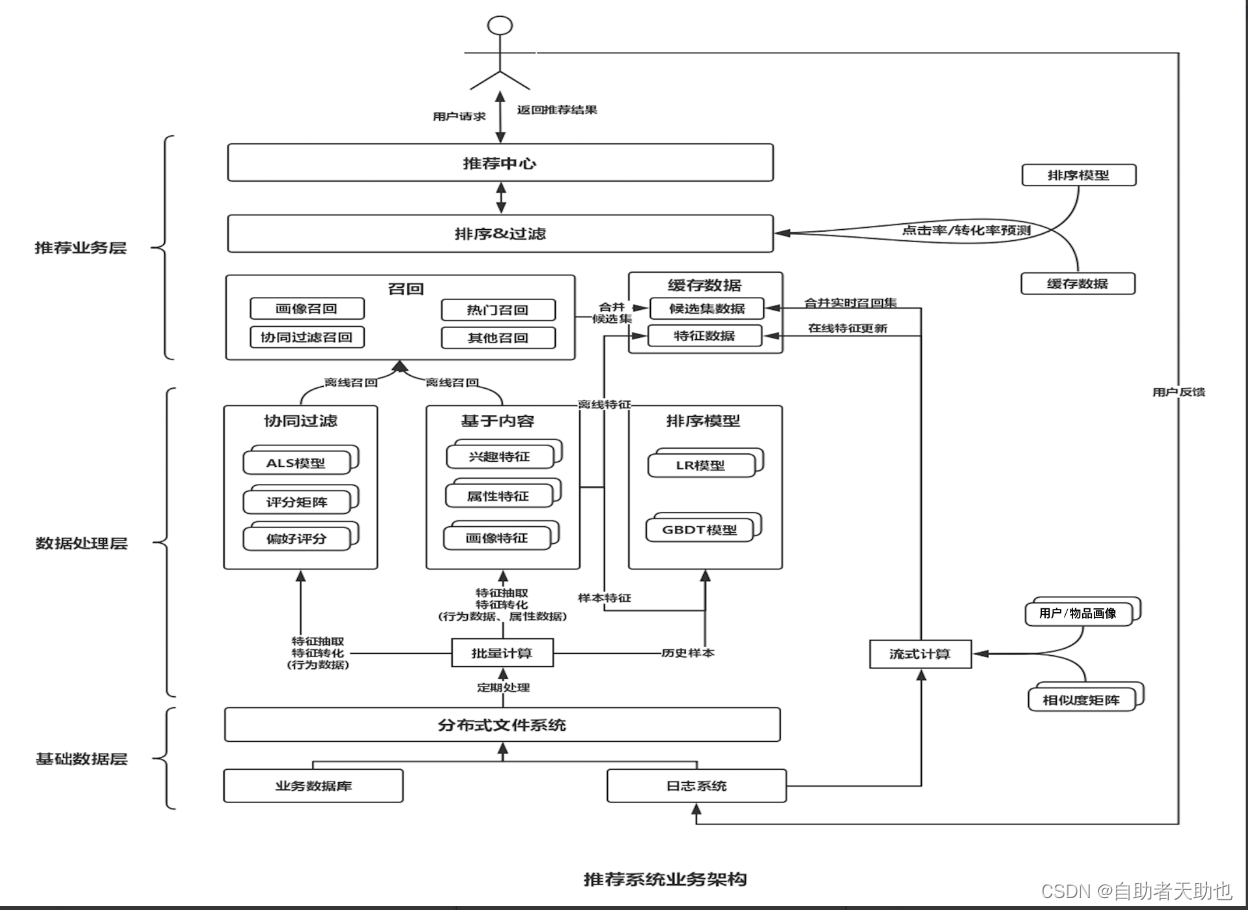
3.4 推荐系统的整体架构
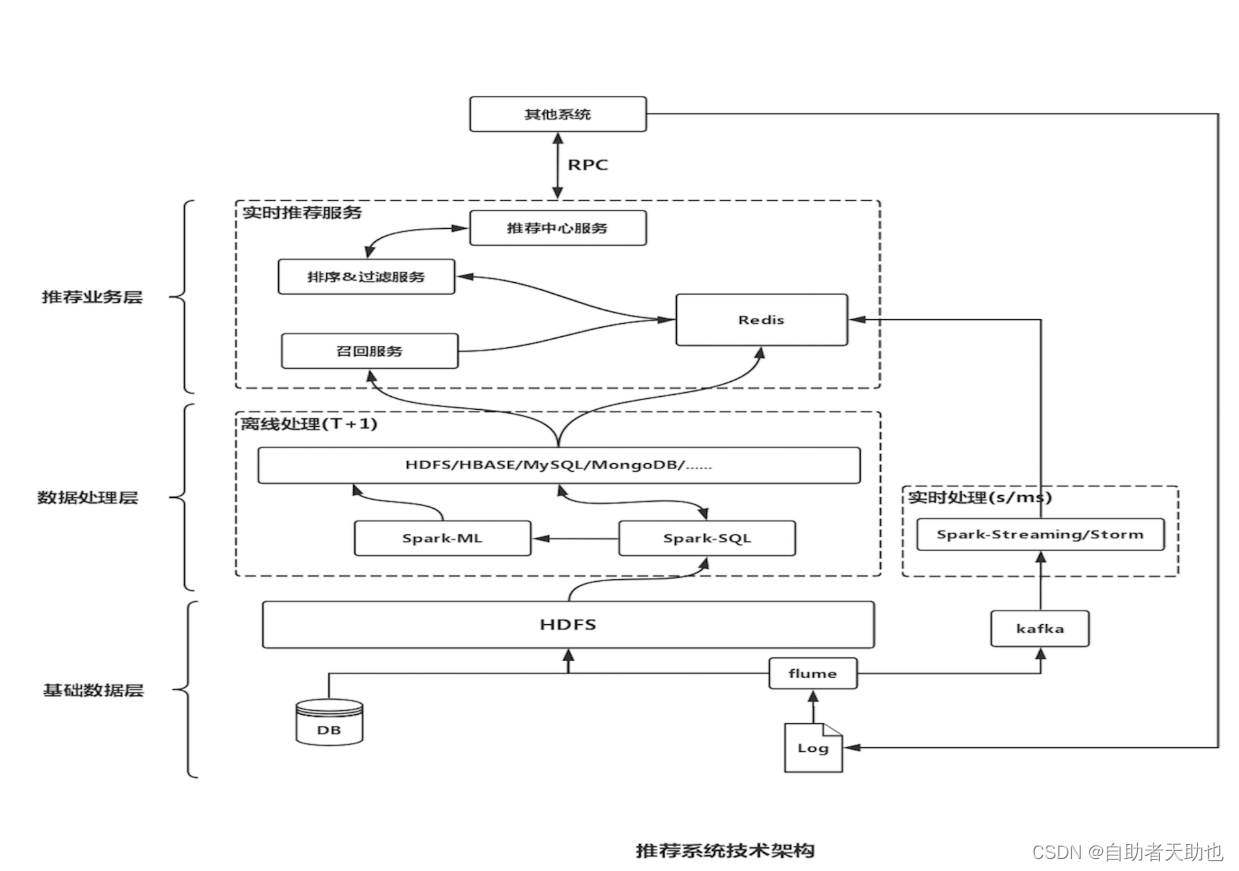















 192
192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









