







虚拟机准备
修改主机名
连接服务器后修改主机名
hostnamectl set-hostname 主机名
bash
分发脚本
#1. scp(secure copy)安全拷贝
(1)scp定义:
scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
(2)基本语法
scp -r $pdir/$fname $user@hadoop$host:$pdir/$fname
命令 递归 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
2、分发脚本
#!/bin/bash
prame=$1 #接收文件名
dirname=`dirname $1`
cd $dirname #进入该文件路径下
fullpath=`pwd -P .` #获得该文件的绝对路径
user=`whoami` #获得当前用户的身份
for ip in node2 node3 node4 #循环三个主机名
do
echo ============ $ip =============
scp -r $prame ${user}@$ip:$fullpath
done
---------------------------------------------------------------------------------------
vi call_all.sh(可以向所有的主机发送命令)
#!/bin/bash
prame=$1 #接收命令参数
for ip in node1 node2 node3 node4 #循环三个主机名
do
echo ============= $ip $prame ==============
ssh $ip "source /etc/profile;$prame"
done
chmod a+x call_all.sh
---------------------------------------------------------------------------------------
vim jps_all.sh(相当于同时下达各主机下达jps命令)
#!/bin/bash
for ip in node1 node2 node3 node4 #循环三个主机名
do
echo ============= $ip jps ==============
ssh $ip "source /etc/profile;jps"
done
(b)修改脚本 xsync 具有执行权限
$ chmod 777 xsync
(c)调用脚本形式:xsync 文件名称
$ xsync /home/atguigu/bin
ssh配置文件检查
使用命令
vim /etc/ssh/sshd_config
查看下面几个配置项是否正确。如不正确,需按下面要求进行修改。(在非编辑模式下,按“/xxx”可进行搜索,如“/UseDNS”为搜索UseDNS,按回车进行跳转)
“UseDNS”项必须配置为“no”。
“MaxStartups”必须配置为大于等于1000。
“PasswordAuthentication”和“ChallengeResponseAuthentication”两个配置项都设置为“yes”。
注意:四台机器都需要设置,并且在设置的时候记得删除对应行的井号“#”。
hosts配置文件设置
步骤1使用命令ifconfigeth0查询ECS内网IP
ifconfig eth0
修改hosts配置文件
使用命令vim/etc/hosts,为node1-4四个节点增加内网IP与节点主机名的映射,确保各节点之间可以使用主机名作为通信的方式。
vim/etc/hosts
需删除自己的主机名映射到127.0.0.1的映射,如node1为:
127.0.0.1 node1
加入以下内容如下:
192.168.0.100 node1
192.168.0.101 node2
192.168.0.102 node3
192.168.0.103 node4
注意:如果内网IP与文档不同,请记得修改成自己的,四台服务器都需要修改。
修改cloud.cfg配置文件
使用公共镜像创建的ECS服务器,默认安装Cloud-init工具,能够对新创建弹性云服务器中指定的自定义信息(主机名、密钥和用户数据等)进行初始化配置。
但它会在ECS重启动后修改一下系统配置文件,如/etc/hosts、/etc/hostname等。所以需要修改Cloud-init工具的配置文件/etc/cloud/cloud.cfg,注释对系统关键配置文件的影响项
步骤1编辑cloud.cfg配置文件
在node1-4进行以下操作(在非编辑模式下,按49,然后再按一下shift+g,可跳转到49行)
vim/etc/cloud/cloud.cfg注释第49、50、51行内容:
#-set_hostname
#-update_hostname
#-update_etc_hosts
关闭防火墙
在node1-4四个节点执行如下命令关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
配置ssh互信免密登录
步骤1生成id_rsa.pub文件
各节点执行ssh-keygen -t rsa命令后,连续回车三次后生成/root/.ssh/id_rsa.pub文件
/root/.ssh/id_rsa.pub
每个节点分别sshnode1~node4,选择yes后,确保能够互相免密码登录。
ssh node1
ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
先给自己发免密登录设置
各个节点执行cat/root/.ssh/id_rsa.pub命令,我们需要将密钥进行汇总,思路是先将node2、node3、node4的密钥拷贝到node1,在node1进行汇总,然后将汇总好的文件分发到node2、node3、node4,这样的话,每个节点就有了彼此的密钥,达到互相免密码登录的效果。
scp .ssh/id_rsa.pub root@node1:/root/.ssh/id2
scp .ssh/id_rsa.pub root@node1:/root/.ssh/id3
scp .ssh/id_rsa.pub root@node1:/root/.ssh/id4
scp id_rsa.pub root@node1:/root/.ssh/id2
把公匙都放到一个文件
cat id2 id3 id4 id_rsa.pub >> authorized_keys
cat id_rsa.pub >> authorized_keys
cat authorized_keys
然后再分发
scp authorized_keys root@node2:~/.ssh/
scp authorized_keys root@node3:~/.ssh/
scp authorized_keys root@node4:~/.ssh/
每个节点分别sshnode1~node4,选择yes后,确保能够互相免密码登录。
ssh node1
ssh node2
ssh node3
ssh node4
注意:登录进其他节点之后,请务必记得退出,然后再测试能否登录进其他节点。
挂载数据盘
1、执行fdisk /dev/vdb后,输入n后连续按5次回车到Command(mforhelp):命令行,
输入w将分区结果写入分区表中,并自动退出命令行
2、执行partprobe命令,将新的分区表变更同步至操作系统
3、执行mkfs -t ext4 /dev/vdb1命令,将新建分区文件系统设为系统所需格式
4、执行mount /dev/vdb1 /home命令,将新建分区挂载到/home目录
5、执行df-h命令,查看/home目录是否已经挂载成功,如下所示则表示挂载成功
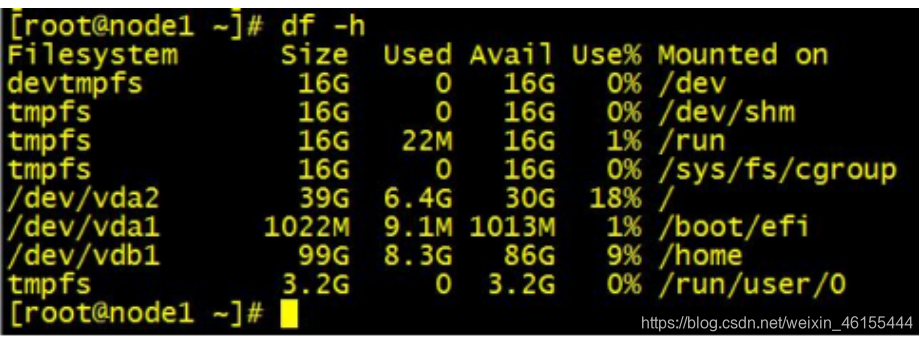
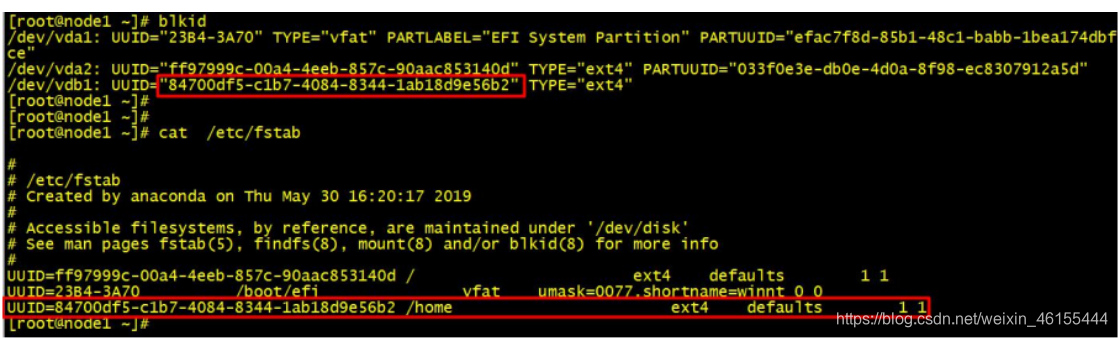
6、执行blkid查看/dev/vdb1的UUID
7、设置开机自动挂载,
执行vim/etc/fstab后,按照步骤6查询到的UUID,增加如下一行
UUID=e0e0b1e7-d0c5-46ba-b805-9846bd35bb88 /home ext4 defaults 1 1
UUID=4d53f32a-c8a3-478e-bd41-ef2536711b8a /home ext4 defaults 1 1
UUID=8ce086b5-4351-44dd-93d0-207714ba69ec /home ext4 defaults 1 1
UUID=66e30ad1-bac7-4c0c-938a-6bada62b73f9 /home ext4 defaults 1 1
注意:四台服务器都需要操作。
下载软件包
四台服务器都需要操作
创建文件夹
mkdir -p /home/modules/data/buf/
mkdir -p /home/test_tools
mkdir -p /home/nm/localdir
安装java和hadoop
(1)查询是否安装Java软件:
$ rpm -qa | grep java
(2)如果安装的版本低于1.7,卸载该JDK:
$java -version
$ sudo rpm -e 软件包
(3)查看JDK安装路径:
$ which java
经过查找自带的java的java_home在
/usr/lib/jvm/java
下载Hadoop软件包
在node1执行如下命令,从华为公有云OBS的公共存储中下载Hadoop软件包到node1的/home目录下,下载完成后需要修改软件包目录名称
wget https://xunfang.obs.cn-south-1.myhuaweicloud.com/kunpeng_bigdata_pro_extend_tools.tar.gz
下载后解压
mv kunpeng_bigdata_pro_extend_tools.tar.gz extend_tools.tar.gz
tar -zxvf extend_tools.tar.gz
cd /home/extendto
> tar -zxvf hadoop-2.8.3.tar.gz -C /home/modules
> ls /home/modules/ | grep hadoop
搭建集群
修改配置文件
步骤 1 配置 hadoop-env.sh
在 node1 上执行命令
vim /home/modules/hadoop-2.8.3/etc/hadoop/hadoop-env.sh
添加上 JAVA_HOME 路径,ECS 已经默认装好了 JDK
export JAVA_HOME=/usr/lib/jvm/java
步骤 2 预配置 core-site.xml
在 node1 上执行命令 vim /home/modules/hadoop-2.8.3/etc/hadoop/core-site.xml
在与之间填入以下内容,此为预配置,后期还要再修改
<property>
<name>fs.obs.readahead.inputstream.enabled</name>
<value>true</value>
</property>
<property>
<name>fs.obs.buffer.max.range</name>
<value>6291456</value>
</property>
<property>
<name>fs.obs.buffer.part.size</name>
<value>2097152</value>
</property>
<property>
<name>fs.obs.threads.read.core</name>
<value>500</value>
</property>
<property>
<name>fs.obs.threads.read.max</name>
<value>1000</value>
</property>
<property>
<name>fs.obs.write.buffer.size</name>
<value>8192</value>
</property>
<property>
<name>fs.obs.read.buffer.size</name>
<value>8192</value>
</property>
<property>
<name>fs.obs.connection.maximum</name>
<value>1000</value>
</property>
<property>
<!-- 指定HDFS中NameNode的地址 -->
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<name>hadoop.tmp.dir</name>
<value>/home/modules/hadoop-2.8.3/tmp</value>
</property>
<property>
<name>fs.obs.buffer.dir</name>
<value>/home/modules/data/buf</value>
</property>
<property>
<name>fs.obs.impl</name>
<value>org.apache.hadoop.fs.obs.OBSFileSystem</value>
</property>
<property>
<name>fs.obs.connection.ssl.enabled</name>
<value>false</value>
</property>
<property>
<name>fs.obs.fast.upload</name>
<value>true</value>
</property>
<property>
<name>fs.obs.socket.send.buffer</name>
<value>65536</value>
</property>
<property>
<name>fs.obs.socket.recv.buffer</name>
<value>65536</value>
</property>
<property>
<name>fs.obs.max.total.tasks</name>
<value>20</value>
</property>
<property>
<name>fs.obs.threads.max</name>
<value>20</value>
</property>
配置 OBS 转存

步骤 2 在 OBS 控制台中选择要对接 Hadoop 的 OB
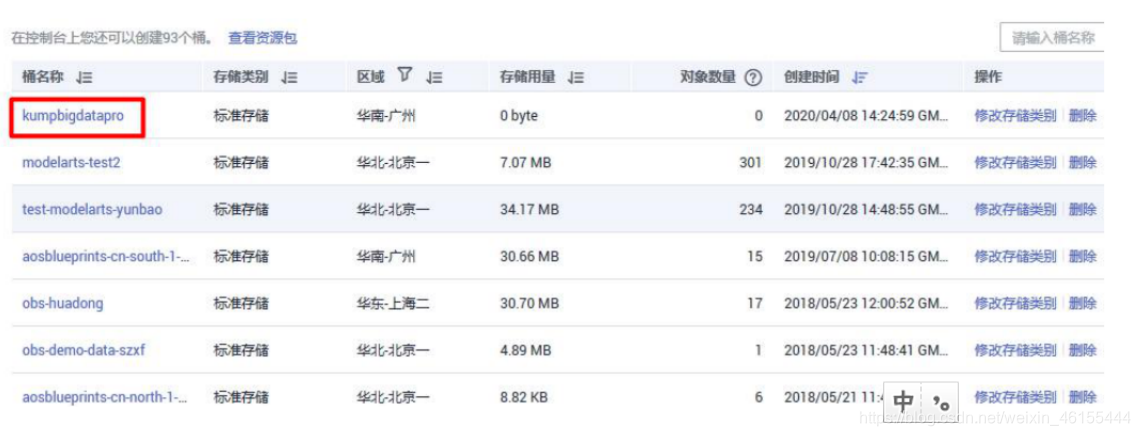
如果当前账号下没有 OBS 桶,请自行创建新 OBS 桶,自定义桶名称,其它参数默认
步骤 3 记录桶名称、Endpoint、区域等基本信息
我的:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1JK2vmLJ-1610179952441)(D:\study\学校\大二\鲲鹏班学习\笔记\day09服务器购买和搭建hadoop\配置服务器集群.assets\image-20201112085500535.png)]](https://i-blog.csdnimg.cn/blog_migrate/4f26ad42c6e1b913bb8b56d72d46d3f9.png)

桶名称
cyt-84
存储类别
标准存储
桶版本号
3.0
区域
华东-上海一
账号ID
0953fef3cf00f29e0fdcc00338ef90e0
创建时间
2020/11/12 08:54:02 GMT+08:00
多版本控制
未启用 编辑
Endpoint
obs.cn-east-3.myhuaweicloud.com
访问域名
cyt-84.obs.cn-east-3.myhuaweicloud.com
数据冗余存储策略
已开启
集群类型
公共集群
步骤 4 记录 AK 和 SK
访问密钥即 AK/SK(Access Key ID/Secret Access Key),是通过开发工具访问华为云时的身份凭证。
注意:每个访问密钥仅能在创建时下载一次,如果已经获取过,则不需要重新获取
方式如下图,打开“我的凭证”-“访问秘钥”-“新建访问密钥
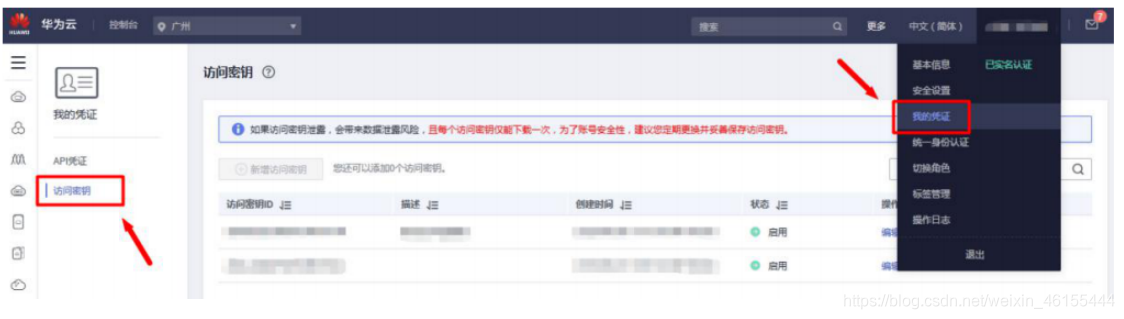
我的:
| User Name | Access Key Id | Secret Access Key |
|---|
步骤 5 重新修改 core-site.xml 配置文件
在 node1 上执行命令 vim /home/modules/hadoop-2.8.3/etc/hadoop/core-site.xml,在
配置文件中添加 fs.obs.access.key、fs.obs.secret.key、fs.obs.endpoint 3 项内容,并按照
实际情况填写
<property>
<name>fs.obs.access.key</name>
<value>Access Key ID</value>
</property>
<property>
<name>fs.obs.secret.key</name>
<value>Secret Access Key</value>
</property>
<property>
<name>fs.obs.endpoint</name>
<value>obs.cn-north-4.myhuaweicloud.com</value>
</property>
<property>
<name>fs.obs.access.key</name>
<value>UBXE52FOL57MJTQWWXIA</value>
</property>
<property>
<name>fs.obs.secret.key</name>
<value>Q7N5IHkQmESTIKwi0p5wB9bcxB5xcxykB7AibZjG</value>
</property>
<property>
<name>fs.obs.endpoint</name>
<value>obs.cn-east-3.myhuaweicloud.com</value>
</property>
配置 hdfs-site.xml
在 node1 上执行命令 vim /home/modules/hadoop-2.8.3/etc/hadoop/hdfs-site.xml,
在与之间内容替换如下:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:50090</value>
</property>
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>node1:50091</value>
</property>
配置 yarn-site.xml
在 node1 上执行命令 vim /home/modules/hadoop-2.8.3/etc/hadoop/yarn-site.xml
在与之间内容替换如下:
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!-- 指定YARN的ResourceManager的地址 -->
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
<description>表示 ResourceManager 安装的主机</description>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>node1:8032</value>
<description>表示 ResourceManager 监听的端口</description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/home/nm/localdir</value>
<description>表示 nodeManager 中间数据存放的地方</description>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>3072</value>
<description>表示这个 NodeManager 管理的内存大小</description>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
<description>表示这个 NodeManager 管理的 cpu 个数</description>
</property>
配置 mapred-site.xml
在 node1 上执行命令
cp /home/modules/hadoop-2.8.3/etc/hadoop/mapred-site.xml.template /home/modules/hadoop-2.8.3/etc/hadoop/mapred-site.xml
,然后编辑复制出来的配置
文件 vim /home/modules/hadoop-2.8.3/etc/hadoop/mapred-site.xml
在<configuration>与</configuration>之间内容替换如下:
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
<property>
<name>mapred.task.timeout</name>
<value>1800000</value>
</property>
配置 slaves
在 node1 节点配置从节点,删掉里面的 localhost,配置上从节点(node2、node3、node4)
vim /home/modules/hadoop-2.8.3/etc/hadoop/slaves
node2
node3
node4
1.2.4.8 更改 jar 包
在 node1 节点,执行如下命令将 OBA-HDFS 的插件 jar 包,替换到对应的目录中
cp /home/extend_tools/hadoop-huaweicloud-2.8.3.33.jar /home/modules/hadoop-2.8.3/share/hadoop/common/lib/
cp /home/extend_tools/hadoop-huaweicloud-2.8.3.33.jar /home/modules/hadoop-2.8.3/share/hadoop/tools/lib
cp /home/extend_tools/hadoop-huaweicloud-2.8.3.33.jar /home/modules/hadoop-2.8.3/share/hadoop/httpfs/tomcat/webapps/webhdfs/WEB-INF/lib/
cp /home/extend_tools/hadoop-huaweicloud-2.8.3.33.jar /home/modules/hadoop-2.8.3/share/hadoop/hdfs/lib/
1.2.4.10 添加环境变量
在 node1~node4,执行
vim /etc/profile
添加如下环境变量
export HADOOP_HOME=/home/modules/hadoop-2.8.3
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_CLASSPATH=/home/modules/hadoop-2.8.3/share/hadoop/tools/lib/*:$HADOOP_CLASSPATH
export JAVA_HOME=/usr/lib/jvm/java
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
在 node1~node4,执行如下命令,使环境变量生效
source /etc/profile
1.2.4.9 分发组件
在 node1 执行如下命令,将 hadoop-2.8.3 目录拷贝到其他各个节点的/home/modules/
下
for i in {2..4};do scp -r /home/modules/hadoop-2.8.3
root@node${i}:/home/modules/;done
等待几分钟拷贝完毕后,在 node2~node4 节点执行如下命令检查是否复制成功
[root@node2 ~]# ls /home/modules/ | grep hadoop
hadoop-2.8.3
[root@node3 ~]# ls /home/modules/ | grep hadoop
hadoop-2.8.3
[root@node4 ~]# ls /home/modules/ | grep hadoop
hadoop-2.8.3
3.在集群上分发配置好的Hadoop配置文件
$ xsync /home/modules/hadoop-2.8.3/
$ xsync /etc/profile
4.查看文件分发情况
$ cat /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml
启动集群
初始化 namenode
在 node1 上执行如下命令,初始化 namenode
hdfs namenode -format
1.2.5 启动 hadoop 集群
步骤 1 在 node1 节点执行以下命令:
start-dfs.sh
start-yarn.sh
返回信息中有以下内容,表示 hadoop 集群启动成功:
Starting namenodes on [node1]
Starting secondary namenodes [node1]
starting yarn daemons
备注:关闭 hadoop 集群的命令为 stop-dfs.sh && stop-yarn.sh
#### 1.2.6 验证 hadoop 状态
步骤 2 使用 jps 命令在 node1-4 中查看 java 进程
在 node1 中可以查看到 NameNode,SecondaryNameNode,ResourceManager
进程,在 node2-4 中可以查看到 NodeManager 和 Datanode 进程,表示 hadoop 集群状态正常。
jps
1538 WrapperSimpleApp
5732 SecondaryNameNode
5508 NameNode
6205 Jps
5918 ResourceManager
jps
3026 Jps
2740 DataNode
1515 WrapperSimpleApp
2862 NodeManager
这个需要在windows上配置映射
web端查看HDFS文件系统
http://node1:50070/dfshealth.html#tab-overview
步骤 3 访问 http://node1 弹性公网 IP:50070,可以登录 namenode 的 web 界面
无法打开时因为没有改映射C:\Windows\System32\drivers\etc,而该路径下的hosts即为保存映射的配置文件;用文本编辑器打开,它的内容其实和linux的hosts配置文件是相同的,只要在最后一行添加 ip+空格+映射名(可以自己取。用管理员身份进行打开编辑保存即可。
192.168.0.100 node1
192.168.0.101 node2
192.168.0.102 node3
192.168.0.103 node4
注意:如果还不能查看,看如下帖子处理
http://www.cnblogs.com/zlslch/p/6604189.html

















 789
789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









