









 本文详细描述了如何使用Spotfire工具对本地CSV文件进行数据操作,包括筛选、更新值、增加新行和删除行,以及利用Python脚本实现自动刷新和数据同步功能。
本文详细描述了如何使用Spotfire工具对本地CSV文件进行数据操作,包括筛选、更新值、增加新行和删除行,以及利用Python脚本实现自动刷新和数据同步功能。
Spotfire主要是一个分析工具,但有时我们有需求对数据进行操作后,再将数据写回原文件,实现对数据的更新
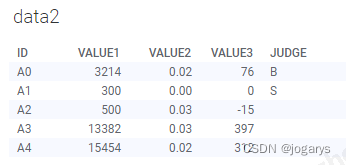
假设有一个本地文件(存放在Spotfire服务器可访问的共享盘即可实现网页访问),数据内容如下表,数据主键为ID列,将通过Spotfire对此文件进行读写(增删改查)
| ID | VALUE1 | VALUE2 | VALUE3 | JUDGE |
| A0 | 3214 | 0.0236 | 76 | B |
| A1 | 300 | 0 | 0 | |
| A2 | 500 | 0.0305 | -15 | |
| A3 | 13382 | 0.0297 | 397 | |
| A4 | 15454 | 0.0202 | 312 |
1. 新建一些文档属性,打开路径:文件→文档属性→属性→新建
| 属性 | 类型 | 示例值 | 脚本 | 备注 |
| file1 | string | E:\新建文件夹\data3.csv | 存储文件路径 | |
| id1 | string | A4 | 存储筛选的主键名称 | |
| judge | string | 存储待写入的JUDGE值 | ||
| lasttime | datetime | 2024/3/15 19:59 | refresh | 操作刷新时间,脚本用于每次操作后自动读取文件最新内容 |
| adddata | string | A5;133;0.03;60 A6;13609;0.05;888 | 存储需写入的行数据 | |
| deletedata | string list | A6, A5 | to_string | 存储选中的待删除的行,此类型属性无法提前新建,在后续操作过程建立。 脚本用于将string list的值转化为string |
| deleteid | string | A6;A5 | 存储上面转化为string后的值 |
refresh脚本:用于每次操作后自动读取文件最新内容,原理为每次函数操作后,会将当前时间输出到属性lasttime,lasttime的值改变后,会自动执行该脚本,实现数据表自动刷新
aa.Refresh()
#aa为脚本参数,选择需要刷新的数据表to_string脚本:用于将string list的值转化为string,由于多行选择的属性为string list,自定义函数(Python)无法识别该类型,因此需将其转化为string格式
Document.Properties['deleteid'] = ';'.join(Document.Properties['deletedata'])2.更新值并写入文件
在文本区域添加如下内容:下拉框绑定属性id1,文本输入框绑定属性judge,
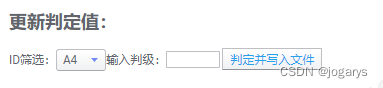
操作按钮“判定并写入文件”绑定自定义函数inputjudge,内容如下:
import pandas as pd
tablein.loc[tablein[tablein['ID'] == id].index,'JUDGE']=judgein
#写表
table = pd.DataFrame(tablein)
table.to_csv(file_name,encoding='gbk',index=False)
lasttime = now函数输入参数:

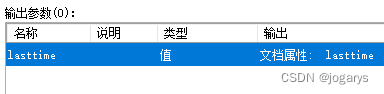
函数输出参数:

运行函数,输入参数选择如下:

输出参数选择如下:
测试一下:ID筛选A1,输入判级S,点击按钮“判定并写入文件”,可以看到表格中A1行的JUDGE值已更新为S:
此外,可以添加一个自动获取选定行的judge值的函数,用于选定ID后自动获取其judge值:
import numpy as np
if tablein[tablein['ID']==id]['JUDGE'].dropna().empty:
getjudge = ''
else:
getjudge = tablein[tablein['ID']==id]['JUDGE'].max()其中ID和tablein为选定的属性ID和输入表格,getjudge输出到属性judge
3.增加数据并写入文件
在文本区域添加如下内容:文本输入框(多行)绑定属性adddata,

操作按钮“增加并写入文件”绑定自定义函数add_rows,内容如下:
import numpy as np
import pandas as pd
col_num = len(tablein.columns)
adddata_list = [(a.split(';')+[np.nan]*col_num)[:col_num] for a in adddata.strip().split('\n')]
adddata_list = pd.DataFrame(adddata_list,columns=tablein.columns)
table = pd.DataFrame(tablein)
table = table.append(adddata_list,ignore_index=True)
table.to_csv(file_name,encoding='gbk',index=False)
lasttime = now函数输入参数:
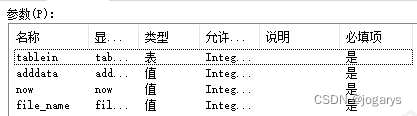
函数输出参数:

运行函数,输入参数选择如下:
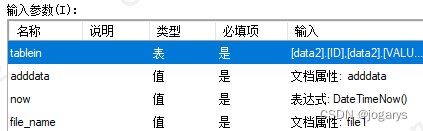
输出参数选择如下:
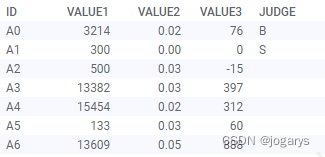
测试一下:文本框输入
“A5;133;0.03;60
A6;13609;0.05;888”
,点击按钮“增加并写入文件”,可以看到表格中增加了A5,A6两行数据:
4.删除数据并写入文件
在文本区域添加如下内容:列表框(多个选择)绑定新建属性deletedata,并添加1中脚本to_string

操作按钮“删除并写入文件”绑定自定义函数delete_rows,内容如下:
import numpy as np
import pandas as pd
deleteids = deleteid.split(';')
tablein.drop(tablein[tablein['ID'].isin(deleteids)].index, inplace=True)
table = pd.DataFrame(tablein)
table.to_csv(file_name,encoding='gbk',index=False)
lasttime = now函数输入参数:

函数输出参数:
运行函数,输入参数选择如下:

输出参数选择如下:
测试一下:列表框选择A5,A6,

,点击按钮“删除并写入文件”,可以看到表格中A5,A6两行数据已删除:
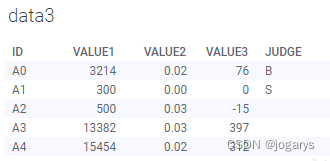
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









