









Dense Optical Tracking: Connecting the Dots—DOT密集光流与点跟踪相结合
标题:Dense Optical Tracking: Connecting the Dots
机构:Inria、纽约大学 2024
时间:2024 年的 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 上,具体日期是 2024 年 6 月 16 日
原文链接:https://arxiv.org/abs/2312.00786
代码链接:https://github.com/16lemoing/dot
官方主页:https://16lemoing.github.io/dot/

因为和自己的研究方向MOT的某个小点相关,在开学的这一段时间,自己在导师的指导下看了谷歌的Omnimotion,谷歌的Cotrack等一些点跟踪器,同时自己也从另外的一个角度学习了对于全像素进行跟踪的密集光流跟踪算法RATF等 不管是密集光流还是点跟踪算法区别主要是在于(部分点还是全像素点的一个密集光流算法)都是和点跟踪相关嘛这篇论文就结合的提出了分为三个阶段将我们的Cotracker点跟踪器和RATF光流跟踪器结合提出了新的一个简化计算的跟踪器DOT跟踪器
因为论文的部分比较短,我在看完并debug一遍代码之后,结合一部分代码来简单解析一下这篇论文。之前查论文并没有详细一些的资料,自己存在错误的地方也欢迎去交流改正。
摘要
- 点跟踪方法对于遮挡有很好的恢复作用,但是去存在一个问题:它们在实践中太慢,无法在合理的时间内跟踪单帧中观察到的每个点。 因此文章提出了DOT的方法
这个和核心步骤在摘要中就已经给出了就是下面的三个部分组成的。
-
它首先使用现成的点跟踪算法—Cotrakcer2从运动边界的关键区域中提取一小组轨迹。
-
给定源帧和目标帧,DOT 然后通过最近邻插值计算密集流场和可见性掩模的粗略初始估计。
-
可学习的光流估计器对其进行精炼
- 我们证明,DOT 比当前的光流技术更加准确,优于 OmniMotion 等复杂的通用点跟踪器,并且与 CoTracker 等最佳点跟踪算法相当或更好,同时速度至少快两个数量级。

引言与相关方法概括
-
首先先介绍了之前的细粒度的运动估计方法,主要依赖的是光流估计算法。缺乏对大运动或遮挡的鲁棒性,将它们对上下文的使用限制在少数相邻帧并限制了长期推理的能力。
-
点跟踪方法已成为一种有前途的替代方法。 在大多数情况下,它们能够通过视频的大部分来跟踪任何特定点,即使存在遮挡,也能在数千帧后成功保留超过 50% 的初始查询。
这些方法仍然太慢并且占用大量内存,无法跟踪视频中的每个单独点这种计算障碍限制了点跟踪作为下游任务中光流的可行替代品的广泛采用
DOT, connects the dots (hence its name) between optical flow and point tracking methods.
文章的主要贡献
-
引入了 DOT,这是一种新颖、简单且高效的方法,它统一了点跟踪和光流,使用一小组轨迹来预测视频中任意帧之间的密集流场和可见性掩模。重要
-
我们用 500 个新视频扩展了 CVO 基准,以增强对密集和长期跟踪的评估。 新视频比现有视频更长、帧速率更高,可实现更具挑战性的动作。
-
证明 DOT 显着优于最先进的光流方法,并且与最好的光流方法相当或更好点跟踪算法在密集预测时速度更快(×100 加速)
相关工作分类
相关的工作主要分为了下面的几个方面。
-
Optical flow estimation(光流估计):侧重于使其适应长距离运动(
由粗到细)DOT 建立在这些经典方法的基础上,还从稀疏对应中细化密集运动,但使用点跟踪而不是局部特征匹配 -
Optical flow across distant frames(
一些光流估计算法)
- Lucas-Kanade algorithm LK光流
- AccFlow
- FlowNet
- RAFT
- OmniMotion
- Point tracking(点跟踪算法):给定帧中的一个像素,它会预测视频的每个其他帧中相应点的位置和可见性。
- TAPNet iccv 2023
- PIPs
- CoTracker
核心方法
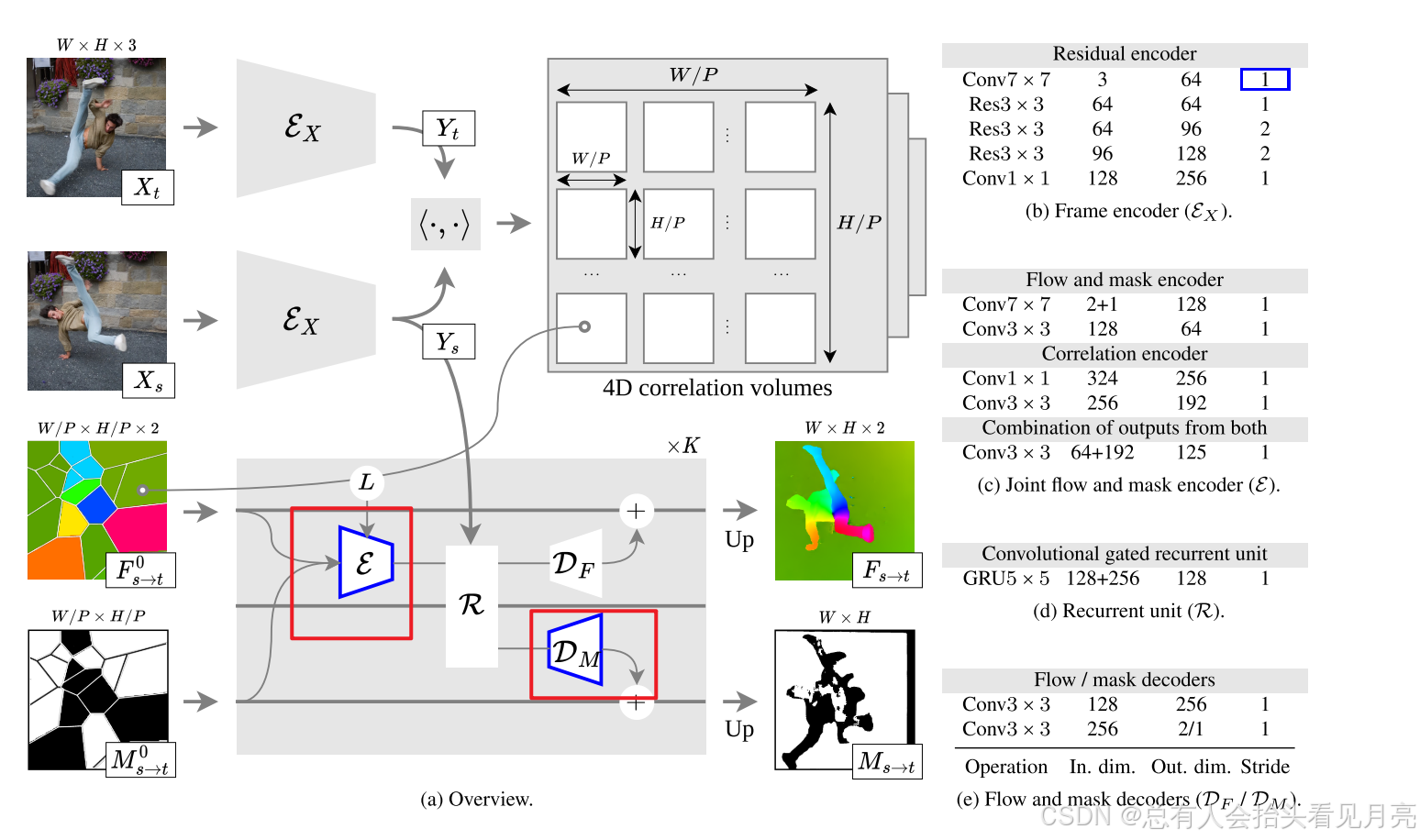
整体概括

-
我们的方法 DOT 以视频作为输入,并在任意一对源帧和目标帧 Xs / Xt 之间生成密集的运动信息,作为光流图 Fs→t 和可见性掩模 Ms→t。
-
从运动边界处的关键区域(以灰色显示)进行采样。 我们通过使用关联点在 s 处可见的所有轨迹来推导运动估计 F0 s→t / M0 s→t,记为 Vs
主要也就是分为了三个部分的信息。

输入的是全长的视频序列:
X t ( t in 1 … T ) in R W × H × 3 X_{t}(t\text { in } 1 \ldots T) \text { in } \mathbb{R}^{W \times H \times 3} Xt(t in 1…T) in RW×H×3
给出源帧和目标帧(s,t)我们的目标是预测源帧 Xs 中每个像素位置 (x, y) 的可见性 v(如果被遮挡则为 0,如果可见则为 1)
坐标系 Xt 中相应物理点的 2D 位置:
( x + Δ x , y + Δ y ) (x+\Delta x, y+\Delta y) (x+Δx,y+Δy)
我们将源和目标之间的这些密集对应关系表示为光流
F s → t in R W × H × 2 where F s → t ( x , y ) = ( Δ x , Δ y ) F_{s \rightarrow t} \text { in } \mathbb{R}^{W \times H \times 2} \text { where } F_{s \rightarrow t}(x, y)=(\Delta x, \Delta y) Fs→t in RW×H×2 where Fs→t(x,y)=(Δx,Δy)
M s → t in { 0 , 1 } W × H where M s → t ( x , y ) = v . M_{s \rightarrow t} \text { in }\{0,1\}^{W \times H} \text { where } M_{s \rightarrow t}(x, y)=v . Ms→t in {0,1}W×H where Ms→t(x,y)=v.
Point tracking(提取一小组轨迹)
我们首先使用现成的点跟踪方法在视频的所有帧上计算 N 个轨迹(这里的代码中的N=8192 分为4次完成每次2048)取得点相比较与全像素来说实际上在第一步减少了很大得计算量。
代码中我为了跑的快一点方便断点调试我改成了 480每次120
A point i in 1 . . .N tracked at time t in 1 . . .T is denoted by
p t i = ( x t i , y t i , v t i ) p_{t}^{i}=\left(x_{t}^{i}, y_{t}^{i}, v_{t}^{i}\right) pti=(xti,yti,vti)
P t = { p t i ∣ i ∈ [ 1 … N ] } P_{t}=\left\{p_{t}^{i} \mid i \in[1 \ldots N]\right\} Pt={pti∣i∈[1…N]}
Interpolation(插值粗轨迹初始化)
插值。 轨迹提供 s 和 t 之间的稀疏对应关系.我们使用最近邻插值推导出初始光流和掩码估计,F0 s→t 和 M0 s→t:
我们将源帧 Xs 中的每个像素与 s 处可见的像素中最近的轨迹 i 相关联,记为 Vs,并使用对应关系 (pi s, pi t) 的位置和可见性来分别初始化流和掩模。
也就是从源帧开始建立一个全长的轨迹序列。(粗略估计)
Optical flow(光流估计进行细化)
我们使用受 RAFT 启发的光流方法将这些估计细化为最终预测 Fs→t 和 Ms→t
我们通过将所有帧视为给定源的目标来获得密集轨迹,将 s 设置为 1 并在 {2 . 。 .T} 从第一帧获取所有轨迹。

整体方法
点跟踪细节
- 点跟踪。 并非所有轨迹都具有同等的信息量,并且点跟踪的计算量很大,因此我们在经历显着运动或可能被遮挡的区域中更密集地对轨迹进行采样。 这些通常位于移动物体的边缘周围

- 通过在视频的连续帧上运行预先训练的模型(Cotrack),然后应用 Sobel 滤波器来检测流中的不连续性

- 给定 N 个轨道,我们的采样策略包括在边缘附近(距边缘最多 5 个像素)随机初始化一半轨迹(1/4),并对整个图像中的剩余轨迹进行采样。 跑代码一次是执行25%的
Interpolation细节
目标:我们以降低的空间分辨率 W/P×H/P 初始化源和目标之间的粗略运动和可见性估计,F0 s→t 和 M0 s→t
最终通过最邻近插值生成的是:Voronoi cells
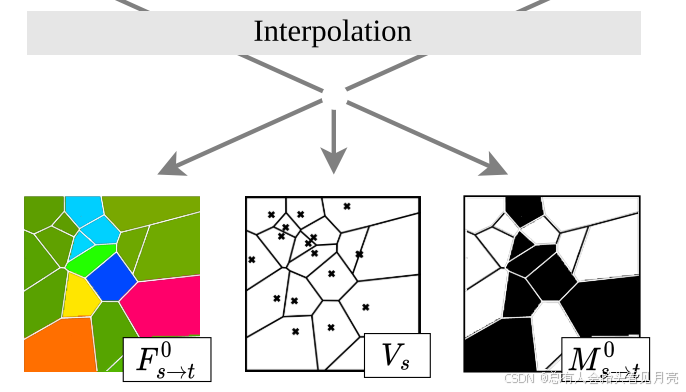
{ F s → t 0 ( x , y ) = ( x t i , y t i ) − ( x s i , y s i ) , M s → t 0 ( x , y ) = v t i , \left\{\begin{array}{l} F_{s \rightarrow t}^{0}(x, y)=\left(x_{t}^{i}, y_{t}^{i}\right)-\left(x_{s}^{i}, y_{s}^{i}\right), \\ M_{s \rightarrow t}^{0}(x, y)=v_{t}^{i}, \end{array}\right. {Fs→t0(x,y)=(xti,yti)−(xsi,ysi),Ms→t0(x,y)=vti,
i = arg min j ∈ V s ∥ ( x s j , y s j ) − ( x , y ) ∥ 2 i=\arg \min _{j \in V_{s}}\left\|\left(x_{s}^{j}, y_{s}^{j}\right)-(x, y)\right\|_{2} i=argj∈Vsmin (xsj,ysj)−(x,y) 2
{ j ∈ 1.. N ∣ v j s = 1 } \left\{j \in 1 . . N \mid v_{j}^{s}=1\right\} {j∈1..N∣vjs=1}
Optical flow细节
F0 s→t 和 M0 s→t 的估计本质上是不精确的,特别是对于远离输入轨道的点。 我们使用光流方法对其进行细化。
与 RAFT 一样,我们在 RW/P×H/P×C 中提取源(目标)帧 Xs(分别 Xt)的粗略特征 Ys(分别 Yt)
使用卷积神经网络。 然后,我们计算不同特征分辨率级别下所有源位置和目标位置对的特征之间的相关性,从而生成每个分辨率级别的 4D 相关量
通过重复 K 次以下过程(实际中 K=4),流程逐渐细化 然后将每个源点与其当前目标对应关系周围的局部邻域的相似性馈送到循环神经网络。
从而预测出来最终的轨迹信息。

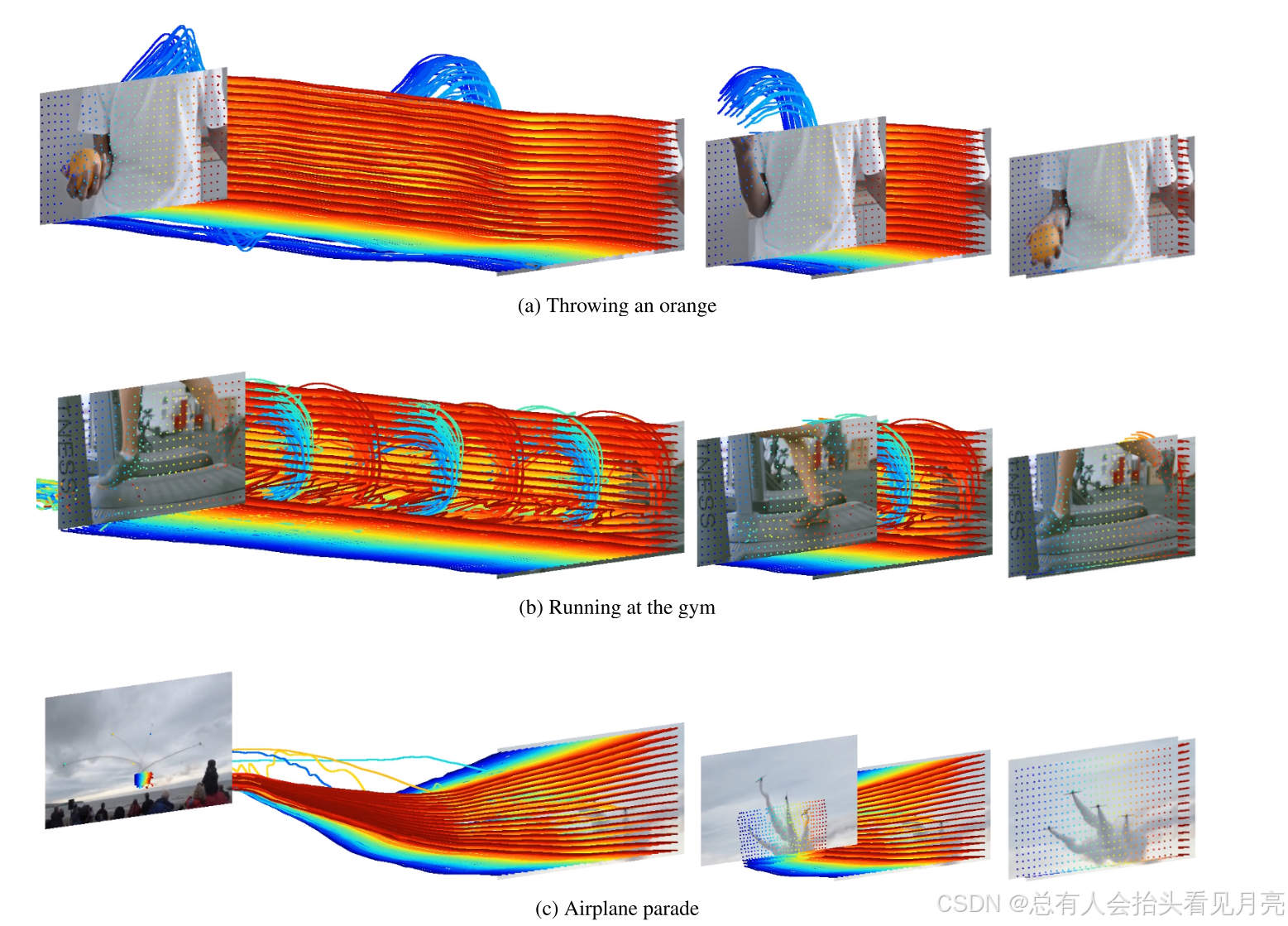
对于训练和实验的部分细节我们则进行省略。实验生成的视频效果如下所示
结构改进



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











