







图相似性计算网络
SimGNN: A Neural Network Approach to Fast Graph Similarity Computation:快速的图相似性计算网络
ABSTRACT
算法的作用:使用图神经网络解决图相似性计算的问题,看介绍上描述的是输入两个图,输入是两个图之间的相似性程度。
- 首先,设计了一个可学习的嵌入函数,将每个图映射到一个嵌入向量,从而提供图的全局总结。提出了一种新的节点注意机制,根据特定的相似性度量来强调重要节点。
可学习的嵌入函数 (Learnable embedding function):
- "可学习"指的是这个函数的参数是可以通过训练过程优化的。也就是说,嵌入函数本身不是一个固定的数学公式,而是一个可以根据数据和任务要求自动调整的模型。
- "嵌入函数"是指一个将图数据映射到一个低维向量空间的函数。在图匹配或图分类任务中,图嵌入通常用于将一个复杂的图结构压缩成一个具有重要信息的向量,这个向量包含了图的主要特征。
将每个图映射到嵌入向量 (maps every graph into an embedding vector):
- 每个图被转换成一个固定维度的向量,这个向量表示了图的全局特征。图的所有结构、节点特征和连接关系都会被嵌入到这个向量中。
- 这种映射是“全局”的,意味着它并不是仅仅关注图的某个局部特征,而是综合了整个图的特性,提供一个高层次的图表示。
全局总结 (global summary):
- 这个向量为图提供了一个“全局总结”,即它捕捉了图的整体特征或信息,而不是仅仅关注某个局部区域。这意味着该嵌入向量会包含关于图的所有节点、边以及它们之间关系的综合信息,从而能够代表整个图的结构。
- 我们设计了一种成对节点比较方法,以细粒度的节点级信息补充图级嵌入.
SimGNN为图相似度计算和图相似度搜索提供了一个新的研究方向。
INTRODUCTION And BackGround
不同的图相似性/距离度量,例如图编辑距离(GED)最大公共子图(MCS) 对于GED,即使是最先进的算法也不能在合理的时间内可靠地计算具有超过16个节点的图之间的精确GED
图编辑距离衡量的是将一个图转换为另一个图所需要的最小编辑操作的数量。
| 特征 | 图编辑距离 | 图的余弦相似度 |
|---|---|---|
| 衡量内容 | 图的拓扑结构和节点/边特征的差异 | 节点/边特征之间的相似度 |
| 计算方法 | 计算最小编辑操作数,考虑节点、边的添加、删除、修改 | 计算嵌入向量或特征向量的相似度 |
| 计算复杂度 | 较高(NP难度),尤其是大图时 | 较低,计算简单,尤其是通过向量表示时 |
| 对拓扑结构的考虑 | 考虑图的拓扑结构和编辑操作 | 主要关注节点特征,忽略拓扑结构 |
| 适用场景 | 图匹配、图同构、结构差异检测等 | 特征相似度计算、图分类、图聚类等任务 |
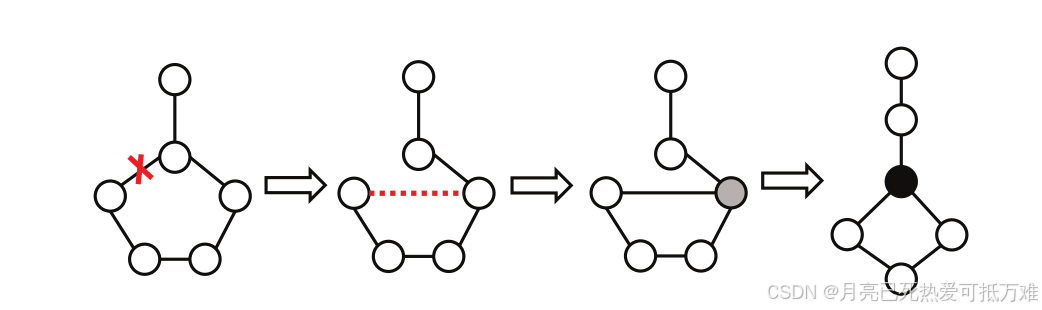
我们的解决方案不是直接使用组合搜索来计算近似相似度,而是将其转化为学习问题。
-
设计了一个基于神经网络的函数,将一对图映射到相似性得分。在训练阶段,将通过最小化预测的相似性得分和GT值之间的差异来学习该函数中涉及的参数,其中每个训练数据点是一对图及其真实相似性得分。
-
在测试阶段,通过向学习的函数馈送任意一对图,我们可以获得预测的相似性分数。我们将这种方法称为SimGNN,即:基于图神经网络的相似度计算。
有效性要求:
尽管 SimGNN 在效率上有优势,但要确保其在图匹配任务中的有效性,必须精心设计网络架构以满足以下三个关键性质:
Representation-invariant(表示不变性):
- 问题:图的表示可以通过不同的邻接矩阵来表示,具体来说,图的节点顺序可以被打乱(即节点重排),但图的结构和图的内在信息是相同的。因此,图的邻接矩阵和节点顺序的改变不应影响图的相似度计算。
- 要求:SimGNN 需要确保其计算的相似度分数对节点顺序的变化是不变的,也就是说,无论图的节点如何排列,得到的相似度结果应该是一样的。
Inductive(归纳性):
- 问题:训练过程中,模型通常只见过某些图的对,但在实际应用中,可能会遇到全新的图。这些新的图没有出现在训练数据中。
- 要求:SimGNN 需要具备归纳能力,即能够推广到训练集之外的图。它应该能够在没有见过的图对上计算相似度,而不仅仅是依赖于训练集中的图对。
Learnable(可学习性):
- 问题:不同的应用场景可能需要不同的相似度度量。例如,某些任务可能更加注重图的拓扑结构,而其他任务可能更关注节点特征的相似度。
- 要求:SimGNN 应该是可学习的,也就是说,模型应能通过训练来适应不同的相似度度量。它的参数可以在训练过程中自动调整,以适应不同任务的需求,确保能够计算出最合适的图相似度。
目前来看设计的这个架构所要满足的条件是能够支持100个跟踪器点图和100个检测框点图之间的相似性计算的问题的。
- 设计了一个可学习的嵌入函数,它将每个图映射到一个嵌入向量,通过聚合节点级嵌入来提供图的全局摘要。
- 提出了一种新的注意力机制,选择出一个特定的相似性度量的整个图的重要节点。(这个地方可能不太适用)
图级嵌入已经可以在很大程度上保持图之间的相似性:
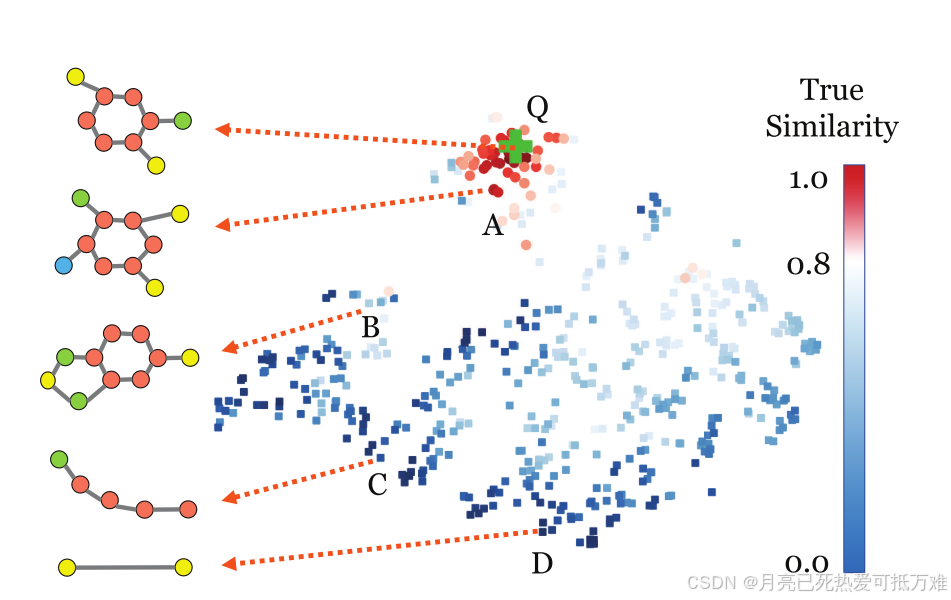
相似性保持图嵌入的说明。每个图都被映射到一个嵌入向量(在图中表示为一个点),该向量在特定的图相似性度量方面保持它们彼此之间的相似性。绿色“+”符号表示示例查询图的嵌入。点的颜色表示图形与基于基本事实的查询的相似程度(从红色到蓝色,意味着从最相似到最不相似)。
- 设计了一种成对节点比较方法,以补充图级嵌入的细粒度节点级信息。
由于每个图一个固定长度的嵌入可能太粗糙,我们进一步计算两个图中节点之间的成对相似性得分,从中提取直方图特征,并与图级信息相结合,以提高我们模型的性能。这导致在图形大小方面的操作的二次量,然而,这仍然是图相似性计算的最有效的方法之一。
THE PROPOSED APPROACH: SIMGNN
SimGNN,这是一种基于端到端神经网络的方法,它试图学习一个函数来将一对图映射到相似性得分。
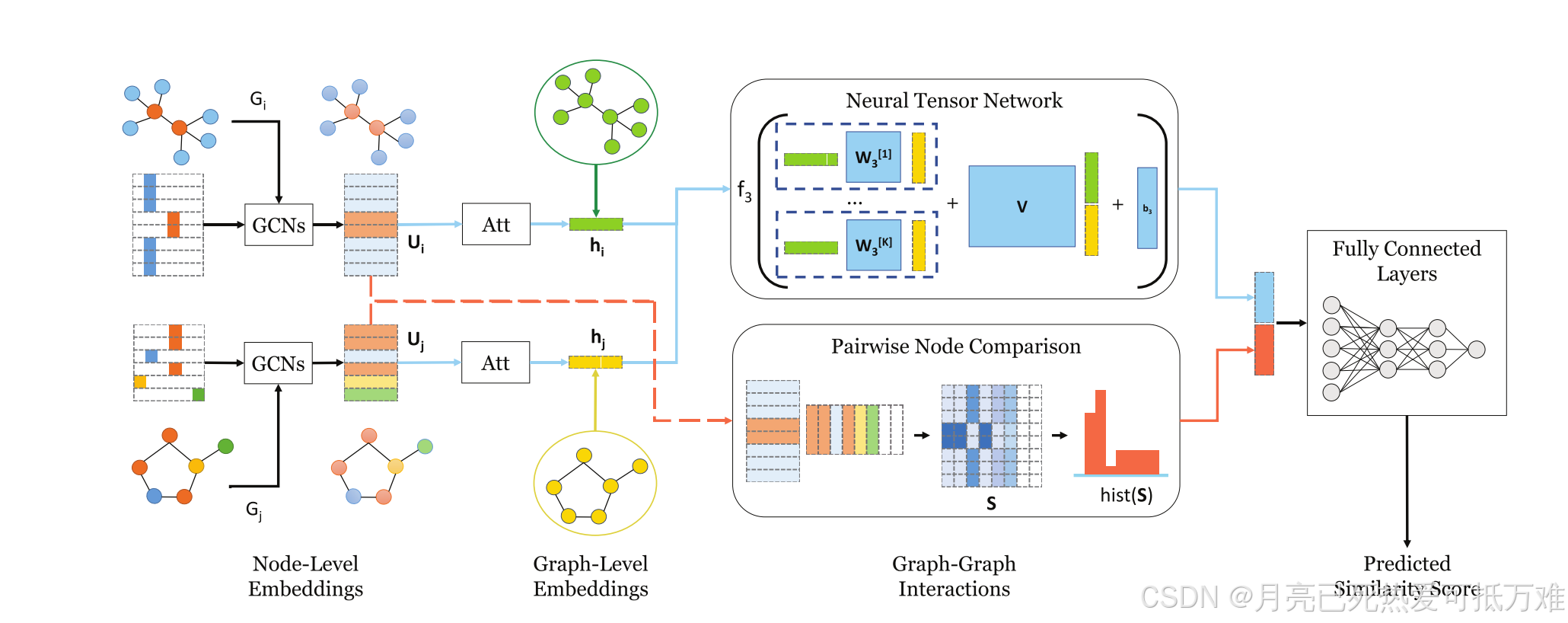
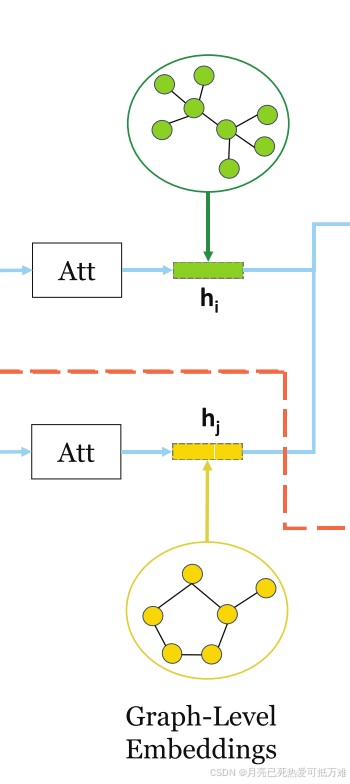
图SimGNN的概述。蓝色箭头表示策略1的数据流,该策略基于图级嵌入。红色箭头表示策略2的数据流,该策略基于成对节点比较。
我们的模型将每个图的节点转换为向量,编码每个节点周围的特征和结构属性。提出了两种相似度建模策略,分别对两个图的相似度进行建模。
- 一种是基于两个图级嵌入之间的交互。
- 另一种是基于比较两组节点级嵌入。
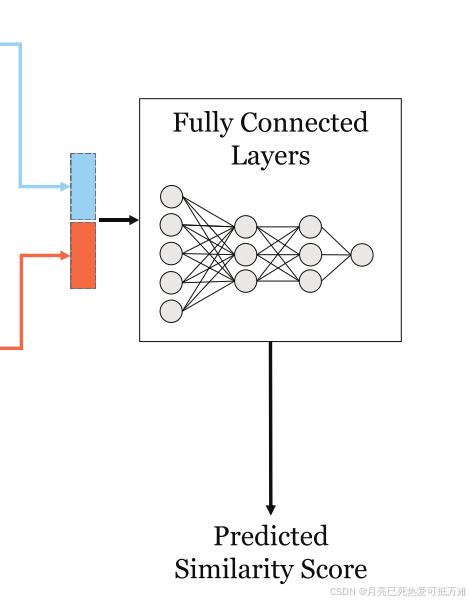
- 最后,将两种策略结合在一起,输入全连接神经网络,得到最终的相似度得分。
策略一:图级嵌入交互
该策略基于一个好的图级嵌入可以编码图的结构和特征信息的假设,通过两个图级嵌入的交互,可以预测两个图之间的相似性。
第一个分支所的具体流程。
- 节点嵌入阶段,将图的每个节点转换为向量,编码其特征和结构属性;
- 图嵌入阶段,通过对前一阶段中生成的节点嵌入进行基于注意力的聚合,为每个图生成一个嵌入
- 图-图交互阶段,其接收两个图级嵌入并返回表示图-图相似性的交互分数
- 最终图相似性得分计算阶段
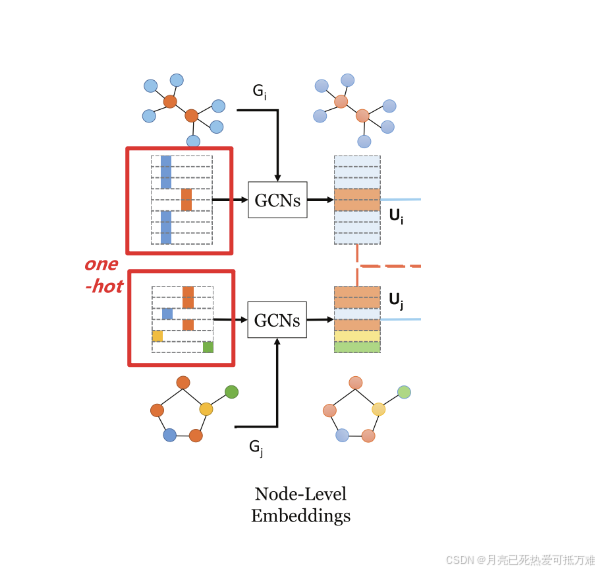
第一阶段:节点嵌入。在现有的最新方法中,我们采用GCN(并且原始节点表示是独热编码的,这个编码格式和自己的任务相比会比较合适吗?)
第二阶段:图形嵌入:全局上下文感知注意力。为了使用一组节点嵌入为每个图生成一个嵌入,可以执行节点嵌入的加权平均,或者与节点相关联的权重由其度确定的加权和。然而,哪些节点更重要并且应该获得更多权重取决于特定的相似性度量。因此,我们提出了以下注意力机制,让模型在特定相似性度量的指导下学习权重。
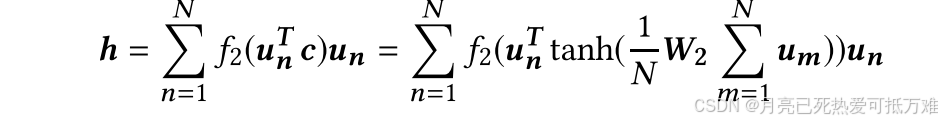
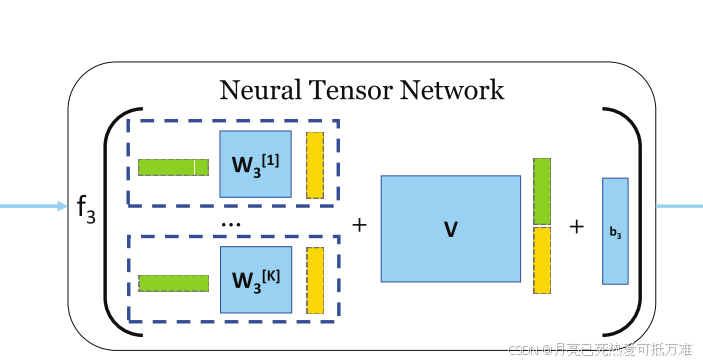
第三阶段:图-图交互:NeuralTensorNetwork给定前一阶段产生的两个图的图级嵌入,建模它们之间关系的一种简单方法是取两者的内积。我们使用神经张量网络(NTN)来建模两个图级嵌入之间的关系:
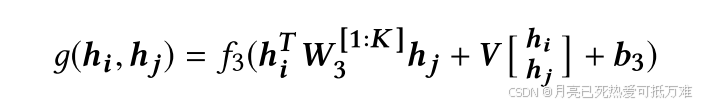
节点级信息(如节点特征分布和图大小)可能会因图级嵌入而丢失。在许多情况下,两个图之间的差异在于很小的子结构,很难通过图级嵌入来反映。一个类比是,在自然语言处理中,基于每个句子一个嵌入的句子匹配的性能可以通过使用细粒度的单词级信息来进一步增强。这就引出了我们的第二个策略。
策略二:成对节点比较
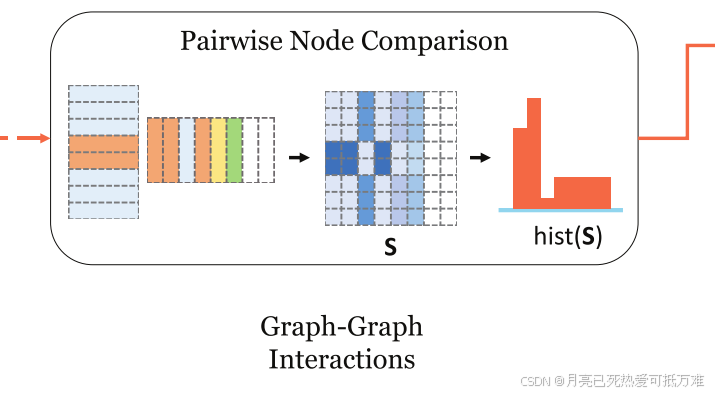
我们提取其直方图特征:hist(S)∈ RB,其中B是控制直方图中的箱数的超参数。直方图使用七个箱。直方图特征向量被归一化并与图级交互得分(hi,hj)连接,并被馈送到全连接层以获得图对的最终相似性得分。
单独的直方图特征不足以训练模型,因为直方图不是连续的微分函数,不支持反向传播。事实上,我们依赖策略1作为更新模型权重的主要策略,并使用策略2来补充图级特征,这为我们的模型带来了额外的性能增益。
将这个图相似度计算网络应用到自己的检测框图和跟踪框图的相似度计算中,结合自己之前工作中搭建好的框架结构和损失函数,应该是有一定的可取之处的。具体的判断还是要看。代码实现的具体细节和它适用的数据集结构能否迁移过去。


















 1887
1887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











