







Human-object interaction prediction in videos through gaze following
Abstract
The video-based HOI anticipation task in the third-person view is rarely researched. In this paper, a framework to detect current HOIs and anticipate future HOIs in videos is propose. Since people often fixate on an object before interacting with it, in this model gaze features together with the scene contexts and the visual appearances of human–object pairs are fused through a spatio-temporal transformer. Besides, a set of person-wise multi-label metrics are proposed to evaluate the model in the HOI anticipation task in a multi-person scenario.
Overview of the video-based HOI detection and anticipation framework.
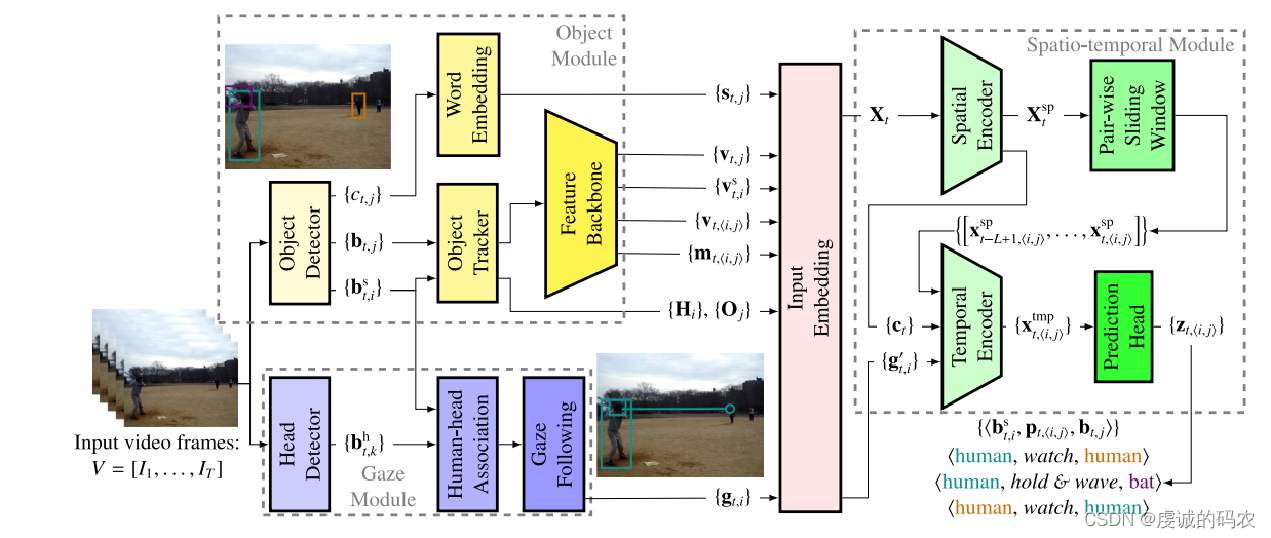
The framework consists of three modules:
- Object Module
- The object module detects bounding boxes of humans { b t , i s } \{b^s_{t,i}\} {bt,is} and objects { b t , j } \{b_{t,j}\} {bt,j}, and recognizes object classes { c t , j } \{c_{t,j}\} {ct,j}. An object tracker obtains human and object trajectories ( { H i } \{\textbf{H}_i\} {Hi} and { O j } \{\textbf{O}_j\} {Oj}in the video. Then, the human visual features { v t , i s } \{v^s_{t,i}\} {vt,is}, object visual features { v t , j } \{v_{t,j}\} {vt,j}, visual relation features { v t , < i , j > } \{v_{t,<i,j>}\} {vt,<i,j>}, and spatial relation features { m t , < i , j > } \{m_{t,<i,j>}\} {mt,<i,j>} are extracted through a feature backbone. In addition, a word embedding model is applied to generate semantic features { s t , j } \{s_{t,j}\} {st,j} of the object class.
- Gaze Module
- The gaze module detects heads { b t , k h } \{b^h_{t,k}\} {bt,kh} in RGB frames, assigns them to detected humans, and generates gaze feature maps for each human { g t , i } \{g_{t,i}\} {gt,i} using a gaze-following model.
- Spatial-temporal Module
- Next, all features in a frame are projected by an input embedding block.
- The human-object pair features are concatenated to a sequence of pair representations X t X_t Xt, which are refined to X t s p X_t^{sp} Xtspby a spatial encoder.
- The spatial encoder also extracts a global context feature c t c_t ct from each frame. Then, the global features { c t } \{c_t\} {ct} and projected human gaze features { g t , i ′ } \{g'_{t,i}\} {gt,i′}are concatenated to build the person-wise sliding windows of context features.
- Several instance-level sliding windows are constructed, each only containing refined pair representations of one unique human–object pair across time [ x t − L + 1 , < i , j > s p , … , X t , < i , j > s p ] \left[x^{sp}_{t−L+1,<i,j>},… , X_{t,<i,j>}^{sp}\right] [xt−L+1,<i,j>sp,…,Xt,<i,j>sp].
- A temporal encoder fuses context knowledge into the pair representations by the cross-attention mechanism.
- Finally, the prediction heads estimate the probability distribution z t , ⟨ i , j ⟩ z_{t,⟨i,j⟩} zt,⟨i,j⟩ of interactions for each human–object pair based on the last occurrence x t , ⟨ i , j ⟩ t m p x^{tmp}_{t,⟨i,j⟩} xt,⟨i,j⟩tmpin the temporal encoder output.
Object module
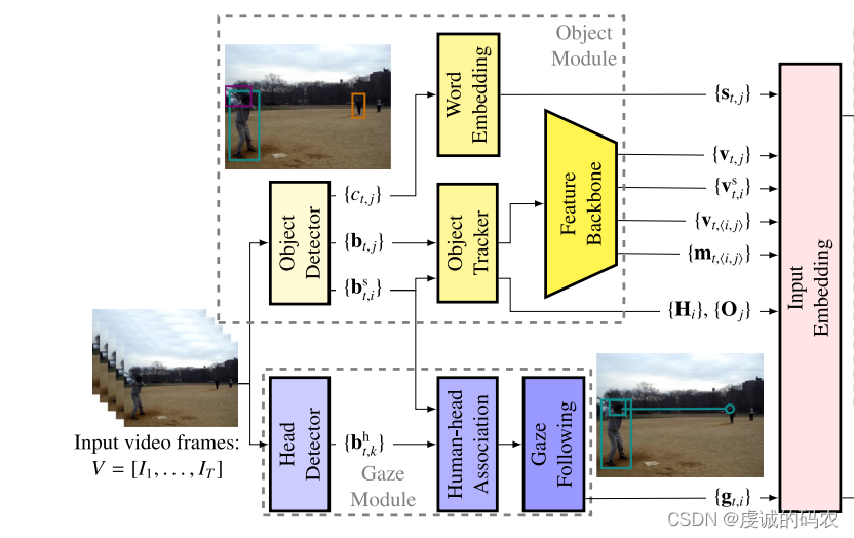
- The object module takes a sequence of RGB video frames as input and detects bounding boxes and classes for objects in each frame, including bounding boxes for humans.
- An object tracker associates current detections with past ones to obtain trajectories for human and object bounding boxes. This allows analyzing each unique human-object pair.
- Visual features are extracted for each box using a ResNet. Additional features are extracted for human-object pairs like visual relation features and spatial relation masks.
- Object semantic features are generated from object categories using word embeddings, to reflect different likely interactions depending on object type.
Gaze module
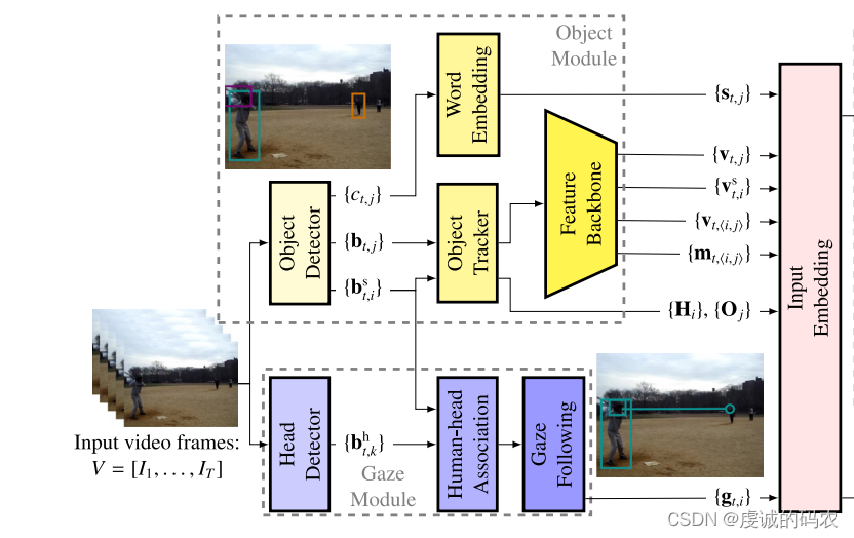
- The gaze-following method from Chong et al. (2020) is adopted to generate a gaze heatmap for each human.
- A head detector is needed to identify human heads in the scene. Directly getting the head box from the human box can cause mismatches in some cases.
- The gaze module first detects all heads in the full RGB frame. These are matched to human boxes using linear assignment.
- An intersection over head (IoH) ratio is computed between each human box and head box. If the IoH ratio exceeds a threshold of 0.7, the head is shortlisted as a match for that human.
- Finally, the gaze-following model combines the head information and the scene feature map using an attention mechanism, and encode the fused features and extract temporal dependencies to estimate the gaze heatmap using a convolutional Long Short-Term Memory (Conv-LSTM) network.
Spatial and temporal encoders
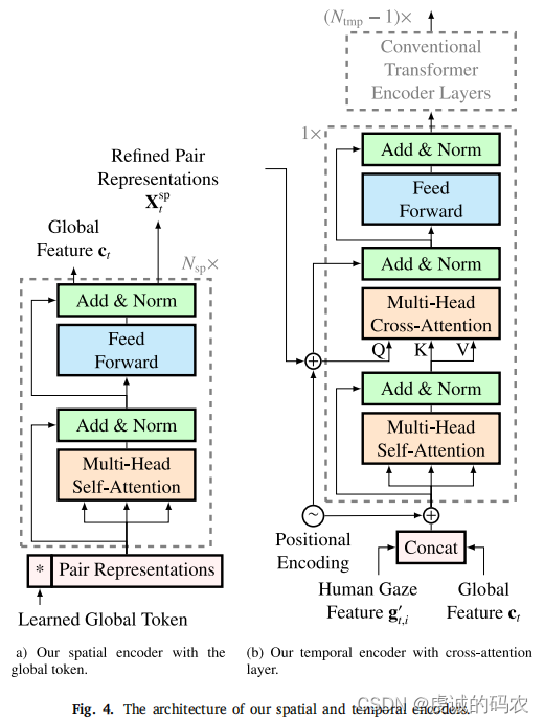
- A spatial encoder exploits human-object relation representations from one frame to understand dependencies between appearances, spatial relations, and semantics. It extracts a global feature vector for each frame to represent contexts between all human-object pairs.
- The spatial encoder takes human-object pair relations as input. After stacked self-attention layers, a learnable global token is prepended to summarize dependencies between pairs into a global feature vector, while the pair relation representations are refined.
- The refined pair representations are concatenated into sequences for the temporal encoder. Unlike STTran which jointly processes all pairs, sequences are formulated so each only contains one human-object pair.
- The human’s gaze feature is concatenated with the global frame feature into a person-wise context feature sequence. This is fed to the temporal encoder along with the pair sequences.
- Positional encodings are added to entries in both context and pair sequences since the temporal encoder loses order. Sinusoidal encoding performs better than learned.
- The temporal encoder fuses contexts and pairs via cross-attention to capture temporal evolution of dependencies to detect interactions over time.
- Prediction heads generate probability distributions for interaction categories. Outputs are concatenated into the final model output.
Experiments
Datasets
VidHOI dataset
Currently the largest video dataset with complete HOI annotations. The VidHOI dataset applies keyframe-based annotations, where the keyframes are sampled in 1 frame per second (FPS). There are 78 object categories and 50 predicate classes.
Loss function
VidHOI dataset is an unbalanced dataset with long-tailed interaction distribution. To address the imbalance issue and avoid over-emphasizing the importance of the most frequent classes in the dataset, the class-balanced (CB) Focal loss (Cui et al.,2019) is adopted as follows:
C
B
f
o
c
a
l
(
p
i
,
y
i
)
=
−
1
−
β
1
−
β
n
i
(
1
−
p
i
i
)
γ
log
p
y
i
CB_{focal}(p_i,y_i)=-\frac{1-\beta}{1-\beta^{n_i}}(1-p_{i_i})^\gamma\log{p_{y_i}}
CBfocal(pi,yi)=−1−βni1−β(1−pii)γlogpyi
with
p
y
i
=
{
p
i
if
y
i
=
1
1
−
p
i
otherwise
p_{y_{i}}=\left\{\begin{array}{ll} p_{i} & \text { if } y_{i}=1 \\ 1-p_{i} & \text { otherwise } \end{array}\right.
pyi={pi1−pi if yi=1 otherwise
The term
−
(
1
−
p
i
i
)
γ
log
p
y
i
-(1-p_{i_i})^\gamma\log{p_{y_i}}
−(1−pii)γlogpyirefers to the Focal loss proposed in Lin et al. (2017), where
p
i
p_i
pi denotes the estimated probability for the 𝑖th class and
y
i
∈
{
0
,
1
}
y_i \in \left\{0, 1\right\}
yi∈{0,1} is the ground-truth label. The variable
n
i
n_i
ni denotes the number of samples in the ground truth of the 𝑖th class and
β
∈
[
0
,
1
)
\beta \in [0, 1)
β∈[0,1) is a tunable parameter. The mean of losses in all classes is considered as the loss for one prediction.
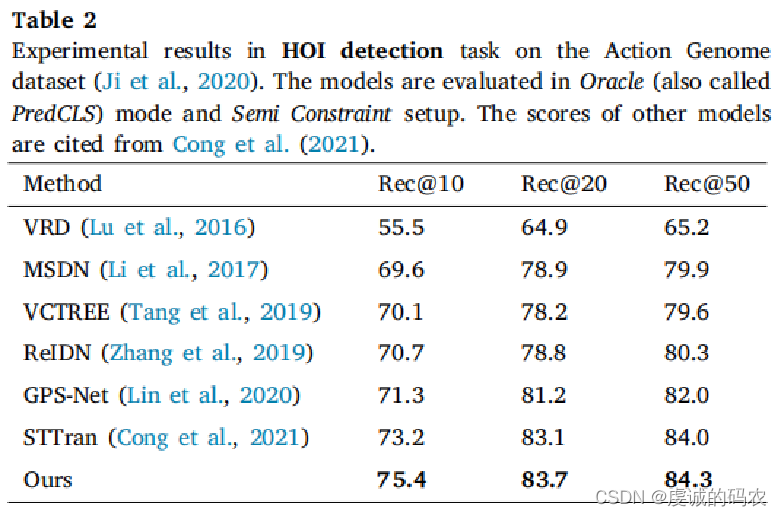
Action genome dataset
Another large-scale video dataset containing 35 object categories and 25 interaction classes. Nevertheless, only HOIs for a single person are annotated in each video even if more people show up. Moreover, the videos are generated by volunteers performing pre-defined tasks. Thus, models designed on the Action Genome dataset may be less useful in the real world.
Evaluation metrics
A predicted HOI triplet is assigned true positive if: (1) both detected human and object bounding boxes are overlapped with the ground truth with intersection over union (IoU) > 0.5, (2) the predicted
object class is correct, and (3) the predicted interaction is correct.
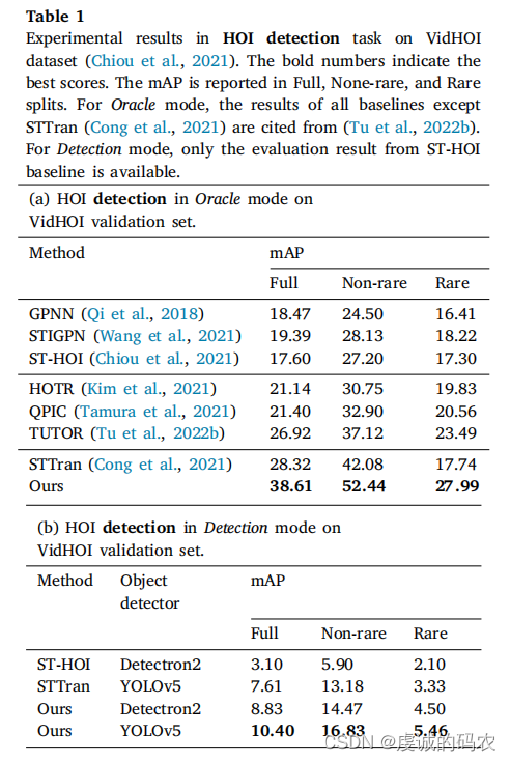
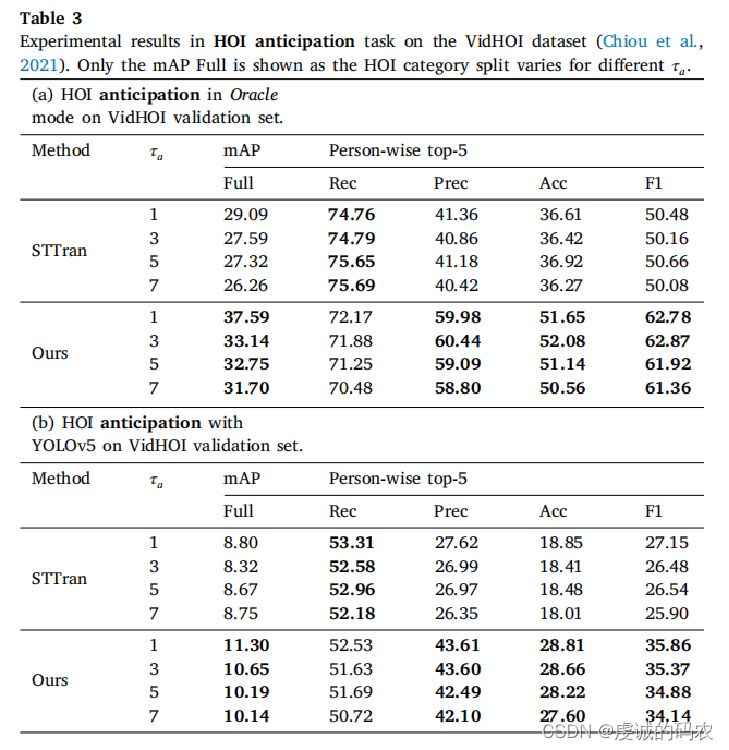
The metric mAP is reported on the VidHOI dataset over three different HOI category sets: (1) Full: all 557 HOI triplet categories, (2) Rare: 315 categories with < 25 instances in the validation set, and (3) Non-rare: 242 categories with ≥ 25 instances in the validation set.
A set of person-wise multi-label top-𝑘 metrics as additional evaluation metrics is proposed. For each frame, first assign the detected human–object pairs to the ground-truth pairs. Then, the top-𝑘 triplets of each human are used to compute the metrics for this human. The final results are averaged over all humans in the dataset, without frame-wise or video-wise mean computation.
All models are trained with ground-truth object trajectories. Models in Oracle mode are evaluated with ground-truth object bounding boxes, while models in Detection mode are evaluated with object detector.
Implementation details
-
object module, we employ YOLOv5 model (Jocher et al.,2022) as the object detector. The weights are pre-trained on COCO dataset (Lin et al., 2014) and finetuned for the VidHOI dataset.
-
apply the pre-trained DeepSORT model (Wojke et al., 2017) as the human tracker, ResNet-101 (He et al., 2016) as feature backbone, and GloVe model (Pennington et al., 2014) for word embedding.
-
In the gaze module, also apply YOLOv5 to detect heads from RGB frames. The model is pre-trained on the Crowdhuman dataset (Shao et al., 2018). The gaze-following method introduced in Chong et al. (2020) and pre-trained on the VideoAttentionTarget dataset (Chong et al., 2020) is adopted to generate gaze features. All weights in the object module and gaze module are frozen during the training of the spatio-temporal transformer.
Result















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









