







参考原文:https://shenxiaohai.me/2018/10/20/pytorch-tutorial-advanced-02/
本文附带jupyter notebook文件已上传到我的CSDN资源中
1. 导入模型训练相关包
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torchvision import transforms
from torchvision.utils import save_image
2. 配置设备
# # 设备配置
# torch.cuda.set_device(0) # 这句用来设置pytorch在哪块GPU上运行
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 如果没有文件夹就创建一个文件夹
sample_dir = 'samples'
if not os.path.exists(sample_dir):
os.makedirs(sample_dir)
3. 设置超参数、加载dataloader
# 超参数设置
# Hyper-parameters
image_size = 784
h_dim = 400
z_dim = 20
num_epochs = 15
batch_size = 128
learning_rate = 1e-3
dataset = torchvision.datasets.MNIST(root='../../../data/minist',
train=True,
transform=transforms.ToTensor(),
download=True)
# 数据加载器
data_loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=True)
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to ../../../data/minist\MNIST\raw\train-images-idx3-ubyte.gz
0it [00:00, ?it/s]
Extracting ../../../data/minist\MNIST\raw\train-images-idx3-ubyte.gz to ../../../data/minist\MNIST\raw
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to ../../../data/minist\MNIST\raw\train-labels-idx1-ubyte.gz
0it [00:00, ?it/s]
Extracting ../../../data/minist\MNIST\raw\train-labels-idx1-ubyte.gz to ../../../data/minist\MNIST\raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to ../../../data/minist\MNIST\raw\t10k-images-idx3-ubyte.gz
0it [00:00, ?it/s]
Extracting ../../../data/minist\MNIST\raw\t10k-images-idx3-ubyte.gz to ../../../data/minist\MNIST\raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to ../../../data/minist\MNIST\raw\t10k-labels-idx1-ubyte.gz
0it [00:00, ?it/s]
Extracting ../../../data/minist\MNIST\raw\t10k-labels-idx1-ubyte.gz to ../../../data/minist\MNIST\raw
Processing...
Done!
c:\users\user\appdata\local\programs\python\python37\lib\site-packages\torchvision\datasets\mnist.py:480: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at ..\torch\csrc\utils\tensor_numpy.cpp:141.)
return torch.from_numpy(parsed.astype(m[2], copy=False)).view(*s)
查看dataloader中的内容
#导入包
import matplotlib.pyplot as plt # plt 用于显示图片
import matplotlib.image as mpimg # mpimg 用于读取图片
import numpy as np
x = iter(data_loader).next()[0]
x.shape
torch.Size([128, 1, 28, 28])
可以看到dataloader的一次迭代可以加载出128×1×28×28的图片
128: batch大小
1: 通道数(灰度图都是一个通道)
28×28: 单个通道的图像数据
plt.imshow(x[0][0])
<matplotlib.image.AxesImage at 0x2ed7fdb86c8>
上图为一张图片所显示的内容
4. 设置模型
# VAE model
class VAE(nn.Module):
def __init__(self, image_size=784, h_dim=400, z_dim=20):
super(VAE, self).__init__()
self.fc1 = nn.Linear(image_size, h_dim)
self.fc2 = nn.Linear(h_dim, z_dim) # 均值 向量
self.fc3 = nn.Linear(h_dim, z_dim) # 保准方差 向量
self.fc4 = nn.Linear(z_dim, h_dim)
self.fc5 = nn.Linear(h_dim, image_size)
# 编码过程
def encode(self, x):
print("1:"+str(x.shape))
h = F.relu(self.fc1(x))
print("2:"+str(h.shape))
return self.fc2(h), self.fc3(h)
# 随机生成隐含向量
def reparameterize(self, mu, log_var):
std = torch.exp(log_var/2)
eps = torch.randn_like(std)
return mu + eps * std
# 解码过程
def decode(self, z):
h = F.relu(self.fc4(z))
return F.sigmoid(self.fc5(h))
# 整个前向传播过程:编码-》解码
def forward(self, x):
mu, log_var = self.encode(x)
print("3:"+str(mu.shape))
print("4:"+str(log_var.shape))
z = self.reparameterize(mu, log_var)
print("5:"+str(z.shape))
x_reconst = self.decode(z)
print("6:"+str(x_reconst.shape))
return x_reconst, mu, log_var
上述网络结构图形化如下
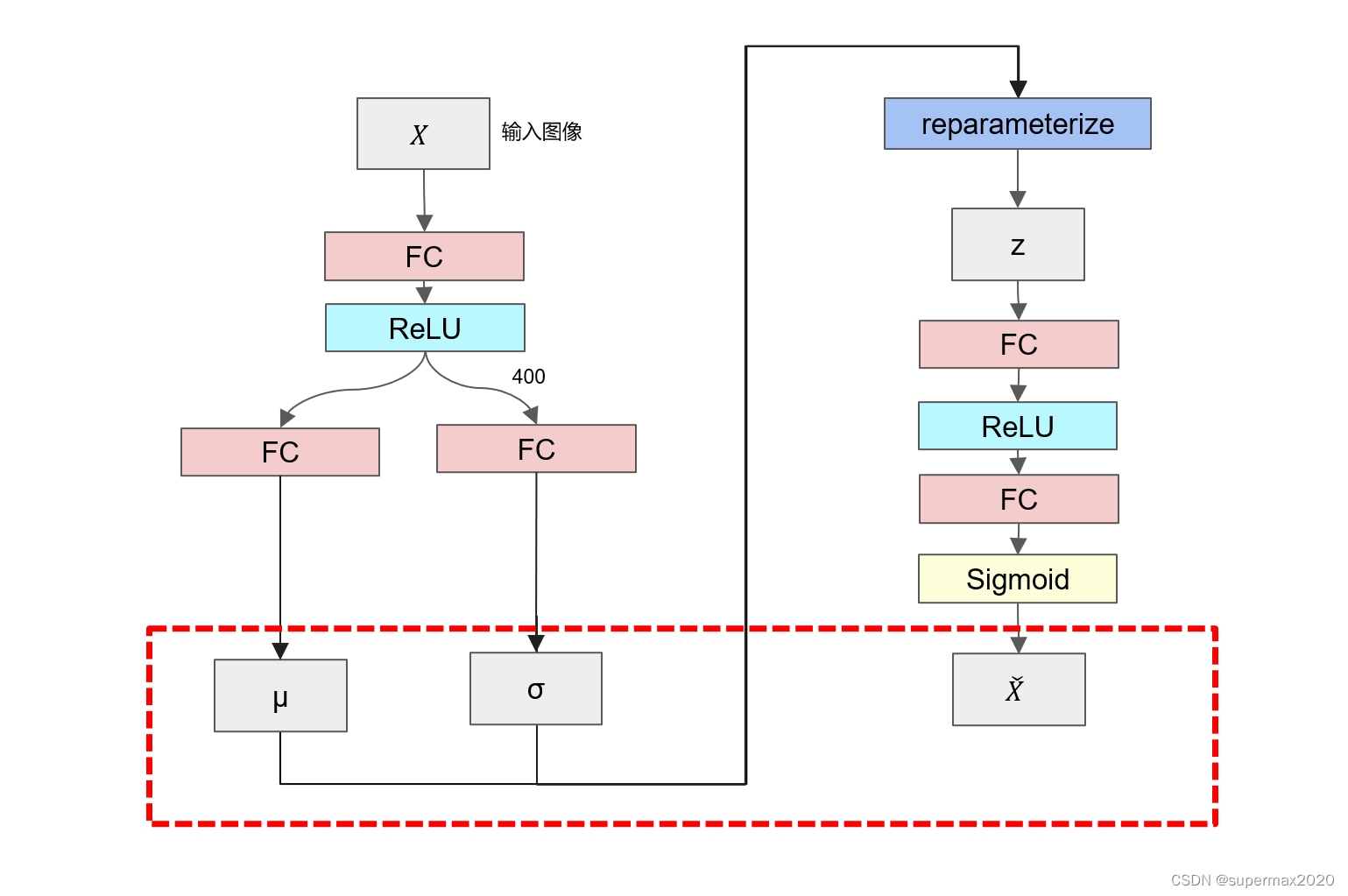
其中红色虚线框中的内容是损失函数的组成部分
5. 开始训练
# 实例化一个模型
model = VAE().to(device)
# 创建优化器
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
for epoch in range(num_epochs):
for i, (x, _) in enumerate(data_loader):
# 获取样本,并前向传播
x = x.to(device).view(-1, image_size)
x_reconst, mu, log_var = model(x)
# 计算重构损失和KL散度(KL散度用于衡量两种分布的相似程度)
# KL散度的计算可以参考论文或者文章开头的链接
reconst_loss = F.binary_cross_entropy(x_reconst, x, size_average=False)
kl_div = - 0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
# 反向传播和优化
loss = reconst_loss + kl_div
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print ("Epoch[{}/{}], Step [{}/{}], Reconst Loss: {:.4f}, KL Div: {:.4f}"
.format(epoch+1, num_epochs, i+1, len(data_loader), reconst_loss.item(), kl_div.item()))
# 利用训练的模型进行测试
with torch.no_grad():
# 随机生成的图像
z = torch.randn(batch_size, z_dim).to(device)
out = model.decode(z).view(-1, 1, 28, 28)
save_image(out, os.path.join(sample_dir, 'sampled-{}.png'.format(epoch+1)))
# 重构的图像
out, _, _ = model(x)
x_concat = torch.cat([x.view(-1, 1, 28, 28), out.view(-1, 1, 28, 28)], dim=3)
save_image(x_concat, os.path.join(sample_dir, 'reconst-{}.png'.format(epoch+1)))
/usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:1960: UserWarning: nn.functional.sigmoid is deprecated. Use torch.sigmoid instead.
warnings.warn("nn.functional.sigmoid is deprecated. Use torch.sigmoid instead.")
/usr/local/lib/python3.7/dist-packages/torch/nn/_reduction.py:42: UserWarning: size_average and reduce args will be deprecated, please use reduction='sum' instead.
warnings.warn(warning.format(ret))
Epoch[1/15], Step [100/469], Reconst Loss: 22325.9961, KL Div: 1292.9675
Epoch[1/15], Step [200/469], Reconst Loss: 16562.2441, KL Div: 2101.5405
Epoch[1/15], Step [300/469], Reconst Loss: 15128.4561, KL Div: 2418.6357
Epoch[1/15], Step [400/469], Reconst Loss: 14666.9990, KL Div: 2442.3835
Epoch[2/15], Step [100/469], Reconst Loss: 13904.7002, KL Div: 2920.0483
Epoch[2/15], Step [200/469], Reconst Loss: 12945.5293, KL Div: 2899.4502
Epoch[2/15], Step [300/469], Reconst Loss: 12416.3398, KL Div: 2859.1750
Epoch[2/15], Step [400/469], Reconst Loss: 11977.3125, KL Div: 2835.1426
Epoch[3/15], Step [100/469], Reconst Loss: 12504.1533, KL Div: 3067.2375
Epoch[3/15], Step [200/469], Reconst Loss: 11617.1113, KL Div: 3061.0508
Epoch[3/15], Step [300/469], Reconst Loss: 11711.5244, KL Div: 3130.3713
Epoch[3/15], Step [400/469], Reconst Loss: 11942.1924, KL Div: 3115.7471
Epoch[4/15], Step [100/469], Reconst Loss: 11302.0635, KL Div: 3117.6763
Epoch[4/15], Step [200/469], Reconst Loss: 11396.1738, KL Div: 3202.3250
Epoch[4/15], Step [300/469], Reconst Loss: 11127.0645, KL Div: 3171.7722
Epoch[4/15], Step [400/469], Reconst Loss: 10985.8320, KL Div: 3098.4009
Epoch[5/15], Step [100/469], Reconst Loss: 11460.6963, KL Div: 3230.8091
Epoch[5/15], Step [200/469], Reconst Loss: 10541.7783, KL Div: 3221.3369
Epoch[5/15], Step [300/469], Reconst Loss: 10609.5420, KL Div: 3134.0396
Epoch[5/15], Step [400/469], Reconst Loss: 10746.1963, KL Div: 3186.7300
Epoch[6/15], Step [100/469], Reconst Loss: 10613.0098, KL Div: 3161.1631
Epoch[6/15], Step [200/469], Reconst Loss: 10862.5127, KL Div: 3171.8523
Epoch[6/15], Step [300/469], Reconst Loss: 11125.9102, KL Div: 3209.8787
Epoch[6/15], Step [400/469], Reconst Loss: 10361.1904, KL Div: 3179.6394
Epoch[7/15], Step [100/469], Reconst Loss: 10869.8262, KL Div: 3277.3511
Epoch[7/15], Step [200/469], Reconst Loss: 10583.9775, KL Div: 3272.1274
Epoch[7/15], Step [300/469], Reconst Loss: 9966.8125, KL Div: 3117.8450
Epoch[7/15], Step [400/469], Reconst Loss: 10690.5742, KL Div: 3339.8892
Epoch[8/15], Step [100/469], Reconst Loss: 10644.7383, KL Div: 3299.1499
Epoch[8/15], Step [200/469], Reconst Loss: 10652.6270, KL Div: 3297.8372
Epoch[8/15], Step [300/469], Reconst Loss: 10541.0684, KL Div: 3166.6426
Epoch[8/15], Step [400/469], Reconst Loss: 10794.7314, KL Div: 3329.0159
Epoch[9/15], Step [100/469], Reconst Loss: 10347.5000, KL Div: 3291.0581
Epoch[9/15], Step [200/469], Reconst Loss: 10460.7686, KL Div: 3147.4270
Epoch[9/15], Step [300/469], Reconst Loss: 10217.2275, KL Div: 3206.6414
Epoch[9/15], Step [400/469], Reconst Loss: 10608.9072, KL Div: 3285.1226
Epoch[10/15], Step [100/469], Reconst Loss: 10454.6016, KL Div: 3290.0586
Epoch[10/15], Step [200/469], Reconst Loss: 10632.7822, KL Div: 3259.0110
Epoch[10/15], Step [300/469], Reconst Loss: 10514.3359, KL Div: 3185.3164
Epoch[10/15], Step [400/469], Reconst Loss: 10258.9453, KL Div: 3200.7063
Epoch[11/15], Step [100/469], Reconst Loss: 10047.3574, KL Div: 3214.2043
Epoch[11/15], Step [200/469], Reconst Loss: 9705.0078, KL Div: 3210.4810
Epoch[11/15], Step [300/469], Reconst Loss: 10236.5371, KL Div: 3314.7139
Epoch[11/15], Step [400/469], Reconst Loss: 10746.6348, KL Div: 3258.6812
Epoch[12/15], Step [100/469], Reconst Loss: 9837.2031, KL Div: 3136.6541
Epoch[12/15], Step [200/469], Reconst Loss: 10117.1963, KL Div: 3282.7031
Epoch[12/15], Step [300/469], Reconst Loss: 9952.3184, KL Div: 3148.8638
Epoch[12/15], Step [400/469], Reconst Loss: 10463.5410, KL Div: 3257.8792
Epoch[13/15], Step [100/469], Reconst Loss: 10687.4766, KL Div: 3315.0667
Epoch[13/15], Step [200/469], Reconst Loss: 10573.5977, KL Div: 3253.9087
Epoch[13/15], Step [300/469], Reconst Loss: 10285.8145, KL Div: 3226.7212
Epoch[13/15], Step [400/469], Reconst Loss: 9812.1465, KL Div: 3238.2170
Epoch[14/15], Step [100/469], Reconst Loss: 10094.8643, KL Div: 3275.3123
Epoch[14/15], Step [200/469], Reconst Loss: 10149.8086, KL Div: 3302.6235
Epoch[14/15], Step [300/469], Reconst Loss: 10553.0664, KL Div: 3305.8149
Epoch[14/15], Step [400/469], Reconst Loss: 10361.6904, KL Div: 3249.9197
Epoch[15/15], Step [100/469], Reconst Loss: 10149.0605, KL Div: 3283.0081
Epoch[15/15], Step [200/469], Reconst Loss: 10201.4980, KL Div: 3220.1846
Epoch[15/15], Step [300/469], Reconst Loss: 10114.3887, KL Div: 3159.8972
Epoch[15/15], Step [400/469], Reconst Loss: 10541.4033, KL Div: 3248.5728
reconsPath = './samples/reconst-15.png'
Image = mpimg.imread(reconsPath)
plt.imshow(Image) # 显示图片
plt.axis('off') # 不显示坐标轴
plt.show()

genPath = './samples/sampled-15.png'
Image = mpimg.imread(genPath)
plt.imshow(Image) # 显示图片
plt.axis('off') # 不显示坐标轴
plt.show()
















 2031
2031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









