






原文链接:https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73
本文是原文的概要翻译,很多地方力求简略,如需理解细节可参考原文
一、引言
生成性神经网络发展迅速,其中VAE和GAN是其中最重要的两个类别。在之前的文章中我们介绍过GAN,本文介绍一下VAE。
简要来说,变分自编码器是一类特殊的编码器:他的编码做出了特殊处理,以使得编码的隐空间具有某些良好属性,以使得其可以用于图像生成。
注意,本文中的数学推导力求完整,但是如果不想深究细节的读者可以跳过本文的最后一节,不会影响对主要概念的理解。
二、数据降维:PCA和AE
PCA和AE是两类用于数据降维的工具。下面我们简要介绍一下他们是怎么运作的、以及数据将为的一些基本概念。
什么是数据降维?
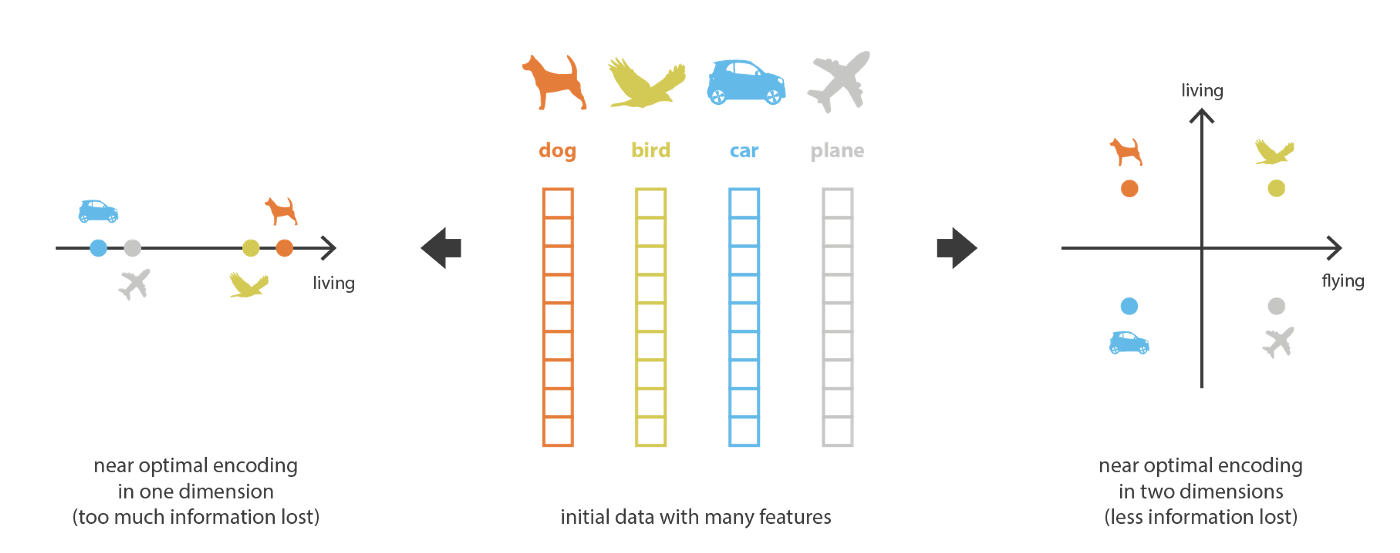
在机器学习中,数据降维指的是降低描述数据的特征的过程。降维的方法可以是筛选(仅保留某些特征),也可以是聚合(从旧特征中生成某些新特征)。尽管数据降维的方法千变万化,但是我们可以从中 总结出一个普适性的框架来描述大部分数据降维过程。
首先,我们将把从"旧特征"中生成"新特征"的过程称为编码器,而逆过程称为解码器。然后数据降维可以这样理解:编码器压缩原始数据,解码器将其恢复。“新特征”所存在的空间我们也称为隐空间
显然,在编码和解码的过程中,不可避免的会有信息损失,解码器也很有可能没办法将隐空间的特征恢复成原始的样子。这种就是有损编码(lossy encoding)
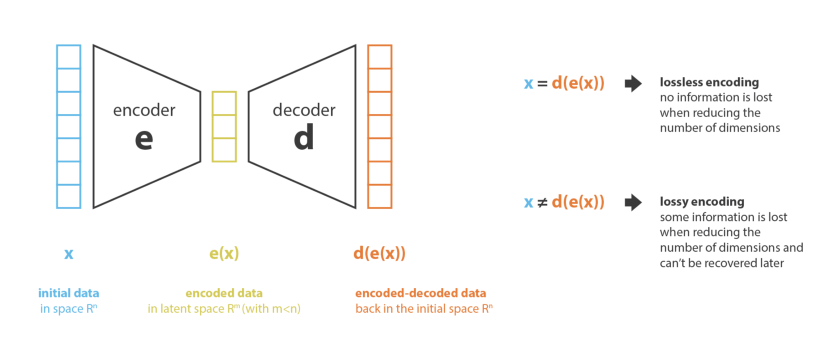
对于数据降维任务来说,我们的目的是:编码器尽可能地多保留原始信息,解码器尽可能地少产生解码错误。我们用E和D表示编码器和解码器,那么这个目标可以写成:
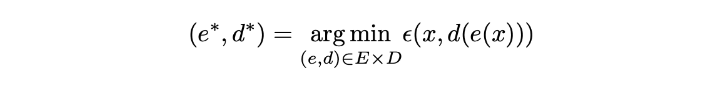
其中
ϵ
(
x
,
d
(
e
(
x
)
)
)
\epsilon(x,d(e(x)))
ϵ(x,d(e(x)))表示原始值x和解码结果d(e(x))之间的误差。
PCA 主成分分析
谈到数据降维首先想到的就是PCA。我们大体过一下PCA的思路,不细究其细节。
假设原始数据是 n d n_d nd维,我们希望将这些原始数据线性组合得到 n e n_e ne维新的独立特征。这些新特征可以很好的表示原始数据的信息。
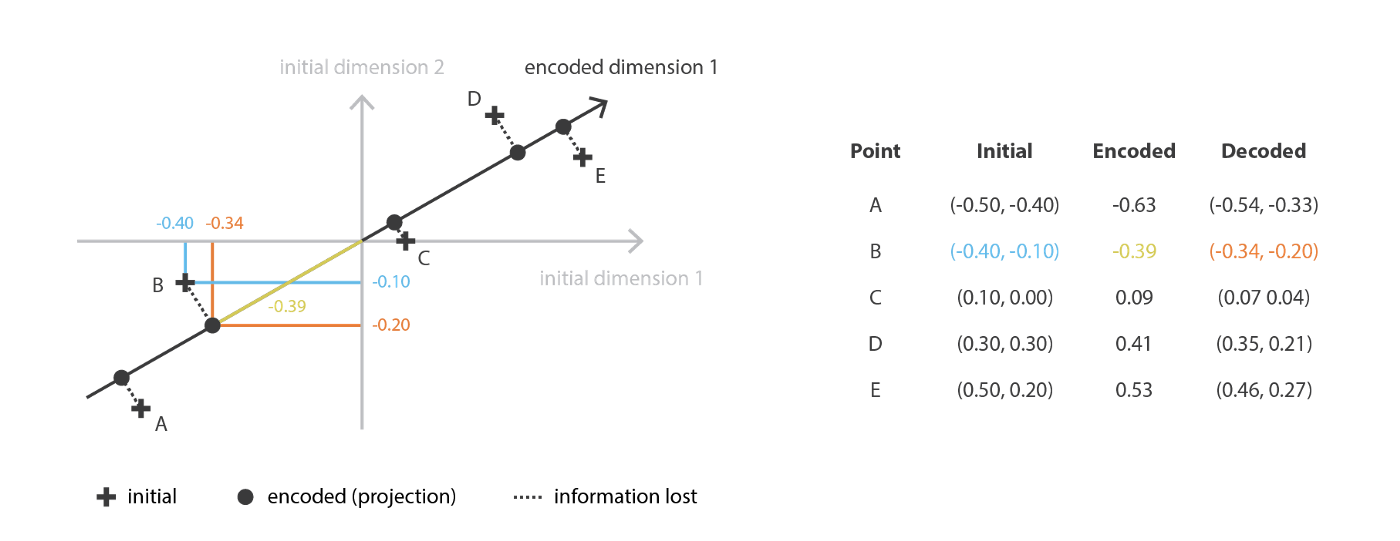
如何用编码器-解码器框架来描述PCA呢? 我们需要寻找这样的编码器:他的维度是 n e × n d n_e \times n_d ne×nd,并且行向量彼此正交。对应的解码器是 n d × n e n_d \times n_e nd×ne也可以证明,编码器和解码器互为转置。
AE 自编码器
自编码器相当简单:设置由神经网络组成的编码器和解码器,并通过迭代优化的方式得到最好的编码-解码组合。每次迭代只需要将解码结果和原始数据做比较并且据此进行反向传播。
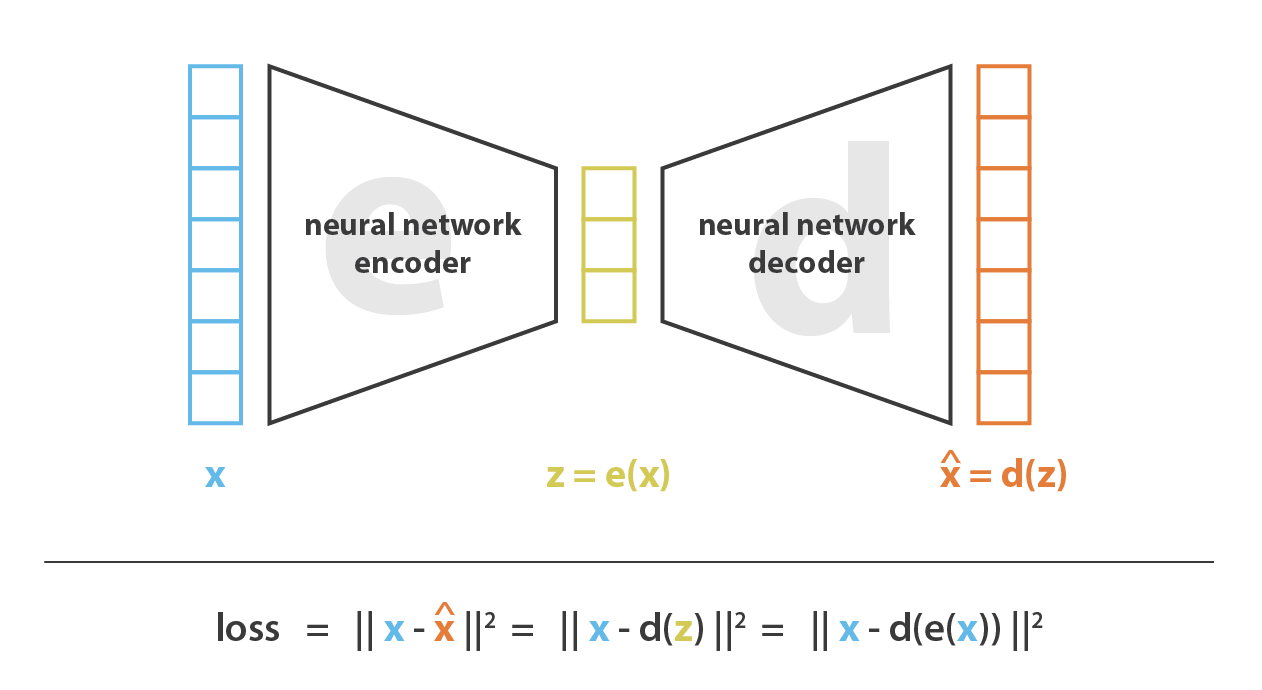
首先我们假设:编码器和解码器的网络只有一层线性层。所以这时编码器和解码器只能做线性变换。这时候我们就发现了自编码器实际上和PCA做的是相似的工作。但是区别在于:PCA的结果基本上是被原始数据限定了的,但是自编码器可以有很多不同的结果。另外,PCA有正交性限制,而自编码器则并不是。
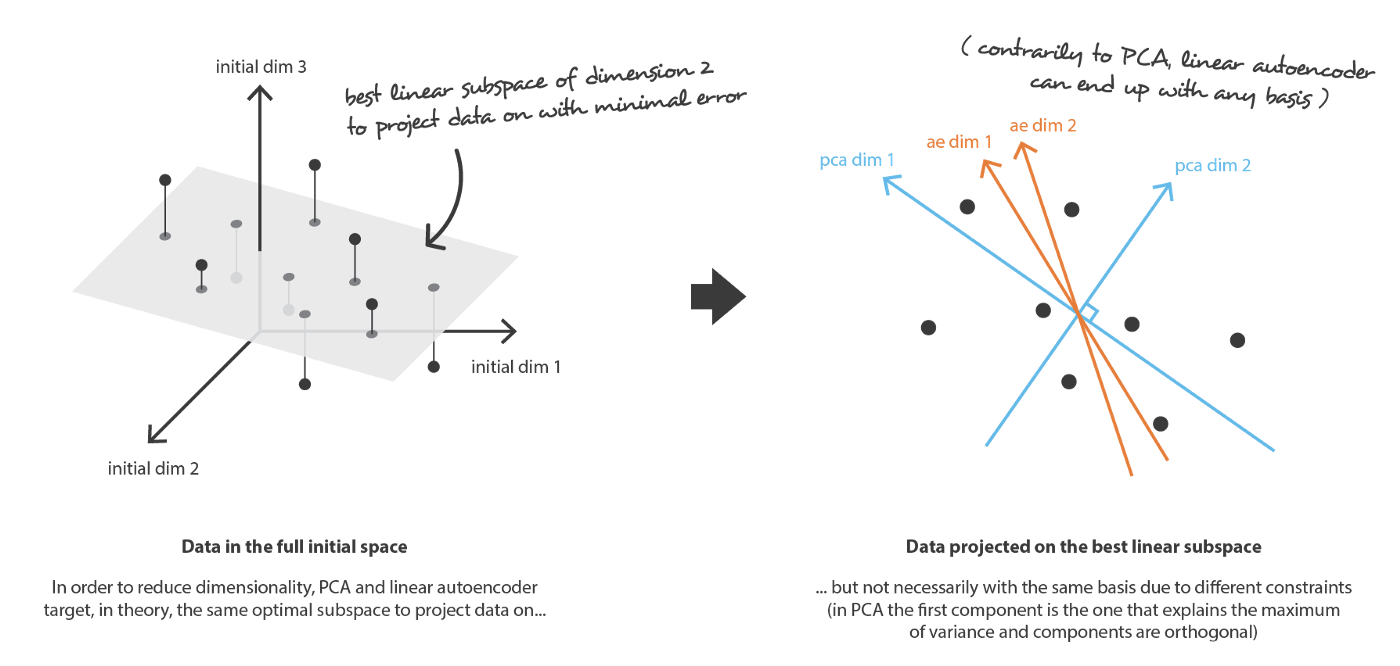
然后我们再继续考虑。 假如解码器和编码器都很深并且是非线性的,换言之,他们都是很复杂的网络,他们就可以既能将数据压缩到很低的维度,也能保持很低的重建误差。从直觉上来说,如果我们的网络足够深,那么我们可以把数据压缩到一维。 实际上,类似的“无限大”的网络可以把数据编码为1、2、3、4…直到N(或者更一般的,实轴上的N个整数)。并且可以同时做到解码器的解码结果没有损失。
现在我们要注意两件事:首先,重建损失低的数据降维手段通常会有代价:潜在空间中缺乏可解释和可利用的结构(也就是缺乏规则性)。 然后,数据降维的目标不仅仅是降低数据的维度,而是在降低维度的基础上尽可能的保留原始数据的结构信息。由于这两个原因,我们必须小心地控制隐空间的维度以及编码器解码器的深度。
三、VAE 变分自编码器
现在我们已经讨论了自编码器,以及他可以通过梯度下降的方法来优化,现在我们再把它和内容生成结合起来,讲一讲他在内容生成上的局限性,然后再介绍变分自编码器。
自编码器用于内容生成的局限性
首先第一个问题是:内容生成和自编码器之间有什么联系?实际上,一旦自编码器训练完成了,我们有编码器和解码器,但是他仍然无法用于内容生成。 乍一想,假如隐空间足够规律(在编码器编码时被很好地组织),我们可以从隐空间中随机取一个点然后用它来进行解码,就可以用于生成新内容了。这里的解码器担任的角色类似于GAN中的生成器。
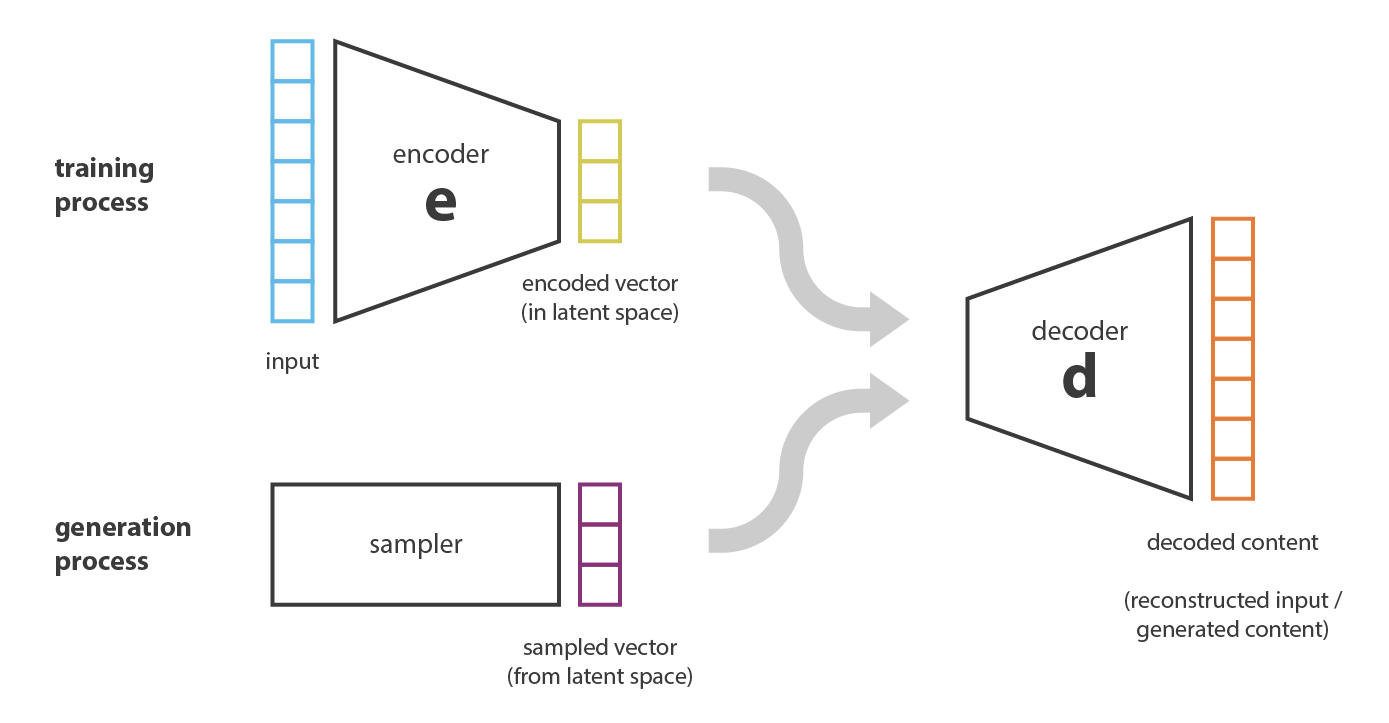
然而,正如我们之前所讨论的那样,对于自编码器来说,隐空间的规则性是个很困难的问题,它取决于原始数据的分布、编码器的结构。
为了举例说明这个问题,我们考虑前面介绍的那个例子: 编码器和解码器足够强大,可以把原始的N种输入编码到实轴上,并且不会有任何的重建损失,同时也带来了严重的过拟合问题。这说明在隐空间中有些点在解码时会产生无意义的内容。自编码器隐空间缺乏规律性的问题是非常普遍的。
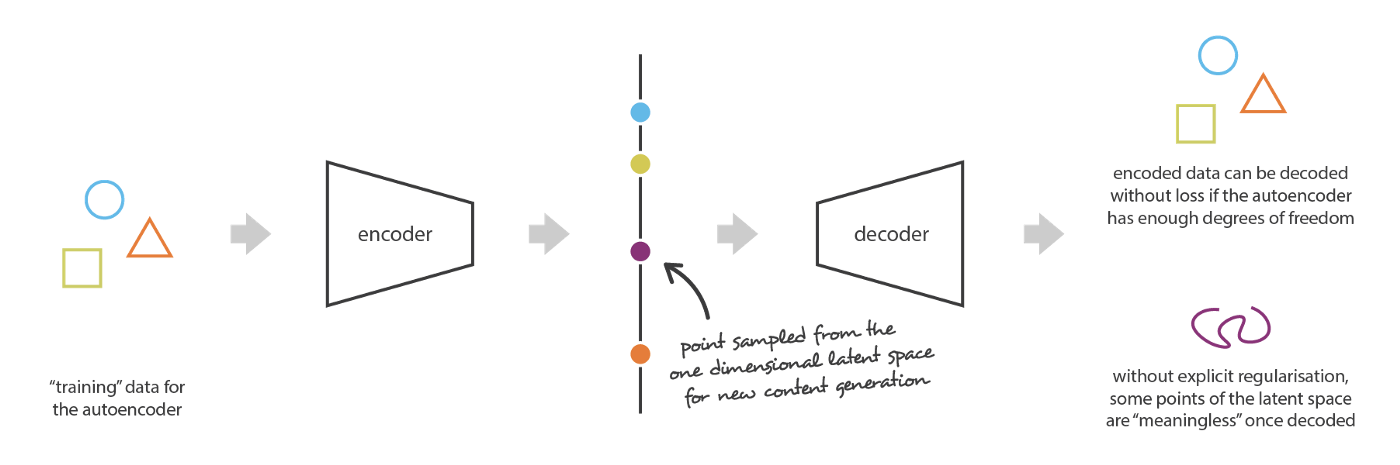
实际上,自编码器隐空间缺乏规律性几乎是必然的:在训练自编码器时我们仅仅希望最终的损失尽可能小,但是没有对隐空间的结构做任何优化。因此,在训练过程中,网络自然会利用各种过拟合的可能性来帮助其完成任务。
变分自编码器(VAE)的定义
因此,为了使得自编码器可以用于内容生成,我们必须保证隐空间足够规律。一个可能的解决方案是引入明确的规律性限制,所以也就诞生了变分自编码器。变分自编码器可以这样定义:他是一个训练时通过正规化手段以避免过拟合,并且确保潜空间具有规律性。这样变分自编码器也可以用于内容生成。
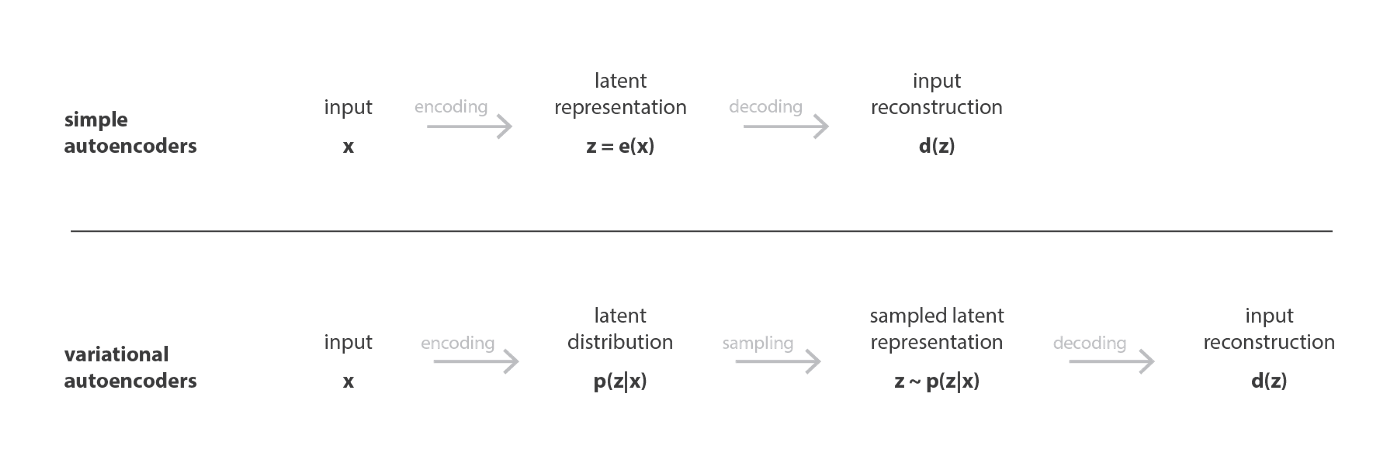
正如标准的自编码器一样,变分自编码器分为编码器和解码器,并且训练的目标是使得重建误差尽可能小。但是为了使得隐空间具有规律性,我们对编码-解码过程做出一定的修正:在变分自编码器中,我们并不是把输入编码为一个点,二十编码为一个分布。模型的训练过程是这样的:
-
- 输入被编码为隐空间中的一个分布
-
- 从隐空间的分布中采样出一个点
-
- 采样出的点通过解码器被重建,并且可以计算出损失
-
- 反向传播
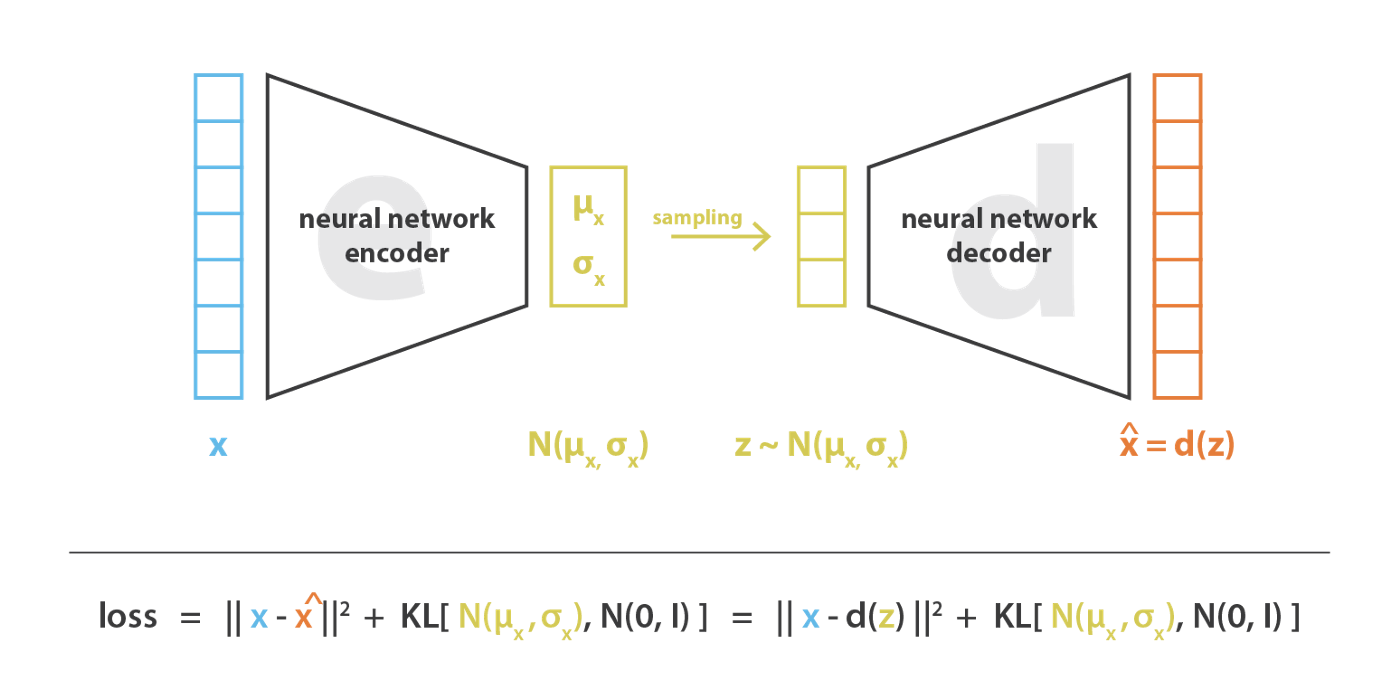
在实践中,编码后的分布被设置为正规化的,这样使得编码器可以被训练为返回描述这些高斯分布的均值和方差矩阵。把输入编码为一个带有方差的分布而不是一个点的主要原因是: 被编码器返回的分布被强行保证为一个标准正态分布。在下一节我们会我们会保证隐空降的总体和局部都实现正则化(总体上控制均值,局部上控制方差)
因此,我们训练VAE时使用的损失函数由以下两部分组成:一个“重建项”,一个“正则化项”。重建项主要用于衡量模型重建数据的效果,正则化项用于尽可能地使隐空间分布和标准正态分布相一致,正则化项的本质是求编码分布和标准正态分布之间的KL散度。
从直觉上理解正则化
为了使生成称为可能,隐空间的规律性可以用两个属性来表示:连续性和完备性
连续性:隐空间中接近的两个点在解码后的内容应当也是相近的
完备性:解码结果应当是“有意义的”

实际上,VAE把输入编码为分布而不是简单的点并不足以保证连续性和完备性。如果不使用一个人定义良好的正则项,模型会尽可能降低重建误差并忽略掉返回的分布。这时候变分自编码器的表现就和自编码器没什么区别了。如何忽略呢?编码器返回的分布可以具有一个很小的方差:这样使得分布接近于常数。也可能返回分布的均值差异很大。
为了避免以上的问题,我们对编码器返回的均值和协方差矩阵都进行正则化。在实现时,这一部分是通过迫使这些分布接近于标准正态分布来实现的。我们要求协方差矩阵接近单位矩阵,防止出现单点分布。并且均值接近于0,防止编码分布距离太远。
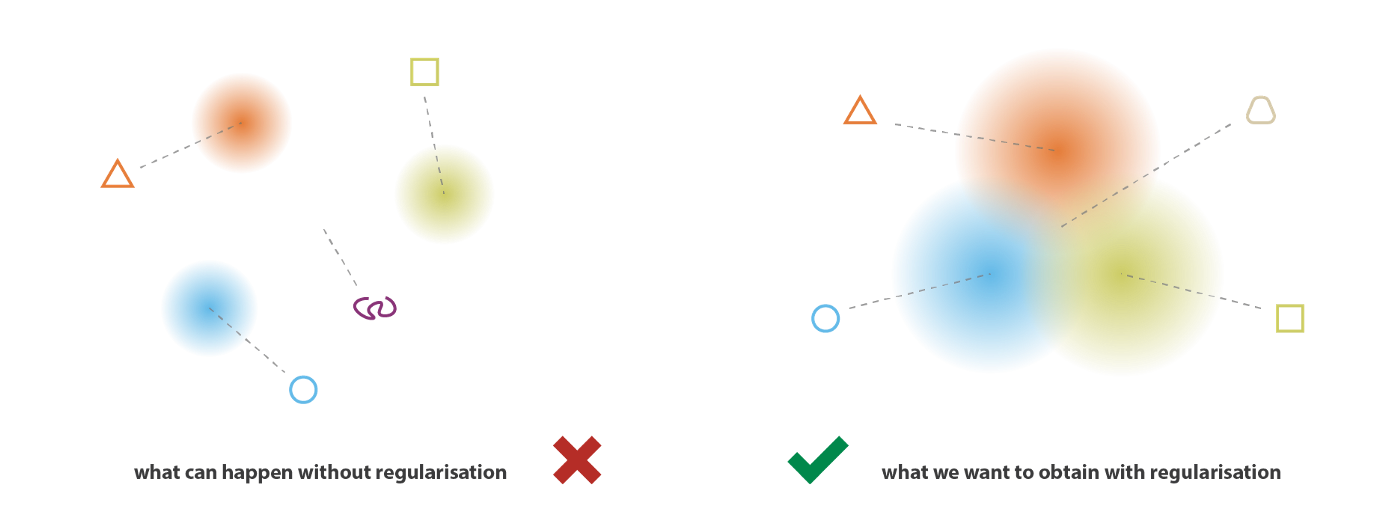
使用正则化项,我们可以防止模型在隐空间的编码相互远离。
数学推导略过,如有兴趣请参照原文
代码实现
参考我的一篇转载文章: VAE代码实现

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









