







多线程开发
最简单例子
import threading
def task(arg):
pass
# 创建一个Thread对象,并封装线程被CPU调度时应该执行的任务和相关参数
t = threading.Thread(target=task, args=('xxx'),)
t.start()
# 主线程执行完所有代码,不结束(等待子线程)
print("继续执行....")
创建一个Thread对象,并封装线程被CPU调度时应该执行的任务和相关参数
主线程执行完所有代码,不结束(等待子线程)
自定义线程类
import threading
class MyThread(threading.Thread):
def run(self):
print("执行此线程", self._args)
t = MyThread(args=(100,))
t.start()
继承的方式重写的run方法,直接将线程要做的事写到run方法中
start函数
start()函数:启动线程,start()表示当前线程已经准备好了(等待CPU调度,具体时间由CPU决定),由于主线程是不会等待子线程执行完再结束的,此时number输出的值是不确定的
import threading
loop = 10000000
number = 0
def _add(count):
global number
for i in range(count):
number += 1
t = threading.Thread(target=_add, args=(loop,))
# 当前线程已经准备好了(等待CPU调度,具体时间由CPU决定)
t.start()
print(number)
join函数
join()函数:主线程等待当前线程的任务执行完毕后再向下执行,即主线程会等待子线程,此时number的值为10000000
import threading
loop = 10000000
number = 0
def _add(count):
global number
for i in range(count):
number += 1
t = threading.Thread(target=_add, args=(loop,))
# 当前线程已经准备好了(等待CPU调度,具体时间由CPU决定)
t.start()
t.join() # 主线程等待中
print(number)
setDaemon
setDaemon(),守护线程(必须放在start之前)- setDaemon(True),设置为守护线程,主线程执行完毕后,子线程也自动关闭
- setDaemon(False),设置为非守护线程,主线程等待子线程,子线程执行完毕后,主线程才结束
import threading
import time
def task(arg):
time.sleep(5)
print('任务')
t = threading.Thread(target=task, args=(11,))
t.setDaemon(True)
t.start()
print('END')
例子运行发现当守护线程设置为True时,由于没有设置
join(),当主线程执行完后就直接结束了子线程
setName和getName
setName()和getName(),线程名字的设置和获取
import threading
def task(arg):
name = threading.current_thread().getName()
print(name)
for i in range(10):
t = threading.Thread(target=task, args=(11,))
t.setName(f'junhao-{i}')
t.start()
is_alive()和isAlive()
# 判断线程是否在执行状态,在执行返回True,否则返回False
t.is_alive()
t.isAlive()
线程安全与死锁
- 一个进程中可以有多个线程,且线程共享所有进程中的资源,多个线程同时去操作一个东西,可能会存在数据混乱的情况
- 有些操作是线程安全的,有些操作不是线程安全的
import threading
loop = 10000000
number = 0
def _add(count):
global number
for i in range(count):
number += 1
def _sub(count):
global number
for i in range(count):
number -= 1
t1 = threading.Thread(target=_add, args=(loop,))
t2 = threading.Thread(target=_sub, args=(loop,))
# 当前线程已经准备好了(等待CPU调度,具体时间由CPU决定)
t1.start()
t2.start()
t1.join()
t2.join()
print(number)
可以发现每次输出的number值是不确定的,因为无法保证两个线程执行的情况,可能一个线程没有执行完,另外一个线程就执行了
import threading
lock_object = threading.RLock()
loop = 10000000
number = 0
def _add(count):
lock_object.acquire() # 申请锁
global number
for i in range(count):
number += 1
lock_object.release() # 释放锁
def _sub(count):
lock_object.acquire() # 申请锁
global number
for i in range(count):
number -= 1
lock_object.release() # 释放锁
t1 = threading.Thread(target=_add, args=(loop,))
t2 = threading.Thread(target=_sub, args=(loop,))
# 当前线程已经准备好了(等待CPU调度,具体时间由CPU决定)
t1.start()
t2.start()
t1.join()
t2.join()
print(number)
给线程加锁,确保每个线程执行完再执行下一个线程
- 用with上下文的方式
import threading
lock_object = threading.RLock()
loop = 10000000
number = 0
def _add(count):
with lock_object:
global number
for i in range(count):
number += 1
def _sub(count):
with lock_object:
global number
for i in range(count):
number -= 1
t1 = threading.Thread(target=_add, args=(loop,))
t2 = threading.Thread(target=_sub, args=(loop,))
# 当前线程已经准备好了(等待CPU调度,具体时间由CPU决定)
t1.start()
t2.start()
t1.join()
t2.join()
print(number)
Lock同步锁,锁一次解一次没有问题,但如果你锁一次没有解的话会出现死锁的情况,嵌套锁的话就会出现死锁
import threading
num = 0
lock_object = threading.Lock()
def task():
print("开始")
lock_object.acquire()
lock_object.acquire()
global num
for i in range(1000000):
num += 1
lock_object.release()
lock_object.release()
print(num)
for i in range(2):
t = threading.Thread(target=task)
t.start()
RLock递归锁,嵌套锁的情况不会出现死锁
import threading
num = 0
lock_object = threading.RLock()
def task():
print("开始")
lock_object.acquire()
lock_object.acquire()
global num
for i in range(1000000):
num += 1
lock_object.release()
lock_object.release()
print(num)
for i in range(2):
t = threading.Thread(target=task)
t.start()
线程之间的通信
前面我已经向大家介绍了,如何使用创建线程,启动线程。相信大家都会有这样一个想法,线程无非就是创建一下,然后再start()下,实在是太简单了。
可是要知道,在真实的项目中,实际场景可要我们举的例子要复杂的多得多,不同线程的执行可能是有顺序的,或者说他们的执行是有条件的,是要受控制的。如果仅仅依靠前面学的那点浅薄的知识,是远远不够的。
那今天,我们就来探讨一下如何控制线程的触发执行。
要实现对多个线程进行控制,其实本质上就是消息通信机制在起作用,利用这个机制发送指令,告诉线程,什么时候可以执行,什么时候不可以执行,执行什么内容。
经过我的总结,线程中通信方法大致有如下三种: - threading.Event - threading.Condition - queue.Queue
接下来我们来一一探讨下。
1. Event事件
Python提供了非常简单的通信机制 Threading.Event,通用的条件变量。多个线程可以等待某个事件的发生,在事件发生后,所有的线程都会被激活。
关于Event的使用也超级简单,就三个函数
event = threading.Event()
# 重置event,使得所有该event事件都处于待命状态
event.clear()
# 等待接收event的指令,决定是否阻塞程序执行
event.wait()
# 发送event指令,使所有设置该event事件的线程执行
event.set()
举个例子来看下。
import time
import threading
class MyThread(threading.Thread):
def __init__(self, name, event):
super().__init__()
self.name = name
self.event = event
def run(self):
print('Thread: {} start at {}'.format(self.name, time.ctime(time.time())))
# 等待event.set()后,才能往下执行
self.event.wait()
print('Thread: {} finish at {}'.format(self.name, time.ctime(time.time())))
threads = []
event = threading.Event()
# 定义五个线程
[threads.append(MyThread(str(i), event)) for i in range(1,5)]
# 重置event,使得event.wait()起到阻塞作用
event.clear()
# 启动所有线程
[t.start() for t in threads]
print('等待5s...')
time.sleep(5)
print('唤醒所有线程...')
event.set()
执行一下,看看结果
Thread: 1 start at Sun May 13 20:38:08 2018
Thread: 2 start at Sun May 13 20:38:08 2018
Thread: 3 start at Sun May 13 20:38:08 2018
Thread: 4 start at Sun May 13 20:38:08 2018
等待5s...
唤醒所有线程...
Thread: 1 finish at Sun May 13 20:38:13 2018
Thread: 4 finish at Sun May 13 20:38:13 2018
Thread: 2 finish at Sun May 13 20:38:13 2018
Thread: 3 finish at Sun May 13 20:38:13 2018
可见在所有线程都启动(start())后,并不会执行完,而是都在self.event.wait()止住了,需要我们通过event.set()来给所有线程发送执行指令才能往下执行。
2. Condition
Condition和Event 是类似的,并没有多大区别。
同样,Condition也只需要掌握几个函数即可。
cond = threading.Condition()
# 类似lock.acquire()
cond.acquire()
# 类似lock.release()
cond.release()
# 等待指定触发,同时会释放对锁的获取,直到被notify才重新占有琐。
cond.wait()
# 发送指定,触发执行
cond.notify()
举个网上一个比较趣的捉迷藏的例子来看看
import threading, time
class Hider(threading.Thread):
def __init__(self, cond, name):
super(Hider, self).__init__()
self.cond = cond
self.name = name
def run(self):
time.sleep(1) #确保先运行Seeker中的方法
self.cond.acquire()
print(self.name + ': 我已经把眼睛蒙上了')
self.cond.notify()
self.cond.wait()
print(self.name + ': 我找到你了哦 ~_~')
self.cond.notify()
self.cond.release()
print(self.name + ': 我赢了')
class Seeker(threading.Thread):
def __init__(self, cond, name):
super(Seeker, self).__init__()
self.cond = cond
self.name = name
def run(self):
self.cond.acquire()
self.cond.wait()
print(self.name + ': 我已经藏好了,你快来找我吧')
self.cond.notify()
self.cond.wait()
self.cond.release()
print(self.name + ': 被你找到了,哎~~~')
cond = threading.Condition()
seeker = Seeker(cond, 'seeker')
hider = Hider(cond, 'hider')
seeker.start()
hider.start()
通过cond来通信,阻塞自己,并使对方执行。从而,达到有顺序的执行。 看下结果
hider: 我已经把眼睛蒙上了
seeker: 我已经藏好了,你快来找我吧
hider: 我找到你了 ~_~
hider: 我赢了
seeker: 被你找到了,哎~~~
3. Queue队列
最后一个,队列,它是本节的重点,因为它是我们日常开发中最使用频率最高的。
从一个线程向另一个线程发送数据最安全的方式可能就是使用 queue 库中的队列了。创建一个被多个线程共享的 Queue 对象,这些线程通过使用put() 和 get() 操作来向队列中发送和获取元素。
同样,对于Queue,我们也只需要掌握几个函数即可。
from queue import Queue
# maxsize默认为0,不受限
# 一旦>0,而消息数又达到限制,q.put()也将阻塞
q = Queue(maxsize=0)
# 默认阻塞程序,等待队列消息,可设置超时时间
q.get(block=True, timeout=None)
# 发送消息:默认会阻塞程序至队列中有空闲位置放入数据
q.put(item, block=True, timeout=None)
# 等待所有的消息都被消费完
q.join()
# 通知队列任务处理已经完成,当所有任务都处理完成时,join() 阻塞将会解除
q.task_done()
以下三个方法,知道就好,一般不需要使用
# 查询当前队列的消息个数
q.qsize()
# 队列消息是否都被消费完,返回 True/False
q.empty()
# 检测队列里消息是否已满
q.full()
函数会比之前的多一些,同时也从另一方面说明了其功能更加丰富。
我来举个老师点名的例子。
# coding=utf-8
from queue import Queue
from threading import Thread
import time
class Student:
def __init__(self, name):
self.name = name
def speak(self):
print("{}:到!".format(self.name))
class Teacher:
def __init__(self, queue):
super().__init__()
self.queue=queue
def call(self, student_name):
if student_name == "exit":
print("点名结束,开始上课..")
else:
print("老师:{}来了没?".format(student_name))
# 发送消息,要点谁的名
self.queue.put(student_name)
class CallManager(Thread):
def __init__(self, queue):
super().__init__()
self.students = {}
self.queue = queue
def put(self, student):
self.students.setdefault(student.name, student)
def run(self):
while True:
# 阻塞程序,时刻监听老师,接收消息
student_name = queue.get()
if student_name == "exit":
break
elif student_name in self.students:
self.students[student_name].speak()
else:
print("老师,咱班,没有 {} 这个人".format(student_name))
queue = Queue()
teacher = Teacher(queue=queue)
s1 = Student(name="小明")
s2 = Student(name="小亮")
cm = CallManager(queue)
cm.put(s1)
cm.put(s2)
cm.start()
print('开始点名~')
teacher.call('小明')
time.sleep(1)
teacher.call('小亮')
time.sleep(1)
teacher.call("exit")
运行结果如下
开始点名~
老师:小明来了没?
小明:到!
老师:小亮来了没?
小亮:到!
点名结束,开始上课..
其实 queue 还有一个很重要的方法,Queue.task_done()
如果不明白它的原理,我们在写程序,就很有可能卡死。
当我们使用 Queue.get() 从队列取出数据后,这个数据有没有被正常消费,是很重要的。
如果数据没有被正常消费,那么Queue会认为这个任务还在执行中,此时你使用 Queue.join() 会一直阻塞,即使此时你的队列里已经没有消息了。
那么如何解决这种一直阻塞的问题呢?
就是在我们正常消费完数据后,记得调用一下 Queue.task_done(),说明队列这个任务已经结束了。
当队列内部的任务计数器归于零时,调用 Queue.join() 就不会再阻塞了。
要理解这个过程,请参考 https://python.iswbm.com/c02/c02_06.html 里自定义线程池的的例子。
4. 消息队列的先进先出
消息队列可不是只有queue.Queue这一个类,除它之外,还有queue.LifoQueue和queue.PriorityQueue这两个类。
从名字上,对于他们之间的区别,你大概也能猜到一二吧。
queue.Queue:先进先出队列queue.LifoQueue:后进先出队列queue.PriorityQueue:优先级队列
先来看看,我们的老朋友,queue.Queue。 所谓的先进先出(FIFO,First in First Out),就是先进入队列的消息,将优先被消费。 这和我们日常排队买菜是一样的,先排队的人肯定是先买到菜。
用代码来说明一下
import queue
q = queue.Queue()
for i in range(5):
q.put(i)
while not q.empty():
print q.get()
看看输出,符合我们先进先出的预期。存入队列的顺序是01234,被消费的顺序也是01234。
0
1
2
3
4
再来看看Queue.LifoQueue,后进先出,就是后进入消息队列的,将优先被消费。
这和我们羽毛球筒是一样的,最后放进羽毛球筒的球,会被第一个取出使用。
用代码来看下
import queue
q = queue.LifoQueue()
for i in range(5):
q.put(i)
while not q.empty():
print q.get()
来看看输出,符合我们后进后出的预期。存入队列的顺序是01234,被消费的顺序也是43210。
4
3
2
1
0
最后来看看Queue.PriorityQueue,优先级队列。 这和我们日常生活中的会员机制有些类似,办了金卡的人比银卡的服务优先,办了银卡的人比不办卡的人服务优先。
来用代码看一下
from queue import PriorityQueue
# 重新定义一个类,继承自PriorityQueue
class MyPriorityQueue(PriorityQueue):
def __init__(self):
PriorityQueue.__init__(self)
self.counter = 0
def put(self, item, priority):
PriorityQueue.put(self, (priority, self.counter, item))
self.counter += 1
def get(self, *args, **kwargs):
_, _, item = PriorityQueue.get(self, *args, **kwargs)
return item
queue = MyPriorityQueue()
queue.put('item2', 2)
queue.put('item5', 5)
queue.put('item3', 3)
queue.put('item4', 4)
queue.put('item1', 1)
while True:
print(queue.get())
来看看输出,符合我们的预期。我们存入入队列的顺序是25341,对应的优先级也是25341,可是被消费的顺序丝毫不受传入顺序的影响,而是根据指定的优先级来消费。
item1
item2
item3
item4
item5
5. 总结一下
学习了以上三种通信方法,我们很容易就能发现Event 和 Condition 是threading模块原生提供的模块,原理简单,功能单一,它能发送 True 和 False 的指令,所以只能适用于某些简单的场景中。
而Queue则是比较高级的模块,它可能发送任何类型的消息,包括字符串、字典等。其内部实现其实也引用了Condition模块(譬如put和get函数的阻塞),正是其对Condition进行了功能扩展,所以功能更加丰富,更能满足实际应用。
线程池的使用
-
在使用多线程处理任务时也不是线程越多越好,由于在切换线程的时候,需要切换上下文环境,依然会造成cpu的大量开销。为解决这个问题,线程池的概念被提出来了。预先创建好一个合理数量的线程池,让过来的任务立刻能够使用,就形成了线程池。
-
基本使用
import time
from concurrent.futures import ThreadPoolExecutor
def task(video_url):
print("开始执行任务", video_url)
time.sleep(1)
pool = ThreadPoolExecutor(10)
url_list = [f'www.xxx-{i}.com' for i in range(100)]
for url in url_list:
pool.submit(task, url)
- 添加shutdown,类似于join
import time
from concurrent.futures import ThreadPoolExecutor
def task(video_url):
print("开始执行任务", video_url)
time.sleep(1)
pool = ThreadPoolExecutor(10)
url_list = [f'www.xxx-{i}.com' for i in range(100)]
for url in url_list:
pool.submit(task, url)
# 执行完所有子线程再结束主线程
pool.shutdown()
print('6'*20)
- 利用add_done_callback()函数,可以做分工,例如:task专门下载 ,done专门将下载的数据写入本地
import random
import time
from concurrent.futures import ThreadPoolExecutor
def task(video_url):
# print("开始执行任务", video_url)
time.sleep(1)
return random.randint(0, 10)
def done(res):
print(res.result())
pool = ThreadPoolExecutor(10)
url_list = [f'www.xxx-{i}.com' for i in range(100)]
for url in url_list:
future = pool.submit(task, url)
future.add_done_callback(done)
- 获得结果后统一处理
import random
import time
from concurrent.futures import ThreadPoolExecutor
def task(video_url):
# print("开始执行任务", video_url)
time.sleep(1)
return random.randint(0, 10)
def done(res):
print(res.result())
pool = ThreadPoolExecutor(10)
url_list = [f'www.xxx-{i}.com' for i in range(100)]
future_list = []
for url in url_list:
future = pool.submit(task, url)
future_list.append(future)
pool.shutdown(True)
for fu in future_list:
print(fu.result())
- 更优雅的方式,创建线程池还可以使用更优雅的方式,就是使用上下文管理器
with ThreadPoolExecutor(5) as pool:
for i in range(100):
pool.submit(target)
多进程开发
window下创建子进程时,需要将创建子进程的代码块包裹在__main__代码块内或自定义函数内。
多进程的三大模式
fork
fork会拷贝主进程的所有资源然后会交给新的进程,并且支持文件对象和线程锁的传输(块)linux系统特有的,任意位置开始执行
spawn
- 会传递run函数内的必备资源,并且不支持文件对象和线程锁的传输(慢),linux,win都含有,会从main函数代码块开始执行
import multiprocessing
import time
def task():
print(name)
if __name__ == '__main__':
multiprocessing.set_start_method("spawn")
name = []
p1 = multiprocessing.Process(target=task)
p1.start()
此时会报错,因为主进程和子进程spawn不会资源共享
import multiprocessing
import time
def task(data):
print(data)
if __name__ == '__main__':
multiprocessing.set_start_method("spawn")
name = []
p1 = multiprocessing.Process(target=task, args=(name,))
p1.start()
此时不会报错,通过arg这个参数给子进程传参数
forkserver
会传递run函数内的必备资源,并且不支持文件对象和线程锁的传输(慢),只有部分linux含有,会从main函数代码块开始执行
常用功能
- p.start(),当前进程准备就绪,等待CPU调度,其工作单元其实是进程中的线程
- p.join(),等待当前进程的任务执行完毕后再向下继续执行,主进程等主进程
import multiprocessing
import os
import time
from multiprocessing import Process
def task(arg):
print(os.getpid())
print(os.getppid())
print("执行中...")
print(multiprocessing.current_process().name)
if __name__ == '__main__':
multiprocessing.set_start_method("spawn")
p = Process(target=task, args=('xxx', ))
p.name = "666"
p.start()
p.join()
print("继续执行")
-
p.deamon = bool,守护进程(必须放在start之前)
- p.daemon = True,设置为守护进程,主进程执行完毕后,子进程也自动关闭
- p.daemon = False,设置为非守护进程,主进程等待子进程,子进程执行完毕后,主进程才结束
-
p.name = “xxx”,给进程设置别名
-
os.getpid(),获取当前进程的pid
-
os.getppid(),获取父进程的pid
自定义进程类
import multiprocessing
class MyProcess(multiprocessing.Process):
def run(self):
print('执行此进程', self._args)
if __name__ == '__main__':
multiprocessing.set_start_method("spawn")
p = MyProcess(args=('xxx',))
p.start()
print('继续执行')
进程之间的通信
- 使用Manger
from multiprocessing import Process, Manager
def f(data):
data[1] = 1
data['2'] = 2
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
p = Process(target=f, args=(d, ))
p.start()
p.join()
print(d)
- 使用Queue

import multiprocessing
def task(q):
for i in range(10):
q.put(i)
if __name__ == '__main__':
queue = multiprocessing.Queue()
p = multiprocessing.Process(target=task, args=(queue,))
p.start()
p.join()
print("主进程")
for i in range(10):
print(queue.get())
- 使用Pipe

import time
import multiprocessing
def task(conn):
time.sleep(1)
conn.send([111, 22, 33, 44])
data = conn.recv()
print("子进程接手:", data)
time.sleep(1)
if __name__ == '__main__':
parent_conn, child_conn = multiprocessing.Pipe()
p = multiprocessing.Process(target=task, args=(child_conn,))
p.start()
info = parent_conn.recv()
print("主进程接受", info)
parent_conn.send(666)
值得注意的是,虽然上述可以实现进程之间的数据交换,但是真正在生产环境时,我们一般借助第三方工具,例如数据库mysql和redis来进行进程之间的进程资源共享
进程锁
from multiprocessing import Process,Lock
import json,time,os
# 获取剩余票数
def search():
time.sleep(1) # 模拟网络io(网络延迟)
with open('db.txt','rt',encoding='utf-8') as fr:
res = json.load(fr)
# print(res)
print(f"还剩{res['count']}")
def get():
with open('db.txt','rt',encoding='utf-8') as fr:
res = json.load(fr)
time.sleep(1) # 模拟网络io(网络延迟)
if res['count'] > 0 :
res['count'] -= 1
with open('db.txt','wt',encoding='utf-8') as fw:
json.dump(res,fw)
print(f'进程{os.getpid()} 抢票成功')
time.sleep(1) # 模拟网络io(网络延迟)
else:
print('票已经售空了!!!')
def func(lock):
search()
# 锁住
lock.acquire()
get()
lock.release()
if __name__ == '__main__':
lock = Lock() # 写在主进程是为了让子进程拿到一把锁
for i in range(10):
p = Process(target=func,args=(lock,))
p.start()
# p.join()
# 进程锁 是把锁住的代码变成了串行
# join 是把所有非子进程变成了串行
# 为了保证数据的安全,串行牺牲掉了效率
进程池
import time
from concurrent.futures import ProcessPoolExecutor
def task(num):
print("执行", num)
time.sleep(1)
if __name__ == '__main__':
pool = ProcessPoolExecutor(6)
for i in range(10):
pool.submit(task, i)
# 子进程全部执行完,主进程再执行
pool.shutdown(True)
协程
线程和进程和协程的区别
线程:是计算机中可以被cpu调度的最小单元
进程:是计算机资源分配的最小单元(进程为线程提供资源)
一个进程中可以有多个线程,同一个进程中的线程可以共享此进程的资源
由于解释器中Cpython中GIL的存在:
- 线程,适用于IO密集型操作
- 进程,适用于计算机密集型操作
- 协程,适用于IO密集型操作,比协程更好,因为可以在一个线程实现并发操作,在处理IO操作时协程比线程更加节省开销(但是协程的开发难度大一些)
协程:让一个线程去执行如果遇到IO堵塞,会自动切换到下一个任务或者下一个协程,当IO堵塞结束后再切换回来。可以通过一个线程实现并发操作
协程实例
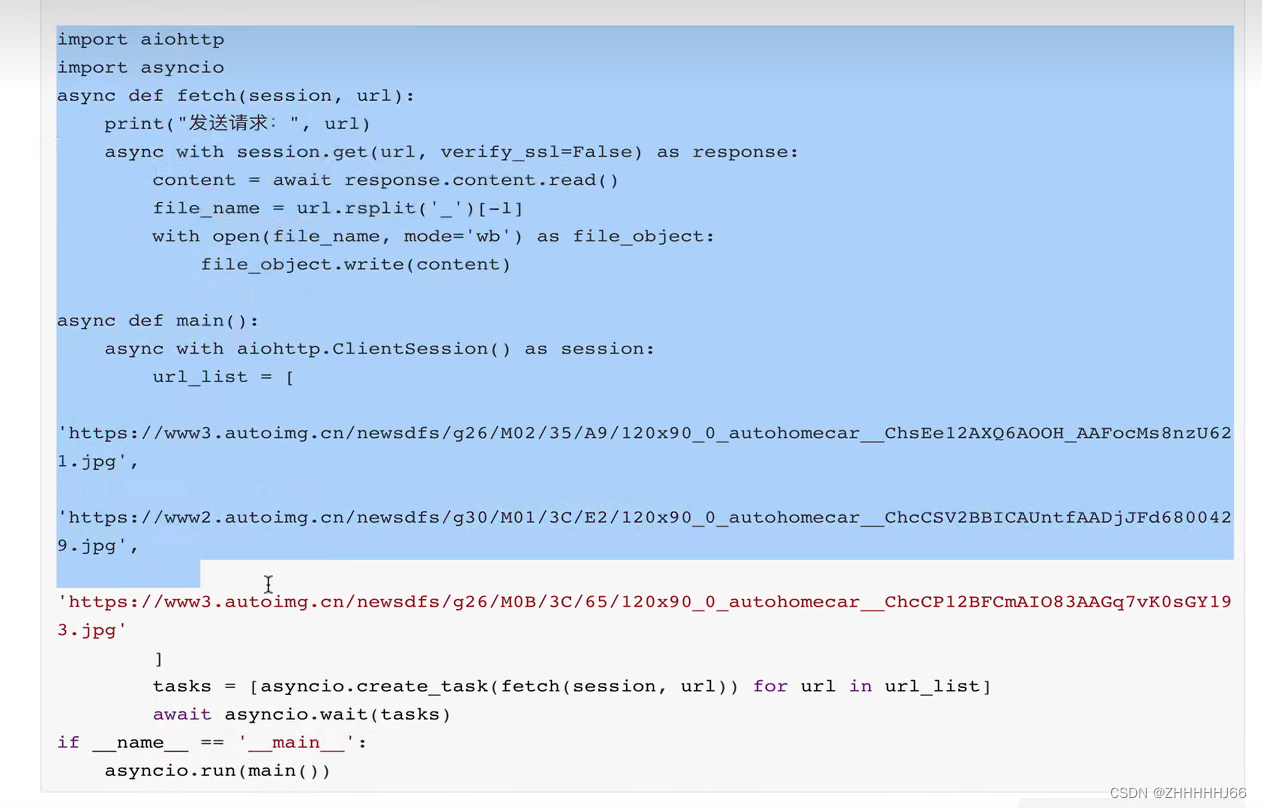
参考(进程通信):
https://python.iswbm.com/c10/c10_04.html















 363
363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









