







文件
数据组织的维度
数据类型
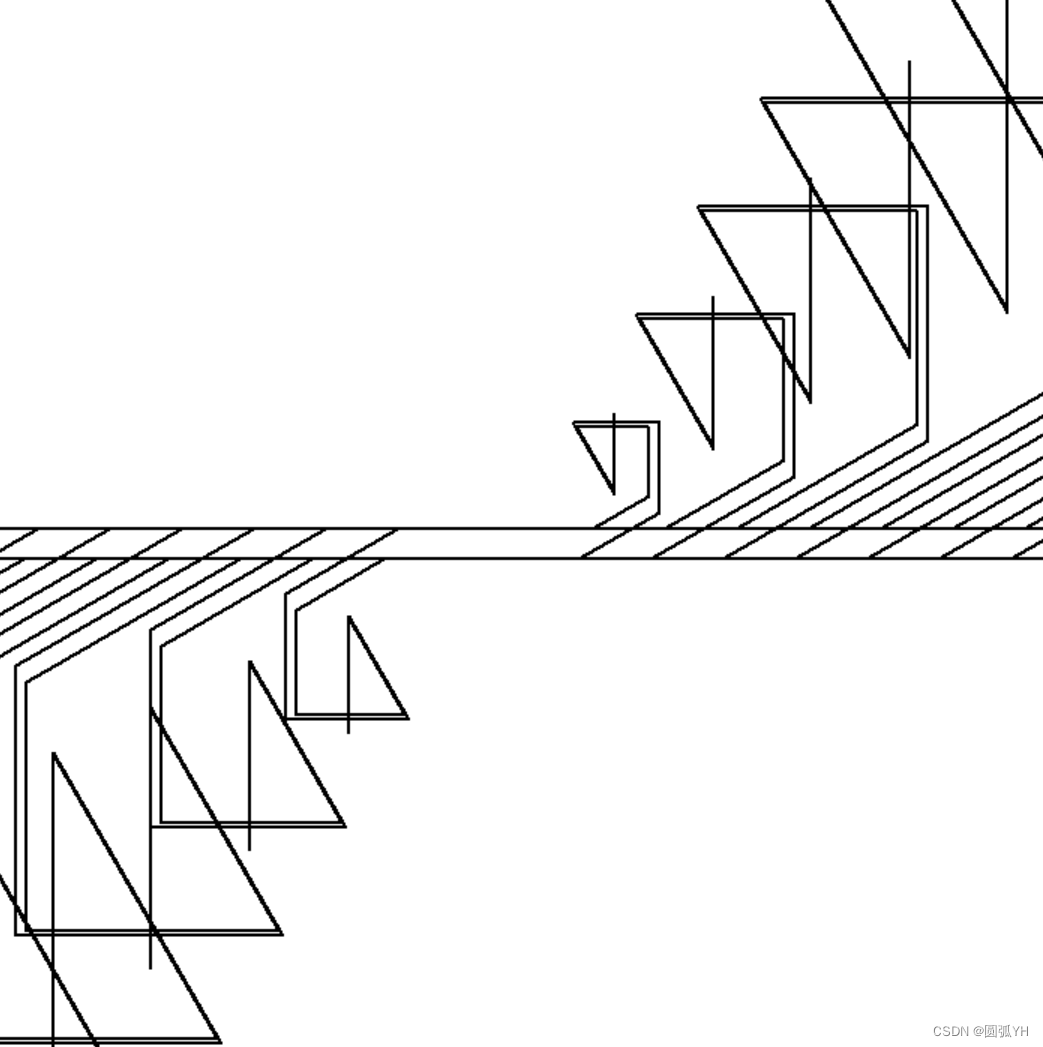
import turtle
turtle.tracer(False)
turtle.pensize(2)
d=0
for i in range(1,1000):
m=40+i*2
turtle.fd(m)
d += 30*i
turtle.seth(d)生成如下图形:
import turtle
turtle.pensize(2)
d=0
for i in range(1,13):
m=40
turtle.fd(m)
d += 30
turtle.seth(d)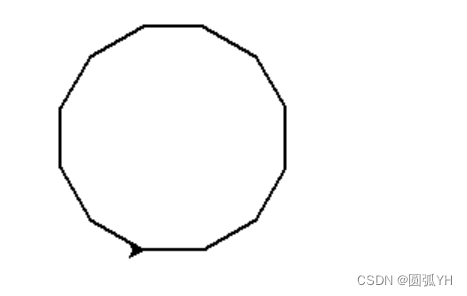
文件的读取和写入
读取和写入文件
文本编码,有时候可以忽略一些错误,如下代码所示:
file=open('test.txt','r',encoding='gbk',errors='ignore')这样在读取文件的时候,可以忽略一些极其个别的错误。
读取

如下代码所示:
rfile=open("test.txt","r",encoding="utf-8")
data=rfile.read()
rfile.close()
datalines=data.splitlines()
for m in datalines:
l=m.split(":")
print(l[1],l[0],end="")
print()
这个时候,用datalines=data.splitlines(),是将一大段字符串,按照行切分为各个小字符串,这些字符串都在有一个列表中。
而如果用readlines,而是以每行为元素形成列表,这些列表都在一个列表中。
二者区别在于,前者列表中的元素是字符串,后者列表中的元素是列表。
写入

代码如下:
fname="test.txt"
fo=open(fname,"w+")
ls=["唐诗","宋词","元曲"]
fo.writelines(ls)
fo.seek(0)#改变当前文件操作指针的位置,0为文件开头;2为文件结尾
fo=open(fname,"r")
data=fo.read()
print(data)这个时候,输出的结果如下:
唐诗宋词元曲
用了writelines,即将列表中的字符串元素,作为整体统一写入了文件。
代码又如下,输入文本名称:
filename=input('请输入文件名:\n')
##请输入文件名:
##pythontest.txt
myfile=open(filename,'w',encoding='utf-8')
character=''
while '#' not in character:
myfile.write(character)
print(' ',end='',file=myfile)
character=input('请输入字符串:\n')
myfile.close()
又另一代码如下:
# -*- coding: utf-8 -*-
"""
Created on Sat Jul 6 23:12:48 2019
@author: cc
"""
with open("learn.txt","wt")as file:
file.write("学习编程的乐趣是无穷的,\n你在创造一个新世界。\n好好学习,天天向上。")
with open("learn.txt","rt") as file:
text=file.read()
print(text)
with open("HLMnovel.txt","rt")as file:
text=file.readlines()
print(text)
打开文件,代码所示:
import re
file=open("E:\文件\书籍文本\三国演义.txt",'r',encoding='GB18030')
data=file.read()
file.close()
#print(data)
#mylist=list(data)
newlist=['apple','bag','dog','egg']
mylist=[w for w in newlist if re.search("g$",w)]
print(mylist)
即可完成。
整理txt
代码如下:
#这个程序,用来整理古文,使得古文句子有序排列,形式美观。
myFile=open("myArticle.txt","r",encoding="utf-8")
myData=myFile.read()
myFile.close()
listComma=["?","。","!",";"]
passComma="01[]23456789[]"#不用输出的符号
dataLines=myData.splitlines()
wFile=open("Result.txt","w",encoding="utf-8")
for myLine in dataLines:
if "”" in myLine:
everyList=myLine.split("”")#照应后面的"”"符号,使得分行更加精准。
for everyLine in everyList:
if everyLine=="":#体现文档的换行
print("\n",file=wFile)
else:
for i in everyLine[:-1]: #这个everyLine[:-1]帮助处理末尾的"”",everyLine[-1]是句号,左闭右开。
if i in passComma:pass
elif i=="“":
print("\n",i,end="",file=wFile)
elif i in listComma:
print(i,"\n",end="",file=wFile)
else:
print(i,end="",file=wFile)
print(everyLine[-1]+"”","\n",end="",file=wFile)#帮助处理末尾的"”"
elif len(myLine)==0:
print("\n",file=wFile)
else:
for i in myLine:
if i in passComma:pass
elif i in listComma:
print(i,"\n",end="",file=wFile)
elif i=="“":
print("\n",i,end="",file=wFile)
else:
print(i,end="",file=wFile)
wFile.close()
即可完成。
切分汉语词语并统计个数
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Mon Jul 1 10:49:20 2019
切分文本,统计词频
@author: 圆弧
"""
import codecs#输入《红楼梦》文本
with codecs.open('HLMnovel.txt','r','utf-8')as fileObject:
print("文件名是:",fileObject.name)
lines=fileObject.read()
fileObject.close()
a=lines.find("第四十一回")
b=lines.find("第八十一回")
part1=lines[0:a]
part2=lines[a:b]
part3=lines[b:-1]
chang=len(lines)
with open("part1.txt","w",encoding="utf-8")as f:
f.write(part1)
with open("part2.txt","w",encoding="utf-8")as f:
f.write(part2)
with open("part3.txt","w",encoding="utf-8")as f:
f.write(part3)
with open("result.txt","w",encoding="utf-8")as f:
f.write("")
print("分割后,前四十回是part1.text,中四十回是part2.text,后四十回是part3.text。")
with open('result.txt','a',encoding='utf-8')as f:
f.write("分割后,前四十回是part1.text,中四十回是part2.text,后四十回是part3.text。")
代码另如下:
#作业1.2 统计五个副词在三部分文档中出现的次数。 越发,难道,可巧,不曾,原是。三个文档中都要记录。
from collections import Counter
import pkuseg
seg=pkuseg.pkuseg()
with open("part1.txt","r",encoding="utf-8")as file1:
lines = file1.readlines()
list1 = []
for line in lines:
seged =seg.cut(line.strip())
for i in seged:
list1.append(i)
num=Counter(list1)
a,b,c,d,e=int(num['越发']),int(num["难道"]),int(num['可巧']),int(num["不曾"]),int(num["原是"])
print('前四十回文本"越发"有%d个词。"难道"有%d个词。可巧"有%d个词。"不曾"有%d个词。"原是"有%d个词。'%a,b,c,d,e)
a=list1.count("越发")
print("'越发'个数:",a)即可完成。
统计字符串
代码如下:
textFile=open('EnglishPaper.txt','rt')
s=textFile.readline
strs=s[:s.find("#")]
for k in set([i for i in strs if i.isalnum()==False and i!='_']):
strs=strs.replace(k," ")
strs=strs.rstrip(' ').lower().split
counts=dict()
for i in strs:
k=i[:15]
if k not in counts:
counts[k]=1
else:
counts[k]+=1
ans=sorted(counts.items(),key=lambda x:(-x[1],x[0]))
print(len(counts))
for i in range(0,int(0.1*len(counts))):
print(str(ans[i][1])+':'+ans[i][0])
textFile.close
即可完成。
回顾反思,如下:
#文件,
#(一)
#python的位置在哪里,pycharm会把生成的文件放到其位置。所以指定一个位置,文件的位置。
# 回去可以打印老师的笔记。大家需要把概念搞清楚。
#还可以用截图。
#(二)
# 我想把它存到文件里面持久记住。
myFile=open("myPrime.txt","w")#表示写入,第一个是文件名,第二个是打开文件的目的。write,read
for i in range(100):
print(i,file=myFile)#把原来输出到屏幕上的东西已经输入到文本文档上了。
# 这个文档在程序运行的时候自动产生了,很神奇。
# 注意格式。file=myFile 一定得写上。
myFile.close()#文件分为三部曲,打开,写入,关闭。
#文件处理就是这么简单。
# 那么文件如何读取呢?
myFile=open("myPrime.txt","r")#用r
myData=myFile.read()#读入文件的全部内容,myData这个命名很重要,还是要写。
myData=myData.split(/n)#用来切分
print(myData)
print(myData[:4])#read,读进来,它就是一个字符串。
myFile.close()#这段话就先空格,提前写下。避免忘记。
#应用于人口数据哦统计。
#来自于国家统计局的数据。看待人口老龄化。
#在现阶段,读进来的是字符串。可以用/n来切分,或者用splitlines,split(',')
#我们要学会解读数据。
'''''
Data=Data.splitlines()#可以按照行来切分。
print(Data[:10])
for everyline in Data:
tmp=ereryline.split(",")
rate=int(tmp([2])/int(tmp([3]))
'''''
#文件的位置也可以自己放。
myFile =open("\prog\python\even.txt","w")
#在执行的时候,产生的文件在根目录下。自己试探一下,熟悉在哪个位置。
#(三)
#把一个数据输入切分。有一种情况,已经拍了照片。老师的文件已经发到教学网上了。
data=data.splitlines():
for line in data:
tmp=line.split(" ,")#按照逗号切分。
#(四)
#我们还可以用readline来读这些数局。如果你的内存有8个G,但又10个G的文件。这时候,你用这种方法逐行读史很正常的。
data=[]
data=file.readlines()#读进来,是一行一行的。
#每一行还可以切分。
文件操作,还有写
file=open("test.txt","w"):
for i in range(1,20)#write只能写str的数据类型。
还有
for i in range(1,20):
print(i,file=myfile )
自己看看讲义。
如此,python 的基础用法就讲完了。即可完成。
文本分割
如下代码所示:
dic1={"北京":34,"上海":34,"广州":32}
list1=list(dic1.items())
print("字典到列表",list1)
list2=['北京,116649_26257\n','天津,75633_1684\n','上海,32633_1684\n']
dic={}
newList=[]
for i in list2:
it = i.split(",") #用split()分割。这样就把一个长的字符串分割成小的字符串。
print(it)
it2 = it[1].strip().split("_")
print(it2)
dic[it[0]] = it2 #用dic[]=word,让列表中元素转换为字典键。
print(dic)
print("列表到字典",newList)
即可完成。
总结反思:
myStr="红军不怕远征难,万水千山只等闲。"
#集合最重要的特征就是没有重复。他会变成一个一个的。
mySet=set(myStr)
print(mySet)
yourSet={"红军不怕远征难,万水千山只等闲。"}
yourSet.add("apple") #集合中用add而不是用append
#set不保证你的顺序。他的最重要特点就是不保证序,查找的速度相当快。list量大的时候,查找的速度比较慢。
set=()#空的集合用括号,而不是花括号。单独的花括号有别的用途。
heLike={'ro','la',"so"}
#set用于高速的增删改查。但是相应的,他的空间就需要大一些。集合函数的掌握得多多实践。差集,交集,子集等需要实现。
'''''
update
intersection
dic={}所以集合用圆括号。字典用花括号。
dynastyLong={"秦":15,"汉":,465}
dynastyLong["元"]=90#无增有改。
字典查找的时候非常快。只需要输入键就可以了。
'''''
hlmFile=open("红楼梦.txt","r",encoding="utf-8")#"utf-8"得加引号
hlmData=hlmFile.read()
hlmFile.close()
print(len(hlmData))
charSet=set(hlmData)
print(charSet)
hzDict={}
#字典没有排序函数。如果想按照顺序排列,那么转化为列表。加items,会把值也放到列表中。没有items,只会保留值。
for singleHz in hlmFile:
if singleHz not in hzDict:
hzDict[singleHz]=1
else:
hzDict[singleHz]+=1
hlmList=list(hzDict.itmes())
hlmList.sort(key=lambda X:X[1],reverse=True)#[("se",1)("se ",2)("jiejie",3)("bao",6)],key=lambda X:X[1],reverse=True所以这么写。
hlmList2=list(hzDict)
print(hlmList[:100])
#如何求词语呢?
Gram2={}
hzCount=len(hlmData)
i=0
while i<hzCount-1:#汉字的count。-1是为了去掉最后的一个字。使得在范围内。
tmpHZ=hlmData[i]+hlmData[i+1]#依次两两组合。
if tmpHZ not in Gram2:
Gram2[tmpHZ]=1
else:
Cram2[tmpHZ]+=1#两两组合。
i+=1
listGram2=list(Gram2.items())
listGram2.sort(key=lambda X:X[1],reverse=True) #("宝玉",1000),("凤姐",90)
print()
i=0
bdStr=set(":,.:'/?%$#@!{}|[]”“;.,,。:~!?!”“")
for everyItem in listGram2:
if everyItem[0][0] not in bdStr or everyItem[0][1]not in bdStr:
print(everyItem,end="")
i+=1
#前后如果有标点符号,可以去掉。
#[0][0]指的是每一个元素里面的一个。(“宝玉”,1772), 计算语言学研究去掉一些词。汉字是可以计算的。拿到一篇文章,看情感分析。
# 比如炒股,把每个人的论坛信息搜集,然后情感分析。最后炒股。
#print(everyItem,end=" ")#这一句是提前写的。很不错。
if i>100:break即可完成。
去除重复
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Mon Jul 1 08:46:02 2019
此处存疑,以待来时。
@author: cc
"""
textFile=open("EnglishPaper.txt","rt")
s=textFile.readlines
strs=s[s]
list(range(strs))
list1=(set(list))
print(list1)
诗文切分
代码如下:
#这个程序,用来整理古文,使得古文句子有序排列,形式美观。
myFile=open("myArticle.txt","r",encoding="utf-8")
myData=myFile.read()
myFile.close()
wFile=open("Result.txt","w",encoding="utf-8")
listComma=["?","。","!",";"]
passComma=["0","1","2","3","4","5","6","7","8","9","[","]"]#不用输出的符号
dataLines=myData.splitlines()
for myLine in dataLines:
everyList=myLine.split("”")#照应后面的"”"符号,使得分行更加精准。
for everyLine in everyList:
if everyLine=="":#体现文档的换行
pass#print("\n",file=wFile)
else:
for i in everyLine[:-1]: #这个everyLine[:-1]帮助处理末尾的"”"
if i in passComma:pass
elif i=="“":
print("\n",i,end="",file=wFile)
elif i in listComma:
print(i,"\n",end="",file=wFile)
else:
print(i,end="",file=wFile)
#print(everyLine[-1],"”",end="")
print(everyLine[-1],"”",end="",sep="",file=wFile)#帮助处理末尾的"”"
wFile.close()
##
优化代码如下:
#这个程序,用来整理古文,使得古文句子有序排列,形式美观。
myFile=open("myArticle.txt","r",encoding="utf-8")
myData=myFile.read()
myFile.close()
wFile=open("Result.txt","w",encoding="utf-8")
listComma=["?","。","!",";"]
passComma=["0","1","2","3","4","5","6","7","8","9","[","]"]#不用输出的符号
dataLines=myData.splitlines()
for myLine in dataLines:
if "“" in myLine:
everyList=myLine.split("”")#照应后面的"”"符号,使得分行更加精准。
for everyLine in everyList:
if everyLine=="":#体现文档的换行
pass#print("\n",file=wFile)
else:
for i in everyLine[:-1]: #这个everyLine[:-1]帮助处理末尾的"”"
if i in passComma:pass
elif i=="“":
print("\n",i,end="",file=wFile)
elif i in listComma:
print(i,"\n",end="",file=wFile)
else:
print(i,end="",file=wFile)
#print(everyLine[-1],"”",end="")
print(everyLine[-1],"”",end="",sep="",file=wFile)#帮助处理末尾的"”"
else:
for i in myLine:
if i in passComma:pass
elif i in listComma:
print(i,"\n",end="",file=wFile)
else:
print(i,end="",file=wFile)
wFile.close()
##
古诗文分段,如下所示:
#这个程序,用来整理古文,使得古文句子有序排列,形式美观。
myFile=open("myArticle.txt","r",encoding="utf-8")
myData=myFile.read()
myFile.close()
wFile=open("Result.txt","w",encoding="utf-8")
listComma=["?","。","!",";"]
passComma=["0","1","2","3","4","5","6","7","8","9","[","]"]#不用输出的符号
dataLines=myData.splitlines()
for myLine in dataLines:
everyList=myLine.split("”")#照应后面的"”"符号,使得分行更加精准。
for everyLine in everyList:
if everyLine=="":#体现文档的换行
print("\n")
else:
for i in everyLine[:-1]: #这个everyLine[:-1]帮助处理末尾的符号
if i in passComma:pass
elif i=="“":
print("\n",i,end="")
elif i in listComma:
print(i,"\n",end="")
else:
print(i,end="")
#print(everyLine[-1],"”",end="")
print(everyLine[-1],"”",end="",sep="")
input()
wFile.close()
##
即可完成。
文档目录实践
改变目录层级
简单常用的当是如下代码:
encodeStr="utf-8"
file=open("FreePic2Pdf_bkmk.txt","r",encoding=encodeStr)
data=file.read()
file.close()
writeFile=open("E:\FreePic2Pdf_bkmk.txt","w",encoding="utf-8")
print("首\n\t封面页\n\t书名页\n\t版权页\n\t序言\n目录",file=writeFile)
datalines=data.splitlines()
for line in datalines:
if "卷" in line:
print(line,file=writeFile)
else:
print("\t",line,file=writeFile)
可以依据第一层目录的文本特点,选择不同的条件语句。
encodeStr=input("(utf-8 utf-16LE GBK...)请输入解码:")
file=open("FreePic2Pdf_bkmk.txt","r",encoding=encodeStr)
data=file.read()
file.close()
writeFile=open("E:\FreePic2Pdf_bkmk.txt","w",encoding="utf-8")
print("首\n\t封面页\n\t书名页\n\t版权页\n\t序言\n目录",file=writeFile)
datalines=data.splitlines()
for line in datalines:
if "第" in line and "章" in line:
print(line,file=writeFile)
elif "第" in line and "讲" in line:
print(line,file=writeFile)
elif "第" in line and "课" in line:
print(line,file=writeFile)
elif "年级" in line:
print(line,file=writeFile)
elif "第" in line and "单元" in line:
print(line,file=writeFile)
elif "第" in line and "卷" in line:
print(line,file=writeFile)
else:
print("\t",line,file=writeFile)
完整代码如下,包括如下:
清楚特殊符选S,换点线为行选N;改变层级选C。
def test():
import re
print()
print("changeTag,特殊文本对象请另写程序代码。")
print()
## itf=open("FreePic2Pdf.itf","r",encoding="utf-8")
## idata=itf.read()
## itf.close()
##
## itfFile=open("E:\FreePic2Pdf.itf","w",encoding="utf-8")
## print(idata,file=itfFile)
## itfFile.close()
##
## file=open("FreePic2Pdf_bkmk.txt","r",encoding="utf-8")
while True:
choice=input("清楚特殊符选S,换点线为行选N;改变层级选C;终止程序选End:")
choice=choice.upper()
if choice=="END":
print("程序结束。")
break
else:
encodeStr=input("(utf-8 utf-16LE GBK...)请输入解码:")
file=open("FreePic2Pdf_bkmk.txt","r",encoding=encodeStr)
data=file.read()
file.close()
if choice=="S":
writeFile=open("E:\FreePic2Pdf_bkmk.txt","w",encoding="utf-8")
datalines=data.splitlines()
myStr="01234567891234567890()()/XYZ/-. .…·"
for line in datalines:
newline=line.split("\t")
for n in myStr:
if n in newline[-1]:
del newline[-1]
break
for m in newline:
print(m,end="",file=writeFile)
print("",file=writeFile)
print("已完成。")
writeFile.close()
continue
elif choice=="N":
writeFile=open("E:\FreePic2Pdf_bkmk.txt","w",encoding="utf-8")
data=data.replace("——","\n\t")
data=data.replace("·","\n\t")
print(data,file=writeFile)
print("已完成。")
writeFile.close()
continue
elif choice=="C":
writeFile=open("E:\FreePic2Pdf_bkmk.txt","w",encoding="utf-8")
print("首\n\t封面页\n\t书名页\n\t版权页\n\t序言\n目录",file=writeFile)
datalines=data.splitlines()
for line in datalines:
if "第" in line and "章" in line:
print(line,file=writeFile)
elif "第" in line and "讲" in line:
print(line,file=writeFile)
elif "第" in line and "课" in line:
print(line,file=writeFile)
elif "年级" in line:
print(line,file=writeFile)
elif "第" in line and "单元" in line:
print(line,file=writeFile)
elif "第" in line and "卷" in line:
print(line,file=writeFile)
else:
print("\t",line,file=writeFile)
print("已完成。")
writeFile.close()
continue
运用正则表达式改变目录
运用正则表达式{ 0,4} ,制作书签PDF。一个使用 技巧来ChangeTagTxt。代码如下:
def test():
import re
print("changeTag")
## itf=open("FreePic2Pdf.itf","r",encoding="utf-8")
## idata=itf.read()
## itf.close()
##
## itfFile=open("E:\FreePic2Pdf.itf","w",encoding="utf-8")
## print(idata,file=itfFile)
## itfFile.close()
##
encodeStr=input("(utf-8;utf-16LE;GBK...)请输入解码:")
file=open("FreePic2Pdf_bkmk.txt","r",encoding=encodeStr)
## file=open("FreePic2Pdf_bkmk.txt","r",encoding="utf-8")
data=file.read()
file.close()
writeFile=open("E:\FreePic2Pdf_bkmk.txt","w",encoding="utf-8")
## while True:
## choice=input("数字为空选S,换线为行选N;改变结构选A;终止程序选End:")
## choice=choice.upper()
##
## if choice=="END":
## print("程序结束。")
## break
##
## elif choice=="S":
## myStr="0123456789()()/XYZ . ."
## for i in myStr:
## data=data.replace(i,"")#这种结构是迭代。如果不采用此结构,替换的数量就是有限的几个。
## print(data,file=writeFile)
## print("已完成。")
## continue
##
## elif choice=="N":
## data=data.replace("——","\n\t")
## print(data,file=writeFile)
## print("已完成。")
## continue
##
## elif choice=="A":
myStr="0123456789()()/XYZ . ."
for i in myStr:
data=data.replace(i,"")#这种结构是迭代。如果不采用此结构,替换的数量就是有限的几个。
datalines=data.splitlines()
pattern1=".*卷.{0,4}[○一二三四五六七八九]"
pattern2=".{0,4}公.{0,4}年" #运用了正则表达式
if "第" in line and "章" in line:
print(line,file=writeFile)
elif "卷" in line:
result=re.findall(pattern,line)
print(result[0],file=writeFile)
a=len(result[0])
print("\t",line[a:],file=writeFile)
else:
print(line,file=writeFile)
print("\t",line,file=writeFile)
print("已完成。")
writeFile.close()
pattern1=".*卷.{0,4}[○一二三四五六七八九]"
pattern2=".{0,4}公.{0,4}年" #运用了正则表达式
具体如《左传》的目录的选取等等,可以用这段代码完成。
编写目录 卷数
这个例子是为了编制目录节数。代码如下,分为不同的情况来考虑。
def test():
choice=input("导出{章X num.num}输入C,添加{num.num}输入A,{汉字大写数字}输入H:")
choice=choice.upper()
code=input("请输入解码格式(utf-8,utf-16LE,GBK):")
def hyszF():
idict={}
numlist=[str(i) for i in range(0,10)]#需要用字符串的形式,这样才能把各个位数上的数字转化为汉语大写形式
bStr="〇一二三四五六七八九"
xy=zip(numlist,bStr)
for i in xy:
idict[i[0]]=i[1]
mydict={}
for i in range(1,1000):
numStr=str(i)
hysz=""
for m in numStr:
hysz+=idict[m]
mydict[str(i)]=hysz
return mydict
def dianF():
zhang=int(input("请输入章数:"))
zhangList=[i for i in range(1,zhang+1)]
jieStr=input("请输入各章的节数{num1,num2,num3……}:")
jieStr=jieStr.replace(",",",")
jieStr=jieStr.rstrip(",")#去除输入者输入的不符合规范的情况(最右侧多余的逗号)
jieStr=jieStr.split(",")
jieList=[int(i) for i in jieStr]
mydict=hyszF()#调用大写数字的字典汉书
if len(jieList)==zhang:
xyList=zip(zhangList,jieList)
for m in xyList:
a=m[0]
print("章",mydict[a],file=wfile)
j=m[1]
for j in range(1,j+1):
result="\t"+str(m[0])+"."+str(j)
print(result,file=wfile)
else:print("章数不符合,请重新输入各章节数。")
if choice=="A":
wfile=open("FreePic2Pdf_bkmk.txt","a",encoding=code)
dianF()
elif choice=="H":
wfile=open("FreePic2Pdf_bkmk.txt","a",encoding=code)
a=int(input("请输入开始章节数:"))
b=int(input("请输入结束章节数:"))
mydict=hyszF()
for i in range(a,b+1):
print(mydict[str(i)],file=wfile)
elif choice=="C":
print("打开txt文本,选择保留章名。")
file=open("FreePic2Pdf_bkmk.txt","r",encoding=code)
data=file.read()
file.close()
wfile=open("FreePic2Pdf_bkmk.txt","w",encoding=code)
data=data.replace("\t","")
datalines=data.splitlines()
zhang=int(input("请输入章数:"))##zhang=20
zhangList=[i for i in range(1,zhang+1)]
jieStr=input("请输入各章的节数{num1,num2,num3……}:")#jieStr="16,24,26,26,28,30,38,21,31,27,26,24,30,44,42,14,26,11,25,3"#论语
jieStr=jieStr.replace(",",",")
jieStr=jieStr.rstrip(",")
jieStr=jieStr.split(",")
jieList=[int(i) for i in jieStr]
if len(jieList)==zhang:
xyList=zip(datalines,jieList)
n=1
for m in xyList:
print(m[0],file=wfile)
for j in range(1,m[1]+1):
result="\t"+str(n)+"."+str(j)
print(result,file=wfile)
n+=1
else:print("章数不符合,请重新输入各章节数。")
wfile.close()
另外一个例子是 为《艺概》编写目录。大写数字。如下:
mytag="""
首
书名页
版权页
序言
目录
前言
凡例
艺概笺注 卷一 文概
艺概笺注 卷二 诗概
艺概笺注 卷三 赋概
艺概笺注 卷四 词曲概
艺概 卷五 书概
艺概 卷六 经义概
附录一
刘熙载《艺概》以外文论集
寤崖子传(刘熙载自传)
附录二
左春坊左中允刘君墓碑 俞樾
《清史稿·儒林传》(刘熙载传)
《清儒学案》(融斋学案) 徐世昌
《清代七百名人传》(刘熙载传) 蔡冠洛
民国《续修兴化县志·人物志》(刘熙载传)
附录三
刘熙载行年小志 王气中
附录四
艺概自叙 刘熙载
附录五
刘融斋诗概诠说 夏敬观
尾
"""
mynum='''卷一:239
卷二:285
卷三:137
卷四:159
卷五:246
卷六:95'''
bstr="〇一二三四五六七八九"
numlist=[str(i) for i in range(0,10)]
xy=zip(numlist,bstr)
mydict={}
for i in xy:
mydict[i[0]]=i[1]
wfile=open("E:\FreePic2Pdf_bkmk.txt","w",encoding="utf-8")
def sz():
for i in range(1,N):
numStr=str(i)
hysz=""
for i in numStr:
hysz+=mydict[i]
print("\t",hysz,file=wfile)
data=mytag.splitlines()
for line in data:
if "卷" in line:
print(line,file=wfile)
N=int(input("请输入节数:"))
sz()
else:print(line,file=wfile)
wfile.close()即可完成。
清除不必要的字符
运用replace() , ord() , chr()
file=open("test.txt","r",encoding="utf-8")
data=file.read()
file.close()
outList=[]
outStr=" \n!!#@"
for i in range(97,123):#英文字母ord("a")=97
outList.append(chr(i))
for nn in range(0,10):
outList.append(str(nn))
for m in outList:
data=data.replace(m,"")
for m in outStr:
data=data.replace(m,"")
wfile=open("outShiWen.txt","w",encoding="utf-8")
print(data,file=wfile)
wfile.close()
即可完成。
大写数字目录
idict={}
numlist=[str(i) for i in range(0,10)]#需要用字符串的形式,这样才能把各个位数上的数字转化为汉语大写形式
bStr="〇一二三四五六七八九"
xy=zip(numlist,bStr)
for i in xy:
idict[i[0]]=i[1]
mydict={}
for i in range(1,16):#依据实际需要修改数字
numStr=str(i)
hysz=""
for m in numStr:
hysz+=idict[m]
mydict[str(i)]=hysz
for k,v in mydict.items():
print(f"卷{v}")
生成可以导入PDF文件中的目录,完整代码如下:
idict={}
numlist=[str(i) for i in range(0,10)]#需要用字符串的形式,这样才能把各个位数上的数字转化为汉语大写形式
bStr="〇一二三四五六七八九"
xy=zip(numlist,bStr)
for i in xy:
idict[i[0]]=i[1]
mydict={}
for i in range(1,1001):#依据实际需要修改数字
numStr=str(i)
hysz=""
for m in numStr:
hysz+=idict[m]
mydict[str(i)]=hysz
wfile=open("E:\FreePic2Pdf_bkmk.txt","w",encoding="utf-8")
head='''
首
书名页
版权页
序言
目录
'''
print(head,file=wfile)
for k,v in mydict.items():
print(f"卷{v}",file=wfile)
wfile.close()
即可完成。
错行目录
下面的目录,通过图片识别汉字,呈现如下的形式,序号和题目分成了两行,没有合在一一齐。
'''
卷第一
1
陳橋兵變黄袍加身
2
韓通被殺
3
太祖受禪
4
陶穀進禪文
5
民間諠言當立點檢為天子
6
杜太夫人聞變言笑自若
7
太祖微行
8
小黄門損畫殿壁
6
軍校獻手檛
10
乘快指揮而誤
11
雖
12
因獵墜馬
13
幽燕未定何謂一統
14
自悔醉酒
15
怒貶趙逢
16
曹彬平江南未得使相
17
太祖彈雀
18
李懷忠諫徙都
19
李筠謀反
20
太祖寵待趙普如左右手
21
金匱之盟
22
趙普舉官
23
趙普固請賞功
24
杯酒釋兵權
25
收諸道精兵
26
愛惜宿衛之士
大
27
28
衛融被俘
29
徐鉉入朝
30
武臣亦當讀經書
31
擢用英俊不問資級
32
董遵誨守通遠軍
33
軍校誣告郭進謀反
34
軍士誣告張永德謀反
35
張美鎮滄州
36
周渭妻莫氏
37
周渭治州縣
不
38
39
太祖太宗授受之懿
40
太祖出宫人
41
以資蔭出身者不得先親民
42
帝王之子當務讀經書
43
太祖性節儉
44
符彦卿不可復委以兵柄
45
曹彬為世宗親吏
46
宋白知貢舉
卷第二
47 吕蒙正不喜記人過
48
侯舍人
49
楊譚林特督運芻粟
50
趙昌言
51
趙昌言折頞
52
錢若水正冤獄
53
一奏欲誅三轉運使
54
曹彬内舉
55
曹瑋用間殺叛卒
56
曹彬仁愛多恕
57
楊徽之
58
王濟好言事
59
魏廷式乞對
60
姚坦好直諫
61
田錫直諫太宗
62
王禹偁文章獨步當世
63
王嘉祐論寇準入相
64
獲李繼遷母
65
魏王德昭自到
66
蘇王元偓
67
寇準奏事忤旨
68
太宗器重寇準
69
李穆
70
知機務與通儒院學士
71
錢俶納土
72
孫何丁謂名大振
73
盧多遜父有高識
74
趙普營西宅
75
報讎張孝子
卷第三
76
錢俶賄趙普
6
涑水記聞
77
曹彬不妄殺
78
曹彬謙恭不伐
79
王禹偁
80
禦戎十策
81
出知黄州
82
上疏陳五事
83
能却繼遷馬
84
澤及子孫
85
張洎與張佖
86
張泊為人
87
王嗣宗
88
梅詢躁於禄位
89
梅詢詈足惜馬
90
梅香孫臭盛肥丁瘦
91
孫何酷好古文
92
孫何盛度丁謂
93
石中立性滑稽
94
鎖廳試
95
省元及第二甲自范鎮始
96
吏治簡易民俗富樂
97
慶曆五年元旦見任兩制以
98
吕夷簡朝會失儀
99
釣魚宴
100
夏竦應科舉
101
制科無登第三等者
102
制科沿革
103
趙槩與歐陽脩
104
龍圖閣待制更直
105
大理寺畏事審刑院
106
陸參迂腐
107
張昇梗直
108
杜杞棄信專殺
109
尚楊二美人得寵
110
滕宗諒諫仁宗内寵太盛
111
宗室换西班官
112
范諷性倜儻
113
編次中書總例
卷第四
114
王德用能處事
115
林瑀以術數侍太宗
116
揀軍
三
117
118
陳執中為宰執
119
葉清臣與陳執中有隙
120
保州卒叛
121
張显之落職知虢州
122
王逵報舊主
123
晉鹽通商
124
北邊塘泊
125
杜杞誘殺宜州蠻
126
孫奭
127
馮元孫奭
128
詔特聽孫奭服犀帶
129
三川口之戰
130
定川砦之戰
131
陝西兵增减
132
狄青平儂智高
133
罷三蕃接伴
134
趙抃上言陳執中八事
卷第五
8
涑水記聞
135
吕夷簡罷相
136
吕夷簡復相
137
廢郭后
138
编
139
龐籍論用文富為相
140
狄青平邕州
141
宋夏慶曆和議
142
李戎訟种世衡擅用官物
143
省兵之議
144
狄青終爲樞密使
145
龐籍求致仕
146
嘉祐違豫
147
章獻劉后本蜀人
148
王欽若譖趙安仁
149
王旦薦寇準爲相
150
馬知節斥王欽若欺君
151
張詠談寇準
152
邢惇
卷第六
153
馮拯
154
王嗣宗劾种放
155
王嗣宗不信鬼神
156
恩讎簿
157
林特善承上接下
158
周王趙祐
159
李允則知雄州
160
周懷政被誅
161
寇準貶雷州
162
章獻劉后惡李迪
163
宫美與劉后
164
胡順之
165
臨淄麻氏
166
真宗决獄
167
朱能得天書
168
孫奭諫西祀
169
駁幸金陵與蜀
170
高瓊請幸北城
171
寇準在澶淵
172
王欽若譖寇準
173
王旦舉代
174
出李迪而留丁謂
175
王旦舉賓客
176
李及代曹瑋知秦州
177
邊患既息漸生侈心
178
符瑞事始於王欽若成於
179
陳恕不進錢榖之數
180
吕端大事不糊塗
181
捲簾乃拜
182
治國猶治家
183
以郭贄知天雄軍
184
敢言者難得
185
孫籍獻書
186
不
187
真宗勤於政事
188
馮元講泰卦
189
真宗重禮杜鎬
190
种放
191
真宗召隱士
192
不
卷第七
10
涑水記聞
193
張詠逼鈐轄討賊
194
勘殺人賊
195
乞斬丁謂
196
楊礪與真宗
197
不以科名自伐
198
李應機
199
王濟張稷
200
孫全照守魏府
201
秤鎚投足
202
唯可進尺不可退寸
203
丁寇異趣
不
204
205
張齊賢分財
206
亡賴子弟皆惕息
207
王欽若陰險多詐
208
王欽若亦智略士
209
王欽若知貢舉受賄
210
王欽若大被知遇
211
向敏中罷相復相
212
辨僧冤獄
213
王旦
214
馬知節為人質直
卷第八
215
王化基為人寬厚
216
李迪
217
仁宗聖性寬仁
218
仁宗祈雨
219
仁宗聽納不倦
220
温成皇后父兄
221
張芻落職貶官
222
張堯佐升遷
223
張元妃殯
224
馮士元獄
225
賜特支錢
226
入閣之儀
227
章獻之過
228
章惠皇后及其弟楊景宗
229
喜雪宴
230
冬至宴
231
温成皇后殯儀
232
郭后之廢
233
兩府執政官非休假日私
234
廢兩制臣僚不許至執政
235
兖國公主入居禁中
236
舉選人充京官與减損蔭
237
京師雨兩月餘不止
238
恭謝天地
239
郭恩被擒
240
磨勘轉官毋自投牒與間戻
241
郭申錫黜知濠州
242
吕夷簡不念舊惡
243
允初癡騃
244
夏守恩坐除名編管
卷第九
245
拓跋諒祚
246
於内帑借錢
247
大興狹河之役
248
宗懿黜官
249
皇子不就肩與
250
作讓知宗正表
12
涑水記聞
251
皇子堅辭新命
252
籍民兵以備契丹
253
契丹遣使奉書入見
254
王則起義
255
築青澗城
256
种世衡知武功縣
257
通判鳳州
258
知澠池縣
259
知青澗城事
260
為屬吏所訟
261
詣羌酋帳
262
遺侍姬於胡酋
263
生羌歸附
264
杖將用間
265
築細腰城
出
266
267
种古
268
夏竦潛加杖數
269
章太傅夫人練氏
270
黄庠中兩元
271
楊真中三元
272
馮京府解貢院殿庭皆第一
273
史吉堅守永平寨
卷第十
274
從卒氣沮
275
劉沆子醜詆張瓌
276
宋氏教子
277
張奎戒酒
278
斬告變者
279
仁宗寢疾
280
281
姜遵知范仲淹
282
晏殊薦范仲淹
283
聱隅子黄晞
284
仁宗欲納陳子城女為后
285
杜衍傭書自資
286
范仲淹論朋黨
287
范仲淹乞罷政事
288
築捍海堤
289
仁宗幸天章閣
290
吴育丁度易位
291
余靖坐詐匿犯刑應舉貶
292
余靖獄案十年猶存
293
築水洛城
294
尹洙以後事屬范仲淹
295
包拯知廬州
296
孔道輔知仙源縣
297
關節不到有閻羅包老
298
重禮周後柴氏
299
300
楊安國趙師民並進職
301
兩府私第毋得見賓客
302
歐陽脩舉進士
303
孫抃被迫請退
304
繁用上表言張茂實為真宗
305
張茂實出知潞州
306
不
307
滕宗諒修岳陽樓
308
焚公使曆
309
仁宗親遇吕夷簡
14
涑水記聞
310
李宗詠
311
王德用出知随州
312
狄青超四資除殿直
313
孔道輔卒於澶州
314
陝西鐵錢
315
沙汰三司吏
316
王素出為外官
317
楊忱監蘄州酒税
卷第十
318
王罕守廣州
319
光化軍宣毅邵興逃叛
320
郊祀配侑
321
提轉按舉苛刻
322
保州雲翼卒叛
323
編輯樞密院文書
324
富弼出使契丹
325
趙元昊與野利氏
326
拓跋諒祚之母
327
种古上書
328
种諤謀取綏州
329
處置綏州之議
330
以綏州易安遠塞門二寨
331
元昊稱帝
332
三川口之戰
卷第十
二
333
李士彬被擒
334
失陷安遠塞門二寨
335
山遇歸宋被拒
336
高繼隆等破後橋寨
337
任福襲取白豹城
338
好水川之戰
339
桑懌
340
任福
341
王立
342
范雍奏諸寨主監押之功
343
築水洛城
344
韓琦論築水洛城利害十
345
西夏兵圍麟府州
346
懸賞捕斬元昊
347
捕斬劉乞都
348
郭遵
349
淮南江浙州軍造紙甲
350
諸路增置弓手
351
强壯弓手編制
352
鄂鄰
353
李士彬
354
元昊圍麟州
355
王吉
356
董氈
357
張方平乞發京畿禁軍赴
358
唃厮囉入貢方物
359
磨氈角自請擊西夏
卷第十
三
360
交趾入寇
361
交趾陷邕州
362
討交趾敕榜
363
楊畋自將擊破叛蠻
364
歐希範
365
366
淯井監蠻攻三江寨
16
涑水記聞
367
淯井叛蠻出降
368
儂智高攻廣州
369
狄青大敗儂智高
370
獲儂智高母
371
趙師道曹覲
372
仲簡落職知筠州
373
儂智高斬蔣偕
374
黄固救廣州
375
石鑒説降邕州諸蠻
376
儂智高父子
377
侍其淵諭叛卒
378
曾鞏草韓維告詞
379
瀘州蠻乞第犯邊
380
文彦博對至和繼嗣事
卷第十四
381
桑湜遷官不受
382
孔噅射虎
383
汪輔之復分司
384
西夏南都統致書宋環慶安
385
王中正攻西夏
386
王中正軍乏糧
387
欲運糧餉王中正軍
388
王中正召河東分屯兵
389
王中正輕視轉運使
390
李憲建議再舉取靈武
391
徐禧等築永樂城
392
徐禧乘勢使氣
393
趙抃任增米價
394
為人清素
395
不敢以私害公
396
劉攽論曾布吕嘉問
397
吕公著在樞府
398
吕公著對役法
399
吕公著薛向相佐佑
400
王居卿改市易法
401
李南公斷獄督税
402
王罕知潭州
平
403
404
閏元宵張燈
405
王麻胡療水疾
406
岐王夫人
407
高遵裕攻靈州
卷第十五
408
薛向罷黜
409
富弼為人温良寬厚
410
鐵龍爪濬川杷
411
决白馬河堤淤田
412
决梁山泊之策
413
黄河分流之策
414
汴口改易
415
塞曹村决河
416
張景温建議榷鹽
417
廢天下馬監
418
李戒建言募人充役
419
追理衙前分外酬獎
420
申明按問欲舉之法
421
夔州路减省賦
422
吕惠卿阻張方平為樞密
423
章惇謁張方平
424
蘇頌草罷吕誨制
涑水記聞卷第十六
425
引用新進
426
427
圜丘赦
428
用新進為提轉
429
何浹提舉常平
430
431
用之必亂天下
432
曾布改助役為免役
433
徐禧王古按秀獄
434
行陝西所鑄折二錢
435
生求墓誌死願託生
436
不
437
438
王安石以疾居家
439
王雱託生
440
李憲言青苗錢爲民害
441
彭汝礪劾王珪等
442
吕升卿落職監酒税
443
王安禮出知潤州
444
王安國常非其兄所為
445
蔣之奇劾歐陽脩帷薄不修
446
王韶獻所著發明自身之學
447
王韶落職知鄂州
448
王安石始與王韶有隙
449
李士寧
450
葉適徐禧
451
鄭俠
452
王永年誣告叔皮謀作亂
453
楊繪竇卞因王永年事被貶
454
宜用敦厚之人以變風俗
455
相州獄
附録一
涑水記聞輯佚
456
太祖採聽明遠
457
將以北朝稱契丹
458
王曾奉使契丹
459
范質爲相
460
四賢一不肖
461
王質餞别范仲淹
462
徹宴助葬
463
罷宦官監軍
464
得輔臣之體
465
山
466
歐陽脩為外夷敬伏
467
王旦遺奏
468
文
469
王旦局量寬厚
470
司馬光諷言祖宗舊法不
471
吕惠卿司馬光等議論變
472
司馬光上資治通鑒
473
文武臣入見謝畢乃得詣
474
崔翰以身許國
475
違陣圖而獲勝
476
王隨薦許元
477
富弼賑飢
478
舉人進止多不如儀
479
梁適除修注
480
郭諮均田賦
481
築古渭寨
20
涑水記聞
482
王陶為監察御史裏行
483
魯有立上言
484
再遣使均田賦
485
罷諸路同提刑
486
富弼堅辭起復
487
韓琦爲首相
488
富弼怨韓琦益深
489
韓維戒潁王
490
錢藻罷直舍人院
491
蔡確鞫相州獄
492
執燭燃鬚
不
493
494
飛矢中黄繖
495
竹木務
496
前朝大臣委靡聽順
附録二
温公日記
1
王旦不置田宅
2
晏殊除祕書正字
3
富弼力争獻納二字
4
歐陽脩衰絰之下服紫袍
5
蔣之奇劾歐陽脩有帷薄之醜
文
6
7
致書妖尼
8
王安石陰結宦官
6
10
王安石不黜王子韶
11
勸仁宗建嗣
12
王安石知江寧府
13
高居簡不宜在左右
14
張方平參政姦邪
15
神宗自製自書資治通鑒序
16
裁省兩府郊賚
17
諷言從諫之美拒諫之禍
18
陳升之為相
19
利口可覆邦家
20
契丹言司馬光忠亮
21
吕公著辨司馬光迂闊
22
乞求外補
23
王安石怨吕公著
24
曾鞏賤市民田
25
謝景温彈蘇軾
26
傅堯俞權鹽鐵副使
27
28
元佐失愛
29
查道
30
李遵勗私長公主乳母
31
丁謂拜相曹利用加同平章
32
山遇來降被拒
33
范仲淹與元昊通書
34
任中師任布並為樞密副使
35
任布罷知河陽
36
復給荆王元儼所上公使錢
37
郭后祔淑德皇后廟
38
徙知揚州馮京知廬州
39
限制僧度弟子
40
出宫人以應天變
41
内殿崇班柴詠
42
43
王珪乞皇太后還政
22 涑水記聞
44
詔山陵所用錢物並從官給
45
契丹耶律宗元謀反
46
韓蟲兒詐得幸有娠
47
韓維戒潁王
48
彗行至張而没
49
居喪不飲酒食肉
50
蔣之奇等奏付樞密院
51
王庭筠等並爲編敕删定官
52
謝景温除侍御史知雜事
53
陳襄除官獨優
54
劉攽與外任
55
利口何至覆邦家
56
蘇頌李大臨封還李定辭頭
57
能制置三司條例司
58
王廣廉在河北
59
廢管勾睦親廣親宅並提舉
60
韓絳王安石協謀沮文彦博
61
寶舜卿代李師中知秦州
62
三司並提舉司轉輪點檢在
63
梁端罷提刑
64
胡宗愈為諫官
65
向寳殺董裕二百餘級
66
賜王欽臣唐坰進士及第出
67
祝諮王庭筠並判刑部
68
審官院流内銓三班院各置
69
侯叔獻楊汲並兼都水
70
李宗諒戰没
71
程昉開御河
72
李定合與不合追服所生母
73
斬李信劉甫
74
高敏等戰死
75
陸詵奏罷川峽四路常平使
76
吕惠卿建言以常平封椿米
77
陳升之稱疾
78
王安石擢用曾布
79
曾布奏改助役為免役殳
80
曾公亮罷相
81
轉對官言有可行特加甄獎
82
武舉推恩
83
鄧綰遷官
84
交趾叛將來降
85
王素以本職致仕
86
王安石營利
87
劉摯最為敢言
88
鄧綰劾富弼
89
程昉憂懼而卒
90
張詵誅殺夔路保塞民
91
張琥落修注
92
楊繪改知鄭州
93
供奉官以下皆免朝請
94
謄下牒漏字
95
齊恢議謀殺人許首事
96
張方平判南京留臺
97
王雱除崇政殿說書
98
鄭獬提舉鴻慶宫
99
王益柔罷直學士院
100
三舍法
101
沈遼衝替
102
編次經義以教後生
103
巡察京城收罪謗議時政者
24
涑水記聞
104
張琥諫勿誅所招慶卒
105
王安石善待蘇液
大
106
107
鞫問張琥
108
曾默有功特遷轉
109
折繼世
110
蔡亢王陶並為詹事
111
王陶與吴奎鬨
112
赤氣見西北隅如火
113
帖子規諫
114
歐陽脩坐擅止青苗錢
番
115
116
朱壽昌尋母
117
李定母亡不丁憂
118
章得象善博
119
李宥知江寧府遭火
120
司馬光論青苗法
121
司馬光初除學士
122
鎖院草制
附録三
温公瑣語
1
蔡確鞫相獄
2
錢藻落直學士院
3
王安石擢用章惇
4
王安石擢用曾布
5
曾布為都檢正
6
唐坰彈王安石
7
曾布詰難楊元素劉摯
8
王安石不汲汲於仕進
9
王安石糾察在京刑獄
附録四
諸家著録題跋
'''针对这种情况,写下如下代码:
myfile=open("test.txt","r",encoding="utf-8")
mylines=myfile.readlines()
myfile.close()
numList=[str(i) for i in range(0,500)]
datalines=[]
for line in mylines:
line=line.rstrip("\n")#用字符串公式去掉空行,要不然,仍然是无法将他们合并在一齐的。
datalines.append(line)
n=0
while True:
shu=2*n#通过列表中的奇数和偶数,奇偶组合。
wen=2*n+1
print(datalines[shu],datalines[wen],end="",sep="")
print()
n+=1
if 2*n==len(datalines):break
要想解决遇到的这些问题,最重要的还是对字符串要熟悉。这样可以游刃有余地操作。
整齐目录
可以用正则表达式取得目录。当有了有钱钟书《管锥编》目录文本,然后对杂乱的目录进行整齐化操作。
目录如下:
zhouyi="""
一二三四五六七八九〇乾坤屯 蒙 需 訟 師,比 小畜兮履 泰 否
○
同人大有 謙 豫 隨,蠱 臨 觀兮噬嗑 賁
剝復 无妄 大畜 頤,大過 坎 離三十備
咸 恒 遯兮及大壯,晉與明夷 家人 睽
蹇 解 損 益 夬 姤 萃,升 困 井 革 鼎 震繼
艮 漸 歸妹 豐 旅 巽,兌 渙 節兮中孚至
小過 既濟兼未濟
繫辭
説卦
"""
shijing='''
一二三四五六七八九〇
○譜序
周南
關雎
葛覃
卷耳
樛木
螽斯
桃夭
兔罝
芣苢
漢廣
汝墳
麟之趾
召南
鵲巢
采蘩
草蟲
采蘋
甘棠
行露
羔羊
殷其靁
摽有梅
小星
江有汜
野有死麕
何彼襛矣
騶虞
邶風
柏舟
綠衣
燕燕
日月
終風
擊鼓
凱風
雄雉
匏有苦葉
谷風
式微
旄丘
簡兮
泉水
北門
北風
靜女
新臺
二子乘舟
鄘風
柏舟
牆有茨
君子偕老
桑中
鶉之奔奔
定之方中
蝃蝀
相鼠
干旄
載馳
衛風
淇奧
考槃
碩人
氓
竹竿
芄蘭
河廣
伯兮
有狐
木瓜
王風
黍離
君子于役
君子陽陽
揚之水
中谷有蓷
兔爰
葛藟
采葛
大車
丘中有麻
鄭風
緇衣
將仲子
叔于田
大叔于田
清人
羔裘
遵大路
女曰鷄鳴
有女同車
山有扶蘇
蘀兮
狡童
褰裳
丰
東門之墠
風雨
子衿
揚之水
出其東門
野有蔓草
溱洧
齊風
雞鳴
還
著
東方之日
東方未明
南山
甫田
盧令
敝笱
載驅
猗嗟
魏風
葛屨
汾沮洳
園有桃
陟岵
十畝之間
伐檀
碩鼠
唐風
蟋蟀
山有樞
揚之水
椒聊
綢繆
杕杜
羔裘
鴇羽
無衣
有杕之杜
葛生
采苓
秦風
車鄰
駟驖
小戎
蒹葭
終南
黃鳥
晨風
無衣
渭陽
權輿
陳風
宛丘
東門之枌
衡門
東門之池
東門之楊
墓門
防有鵲巢
月出
株林
澤陂
檜風
羔裘
素冠
隰有萇楚
匪風
曹風
蜉蝣
候人
鳲鳩
下泉
豳風
七月
鴟鴞
東山
破斧
伐柯
九罭
狼跋
小雅 编辑
鹿鳴之什
鹿鳴
四牡
皇皇者華
常棣
伐木
天保
采薇
出車
杕杜
魚麗
南陔
白華
華黍
南有嘉魚之什
南有嘉魚
南山有臺
由庚
崇丘
由儀
蓼蕭
湛露
彤弓
菁菁者莪
六月
采芑
車攻
吉日
鴻鴈之什
鴻鴈
庭燎
沔水
鶴鳴
祈父
白駒
黃鳥
我行其野
斯干
無羊
節南山之什
節南山
正月
十月之交
雨無正
小旻
小宛
小弁
巧言
何人斯
巷伯
谷風之什
谷風
蓼莪
大東
四月
北山
無將大車
小明
鼓鍾
楚茨
信南山
甫田之什
甫田
大田
瞻彼洛矣
裳裳者華
桑扈
鴛鴦
頍弁
車舝
青蠅
賓之初筵
魚藻之什
魚藻
采菽
角弓
菀柳
都人士
采綠
黍苗
隰桑
白華
緜蠻
瓠葉
漸漸之石
苕之華
何草不黃
大雅 编辑
文王之什
文王
大明
緜
棫樸
旱麓
思齊
皇矣
靈臺
下武
文王有聲
生民之什
生民
行葦
既醉
鳬鷖
假樂
公劉
泂酌
卷阿
民勞
板
蕩之什
蕩
抑
桑柔
雲漢
崧高
烝民
韓奕
江漢
常武
瞻卬
召旻
周頌 编辑
清廟之什
清廟
維天之命
維清
烈文
天作
昊天有成命
我將
時邁
執競
思文
臣工之什
臣工
噫嘻
振鷺
豐年
有瞽
潛
雝
載見
有客
武
閔予小子之什
閔予小子
訪落
敬之
小毖
載芟
良耜
絲衣
酌
桓
賚
般
魯頌 编辑
駉之什
駉
有駜
泮水
閟宮
商頌 编辑
那
烈祖
玄鳥
長發
殷武
'''
shiji='''
○
卷一 五帝本紀第一
卷二 夏本紀第二
卷三 殷本紀第三
卷四 周本紀第四
卷五 秦本紀第五
卷六 秦始皇本紀第六
卷七 項羽本紀第七
卷八 高祖本紀第八
卷九 呂后本紀第九
卷十 孝文本紀第十
卷十一 孝景本紀第十一
卷十二 孝武本紀第十二
表 编辑
卷十三 三代世表第一
卷十四 十二諸侯年表第二
卷十五 六國年表第三
卷十六 秦楚之際月表第四
卷十七 漢興以來諸侯王年表第五
卷十八 高祖功臣侯者年表第六
卷十九 惠景閒侯者年表第七
卷二十 建元以來侯者年表第八
卷二十一 建元以來王子侯者年表第九
卷二十二 漢興以來將相名臣年表第十
書 编辑
卷二十三 禮書第一
卷二十四 樂書第二
卷二十五 律書第三
卷二十六 曆書第四
卷二十七 天官書第五
卷二十八 封禪書第六
卷二十九 河渠書第七
卷三十 平準書第八
世家 编辑
卷三十一 吳太伯世家第一
卷三十二 齊太公世家第二
卷三十三 魯周公世家第三
卷三十四 燕召公世家第四
卷三十五 管蔡世家第五
卷三十六 陳杞世家第六
卷三十七 衛康叔世家第七
卷三十八 宋微子世家第八
卷三十九 晉世家第九
卷四十 楚世家第十
卷四十一 越王勾踐世家第十一
卷四十二 鄭世家第十二
卷四十三 趙世家第十三
卷四十四 魏世家第十四
卷四十五 韓世家第十五
卷四十六 田敬仲完世家第十六
卷四十七 孔子世家第十七
卷四十八 陳涉世家第十八
卷四十九 外戚世家第十九
卷五十 楚元王世家第二十
卷五十一 荊燕世家第二十一
卷五十二 齊悼惠王世家第二十二
卷五十三 蕭相國世家第二十三
卷五十四 曹相國世家第二十四
卷五十五 留侯世家第二十五
卷五十六 陳丞相世家第二十六
卷五十七 絳侯周勃世家第二十七
卷五十八 梁孝王世家第二十八
卷五十九 五宗世家第二十九
卷六十 三王世家第三十
列傳 编辑
卷六十一 伯夷列傳第一
卷六十二 管晏列傳第二
卷六十三 老子韓非列傳第三
卷六十四 司馬穰苴列傳第四
卷六十五 孫子吳起列傳第五
卷六十六 伍子胥列傳第六
卷六十七 仲尼弟子列傳第七
卷六十八 商君列傳第八
卷六十九 蘇秦列傳第九
卷七十 張儀列傳第十
卷七十一 樗里子甘茂列傳第十一
卷七十二 穰侯列傳第十二
卷七十三 白起王翦列傳第十三
卷七十四 孟子荀卿列傳第十四
卷七十五 孟嘗君列傳第十五
卷七十六 平原君虞卿列傳第十六
卷七十七 魏公子列傳第十七
卷七十八 春申君列傳第十八
卷七十九 范睢蔡澤列傳第十九
卷八十 樂毅列傳第二十
卷八十一 廉頗藺相如列傳第二十一
卷八十二 田單列傳第二十二
卷八十三 魯仲連鄒陽列傳第二十三
卷八十四 屈原賈生列傳第二十四
卷八十五 呂不韋列傳第二十五
卷八十六 刺客列傳第二十六
卷八十七 李斯列傳第二十七
卷八十八 蒙恬列傳第二十八
卷八十九 張耳陳餘列傳第二十九
卷九十 魏豹彭越列傳第三十
卷九十一 黥布列傳第三十一
卷九十二 淮陰侯列傳第三十二
卷九十三 韓信盧綰列傳第三十三
卷九十四 田儋列傳第三十四
卷九十五 樊酈滕灌列傳第三十五
卷九十六 張丞相列傳第三十六
卷九十七 酈生陸賈列傳第三十七
卷九十八 傅靳蒯成列傳第三十八
卷九十九 劉敬叔孫通列傳第三十九
卷一百 季布欒布列傳第四十
卷一百零一 袁盎鼂錯列傳第四十一
卷一百零二 張釋之馮唐列傳第四十二
卷一百零三 萬石張叔列傳第四十三
卷一百零四 田叔列傳第四十四
卷一百零五 扁鵲倉公列傳第四十五
卷一百零六 吳王濞列傳第四十六
卷一百零七 魏其武安列傳第四十七
卷一百零八 韓長孺列傳第四十八
卷一百零九 李將軍列傳第四十九
卷一百一十 匈奴列傳第五十
卷一百一十一 衛將軍驃騎列傳第五十一
卷一百一十二 平津侯主父列傳第五十二
卷一百一十三 南越列傳第五十三
卷一百一十四 東越列傳第五十四
卷一百一十五 朝鮮列傳第五十五
卷一百一十六 西南夷列傳第五十六
卷一百一十七 司馬相如列傳第五十七
卷一百一十八 淮南衡山列傳第五十八
卷一百一十九 循吏列傳第五十九
卷一百二十 汲鄭列傳第六十
卷一百二十一 儒林列傳第六十一
卷一百二十二 酷吏列傳第六十二
卷一百二十三 大宛列傳第六十三
卷一百二十四 游俠列傳第六十四
卷一百二十五 佞幸列傳第六十五
卷一百二十六 滑稽列傳第六十六
卷一百二十七 日者列傳第六十七
卷一百二十八 龜策列傳第六十八
卷一百二十九 貨殖列傳第六十九
卷一百三十 太史公自序第七十
'''
为此,写下如下代码:
def test():
import re
print("changeTag")
## itf=open("FreePic2Pdf.itf","r",encoding="utf-8")
## idata=itf.read()
## itf.close()
##
## itfFile=open("E:\FreePic2Pdf.itf","w",encoding="utf-8")
## print(idata,file=itfFile)
## itfFile.close()
##
## encodeStr=input("(utf-8;utf-16LE;GBK...)请输入解码:")
## file=open("FreePic2Pdf_bkmk.txt","r",encoding=encodeStr)
## file=open("FreePic2Pdf_bkmk.txt","r",encoding="utf-8")
##
## data=file.read()
## file.close()
file=open("mulu.txt","r",encoding="utf-8")
data=file.read()
file.close()
writeFile=open("E:\FreePic2Pdf_bkmk.txt","w",encoding="utf-8")
## while True:
## choice=input("数字为空选S,换线为行选N;改变结构选A;终止程序选End:")
## choice=choice.upper()
##
## if choice=="END":
## print("程序结束。")
## break
##
## elif choice=="S":
## myStr="0123456789()()/XYZ . ."
## for i in myStr:
## data=data.replace(i,"")#这种结构是迭代。如果不采用此结构,替换的数量就是有限的几个。
## print(data,file=writeFile)
## print("已完成。")
## continue
##
## elif choice=="N":
## data=data.replace("——","\n\t")
## print(data,file=writeFile)
## print("已完成。")
## continue
##
## elif choice=="A":
myStr="0123456789()()/XYZ . ."
for i in myStr:
data=data.replace(i,"")#这种结构是迭代。如果不采用此结构,替换的数量就是有限的几个。
dataT=data.split("▼")
## datalines=data.splitlines()
## pattern1=".*卷.{0,4}[○一二三四五六七八九]"
## pattern2=".{0,4}公.{0,4}年"
def zhouyiF():
zhouyiContent=dataT[1]
datalines=zhouyiContent.splitlines()
for line in datalines[:10]:
n=0
for word in line:
if word in zhouyi:
print(word,end="",sep="",file=writeFile)
n+=1
if n==1:print(" ",end="",sep="",file=writeFile)
if word not in zhouyi:
break
print("\n",file=writeFile)
nline=line[n:].split("——")
for i in nline:
print("\t",i,file=writeFile)
for line in datalines[10:]:
n=0
for word in line:
if word in zhouyi:
print(word,end="",sep="",file=writeFile)
n+=1
if n==2:print(" ",end="",sep="",file=writeFile)
if word not in zhouyi:
break
print("\n",file=writeFile)
nline=line[n:].split("——")
for i in nline:
print("\t",i,file=writeFile)
zhouyiF()
def maoshiF():
maoshiContent=dataT[2]
datalines=maoshiContent.splitlines()
for line in datalines[:10]:
n=0
for word in line:
if word in shijing:
print(word,end="",sep=" ",file=writeFile)
n+=1
if n==1:
print(" ",end="",sep=" ",file=writeFile)
elif word not in shijing:
break
print("\n",file=writeFile)
nline=line[n:].split("——")
for i in nline:
print("\t",i,file=writeFile)
for line in datalines[10:]:
n=0
for word in line:
if word in shijing:
print(word,end="",sep=" ",file=writeFile)
n+=1
if n==2:
print(" ",end="",sep=" ",file=writeFile)
elif word not in shijing:
break
print("\n",file=writeFile)
nline=line[n:].split("——")
for i in nline:
print("\t",i,file=writeFile)
maoshiF()
def zuozhuanF():
zuozhuanContent=dataT[3]
datalines=zuozhuanContent.splitlines()
for line in datalines[:10]:
n=0
for word in line:
print(word,end="",sep="",file=writeFile)
n+=1
if word=="年":
print(" ",file=writeFile)
break
if n==1:print(" ",end="",sep="",file=writeFile)
nline=line[n:].split("——")
for i in nline:
print("\t",i,file=writeFile)
for line in datalines[10:]:
n=0
for word in line:
print(word,end="",sep="",file=writeFile)
n+=1
if word=="年":
print(" ",file=writeFile)
break
if n==2:print(" ",end="",sep="",file=writeFile)
nline=line[n:].split("——")
for i in nline:
print("\t",i,file=writeFile)
zuozhuanF()
def shijiF():
sj=dataT[-1]
datalines=sj.splitlines()
for line in datalines[:10]:
#print(line)
n=0
for word in line:
if word in shiji:
print(word,end="",sep="",file=writeFile)
n+=1
if n==1:
print(" ",end="",sep=" ",file=writeFile)
continue
if word in "家傳紀書序":
break
print("\n",file=writeFile)
nline=line[n:].split("——")
for i in nline:
print("\t",i,file=writeFile)
for line in datalines[10:]:
n=0
for word in line:
if word in shiji:
print(word,end="",sep="",file=writeFile)
n+=1
if n==2:
print(" ",end="",sep=" ",file=writeFile)
if word in "家傳紀書序":
break
print("\n",file=writeFile)
nline=line[n:].split("——")
for i in nline:
print("\t",i,file=writeFile)
shijiF()
## if "第" in line and "章" in line:
## print(line,file=writeFile)
##
## elif "卷" in line:
## result=re.findall(pattern,line)
## print(result[0],file=writeFile)
## a=len(result[0])
## print("\t",line[a:],file=writeFile)
## elif "年" in line:
## result=re.findall(pattern2,line)
## print(result[0],file=writeFile)
## a=len(result[0])
## print(line[a:],file=writeFile)
##
## else:
## print(line,file=writeFile)
## print("\t",line,file=writeFile)
## print("已完成。")
## continue
writeFile.close()
PDF 操作
pypdf2 →将pdf转化为word
将pdf文件转换为word
可以用如下代码:
import PyPDF2
from docx import Document
def pdf_to_word(pdf_file_path, word_file_path):
# 打开PDF文件
with open(pdf_file_path, 'rb') as file:
# 使用 PdfReader 替代 PdfFileReader
reader = PyPDF2.PdfReader(file)
text = ''
# 遍历PDF的每一页
for page_num in range(len(reader.pages)):
# 使用 pages[page_num] 替代 getPage(page_num)
page = reader.pages[page_num]
text += page.extract_text()
# 创建一个新的Word文档
doc = Document()
# 将提取的文本添加到Word文档中
doc.add_paragraph(text)
# 保存Word文档
doc.save(word_file_path)
# 使用示例
pdf_file_path = 'example.pdf' # 替换为你的PDF文件路径
word_file_path = 'example.docx' # 你想要保存的Word文件路径
pdf_to_word(pdf_file_path, word_file_path)
即可完成。
pdfminer
使用pdfminer,但是一个失败的操作如下:
'''
PDFParser:从一个文件中获取数据
PDFDocument:保存获取的数据,和PDFParser是相互关联的
PDFPageInterpreter处理页面内容
PDFDevice将其翻译成你需要的格式
PDFResourceManager用于存储共享资源,如字体或图像。
'''
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfdevice import PDFDevice
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
from pdfminer.pdfpage import PDFPage
##def fromPdfToTxt(readfile,writefile,pagestart=0,pageend=0):
##
##
##fromPdfToTxt()
originFile=open('E:\文件\书籍文本\zhongguowenxueshi.pdf','rb')
#将pdf文件转化为了二进制,print(data)
parser=PDFParser(originFile)
document=PDFDocument(parser)
#创建一个PDF资源管理器对象来存储共享资源
rsrcmgr = PDFResourceManager()
laparams=LAParams()
#创建一个pdf设备对象
device = PDFDevice(rsrcmgr)
#创建一个PDF解析器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
#处理文档当中的每个页面
for page in PDFPage.create_pages(document):
interpreter.process_page(page)
layout=device.get_result()
for x in layout:
print(x)
input()
书签操作
pdf书签
file=open("shiji.txt","r",encoding="utf-8")
data=file.read()
file.close()
dataList=data.splitlines()
wFile=open("resutShiji.txt","w")
for line in dataList:
everyLine=line.split("\t")
print(everyLine[0],"\t",file=wFile)
wFile.close()
书签减去页码-然后代入PDF文本 用列表就可以。
文档 通过DOS复制文件夹中的文件名 然后将书名整理成notexspress形式导入 节约时间。
myFile=open("name.txt","r",encoding="utf-8")
data=myFile.read()
myFile.close()
noteE="""
{Reference Type}: Book
{Publisher}: 北京:商务印书馆
{Year}: 1997
"""
resultFile=open("resultNmae.txt","w",encoding="utf-8")
nameLines=data.splitlines()
for everyLine in nameLines:
if "D" in everyLine:
iname=everyLine.split("D")
article=iname[-1]
print(noteE,end="",file=resultFile)
print("{Title}:",article[4:-4],file=resultFile)
elif "C" in everyLine:
iname=everyLine.split("C")
article=iname[-1]
print(noteE,end="",file=resultFile)
print("{Title}:",article[4:-4],file=resultFile)
print()
elif "E" in everyLine:
iname=everyLine.split("E")
article=iname[-1]
print(noteE,end="",file=resultFile)
print("{Title}:",article[4:-4],file=resultFile)
print()
resultFile.close()
文件,书名转为noteexpress形式,代码如下:
myFile=open("mybook.txt","r",encoding="utf-8")
data=myFile.read()
myFile.close()
noteE="""
{Reference Type}: Book
{Publisher}: 北京:中华书局
{Year}: 2007
"""
resultFile=open("resultNmae.txt","w",encoding="utf-8")
datalines=data.splitlines()
for everyline in datalines:
iline=everyline.split(".")
book=iline[1:-1][0][1:-1]
aut=iline[1:-1][1]
author=aut.replace(" ","")
print(noteE,end="",file=resultFile)
print("{Title}:", book,file=resultFile)
print("{Author}:",author,file=resultFile)
resultFile.close()
即可完成。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









