







本书的重点是在原则和设计选择方面对vis的一般基础进行广泛的综合,为技术的设计和分析提供一个框架,而不是实例化这些技术的算法。
第1章:介绍含义
第2章:是什么?data Abstraction
第3章:为什么?task Abstraction
第4章:如何?可视化编码和交互技术
第5章:介绍编码信息的标记和通道的原理
第6章:介绍了8条设计经验法则
第7章用于表,第8章用于空间数据,第9章用于网络。
第10章继续介绍视觉编码中映射颜色和其他通道的选择
第11章讨论了操作和更改视图的方法
第12章介绍了在多个视图之间建立数据facet的方法
第13章介绍如何减少每个视图中显示的数据量的选择
第14章介绍了在概述数据上下文中嵌入关于焦点集的信息
第15章用6个案例研究详细分析了完整的框架来结束本书
1 What's Vis, and Why Do it?
可视化适合用来增强人的能力而不是用于计算决策从而取代人。可视化设计充满了权衡,设计空间中的大多数可能性对特定任务无效,因此验证设计的有效性是必要的,也是困难的。Vis设计者必须考虑到三种非常不同的资源限制:计算机的、人的和显示的。
1.1 人类参与的原因?
针对特定的现实世界领域问题设计可视化工具的结果通常是对用户任务的更清晰的理解,除了工具本身。数据可视化和机器学习不同,可视化系统的目的往往是帮助人们更好的进行决策或者后续的分析,所以我们可以制作短期或者长期的可视化工具用来呈现数据或者动态的监视。
1.2 计算机参与的原因?
我们可以通过计算来构建工具,进而探索大量数据的奥秘,实现这个目的靠手工绘制基本不可能,所以需要计算机。
1.3 为什么用外部表示?
本书的外部表示重点是用电脑屏幕可视化数据,正如我们生活中可以触摸的东西,视觉可以让人们将内部认知和记忆的使用转移到感知系统。一种很好的方法就是使用图表,图表作为外部记忆的优点是,信息可以按空间位置组织,提供了加速搜索和识别的可能性。通过将特定问题解决推理所需的所有项分组到同一位置,可以加快搜索速度。通过将同一位置的一件物品的所有相关信息分组,避免了匹配已记住的符号标签的需要,也可以促进识别。然而,非最优图可能将不相关的信息组合在一起,或支持对预期的解决问题过程没有用处的感知推断。
1.4 为什么要依赖视觉?
因为我们可以使用视觉快速的从一堆信息中获取有效信息,比如从一堆灰色的图片中可以快速的发现红色移动的目标。而听觉就不同了,比如我们听到的声音是以声音流的方式,所以不能将长时间听到的声音合并在一起同步体验,这就是为什么超声波技术即使进行过很多次实验却依旧没有获得成功。味觉和嗅觉的感知通道还没有可行的记录和复制技术。触觉输入和反馈设备的存在是为了利用触觉和动觉感知通道,但它们只覆盖了我们所能感知的动态范围中非常有限的一部分。对它们在交流抽象信息方面的有效性的探索仍处于非常早期的阶段。
1.5 为什么要详细展示数据?
比如下面两张对比图:
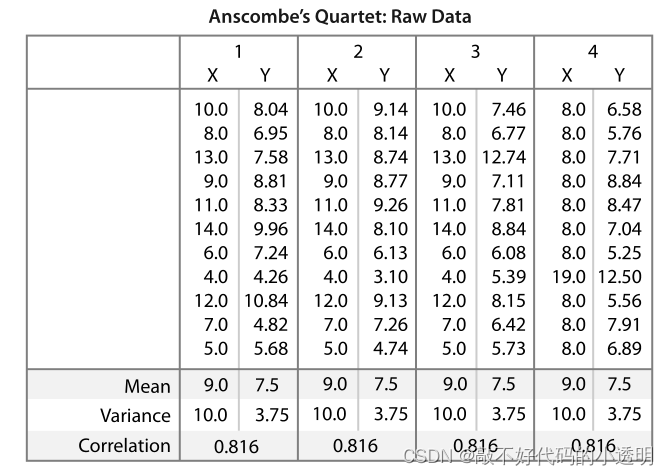 | 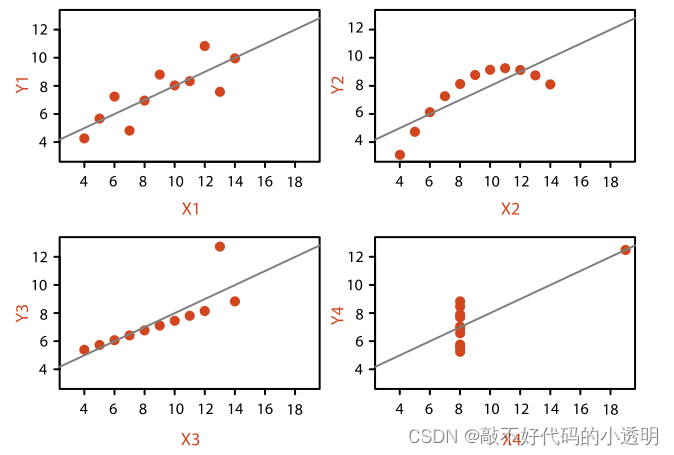 |
如果是第一张图片我们很难去比较四组数据的区别和各自特征,但是用第2张画图的形式就很容易对比他们的不同。当然为了更准确的描述数据的特征,太过简要的数据会导致数据的丢失,从而隐藏数据的真实结构。所以需要详细的显示数据~
1.6 为什么使用互动?
可以对比一下一张静态的地图图片和我们经常使用的高德地图软件,我们可以总览大区域的地图,也可以细致到一个街区一家店面,还可以根据我们的需要选择两个地点进行路线规划。交互性是实现了用户可以按照自己的需求查找或者是输入自己想获得的数据。
1.7 Why Is the Vis Idiom Design Space Huge?
因为如果仅仅用简单的图表展现数据会有很多方法,而将这些图表联系起来交互操作就会有很大的设计空间,而且复杂度也会上升。
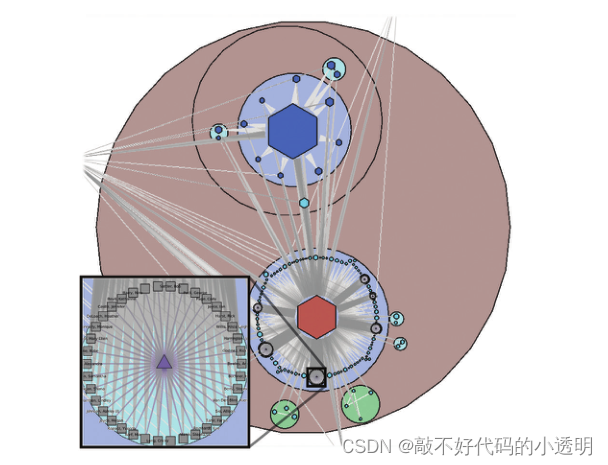
比如这张图展现的是电影《除了这里,一切都在》中出现的演员小团体的细节,并打开了名字标签。可以点击图标查看具体的信息(交互式操作),可设计空间很大。
1.8 为什么要关注于任务?
可视化可以做很多事情,比如可以支持信息的表示、发现或者享受。它还可以支持生成更多的信息以供后续使用。对于发现,比如在探索一个完全不熟悉的数据集时,vis可以用来生成新的假设,或者用来确认关于一些已经部分了解的数据集的现有假设。而一个可视化工具无法在数据集一样的情况下满足另一个服务。
1.9 为什么要关注效率?
对有效性的关注是定义vis的必然结果,以支持用户任务为目标。这一目标导致了对正确性、准确性和真实性的关注,它们在可视化中扮演着非常重要的角色。面对大量抽象的数据,可视化设计师需要在保证有效性的前提下对数据进行可视化。
1.10 为什么大多数设计是无效的?
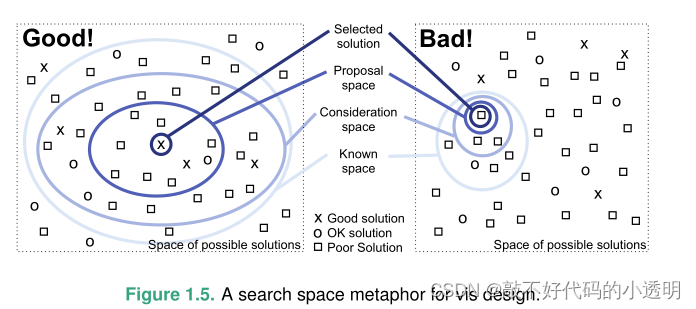
因为设计空间很大,而往往大多数设计选择是无效的。但是我们有一个设计原则是:考虑多个备选方案,然后选择最好的,而不是立即专注于一个解决方案而不考虑其他备选方案。确保考虑到不止一种可能性的一种方法是明确地并行生成多个想法。
图1.5对比了左侧的良好策略(已知和考虑的空间都很大)和右侧的糟糕策略(这些空间都很小)。考虑空间小的问题是只考虑ok或差的解决方案而遗漏了一个好的解决方案的较高概率。
可视化设计不能作为一个简单的优化过程来处理,因为权衡很多。一个在某方面表现良好的设计,在另一方面则表现不佳。可视化设计空间中权衡的表征是可视化研究前沿的一个非常开放的问题。
1.11 为什么验证很难?
因为很难确定判断一个可视化工具“好”或者“不好”的标准,需要考虑的问题有很多,比如:
对于目标用户,你如何判断一种设计比另一种更好或更差?
首先,更好是什么意思?
用户是否能更快地完成任务?
他们这样做更有乐趣吗?
他们能更有效地工作吗?
什么是有效的?
你如何衡量洞察力或敬业度?
这个设计比什么更好?
它比其他可视系统好吗?
它是否比在没有可视化支持的情况下手动完成相同的工作更好……
1.12 为什么会有资源限制?
在设计或分析可视化系统时,必须考虑至少三种不同的限制:计算能力、人的感知和认知能力以及显示能力。对计算机资源的可用性通常有软件和硬件的限制。
软件包括有计算机内存可供使用,因为用户可能会同时运行其他程序。
硬件包括要设计不适合核心内存的大数据集系统。
就人类而言,记忆和注意力是有限的资源。
显示容量也是一种资源限制,比如说屏幕分辨率不足以显示所有的信息。
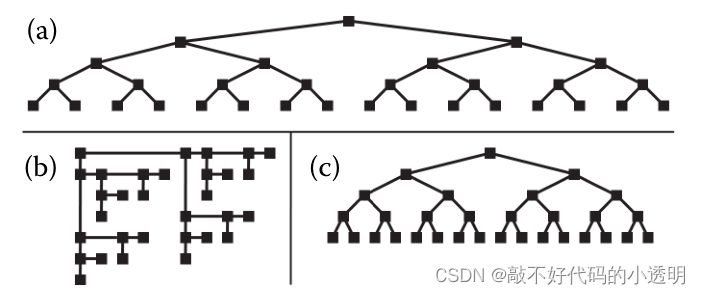
图1.6(a)中的布局用垂直空间位置编码了树中从根到叶的深度。但是,信息密度较低。相比之下,图1.6(b)的布局使用了相同大小的节点,但绘制得更紧凑,因此具有更高的信息密度;也就是说,每个节点的大小与显示整个树所需的面积之间的比例更大。然而,从空间位置不容易读出深度。图1.6(c)显示了一个非常好的替代方案,它结合了前两种方法的优点,既具有紧凑视图的高信息密度,又具有深度的位置编码。所以我们需要进行权衡,选择合适的可视化方案。
1.13 为什么要分析?
“分析现有系统是设计新系统的一个很好的垫脚石”。
我们可以遵循以下步骤:
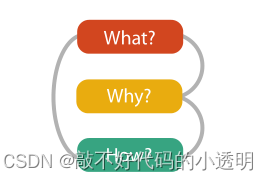
即为什么要执行可视化任务?——需要显示什么数据?——如何选择合适的可视化工具?通过分析可以让你明确目的以及使用的方法。
2 Data Abstraction
2.1 为什么数据语义和类型很重要?
数据的语义是其真实世界的含义。例如,一个单词是代表一个人的名字,还是一个公司名称的缩写,可以在外部列表中查找全名,还是一个城市,还是一种水果?一个数字是代表一个月中的某一天,还是一个年龄,或一种高度,或一个特定的人的唯一代码,或一个社区的邮政编码,还是空间中的一个位置?
数据的类型是它的结构或数学解释。在数据级别上,它是什么类型的东西:项、链接还是属性?在数据集级别,如何将这些数据类型组合成一个更大的结构:表、树、采样值字段?在属性级别,什么类型的数学操作对它有意义?例如,如果一个数字表示洗衣粉的盒数,那么它的类型就是一个数量,将两个这样的数字相加是有意义的。如果数字表示邮政编码,那么它的类型是代码而不是数量——它只是一个类别的名称,恰好是一个数字而不是文本名称。这两个数字相加没有意义。
总之,数据类型和语义帮助我们分析数据并对数据进行正确的操作。
2.2 数据类型

2.3 数据集类型
数据集是一些基本数据类型的组合。
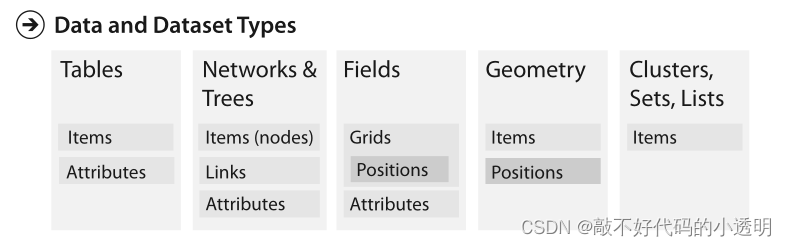
无论是简单的平面情况还是更复杂的多维情况,表都有按项和属性索引的单元格。在网络中,项目通常被称为节点,它们由链接连接;网络的一个特例是树。
连续字段的网格基于单元格中包含属性的空间位置。空间几何只有位置信息。
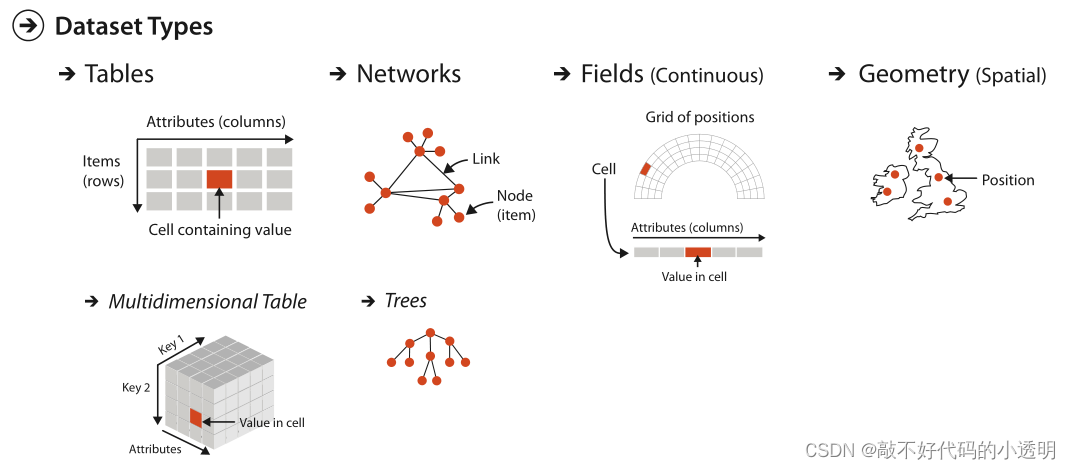
2.3.1 表
对于一个简单的平面表,行代表项目,列表示属性。多维表有一个更复杂的结构,用于索引到单元格中,具有多个键。
2.3.2 网络和树
网络的同义词是图。“图”这个词在视觉上也有很深的含义。有时它被用来表示网络,例如在视觉的子领域叫做“图绘制”或数学的子领域叫做“图论”。有时它在统计图形学领域用于表示图表,如柱状图和线形图。
网络的数据集类型非常适合于指定两个或多个项目之间存在某种关系。
树是网络的一种特例,没有循环,严格定义了父辈、子辈和祖先间的关系。
2.3.3 字段
连续数据通常以空间场的形式出现,其中场的单元结构基于在空间位置上的采样。例如,使用由医疗成像仪器生成的空间场数据集,用户的任务可能是定位可通过独特的形状或密度识别的可疑肿瘤。视觉编码的一个明显选择是显示一些空间上看起来像人体x光图像的东西,并使用颜色编码来突出显示可疑的肿瘤。另一个例子是在一个真实或模拟的风洞中测量在三维空间中流经飞机机翼的空气的温度和压力,其任务是比较不同区域的流动模式。一种可能的视觉编码将使用机翼的几何形状作为空间基底,使用大小编码的箭头显示温度和压力。
拥有空间字段数据的用户可能面临的任务限制了在设计可视化编码习惯用法时关于空间使用的许多选择。许多非空间数据的选择在这种情况下是不合适的,因为数据集没有提供关于空间位置的信息。
当一个字段包含通过完全规则间隔采样创建的数据时,单元格将形成一个统一的网格。
2.3.4 几何
几何数据集类型指定关于具有显式空间位置的项的形状的信息。这些项目可以是点、一维线或曲线、2D曲面或区域或3D体。几何数据有时单独显示,特别是当形状理解是主要任务时。在其他情况下,它是附加信息的背景。

2.4 属性类型
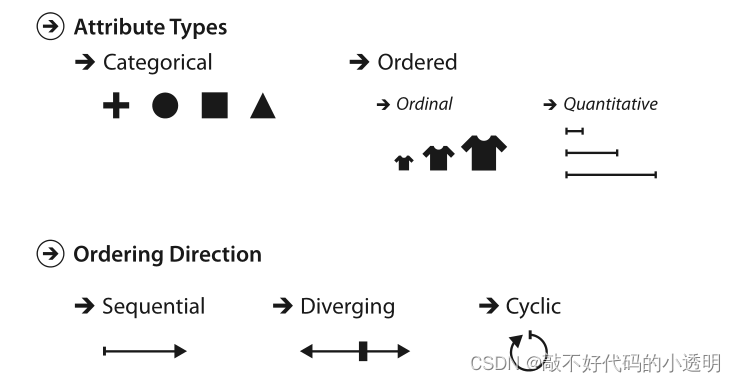
属性类型有类别的、顺序的或定量的。属性排序的方向可以是顺序的、发散的或循环的。
在有序类型中还有序数和定量的进一步区别。有序数据可能是从最小值到最大值的顺序范围,或者可能从范围中间的零点向两个方向发散,或者值可能在一个循环中环绕。
类别的属性(Categorical)是一种分类型的数据,比如最喜欢的水果、喜欢看的书、喜欢的城市等。
有序数据表示数据含有隐式顺序,比如衬衫的大小,我们可以明确的认为中号是位于小号和大号之间的,但是大号减小号显然没有意义,而那些可以进行加减的数据称为定量数据,定量数据是有序数据的一个子集。
有序数据可以是连续的(从最小值到最大值有一个齐次范围),也可以是发散的(可以分解为两个指向相反方向的序列,它们在一个共同的零点相遇)。比如测量水深数据是表示从水底到水平面的距离,是连续的;而测量海拔是测量海平面到陆地以及海平面到海底之和,是发散的。
层次结构:比如说身份证号每个人都不同,但是前几位代表了省份地市,一个身份证号是有层次结构的。
2.5 语义
对于平面表来说,键可以回忆一下数据库中对键的定义。尽管字段与表有本质的不同,因为字段表示连续数据而不是离散数据,但键和值仍然是主要关注点。
3D向量场的一个具体例子是房间中空气在特定时间点的速度,其中每个项目都有方向和速度。场的维数决定了方向向量中分量的数量;它的长度可以直接从这些分量计算,使用标准的欧氏距离公式。
张量场在每个点上都有一个属性数组,代表了比向量中的数字列表更复杂的多元数学结构。一个物理例子是应力,在三维场中,它可以由9个数字定义,代表作用在三个正交方向上的力。几何直觉是,张量场中每一点的全部信息不能仅用一个箭头表示,而需要一个更复杂的形状,如椭球。
时变数据:数据值会随时间变化,包括增加或者删除等操作
3 Task Abstraction
3.1 为什么要抽象的分析任务?
意思是把问题/任务抽象出一个框架,而不是针对某个特定的领域。
将任务描述从特定于领域的语言转换为抽象形式允许您推理它们之间的相似点和不同点。人们努力将特定领域的术语翻译成通用的词汇,尽可能帮助人们分析不同问题之间的联系。从而使同一个vis工具可以用于许多不同的目标。
通常一次只考虑用户的一个目标是有用的,以便更容易地考虑特定的习惯用法如何支持该目标的问题。为了描述复杂的活动,你可以指定一个链式的任务序列,其中一个任务的输出成为下一个任务的输入。分析该任务的另一个重要原因是了解是否以及如何通过派生新数据将用户的原始数据转换为不同的形式。也就是说,任务抽象能够并且应该指导数据抽象。
专门的vis工具是为具有狭窄数据配置范围的特定上下文设计的,相比之下,通用的vis工具被设计为以灵活的方式处理广泛的数据,例如,接受任何特定类型的数据集作为输入:表,或字段,或网络。一些特别宽泛的工具可以处理多种数据集类型,例如,支持表和网络之间的转换。总之就是权力越大,任务越重。
3.2 Actions
目前的目标是指使用vis进行信息的简洁交流,用数据讲故事,或引导观众进行一系列认知操作。使用可视化的演示可能发生在决策、计划、预测和教学过程的上下文中。关于当前目标的关键一点是,vis被某人用来向观众传达一些具体的、已经理解的东西。
在某些情况下,派生属性编码与原始属性相同的数据,但类型发生了变化。如表示温度的浮点数,当决定水的温度是否适合淋浴,该定量属性可能被转换为一个新的派生属性,其顺序为:热、暖或冷。
Search搜索分类有四种类型:
①lookup——查找
如果用户已经知道他们要查找的内容和位置,那么搜索类型就是简单的查找。
②Locate——定位
为了在一个未知的位置找到一个已知的目标,搜索类型是locate:即找出特定的目标在哪里。
③Browse——浏览
知道位置,但是不知道目标身份。它可能是基于特征来指定的。在这种情况下,用户正在搜索符合某种规格的一个或多个项目,例如与特定的属性值范围相匹配。当用户不确切知道他们在找什么,但他们确实在脑海中有一个位置来寻找它时,搜索类型是browse。
④Explor——探索
既不知道目标也不知道位置。例子包括在散点图中搜索异常值,在时间序列数据的线形图中搜索异常峰值或周期模式,或在choropleth图中搜索意料之外的空间依赖模式。
Query有三种类型:identify、compare、summarize
理解趋势、异常值、分布和相关性等抽象任务是使用可视化的最常见原因。
网络数据的基本目标是了解这些相互连接的结构;也就是网络的拓扑结构。更具体的拓扑目标是连接两个节点的一条或多条链路的路径。对于空间数据,理解和比较几何形状是用户操作的共同目标。
4 Four leves for validation(验证)
可见设计的四个嵌套层次在每个层次上对有效性有不同的威胁,因此应该相应地选择验证方法。

4.1 为什么要验证
因为可视化设计空间很大,大多数是无效的,所以从设计一开始就考虑如何验证是必要的。而且我们很难去确定可视化的目标,因为让用户自己精确的描述往往也不是很靠谱~
在人机交互文献中,与特定的目标受众密切合作以迭代地改进设计被称为以用户为中心的设计或以人为中心的设计。
Task and Data Abstraction是需要将特定领域的问题抽象成通用的表达。来自非常不同的领域情况的问题可以映射到相同的抽象vis任务。抽象任务的例子包括浏览、比较和总结。
四个级别上都需要进行验证,以及它们可能出现的问题是不同的。比如:
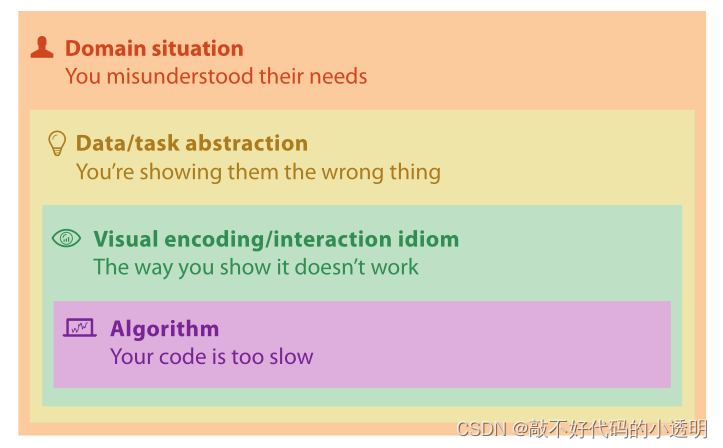
①Domain Validation
主要的威胁是错误地描述了问题:目标用户实际上没有这些问题。验证的一种直接形式是采访和观察目标受众来验证描述,而不是依赖于假设或猜测。这种情况的常用方法是实地研究,即调查人员观察人们在现实环境中的行为,而不是将他们带到实验室环境中。是否需要验证也可以通过目标用户对该可视化工具的采用率体现,但是不是绝对的。
②Abstraction Validation
在抽象层,威胁是识别的任务抽象块和设计的数据抽象块不能解决目标受众的特征问题。针对这种威胁的验证的关键方面是,系统必须由目标用户进行自己的工作来测试,而不是执行vis系统设计者指定的抽象任务。
③Idiom Validation
在可视化编码和交互习惯用语级别,威胁在于所选择的习惯用语不能有效地将所需的抽象传达给使用系统的人。一种直接的验证方法是根据已知的感知和认知原则仔细论证习语的设计。
测量评估有定量和定性两种,定量包括收集研究参与者花费的时间和所犯错误的客观测量值、通过vis工具记录操作,如鼠标移动和点击,或使用外部设备跟踪参与者的眼球运动。定性数据收集通常包括要求参与者通过问卷对他们的策略进行反思。
④Algorithm Validation
在算法层面,主要的威胁是该算法在时间或内存性能方面是次优的。显然,如果用户期望系统在毫秒内响应,但操作却需要数小时或数天,那么较差的时间性能就是一个问题。验证的一种直接形式是使用计算机科学文献中的标准方法分析算法的计算复杂度。虽然许多设计人员根据数据集中项目的数量来分析算法复杂性,但在某些情况下,考虑显示中的像素数量更合适。
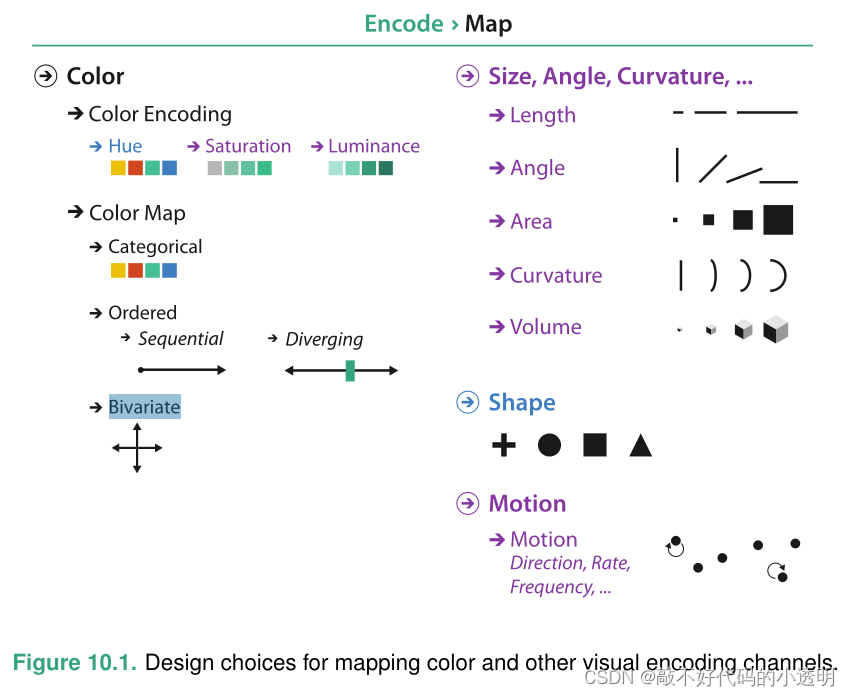
5 Marks and Channels
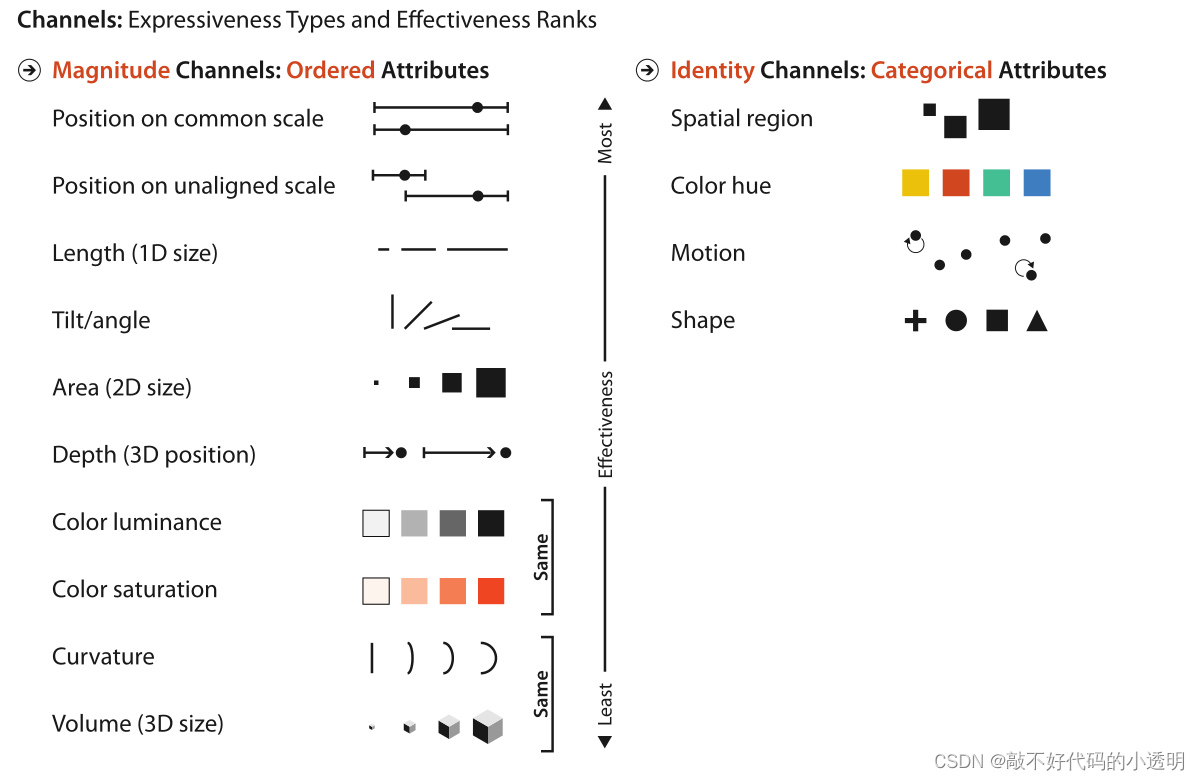
学习对标记和通道进行推理,为分析可视编码提供了基础。视觉编码设计空间的核心可以描述为两个方面的正交组合:被称为标记的图形元素和控制其外观的视觉通道。即使是复杂的视觉编码也可以分解成可以根据其标记和通道结构进行分析的组件。
标记是图像中的基本图形元素。标记是根据所需空间维度的数量分类的几何原始对象。图5.2显示了一些例子:零维(0D)标记是一个点,一维(1D)标记是一条线,二维(2D)标记是一个区域。可以使用三维(3D)体积标记,但不经常使用。

视觉通道是一种控制标记外观的方法,与几何原语的维度无关。图5.3显示了可以将信息编码为标记属性的许多可视通道中的一些。
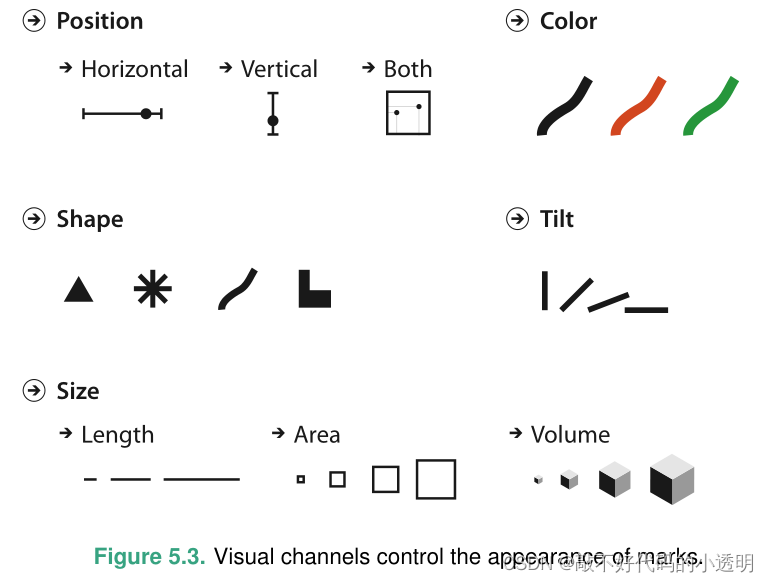
人类的感知系统有两种基本不同的感觉模式。身份通道告诉我们关于某物是什么或它在哪里的信息。相反,大小通道告诉我们某物有多少。
标记可以表示单个项目或它们之间的链接:

视觉编码中有两个原则指导视觉通道的使用:表达性和有效性。表达性原则规定视觉编码应该表达数据集属性中的所有且仅是其中的信息。有效性是指:最重要的属性应该用最有效的通道进行编码。
视觉通道在有序数据和分类数据两个方面的有效性排序:
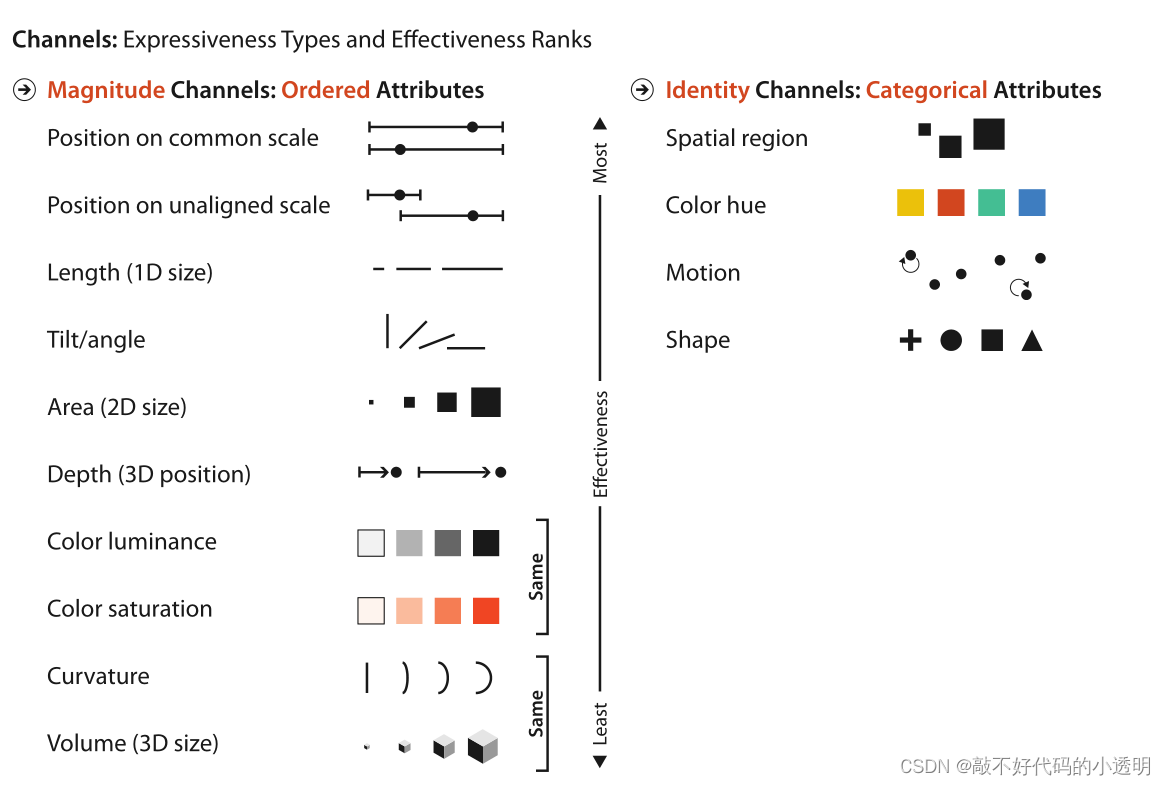
选择哪些属性用位置编码是视觉编码中最核心的选择。接下来将通过根据准确性、可辨别性、可分离性、提供视觉弹出的能力和提供感知分组的能力等标准对通道进行分析,以及为什么按照上图进行排序。
①准确度
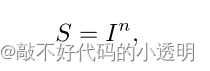
研究表明人们对量级的感知都遵循幂法则,如上公式。S是感知的感觉,I是身体强度。幂律指数n的范围从0.5的次线性亮度到3.5的超线性电流。其中一些感觉与它们的客观强度相比感知被放大(当n > 1时),一些感觉被压缩(当n < 1时)。长度感知是完全准确的,而面积感知是压缩的,饱和度感知是放大的。
精确度问题的另一组答案来自对照实验,这些实验直接映射了人类对视觉编码抽象信息的反应,为我们提供了每种通道类型的知觉精确度的明确排名。
②可辩别性
如果您使用特定的视觉通道编码数据,项目之间的差异是否能被人类所感知?例如,有些通道的容器数量非常有限。考虑行宽:更改行宽只适用于相当少量的步骤。增加宽度超过该限制将导致标记被视为多边形区域而不是线标记。如果要编码的值的数量也很少,那么少量的容器也不是问题。
人的知觉系统从根本上是建立在相对判断上的,而不是绝对的判断;这个原则就是韦伯定律。
6 八条经验法则

透视失真可以理解为近大远小。

很多情况下,使用3D技术对抽象数据可视化是不可取的。实验证据表明,3D界面更适合形状理解,而2D界面最适合相对位置任务:那些需要判断物体之间精确距离和角度的任务。大多数涉及抽象数据的任务无法从3D中获益。研究结果表明,在搜索和点估计任务中,点远远优于景观,在景观情况下,2D景观优于3D景观。
动画在用于两个数据集配置之间的转换时非常强大,因为它帮助用户维护上下文。有相当多的证据表明动画过渡可能比跳跃剪切更有效,因为它们帮助人们跟踪物体位置或摄像机视点的变化。当只有少数东西发生变化时,过渡是最有用的;如果在帧之间变化的对象数量很大,人们将很难跟踪所有发生的事情。我们对图像中不是我们关注焦点的区域的变化视而不见。
对于需要在多个帧之间进行详细比较的任务,同时看到所有帧可能比动画更有效。帧的数量必须足够小,以便能够识别每个帧中的细节,因此这种方法通常适用于当前显示分辨率下的数十帧而不是数百帧。动作也应该被分割成有意义的块,而不是随机选择的关键帧。许多使用多个视图的可视化习惯用法利用了这一点,特别是小的倍数。当我们的注意力不集中时,我们对变化是盲目的。在多帧动画中跟踪复杂和广泛的变化的难度是vis的变化盲目性的含义之一。
对于非空间的抽象数据,浸入式是非常必要的。使用3D对抽象数据进行可视化编码是一种不常见的情况,需要仔细论证。
交互性既有力量也有成本。交互的好处是,人们可以探索比单一静态图像更大的信息空间。然而,交互的成本是它需要人类的时间和注意力。如果用户必须彻底检查每一种可能性,vis系统的使用可能会退化为人工搜索。
7 Arrange Tables
散点图的习惯用法使用垂直和水平空间位置通道编码两个定量值变量,标记类型必须是一个点。
散点图对于提供概览和描述分布的抽象任务是有效的,特别是对于发现异常值和极值。散点图对于判断两个属性之间相关性的抽象任务也非常有效。尺寸编码散点图有时称为气泡图。
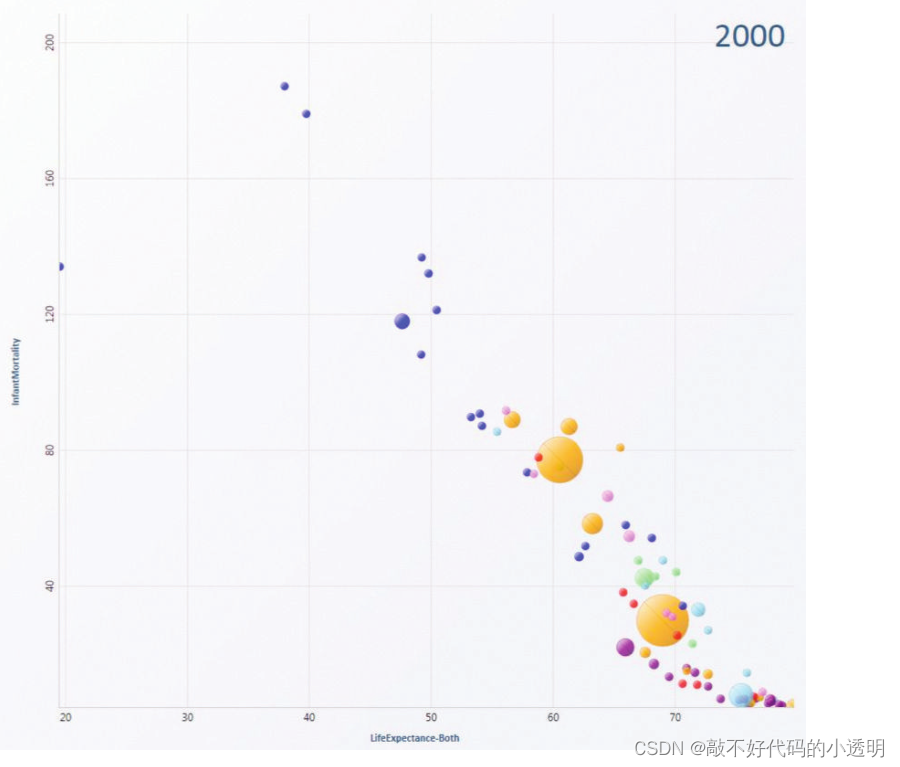
what——why——how的使用实例:
①散点图:

②柱状图

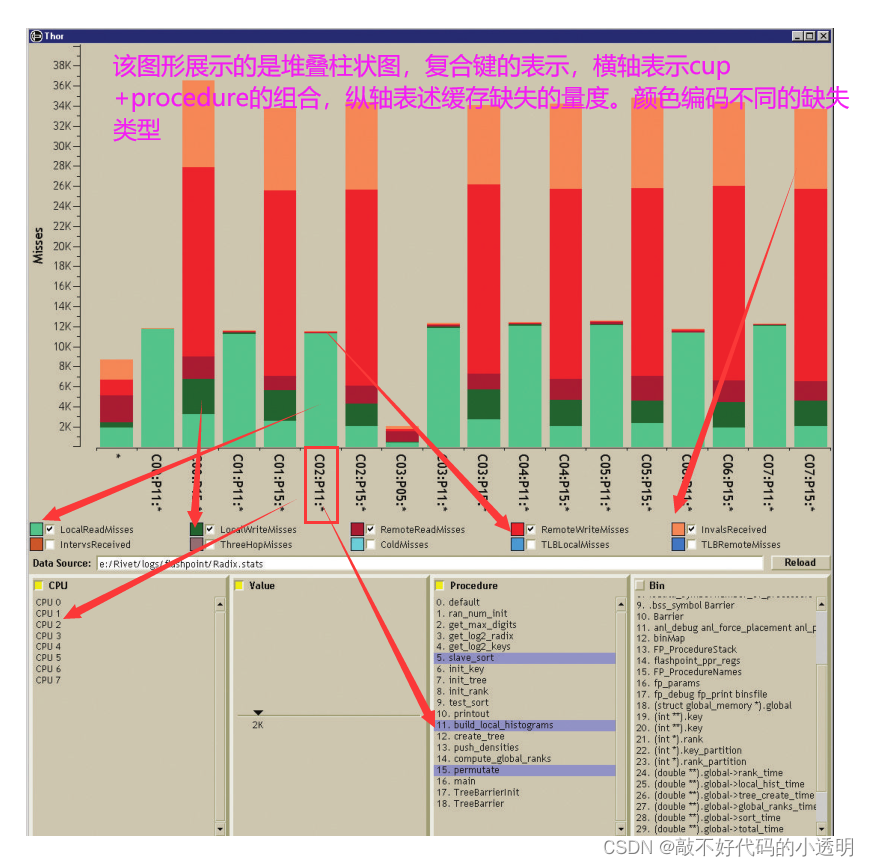
③堆叠柱状图
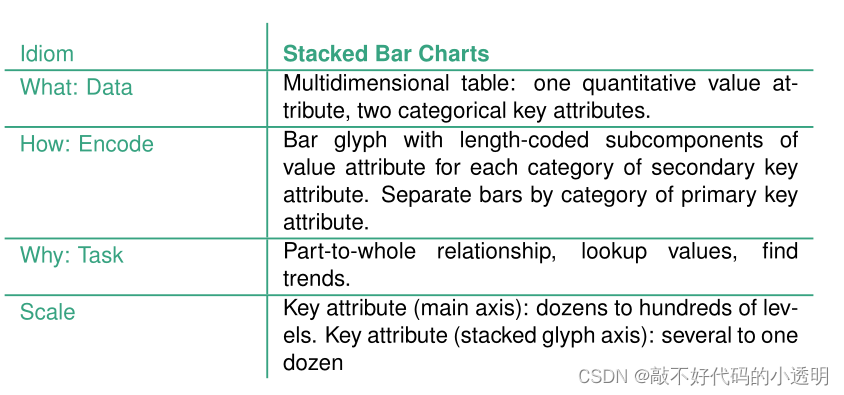
④streamgraphs
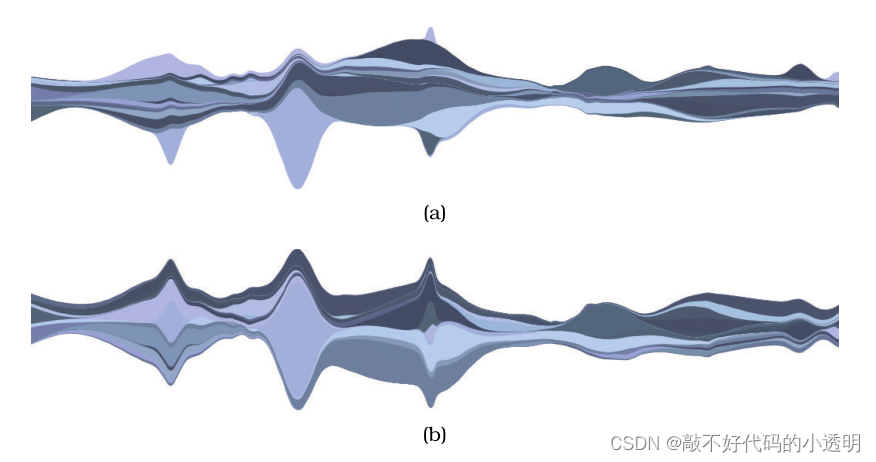 |  |
比如可以用这种绘图方法表示一些艺术家的作品在某段时间受欢迎程度的波动情况,即使主轴(time)跨度时间很长也没问题,scale如上图。
⑤Dot and Line Charts
一种看待点图的方法是像散点图一样,其中一个轴显示类别属性,而不是两个轴都显示数量属性。另一种理解点图的方式是像柱状图一样,其中数量属性是用点标记而不是线标记编码的;这种方法更符合它的标准用法。
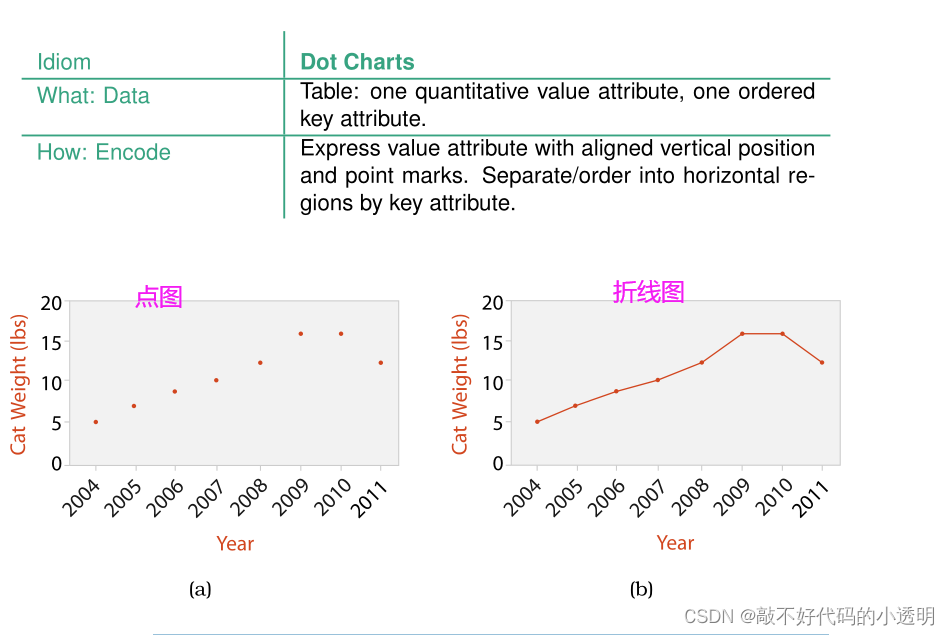

总之,点图、线图和柱状图都显示一个值属性一个键属性在直线空间中的布局。如果想要添加其他属性可以选择其他视觉通道来增强,比如颜色和大小等。线图对发现数据趋势尤其有效。
使用线图的时候要注意考虑其纵横比。最好将线段倾斜角度落到45°附近更方便我们判断,因为人们容易区分45°和43°的区别,却不容易区分20°和22°。
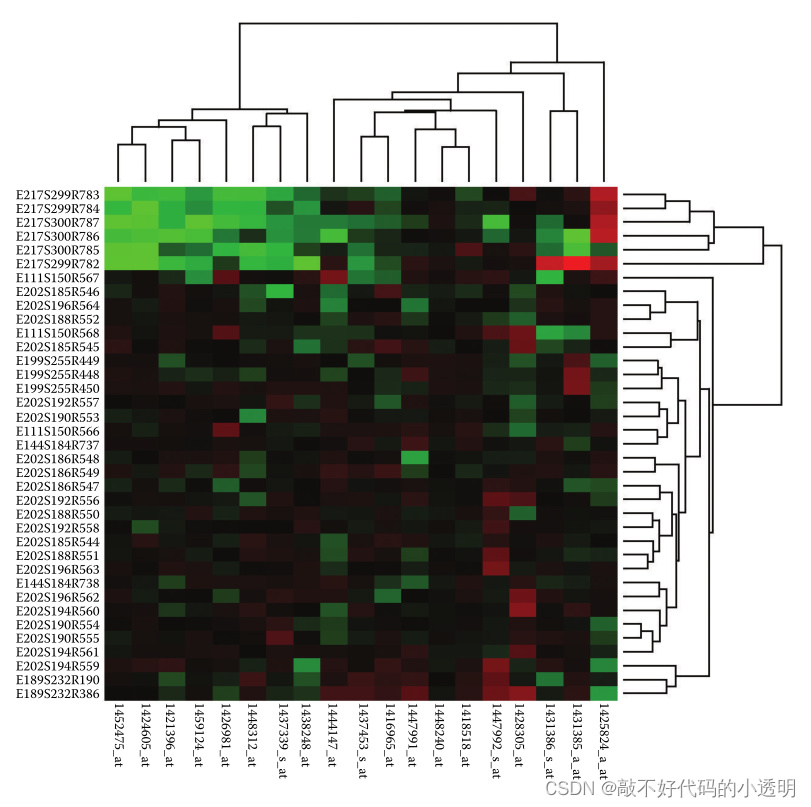
⑥heatmaps
在基因组学领域通常用不同的红——绿色表示定量的属性值,这是一个公约。
一个集群热图是一个热图和两个树状图的并置组合,显示在重新排序中使用的集群层次结构的派生数据。集群层次结构封装了集群算法迭代操作的完整历史。每个叶表示单个项目的集群;内部节点根据相似度记录集群合并的顺序,根节点表示所有项目的单个集群。树状图是一种可视化的树数据编码,树叶对齐,以便于比较内部树枝的高度。矩阵视图的行和列使用的最终顺序是通过遍历树中的叶来确定的。
 |  |
⑦散点图矩阵
陈为说《数据可视化》12.3节
在实践中,SPLOMs(散点图矩阵)通常更容易用于查找相关性的任务。并行坐标更多地用于其他任务,包括对所有属性的概述、查找单个属性的范围、选择项目的范围以及异常值检测。
基本的并行坐标习惯用法可以扩展到显示数百项,而不是数千项。如果过多地绘制过多的线,则会发生遮挡导致产生的信息非常少。
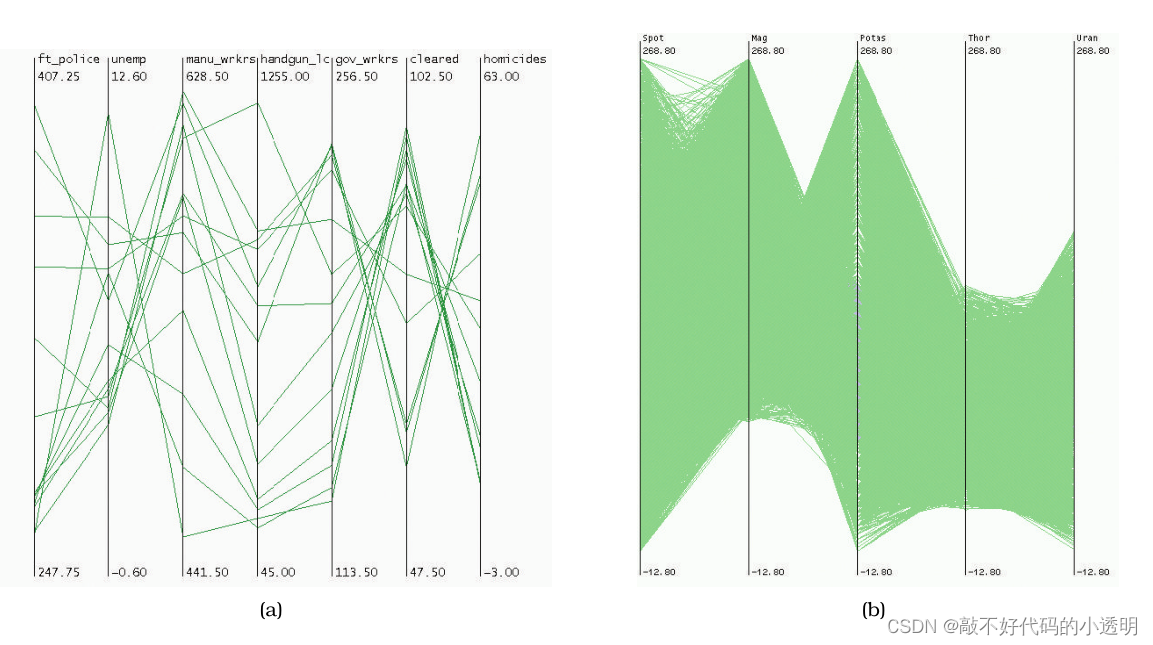
平行坐标的极限是如何确定坐标轴的顺序。大多数实现都允许用户以交互方式对坐标轴重新排序。然而,通过系统的手动交互来探索所有可能的轴的配置将是非常耗时的,因为轴的数量会增长,因为可能的组合数量会爆炸。
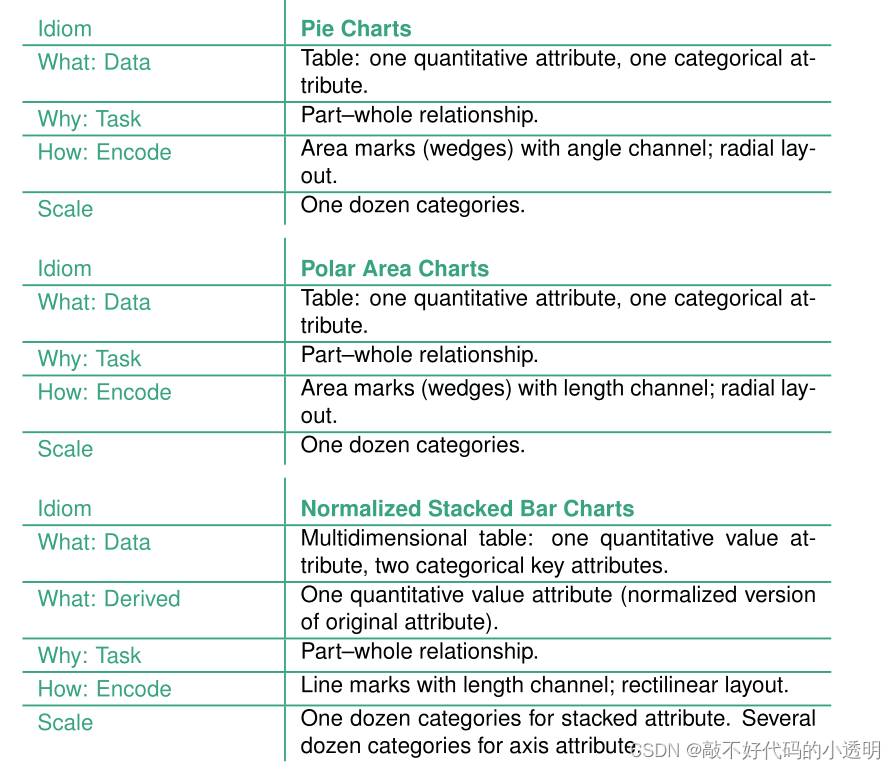
⑧饼图、堆叠柱状图和极面积地图
还有一些绘制图形数据的方法,其中极面积图的同义词是玫瑰图和鸡冠图。
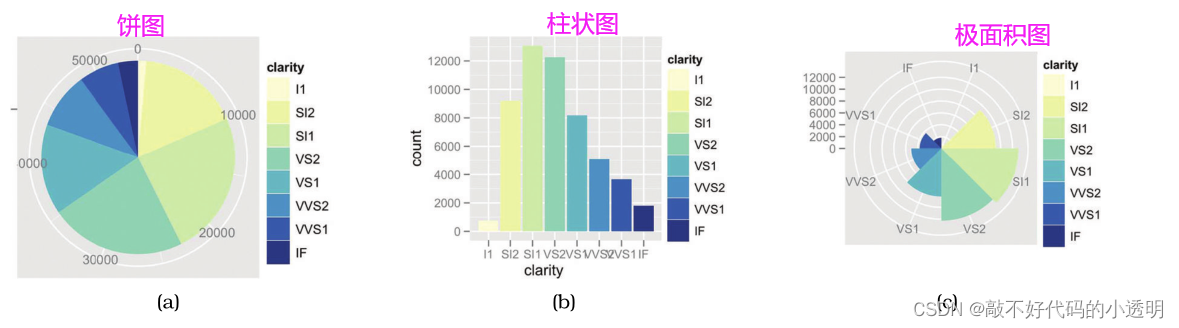
若要考察部分对整体的贡献可以选择下图的方式:
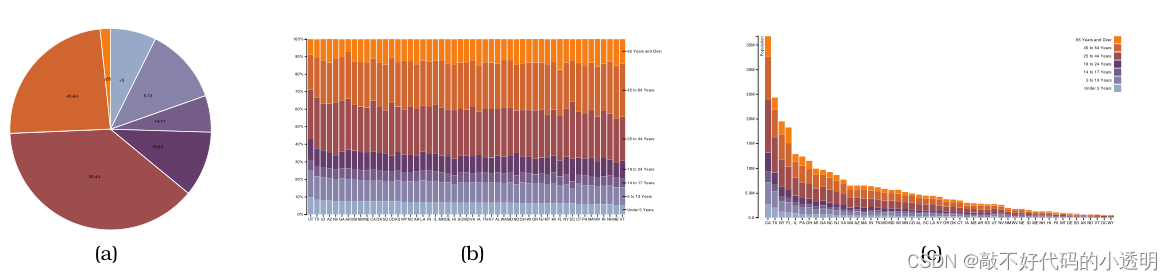
上将单个饼图与标准化堆叠柱状图和所有50个州的堆叠柱状图进行了比较。一个完整的饼图对应于这些图表(b)中的一个柱状图。
饼图和标准化堆叠柱状图都只能显示少量的类别,最多只能显示大约12个类别。
7.2 spatial layout density
①dense software

8 Arrange Spatial Data
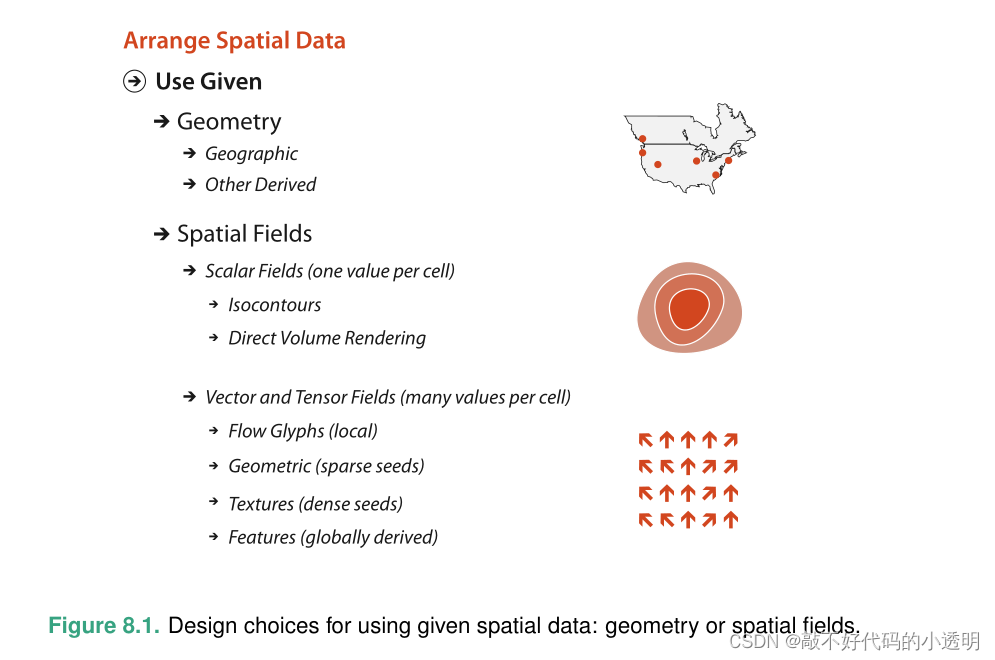
空间数据的常见情况是,给定的空间位置是最重要的属性,因为中心任务围绕着理解空间关系。所以在后续选择视觉编码时就不要使用空间位置通道对带有标记的其他属性进行视觉编码。
8.1 Geometry
①Choropleth Maps(显示的是截止到2016年8月美国的失业率)
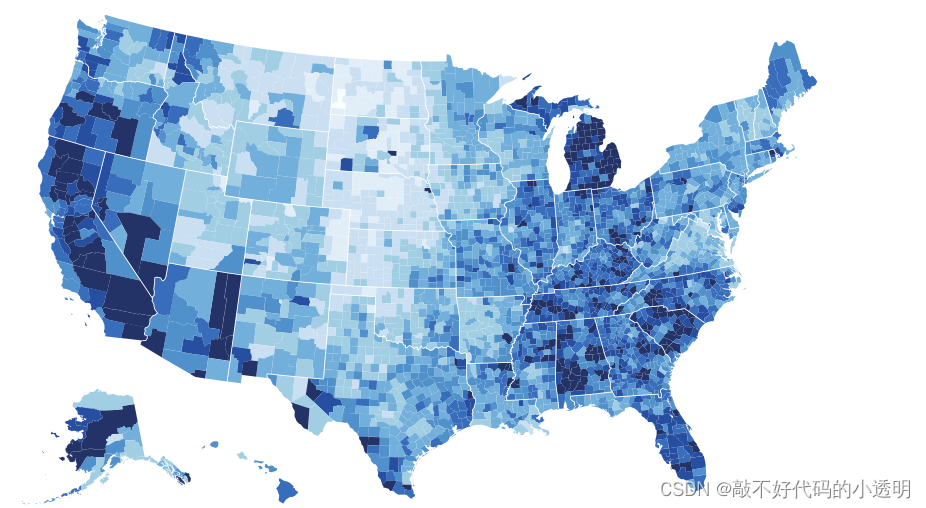
上面地图显示了以颜色编码的数量属性,覆盖了以区域标记分隔的区域,其中每个区域的形状是通过使用给定的几何图形确定的。区域形状可以直接作为基础数据集提供,也可以根据制图泛化选择从基础数据派生。

8.2 Spatial Fields
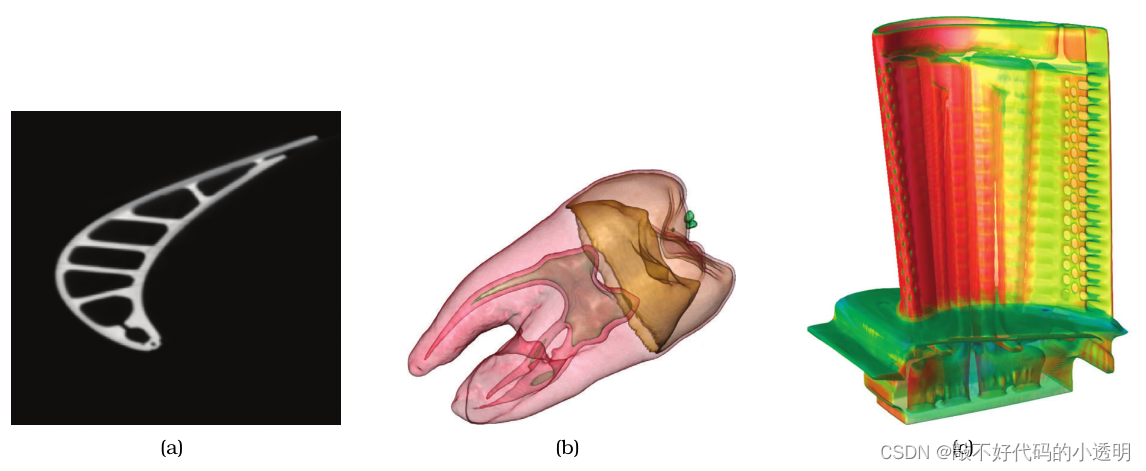
可视化编码标量字段的习惯用法主要有三大类:切片,如图(a)所示;等等值线,如图(b)所示;和直接体绘制,如图(c)所示。使用等值线习惯用法,可以计算低维曲面几何的导出数据,然后使用标准的计算机图形技术显示:通常情况下,对于3D场是二维等值线,对于2D场是一维等值线。
8.2.1 Isocontours
在缓慢变化的区域,等值线会出现在很远的地方,而在快速变化的区域,等值线会靠近,但永远不会重叠;因此,许多不同值的轮廓可以同时显示,而没有过多的视觉混乱。用连续的颜色图对等高线之间的区域进行颜色编码,得到等高线图。
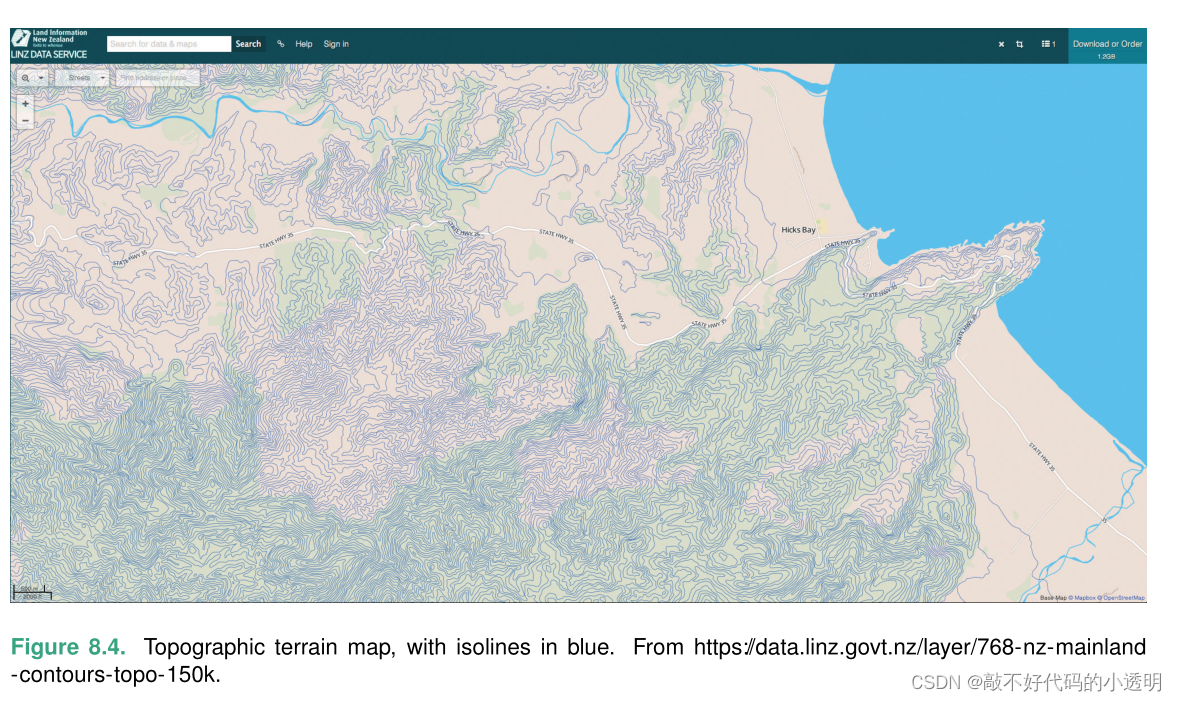
例如:Topographic Terrain Map(地形图)
 |  |

9 Arrange Networks and Trees
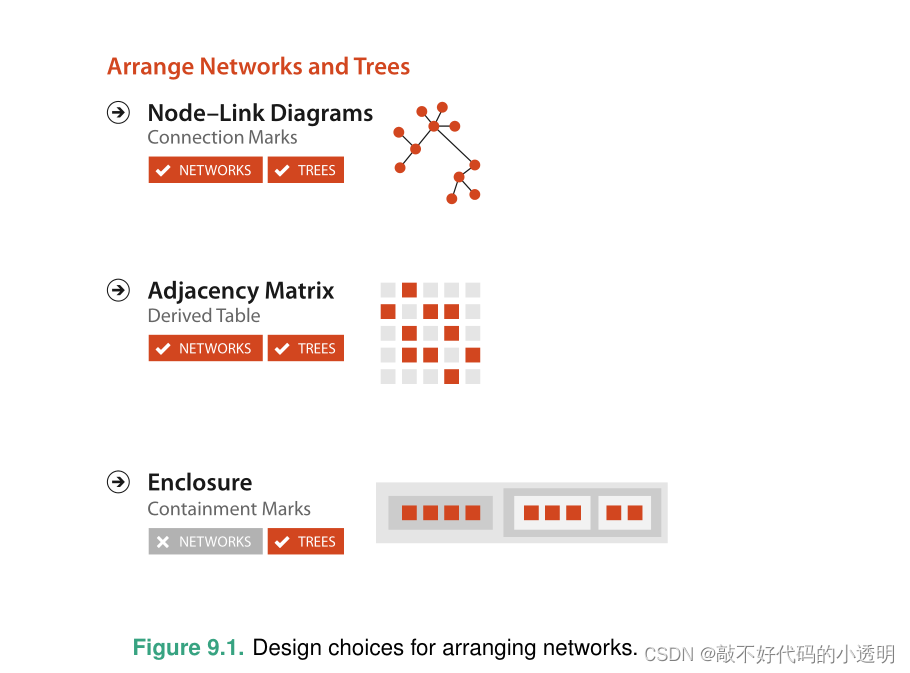
9.1 节点链接视图
节点链接法存在以下两种具体的模型:
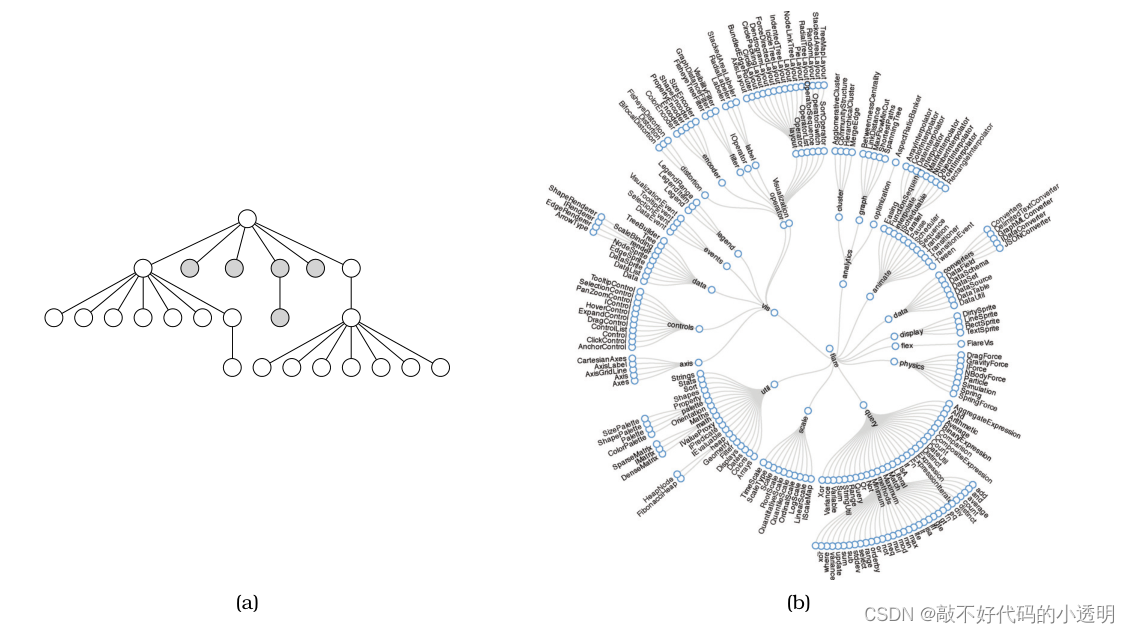
节点树还存在如下布局:

node-link network 的常使用的布局是 force-directed placement,如下示例:
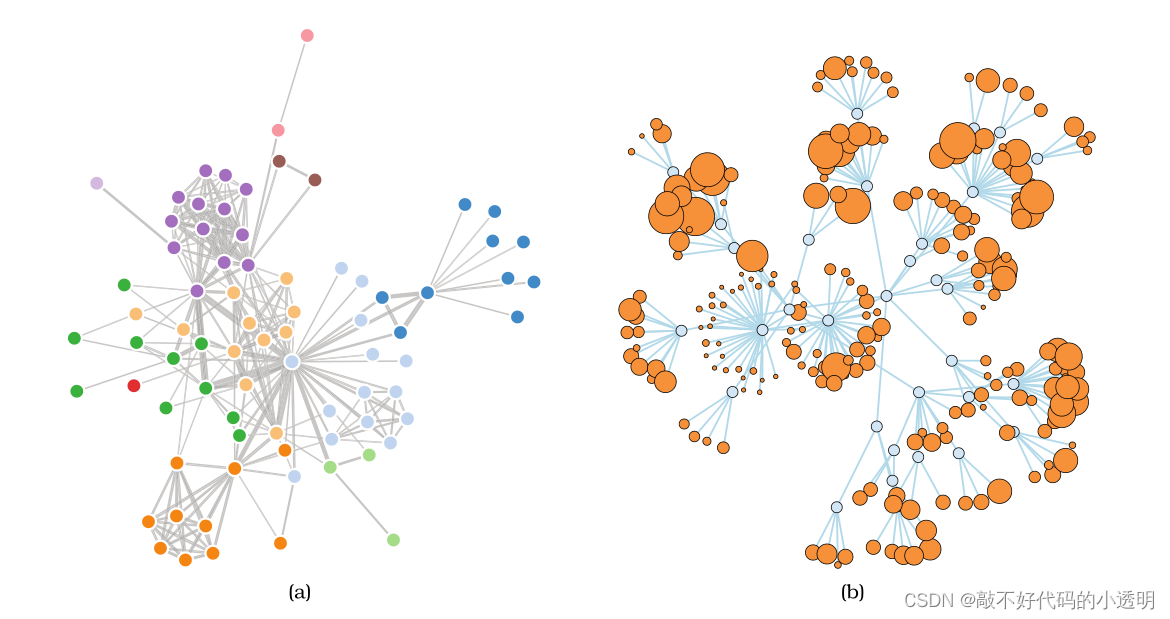
其中(a)使用了线宽编码,(b)使用了节点大小进行编码。空间位置并不编码节点之间的任何属性。有时候节点会因为过于密集(非故意,很可能由其他节点排斥所导致),会误导人们进行分组。
另外,这种布局方法在每次运行后都会产生不一样的空间布局,所以使用空间位置,比如“左上角什么”是不可取的。
这种布局的一个主要的缺点是——可伸缩性差。布局很快就会退化成一个视觉混乱的毛球,甚至只有几百个节点,在数千个节点或更多节点的情况下,路径跟踪或理解整体结构关系的任务变得非常困难,基本上是不可能的。当节点数量大约超过链接数量的四倍时,直接的力导向放置不太可能产生良好的结果。

9.2 邻接矩阵视图
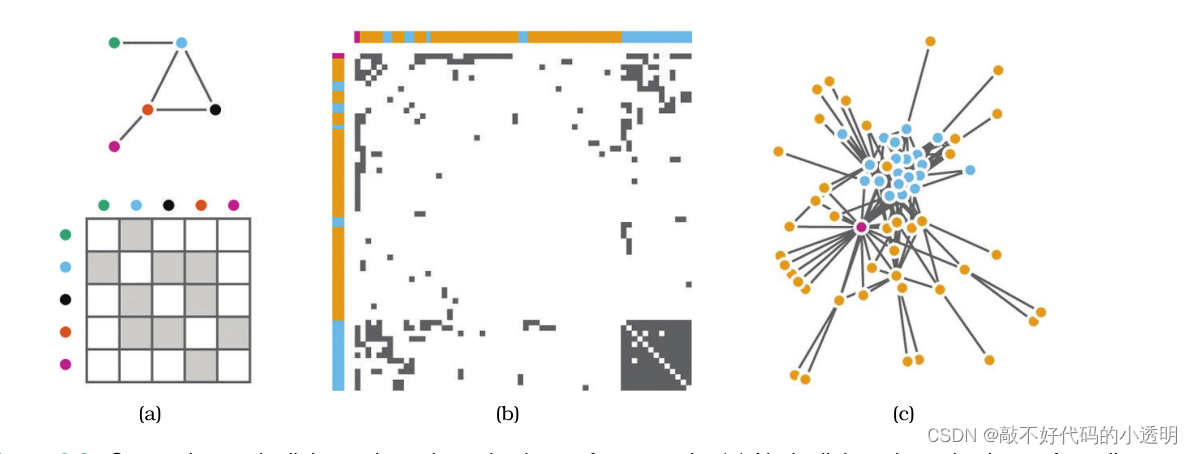
网络的矩阵视图可以达到非常高的信息密度,最多可以达到1000个节点和100万个边,就像集群热图和所有其他使用小区域标记的矩阵视图一样。

将网络可视化编码为节点-链接图,用连接标记表示节点之间的链接,这是迄今为止最流行的可视化网络和树的方法。
矩阵视图可以处理密集的图,其中边的数量是节点数量的平方。矩阵视图的另一个优点是可预测性、稳定性和对重排序的支持。矩阵视图还可以快速估计图中节点的数量,并通过快速节点查找直接支持搜索。
矩阵视图的一个主要缺点是不熟悉:大多数用户能够轻松地解释小型网络的节点-链接视图,而不需要训练,但他们通常需要训练来解释矩阵视图。矩阵视图最关键的弱点是它们缺乏对拓扑结构研究的支持,因为它们以比节点-链接图的直接连接更间接的方式显示链接。
研究发现,对于大多数研究任务,节点-链接视图最适合小型网络,而矩阵视图最适合大型网络。具体来说,对于节点-链接视图来说,随着大小的增加,有一些任务变得更加困难,而对于矩阵视图来说,难度与大小无关。

上图显示了树数据的七种不同的可视化编码习惯用法。
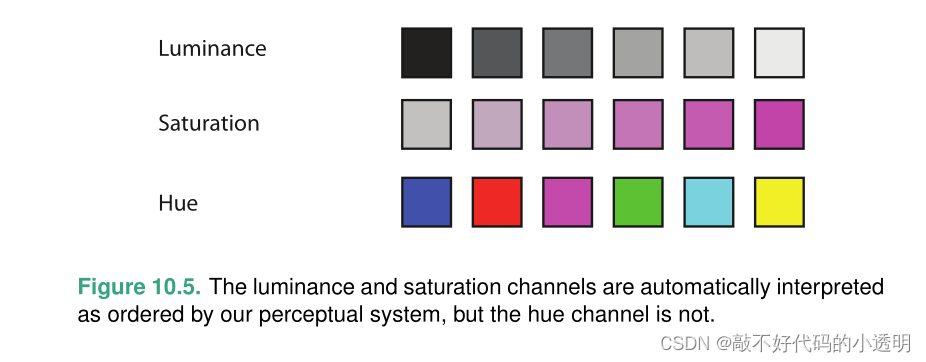
10 Map Color and Other Channels
存在两种色彩空间:①Red-Green-Blue,RGB ②hue–saturation–lightness ,HSL
HSL使用很流行,但是不是真正反应我们的颜色感知。因为我们的感知系统对不同波长的光线有不同的感知灵敏度。
hue is harder to distinguish in small regions than large regions.
在非连续区间也很难区分hue的差异。
透明度transparency:透明度不可以和亮度以及饱和度结合使用,但是必须和色相结合使用。不过色相不宜过多,否则难以区分。
高饱和度颜色适合小区域、低饱和度适合大区域,如果不连续的小区域使用过多颜色会造成视觉区分的负担,主要有两种方案应对这个问题:①过滤属性,减少属性数量采用可辩别颜色进行填充;②借助除颜色以外的其他通道进行辅助编码分类,比如尺寸、形状等。
Rainbow versus two-hue continuous colormap.Rainbow表现得较好,因为可以比较清晰得划分模糊得边界。
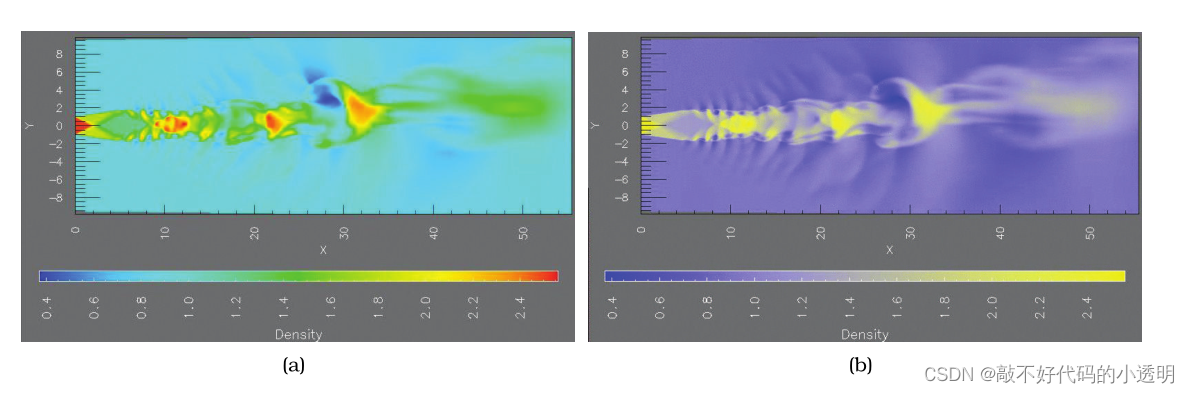
但是Rainbow在视觉感知上有三个严重的问题:①色调被用来表示顺序;②比例视觉感知上非线性;③用色调通道无法感知细微的细节。一个比较合适的解决方案是创建单调增加亮度色彩图。
彩虹并不总是坏的;分段彩虹色图是具有少量类别的类别数据的一个很好的选择。

从实用的角度来看,确保设计使用的颜色对于大多数用户来说是可区分的,最好的方法是使用色盲模拟器进行检查。
11 Manipulate View
持续更新中……
















 1485
1485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











