







 本文介绍了改进的灰狼优化算法(I-GWO),旨在解决全局优化和工程设计问题,特别是针对GWO算法的不足进行了改进,引入基于维度学习的狩猎(DLH)搜索策略,增强种群多样性并平衡局部和全局搜索。通过案例实现,包括目标函数定义、算法编写、结果获取和可视化,展示了I-GWO在实际问题中的应用。
本文介绍了改进的灰狼优化算法(I-GWO),旨在解决全局优化和工程设计问题,特别是针对GWO算法的不足进行了改进,引入基于维度学习的狩猎(DLH)搜索策略,增强种群多样性并平衡局部和全局搜索。通过案例实现,包括目标函数定义、算法编写、结果获取和可视化,展示了I-GWO在实际问题中的应用。
灰狼优化算法暂且不说了,本篇直奔改进的灰狼算法进行案例实践学习。
声明:即使订阅本专栏,也不可转载到它出,甚至商业用途。
一、简介
在论文中,论文作者提出了一种改进的灰狼优化器(I-GWO),用于解决全局优化和工程设计问题. 提出这一改进是为了缓解 GWO 算法缺乏种群多样性、开发和探索之间的不平衡以及过早收敛的问题。I-GWO 算法受益于一种新的运动策略,称为基于维度学习的狩猎 (DLH) 搜索策略,该策略继承自自然界中狼的个体狩猎行为。DLH 使用不同的方法为每只狼构建一个邻域,其中邻域信息可以在狼之间共享。DLH 搜索策略中使用的这种维度学习增强了局部和全局搜索之间的平衡并保持了多样性。
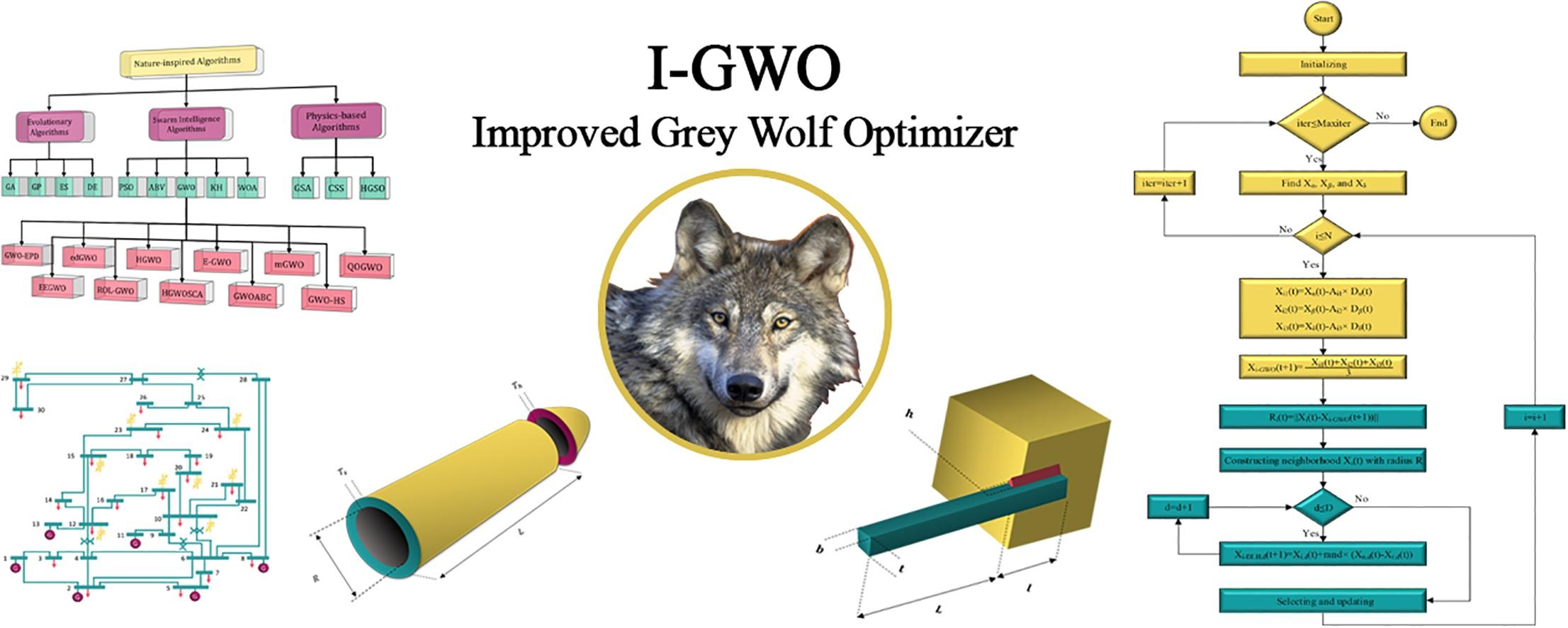
参考文献:
https://www.sciencedirect.com/science/article/abs/pii/S0957417420307107?via%3Dihub

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 526
526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











