







排序算法
1.准备
1.1算法模板
为了专注于算法本身,精简一些不必要的代码,专门创建一个抽象类Sort,实现Comparable接口,并在里面实现了比较大小,元素互换等常见操作,其他的具体排序的类都继承该抽象类,从而使代码的逻辑更加清晰。同时在此说明,本文排序按照升序处理。该类的具体代码如下:
public abstract class Sort<T extends Comparable<T>> implements Comparable<Sort<T>> {
protected T[] array;
private int cmpCount;
private int swapCount;
public void sort(T[] array) {
if (array == null || array.length < 2) {
return;
}
this.array = array;
sort();
}
@Override
public int compareTo(Sort<T> o) {
int result = (int)(time - o.time);
if (result != 0) {
return result;
}
result = cmpCount - o.cmpCount;
if (result != 0) {
return result;
}
return swapCount - o.swapCount;
}
protected abstract void sort();
/*
* 返回值等于0,代表 array[i1] == array[i2]
* 返回值小于0,代表 array[i1] < array[i2]
* 返回值大于0,代表 array[i1] > array[i2]
*/
protected int cmp(int i1, int i2) {
return array[i1].compareTo(array[i2]);
}
protected int cmp(T v1, T v2) {
return v1.compareTo(v2);
}
/**
*交换功能
*/
protected void swap(int i1, int i2) {
T tmp = array[i1];
array[i1] = array[i2];
array[i2] = tmp;
}
}
2.冒泡排序(Bubble Sort)
2.1定义
冒泡排序算法多次遍历数组,在每次遍历中连续比较相邻的元素,如果元素没有按照排序排列,则互换它们的值,否则,保持不变。由于较大(或较小)的值像"气泡"一样逐渐浮向顶部,而较小值沉向底部,所以称这种技术为冒泡排序(bubble sort)或下沉排序(sinking sort)。
2.2执行流程
- 从头开始比较每一对相邻元素,如果第1个比第2个大,就交换它们的位置。 执行完一轮后,最末尾那个元素就是最大的元素。
- 忽略 步骤一 中曾经找到的最大元素,重复执行步骤 1,直至全部元素有序

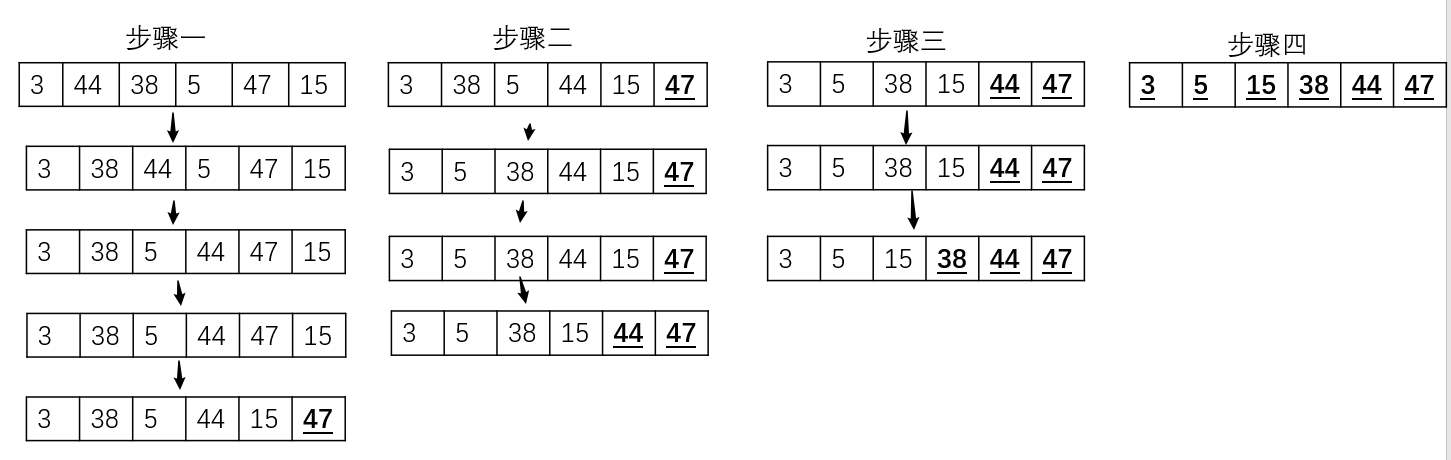
以上图举例:
- 首先比较第一对元素(3和44),因为这两个元素已经是升序,所以不需要交换。接着比较第二对元素(44和38),因为38<44,所以交换。然后比较第三对元素(44,5),因为5<44,所以交换。然后比较第四对元素(44,47),不交换,最后比较(47,15),47>15,所以交换,第一次循环结束。
- 经过上一次循环,数组中的最大值已经是最后一个,下次排序不用再考虑了。即进行第k(k>1)次循环,不用考虑最后(k-1)个元素。
- 当所有元素排好序,不必再进行循环,跳出循环。
2.3代码实现
public class BubbleSort<T extends Comparable<T>> extends Sort<T> {
@Override
protected void sort() {
for (int end = array.length - 1; end > 0; end--) {
boolean sorted = true;
for (int begin = 1; begin <= end; begin++) {
if (cmp(begin, begin - 1) < 0) {
swap(begin, begin - 1);
sorted = false;
}
}
if (sorted) break;
}
}
}
2.4优化
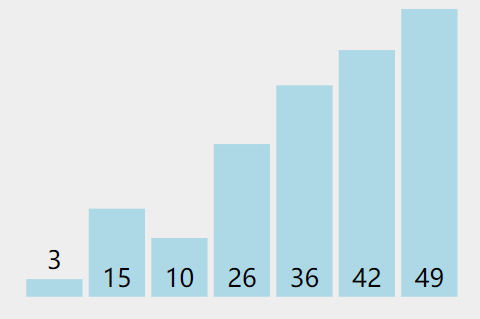
如果 序列尾部已经局部有序,可以记录最后1次交换的位置,减少比较次数。在上图中,第一次循环只交换了15和10,将10的索引位置2记住,下次只需要扫描第一个和第二个元素。
代码如下:
public class BubbleSort<T extends Comparable<T>> extends Sort<T> {
@Override
protected void sort() {
for (int end = array.length - 1; end > 0; end--) {
int sortedIndex = 1;
for (int begin = 1; begin <= end; begin++) {
if (cmp(begin, begin - 1) < 0) {
swap(begin, begin - 1);
sortedIndex = begin;
}
}
end = sortedIndex;
}
}
}
2.5复杂度
- 在最佳情况下,冒泡排序算法只需要一次遍历就能确定数组已排好序,不需要进行下一次遍历,第一次遍历的比较次数为n-1,因此在最佳情况下,冒泡排序的时间复杂度为O(n)。
- 最差情况下,冒泡排序需要进行n-1次遍历,第一次遍历需要n-1次比较,第二次需要n-2次比较,依次进行,最后一次需要一次比较,总和为
T(n)=(n-1)+(n-2)+(n-3)+……+1=n(n-1)/2=O(n²)。
3.选择排序(Selection Sort)
3.1 定义
选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的初始位置,直到全部待排序的数据元素排完。
3.2执行流程
- 从序列中找出最小的那个元素,然后与前面的元素交换位置, 执行完一轮后,最前面的那个元素就是最小的元素
- 忽略步骤1中曾经找到的最小元素,重复执行步骤 1

以上图举例:
- 首先找出最小值3,3就在第一个位置,所以不动。
- 接下来,在剩下的数中找到最小值5,与二号位44互换。依次进行,当剩余数列中只剩一个数字时,排序结束。
3.3代码实现
public class SelectionSort<T extends Comparable<T>> extends Sort<T> {
@Override
protected void sort() {
for (int begin = 0; begin < array.length-1; begin++) {
int min = begin;
for (int end = begin + 1; end < array.length; end++) {
if (cmp(min, end) > 0) {
min = end;
}
}
if (min!=begin){
swap(min, begin);
}
}
}
}
3.4复杂度
设T(n)表示选择排序的复杂度,c表示每次循环其他操作的总数,则
T(n)=(n-1)+c+(n-2)+c+(n-3)+……+1+c=n(n-1)/2=O(n²)
4.堆排序(Heap Sort)
学习堆排序前要掌握堆的相关知识,可看文章:数据结构与算法——二叉堆(Java)
4.1定义
堆排序使用的是二叉堆,它首先将所有元素添加到一个堆上,然后不断移除最大的元素以获得一个排好序的线性表。
4.2执行流程
- 对序列进行原地建堆(heapify)
- 重复执行以下操作,直到堆的元素数量为 1
- 交换堆顶元素与尾元素
- 堆的元素数量减 1
- 对 0 位置进行 1 次 siftDown 操作
现给出一组数据进行堆排序

- 将5个数据原地建堆(heapify)
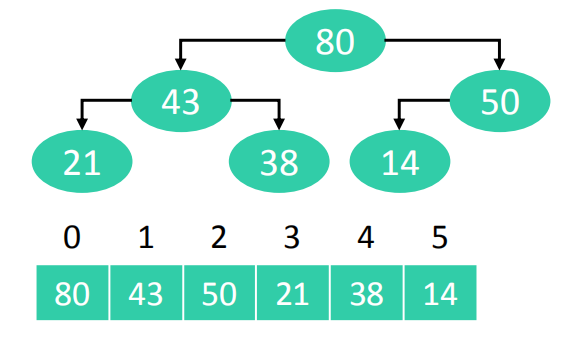
- 交换堆顶元素80和尾部元素14,堆元素个数减1,即将原先的堆顶元素脱离堆,只处理其他元素。对0位置进行一次siftDown操作。
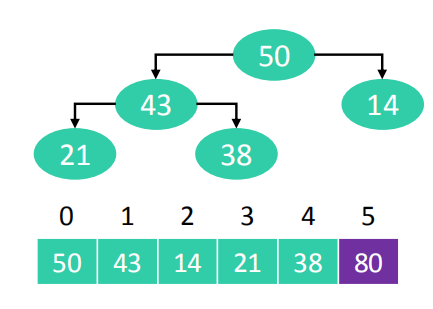
- 重复执行步骤二,直到堆的个数变为1.

此时,数组的顺序已经变为升序。
4.3代码实现
public class HeapSort<T extends Comparable<T>> extends Sort<T> {
private int heapSize;
@Override
protected void sort() {
// 原地建堆
heapSize = array.length;
for (int i = (heapSize >> 1) - 1; i >= 0; i--) {
siftDown(i);
}
while (heapSize > 1) {
// 交换堆顶元素和尾部元素
swap(0, --heapSize);
// 对0位置进行siftDown(恢复堆的性质)
siftDown(0);
}
}
private void siftDown(int index) {
T element = array[index];
int half = heapSize >> 1;
while (index < half) { // index必须是非叶子节点
// 默认是左边跟父节点比
int childIndex = (index << 1) + 1;
T child = array[childIndex];
int rightIndex = childIndex + 1;
// 右子节点比左子节点大
if (rightIndex < heapSize &&
cmp(array[rightIndex], child) > 0) {
child = array[childIndex = rightIndex];
}
// 大于等于子节点
if (cmp(element, child) >= 0) break;
array[index] = child;
index = childIndex;
}
array[index] = element;
}
}
4.4复杂度
- 下滤的复杂度为O(n),故建堆时的复杂度为O(n)。
- 更改堆元素后重建堆时,循环n-1次,每次都是从根节点往下循环查找,所以每一次时间是 logn,总时间:
(n-1) logn= nlogn - logn。
综上所述:建堆的时间复杂度是O(n)(调用一次);调整堆的时间复杂度是logn,调用了n-1次,所以堆排序的时间复杂度是O(n)+O(nlogn) ~ O(nlogn)。
5.插入排序(Insertion Sort)
5.1定义
插入排序重复地将新的元素插入到一个已经排好序的子线性表中,直到整个线性表排好序。
5.2执行流程

- 在执行过程中,插入排序会将序列分为2部分,头部是已经排好序的,尾部是待排序的。
- 从头开始扫描每一个元素,每当扫描到一个元素,就将它插入到头部合适的位置,使得头部数据依然保持有序。
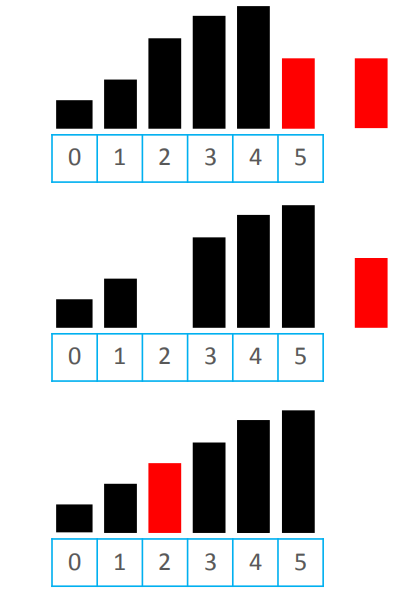
以下图举例:

- 一开始,排好序的子线性表只包含线性表的第一个元素,然后进入循环,44大于3,所以不交换。
- 此时排好序的线性表为{3,44},44>38,所以交换38和44。
- 依次进行,直至 最后一个元素完成比较,完成排序。
5.3代码实现
public class InsertionSort1<T extends Comparable<T>> extends Sort<T> {
@Override
protected void sort() {
for (int begin = 1; begin < array.length; begin++) {
int cur = begin;
while (cur > 0 && cmp(cur, cur - 1) < 0) {
swap(cur, cur - 1);
cur--;
}
}
}
}
5.4普通优化
思路是将交换转为挪动
- 先将待插入的元素备份
- 头部有序数据中比待插入元素大的,都朝尾部方向挪动1个位置
- 将待插入元素放到最终的合适位置
代码实现:
public class InsertionSort2<T extends Comparable<T>> extends Sort<T> {
@Override
protected void sort() {
for (int begin = 1; begin < array.length; begin++) {
int cur = begin;
T v = array[cur];
while (cur > 0 && cmp(v, array[cur - 1]) < 0) {
array[cur] = array[cur - 1];
cur--;
}
array[cur] = v;
}
}
}
5.5二分搜索优化
二分搜索可以快速查找指定元素,减少查找的次数。
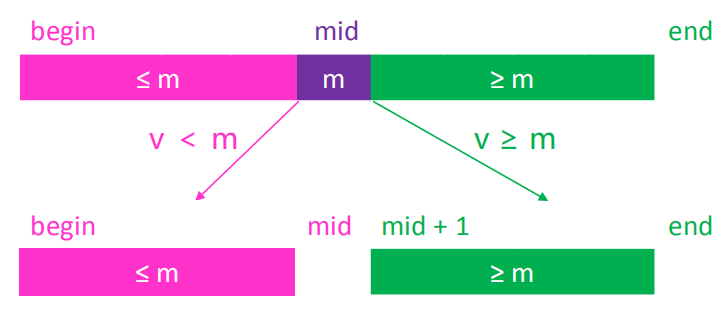
- 假设在
[begin, end)范围内搜索某个元素 v,mid == (begin + end) / 2 - 如果
v < m,去[begin, mid)范围内二分搜索 - 如果
v ≥ m,去[mid + 1, end)范围内二分搜索
5.5.1举例



5.5.2代码实现
public class InsertionSort3<T extends Comparable<T>> extends Sort<T> {
@Override
protected void sort() {
for (int begin = 1; begin < array.length; begin++) {
insert(begin, search(begin));
}
}
/**
* 将source位置的元素插入到dest位置
* @param source
* @param dest
*/
private void insert(int source, int dest) {
T v = array[source];
for (int i = source; i > dest; i--) {
array[i] = array[i - 1];
}
array[dest] = v;
}
/**
* 利用二分搜索找到 index 位置元素的待插入位置
* 已经排好序数组的区间范围是 [0, index)
* @param index
* @return
*/
private int search(int index) {
int begin = 0;
int end = index;
while (begin < end) {
int mid = (begin + end) >> 1;
if (cmp(array[index], array[mid]) < 0) {
end = mid;
} else {
begin = mid + 1;
}
}
return begin;
}
}
6.归并排序(Merge Sort)
6.1定义
归并排序算法将数组分为两半,对每部分递归地应用归并排序。在两部分都排好序后,对它们进行归并。
6.2执行流程
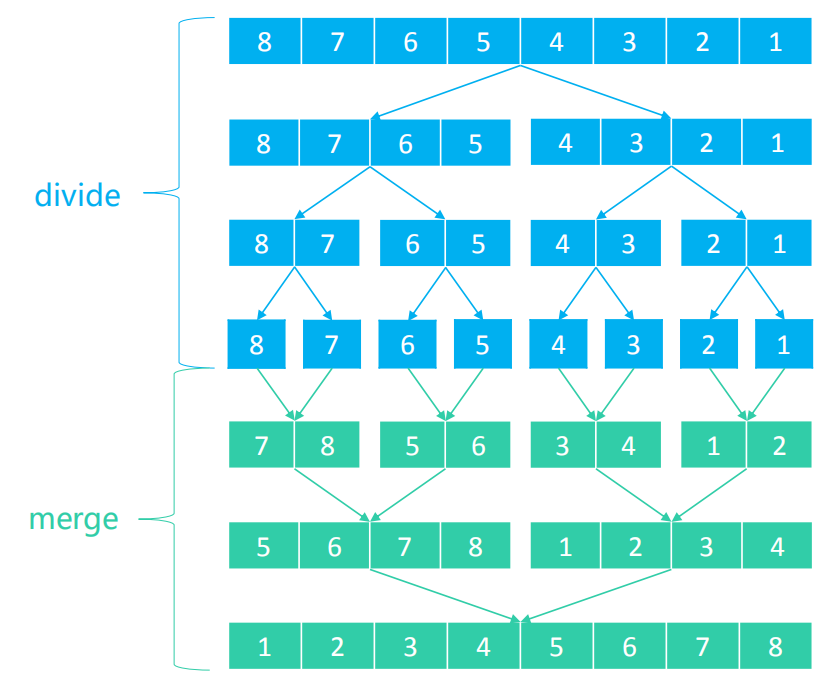
- 不断地将当前序列平均分割成2个子序列,直到不能再分割(序列中只剩1个元素)
- 不断地将2个子序列合并成一个有序序列,直到最终只剩下1个有序序列
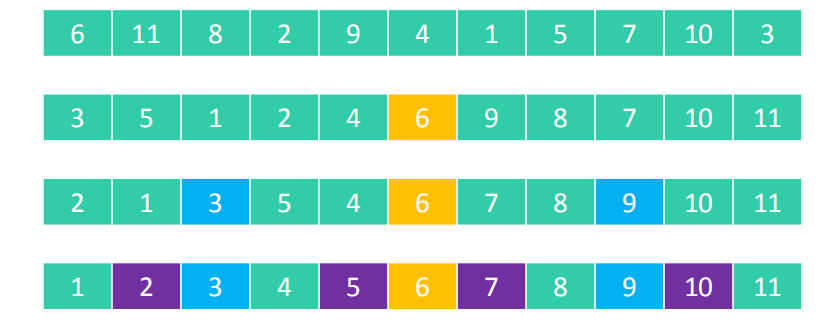
下面我们先看一个简单的例子,如下图:

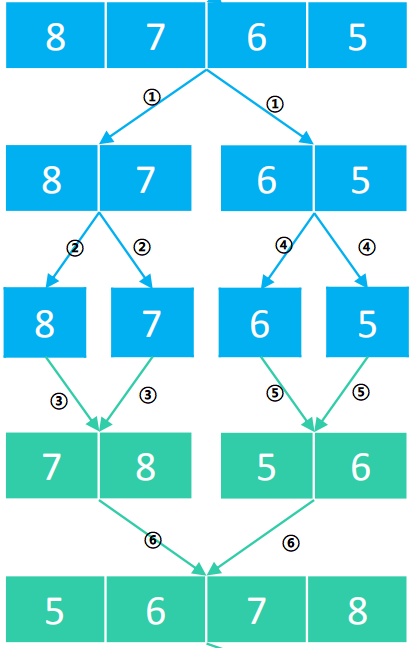
归并排序的算法我们通常用递归实现,我们接下来将这四个数字按照递归归并排序的流程进行排序。完整的流程如下:

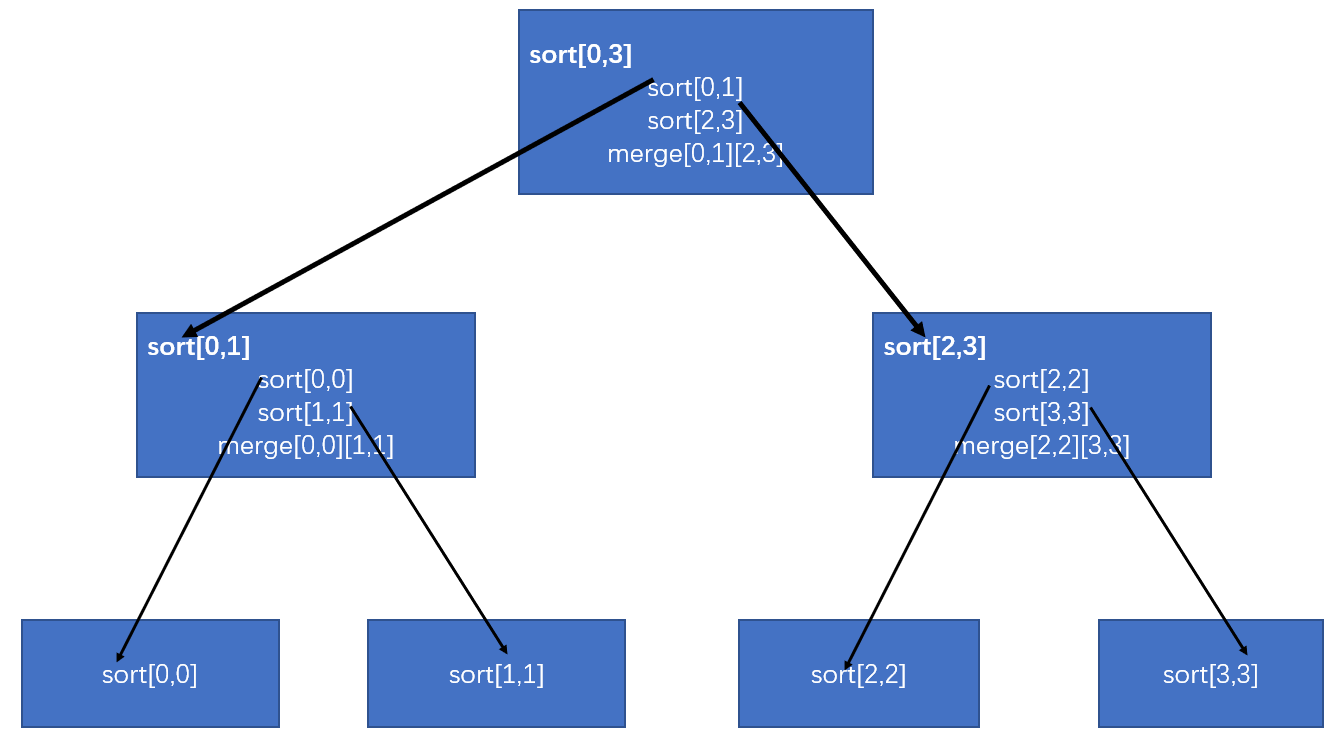
- 首先数组[8,7,6,5]分割为[8,7],[6,5],然后[8.7]又分割为[8],[7],此时数组中只有一个元素,不再分割,递归返回,进行merge操作,合并为[7,8],然后开始分割[6,5],执行与刚才一样的操作。如上图,箭头指向下一次操作
6.2.1具体的merge操作
-
需要 merge 的 2 组序列存在于同一个数组中,并且是挨在一起的

-
merge操作就是将两个子序列合并成一个有序序列,为了更好地完成 merge 操作,最好将其中 1 组序列备份出来,比如 [begin, mid)。
-
li代表左子序列中待移出元素的索引
-
le代表左子序列的终止位置+1
-
ri代表右子序列中待移出元素的索引
-
re代表左子序列的终止位置+1
-
ai代表合并序列待填充元素的索引位置


具体操作如下:
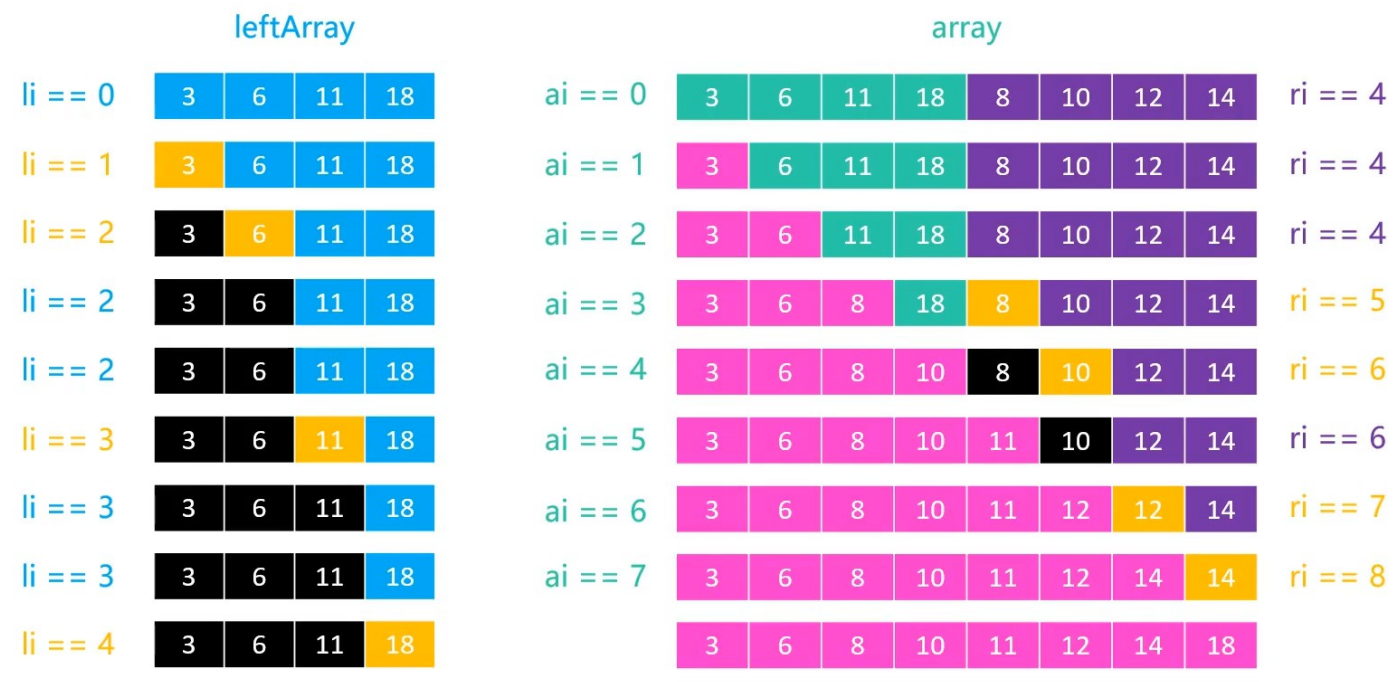
- 初始时,左子序列中li=0,即左子序列的第一个元素3,在array中,ri = 4,指向右子序列的第一个元素8,它们进行比较,3<8,所以array第一个位置为3,li,ai向右移动一位,li++,ai++,ri不变。
- 和步骤一进行相同的操作,直至ri=7,18<14,14填充array最后一个位置,ri+1,此时li=3,继续进行下一次循环,ri>7,直接让18覆盖array最后一个位置,li+1,循环结束。
上述操作为右边先结束的情况。
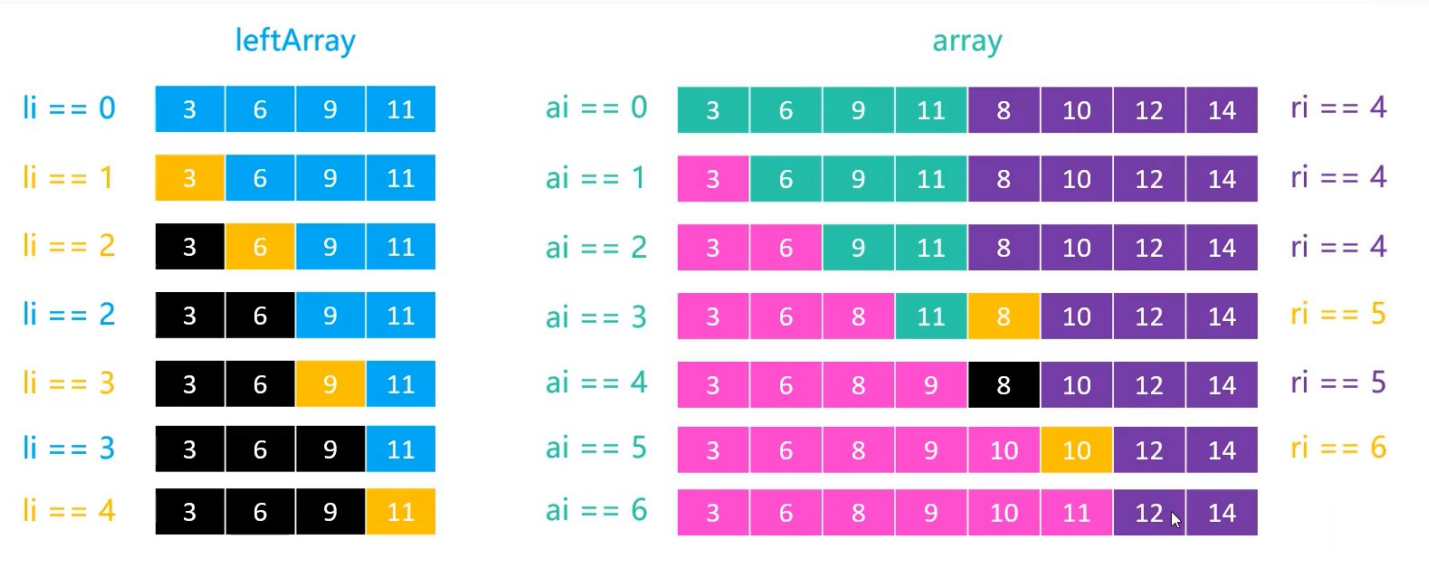
左边先结束的情况:也需要li索引大于le
6.3代码实现
public class MergeSort<T extends Comparable<T>> extends Sort<T> {
private T[] leftArray;
@Override
protected void sort() {
leftArray = (T[]) new Comparable[array.length >> 1];
sort(0, array.length);
}
/**
* 对 [begin, end) 范围的数据进行归并排序
*/
private void sort(int begin, int end) {
if (end - begin < 2) {
return;
}
int mid = (begin + end) >> 1;
sort(begin, mid);
sort(mid, end);
merge(begin, mid, end);
}
/**
* 将 [begin, mid) 和 [mid, end) 范围的序列合并成一个有序序列
*/
private void merge(int begin, int mid, int end) {
int li = 0, le = mid - begin;
int ri = mid, re = end;
int ai = begin;
// 备份左边数组
for (int i = li; i < le; i++) {
leftArray[i] = array[begin + i];
}
// 如果左边还没有结束
while (li < le) {
if (ri < re && cmp(array[ri], leftArray[li]) < 0) {
array[ai++] = array[ri++];
} else {
array[ai++] = leftArray[li++];
}
}
}
}
6.4复杂度

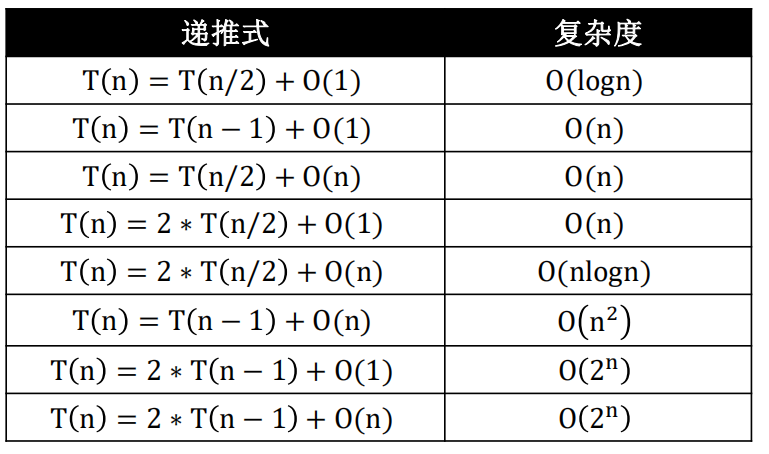
6.4.1常见递推式与复杂度
7.快速排序(Quick Sort)
7.1定义
快速排序工作机制如下:在数组中选择一个称为主元(pivot)的元素,将数组分为两部分,使得第一部分中的所有元素都小于或等于主元,而第二部分中的所有元素都大于主元。对第一部分递归地应用快速排序,然后对第二部分递归地应用快速排序算法。
7.2执行流程
- 从序列中选择一个轴点元素(pivot),假设每次选择 0 位置的元素为轴点元素
- 利用 pivot 将序列分割成 2 个子序列
✓ 将小于 pivot 的元素放在pivot前面(左侧)
✓ 将大于 pivot 的元素放在pivot后面(右侧)
✓ 等于pivot的元素放哪边都可以 - 对子序列进行1,2 操作
✓ 直到不能再分割(子序列中只剩下1个元素)
以下图举例:
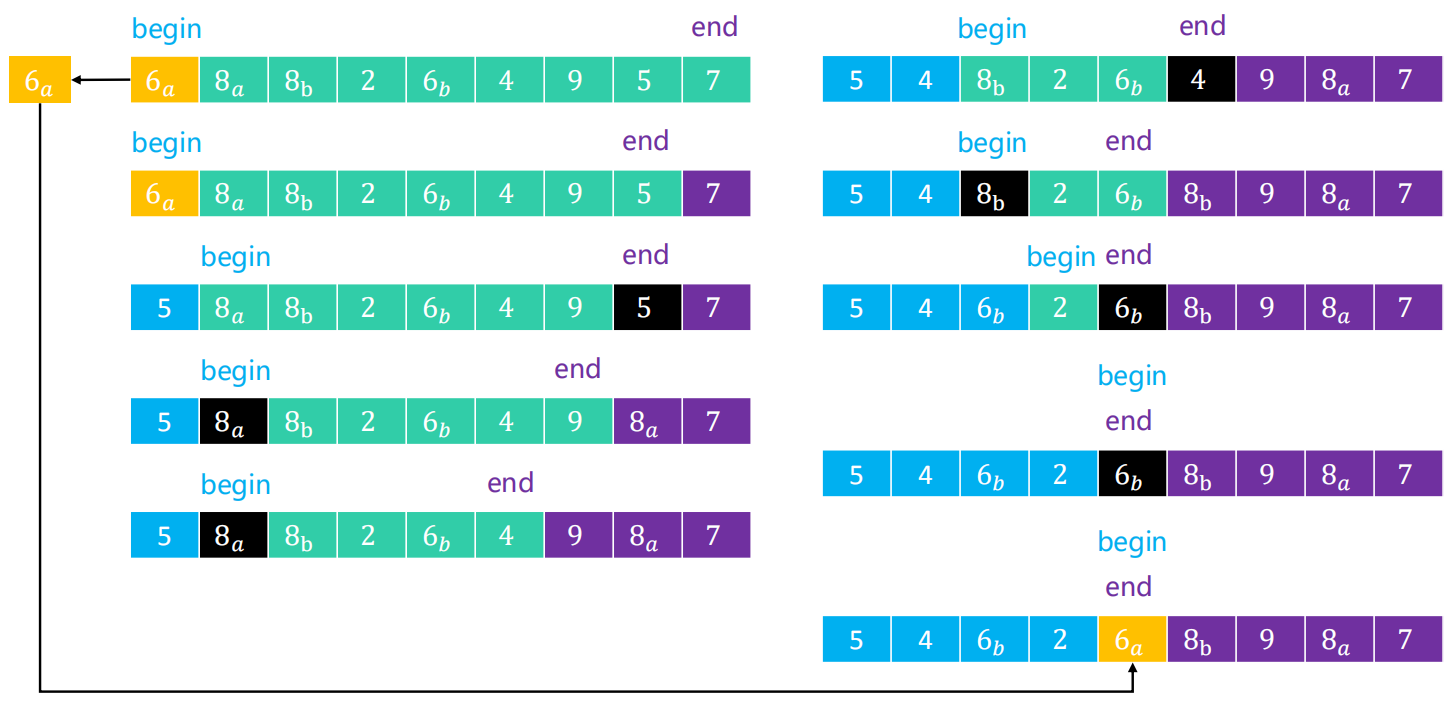
- 我们寻找轴点元素的位置。以0位置元素为轴点元素,因为后面的操作会将该位置替换,故先将其备份。一开始begin指向要快速排序的左边第一个元素,end指向最后一个元素的后一位。
- 先从最后一个位置(end-1)开始扫描,7>6,不移动元素,但是要end–。上次扫描没移动元素,继续从右边向左边扫描,这次5<6,则直接覆盖begin位置的元素,begin++。
- 这次该从begin扫描了,8>6,应该移动到轴点元素的右边,所有移动到原来的end位置。需要注意的是,当begin位置元素或者end位置元素等于轴点元素时,仍然将其认为小于轴点元素。
- 按照上面的操作一直进行,直至begin=end,则轴点元素找到(注意:轴点元素不一定在最中间)。
- 轴点元素找到以后,对两边分别进行快速排序,两边也分别需要找到轴点元素,这就是递归操作了。
7.3代码实现
public class QuickSort<T extends Comparable<T>> extends Sort<T> {
@Override
protected void sort() {
sort(0, array.length);
}
/**
* 对 [begin, end) 范围的元素进行快速排序
* @param begin
* @param end
*/
private void sort(int begin, int end) {
if (end - begin < 2) {
return;
}
// 确定轴点位置 O(n)
int pivot = pivotIndex(begin, end);
// 对子序列进行快速排序
sort(begin, pivot);
sort(pivot + 1, end);
}
/**
* 构造出 [begin, end) 范围的轴点元素
* @return 轴点元素的最终位置
*/
private int pivotIndex(int begin, int end) {
// 备份begin位置的元素
T pivot = array[begin];
// end指向最后一个元素
end--;
while (begin < end) {
while (begin < end) {
if (cmp(pivot, array[end]) < 0) { // 右边元素 > 轴点元素
end--;
} else { // 右边元素 <= 轴点元素
array[begin++] = array[end];
break;
}
}
while (begin < end) {
if (cmp(pivot, array[begin]) > 0) { // 左边元素 < 轴点元素
begin++;
} else { // 左边元素 >= 轴点元素
array[end--] = array[begin];
break;
}
}
}
// 将轴点元素放入最终的位置
array[begin] = pivot;
// 返回轴点元素的位置
return begin;
}
}
7.4复杂度

8.希尔排序(Shell Sort)
8.1定义
希尔排序(Shell’s Sort)是插入排序的一种又称“缩小增量排序”(Diminishing Increment Sort),是直接插入排序算法的一种更高效的改进版本。希尔排序把序列看作是一个矩阵,分成 𝑚 列,逐列进行排序,从某个整数逐渐减为1 ;当 𝑚 为1时,整个序列将完全有序。 因此,希尔排序也被称为递减增量排序(Diminishing Increment Sort)
◼ 矩阵的列数取决于步长序列(step sequence)
✓ 比如,如果步长序列为{1,5,19,41,109,…},就代表依次分成109列、41列、19列、5列、1列进行排序
✓ 不同的步长序列,执行效率也不同
8.2执行流程
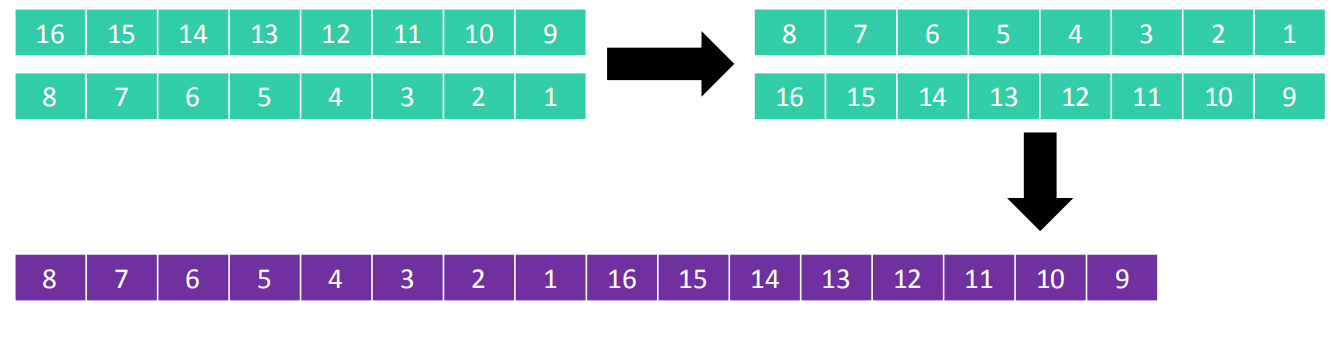
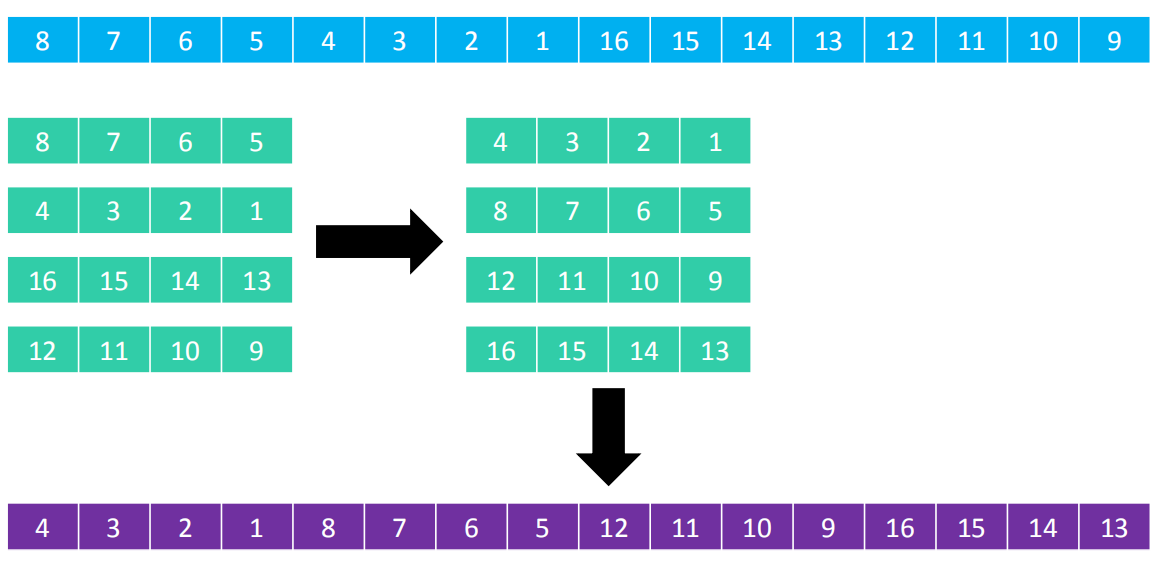
希尔本人给出的步长序列是 𝑛/2𝑘,比如 𝑛 为16时,步长序列是{1, 2, 4, 8}

- 分成8列进行排序
- 分成4列进行排序
- 分成2列进行排序
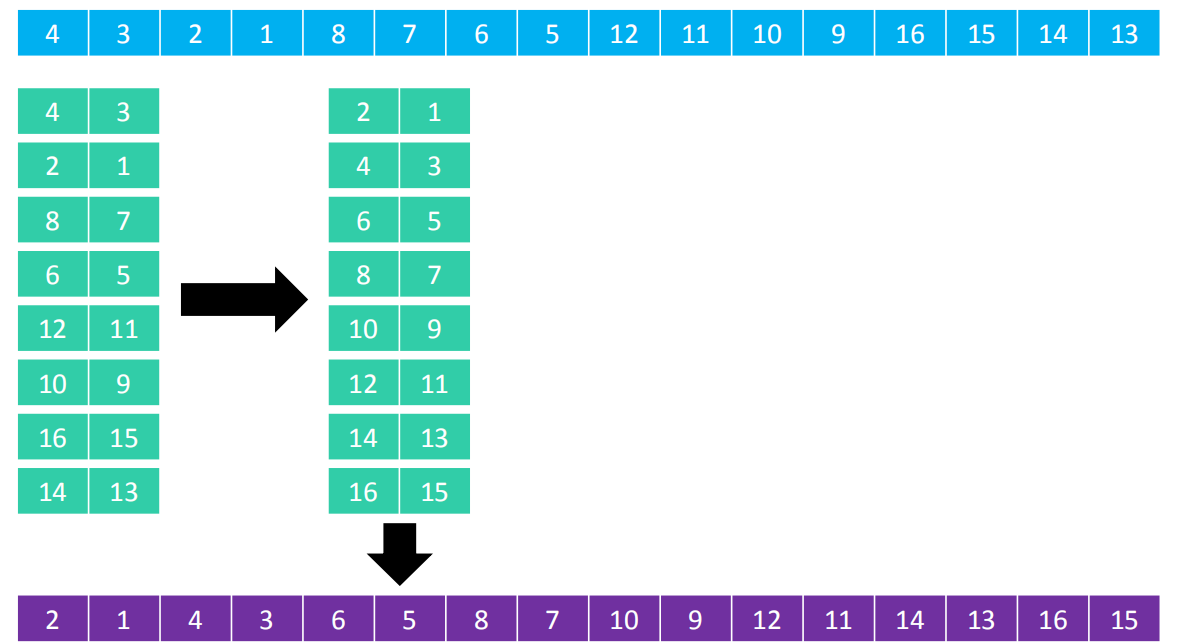
- 分成1列进行排序
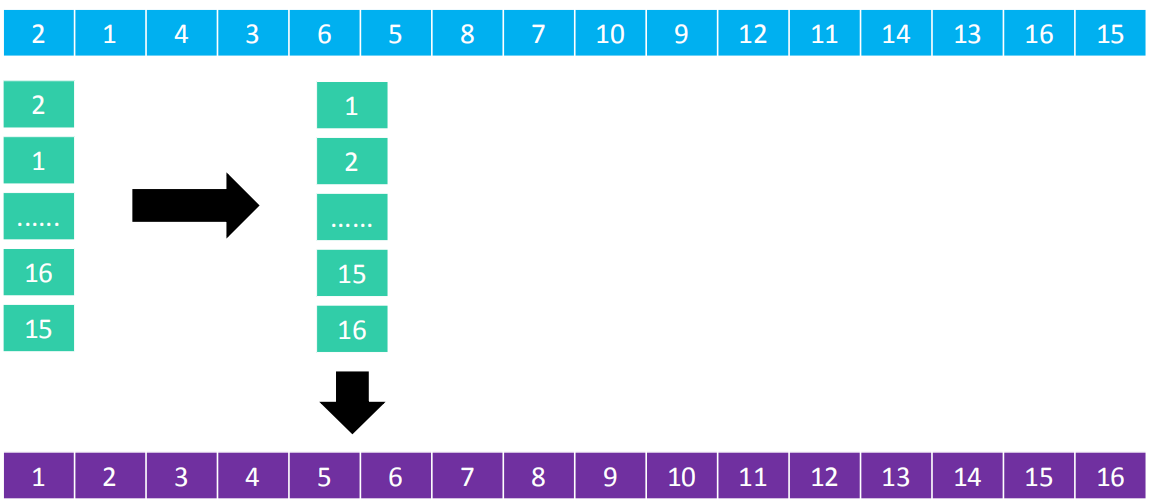
- 不难看出来,从8列 变为 1列的过程中,逆序对的数量在逐渐减少
- 因此希尔排序底层一般使用插入排序对每一列进行排序,也很多资料认为希尔排序是插入排序的改进版
假设有11个元素,步长序列是{1, 2, 5}

- 假设元素在第 col 列、第 row 行,步长(总列数)是 step
- 那么这个元素在数组中的索引是 col + row * step
- 比如 9 在排序前是第 2 列、第 0 行,那么它排序前的索引是 2 + 0 * 5 = 2
- 比如 4 在排序前是第 2 列、第 1 行,那么它排序前的索引是 2 + 1 * 5 = 7
8.3代码实现
public class ShellSort<T extends Comparable<T>> extends Sort<T> {
@Override
protected void sort() {
List<Integer> stepSequence = shellStepSequence();
for (Integer step : stepSequence) {
sort(step);
}
}
/**
* 分成step列进行排序
*/
private void sort(int step) {
// col : 第几列,column的简称
for (int col = 0; col < step; col++) { // 对第col列进行排序
// col、col+step、col+2*step、col+3*step
for (int begin = col + step; begin < array.length; begin += step) {
int cur = begin;
while (cur > col && cmp(cur, cur - step) < 0) {
swap(cur, cur - step);
cur -= step;
}
}
}
}
private List<Integer> shellStepSequence() {
List<Integer> stepSequence = new ArrayList<>();
int step = array.length;
while ((step >>= 1) > 0) {
stepSequence.add(step);
}
return stepSequence;
}
}
9.计数排序(Counting Sort)
9.1定义
计数排序是一个非基于比较的排序算法,该算法于1954年由 Harold H. Seward 提出。它的优势在于在对一定范围内的整数排序时,它的复杂度为Ο(n+k)(其中k是整数的范围),快于任何比较排序算法。 当然这是一种牺牲空间换取时间的做法.计数排序的核心思想:统计每个整数在序列中出现的次数,进而推导出每个整数在有序序列中的索引
9.2执行流程

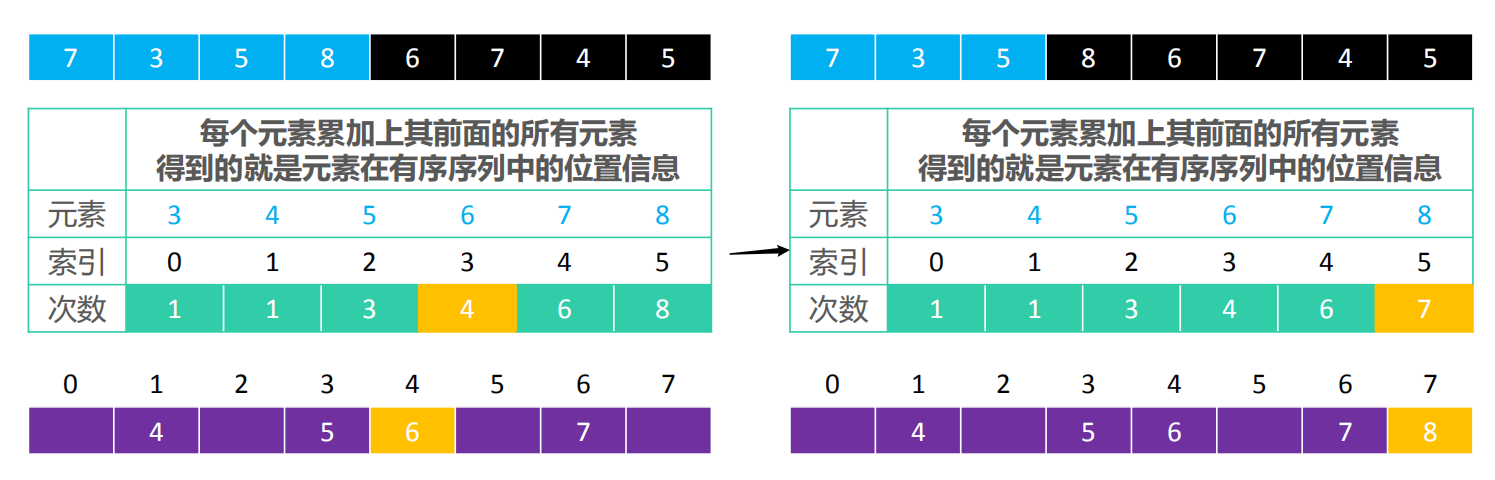
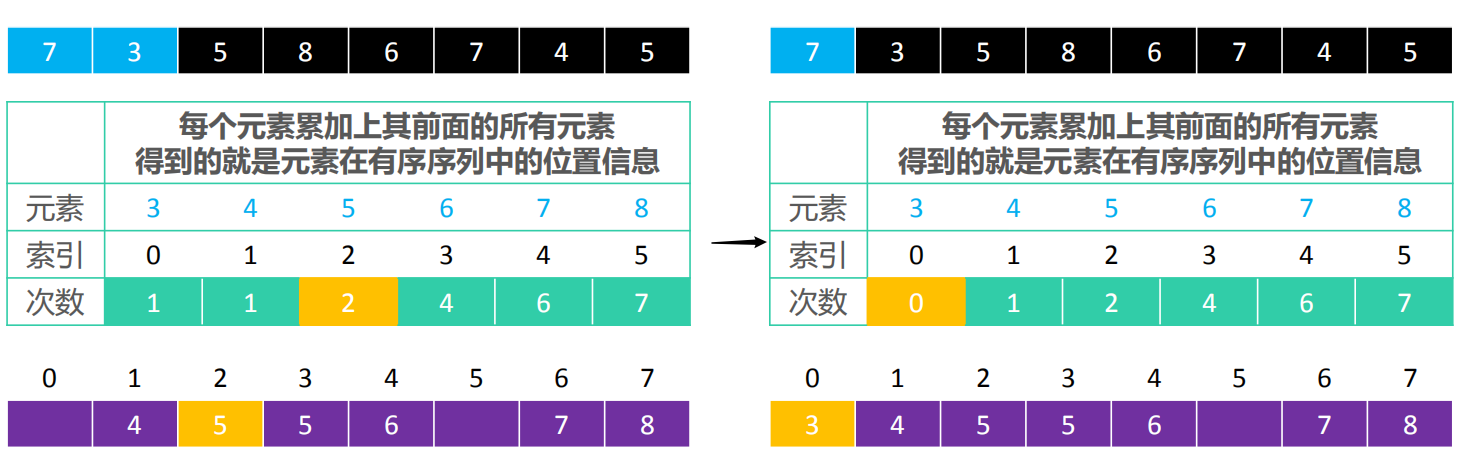
- 在这个数组中,先找到最大值max和最小值min,然后呢,从索引0开始依次存放3~8出现的次数,每个次数累加上其前面的所有次数,得到的就是元素在有序序列中的位置信息。

- 如果元素不重复,array中的元素 k 对应的 counts 索引是
k – min - 比如元素 8 在有序序列中的索引
counts[8 – 3] – 1,结果为 7 - 如果重复,array中的元素 k 对应的 counts 索引是 k – min-p,p 代表着是倒数第几个 k
- 比如倒数第 1 个元素 7 在有序序列中的索引
counts[7 – 3] – 1,结果为 6 , 倒数第 2 个元素 7 在有序序列中的索引counts[7 – 3] – 2,结果为 5
- 然后我们可以创建一个新数组,从后往前遍历array,将其放入新创建的数组。
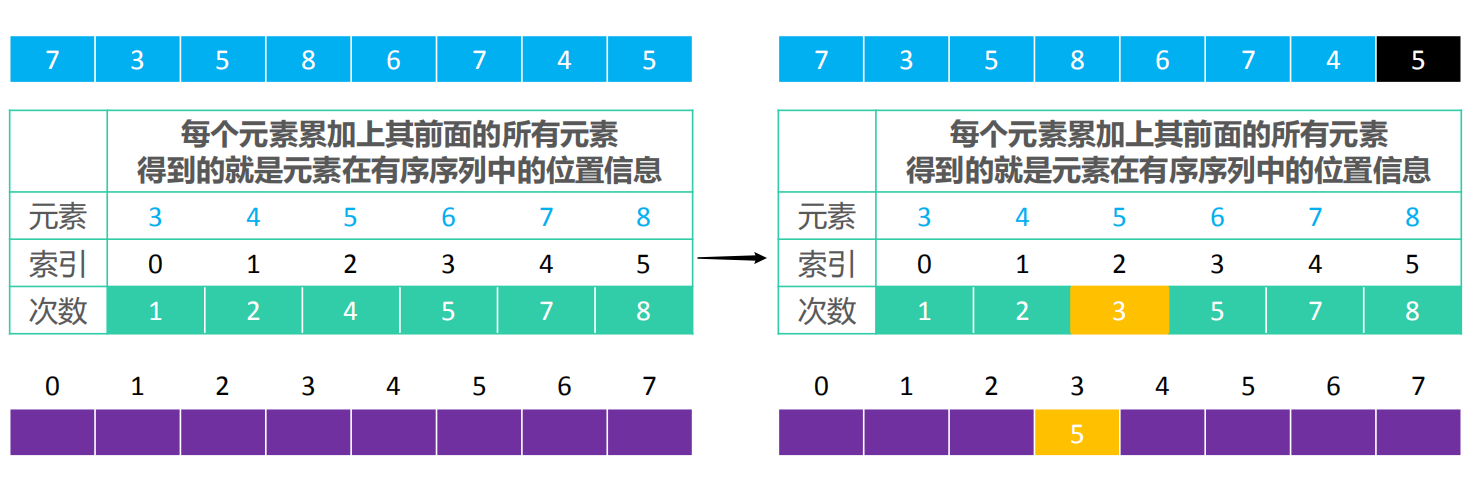
比如将5放进newArray中,counts[5-3]-1=counts[2]-1=4-1=3,所以3就是5在newArray的索引
,如上图。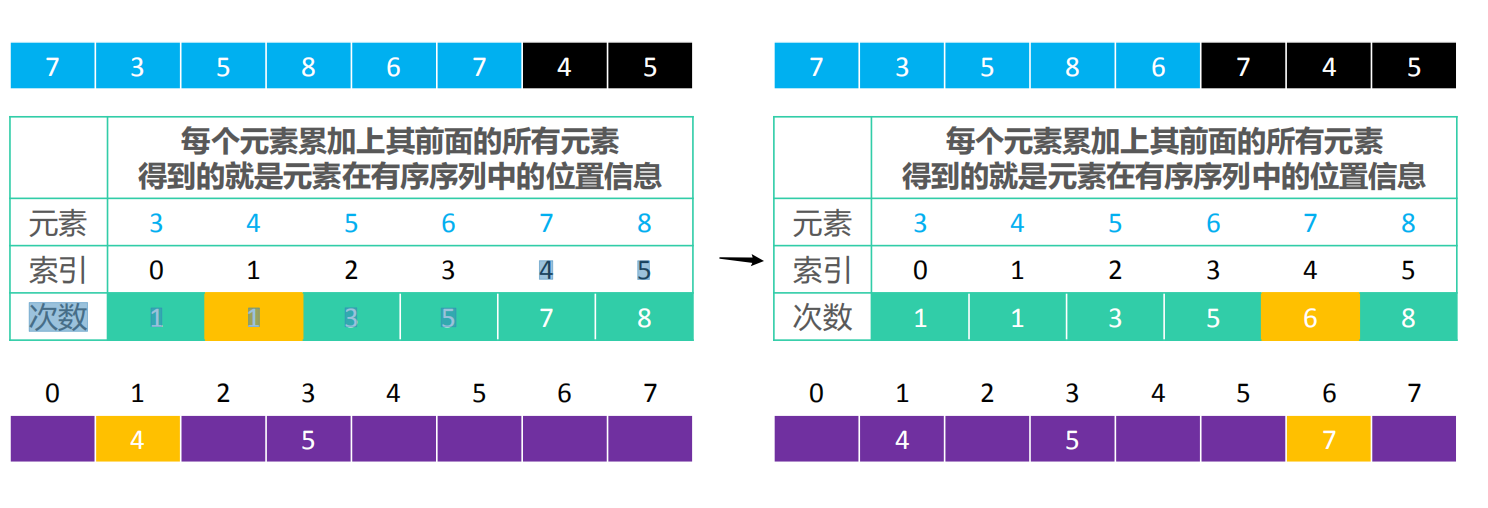


9.3代码实现
public class CountingSort extends Sort<Integer> {
@Override
protected void sort() {
// 找出最值
int max = array[0];
int min = array[0];
for (int i = 1; i < array.length; i++) {
if (array[i] > max) {
max = array[i];
}
if (array[i] < min) {
min = array[i];
}
}
// 开辟内存空间,存储次数
int[] counts = new int[max - min + 1];
// 统计每个整数出现的次数
for (int i = 0; i < array.length; i++) {
counts[array[i] - min]++;
}
// 累加次数
for (int i = 1; i < counts.length; i++) {
counts[i] += counts[i - 1];
}
// 从后往前遍历元素,将它放到有序数组中的合适位置
int[] newArray = new int[array.length];
for (int i = array.length - 1; i >= 0; i--) {
newArray[--counts[array[i] - min]] = array[i];
}
// 将有序数组赋值到array
for (int i = 0; i < newArray.length; i++) {
array[i] = newArray[i];
}
}
}
10.基数排序(Radix Sort)
10.1定义
基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,依次对个位数、十位数、百位数、千位数、万位数…进行排序(从低位到高位)
10.2执行流程
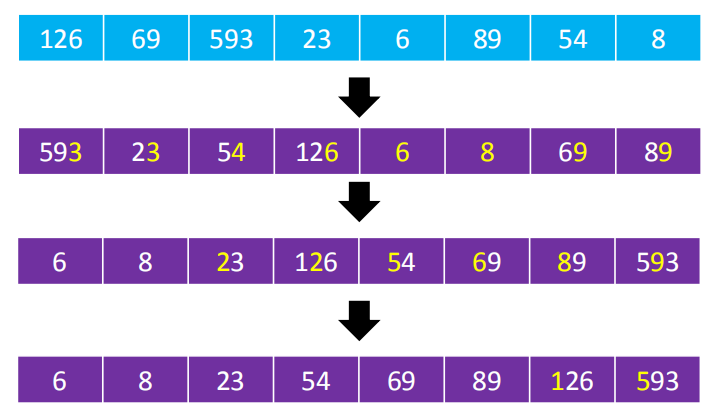
个位数、十位数、百位数的取值范围都是固定的0~9,可以使用计数排序对它们进行排序
- 上图中,先比较个位,分别是6,9,3,3,6,9,4,8。按照最后一位的大小进行排序
- 比较十位,9,2,5,2,0,0,6,8
- 比较百位,0,0,0,1,0,0,0,5

10.3代码实现
public class RadixSort extends Sort<Integer> {
@Override
protected void sort() {
// 找出最大值
int max = array[0];
for (int i = 1; i < array.length; i++) {
if (array[i] > max) {
max = array[i];
}
}
// 个位数: array[i] / 1 % 10 = 3
// 十位数:array[i] / 10 % 10 = 9
// 百位数:array[i] / 100 % 10 = 5
// 千位数:array[i] / 1000 % 10 = ...
for (int divider = 1; divider <= max; divider *= 10) {
countingSort(divider);
}
}
protected void countingSort(int divider) {
// 开辟内存空间,存储次数
int[] counts = new int[10];
// 统计每个整数出现的次数
for (int i = 0; i < array.length; i++) {
counts[array[i] / divider % 10]++;
}
// 累加次数
for (int i = 1; i < counts.length; i++) {
counts[i] += counts[i - 1];
}
// 从后往前遍历元素,将它放到有序数组中的合适位置
int[] newArray = new int[array.length];
for (int i = array.length - 1; i >= 0; i--) {
newArray[--counts[array[i] / divider % 10]] = array[i];
}
// 将有序数组赋值到array
for (int i = 0; i < newArray.length; i++) {
array[i] = newArray[i];
}
}
}
- 最好、最坏、平均时间复杂度:
O(d ∗ (n + k)),d 是最大值的位数,k 是进制。属于稳定排序 - 空间复杂度:
O(n + k),k 是进制
11.桶排序(Bucket Sort)(了解)
11.1定义
桶排序的基本思想是将一个数据表分割成许多buckets,然后每个bucket各自排序,或用不同的排序算法,或者递归的使用bucket sort算法。也是典型的divide-and-conquer分而治之的策略。实现的代码不止一种。
11.2执行流程
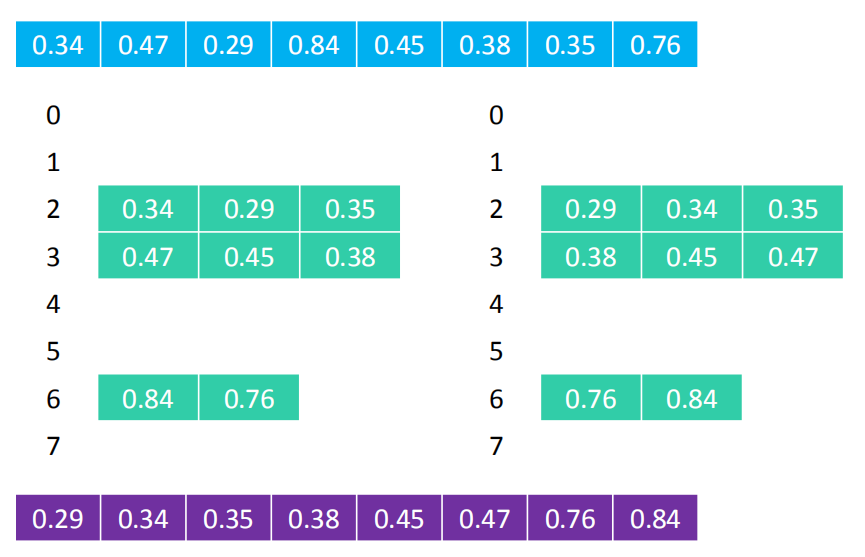
元素在桶中的索引 元素值 * 元素数量
执行流程
- 创建一定数量的桶(比如用数组、链表作为桶)
- 按照一定的规则(不同类型的数据,规则不同),将序列中的元素均匀分配到对应的桶
- 分别对每个桶进行单独排序
- 将所有非空桶的元素合并成有序序列
12.3复杂度

















 13万+
13万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











