








A SANITY CHECK FOR AI-GENERATED IMAGE DETECTION
https://arxiv.org/pdf/2406.19435
【ICLR2025】!!!小红书发表AI图像识别的多模态算法,文章解读和创新点解析A Sanity Check for AI-generated Image Detection
A Sanity Check for AI-generated Image Detection (arXiv:2406.19435) 的解读:
📄 A Sanity Check for AI-generated Image Detection
作者:Shilinyan Yan, Yanhua Cheng, Yujun Shen, et al.
机构:小红书、上海交通大学、中国科学技术大学
会议:ICLR 2025(已接收)
论文链接:arxiv.org/abs/2406.19435
代码仓库:GitHub - AIDE
🎯 研究动机与问题
随着扩散模型和 GAN 等 AI 图像生成技术的进步,伪造图像在视觉质量上愈发逼真。虽然已有多种检测方法用于识别 AI 生成图像,但当前方法存在以下问题:
- 仅对特定模型或特定模态图像有效
- 泛化能力弱,在真实环境中的检测准确率显著下降
- 缺乏真正具有“欺骗性”的评测数据集
🧪 Chameleon:具有高欺骗性的检测挑战数据集
论文构建了一个全新数据集 Chameleon,作为对现有检测器的“理智检验”(sanity check):
🔍 数据集特点:
- 人类图灵测试:所有图像均通过人类盲测,被误判为真实图像
- 内容多样性:覆盖人像、动物、自然场景等多个领域
- 高分辨率:大部分图像支持 4K 分辨率
- 模型多样性:涵盖多个主流扩散模型(如 SDXL、DALL·E3、Midjourney)
在该数据集上,9 种主流检测器几乎全部失效,大量将 AI 生成图像判断为真实图像,暴露了当前检测技术的严重局限性。
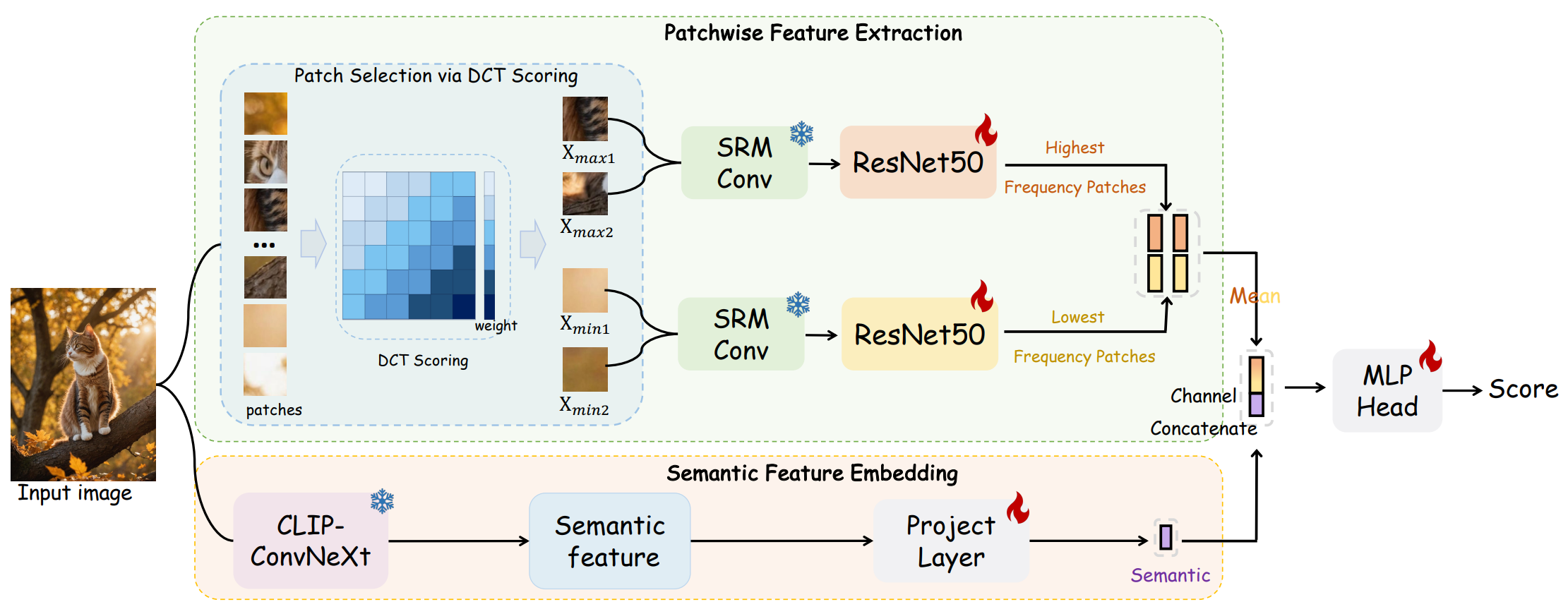
🧩 AIDE 方法:融合多模态特征的检测器
为应对检测器在 Chameleon 数据集上的失败,作者提出新检测方法 AIDE(AI-generated Image DEtector with Hybrid Features),该方法结合:
✨ 特征融合策略:
| 特征类型 | 描述 |
|---|---|
| 高层语义特征 | 利用 CLIP 提取图像的语义嵌入,用于识别逻辑一致性和语义完整性 |
| 低层视觉特征 | 从图像中提取局部区域(如高频区域、低频平滑区域),分析图像纹理、噪声、抗锯齿痕迹等生成特征 |
📊 实验结果
AIDE 在多个基准数据集上展现出强劲的性能:
| 数据集 | 基线检测器表现 | AIDE 提升幅度 |
|---|---|---|
| AIGCDetectBenchmark | - | +3.5% |
| GenImage | - | +4.6% |
| Chameleon | 原有检测器近乎完全失败 | AIDE 表现良好,远优于现有方法 |
🧠 个人总结与启发
-
检测方法的鲁棒性至关重要,仅靠某类模型特征并不能保证泛化性能。
-
构建真正具挑战性的数据集(如 Chameleon)是推动检测技术进步的关键。
-
多特征融合(低层 + 语义)策略是未来图像取证的重要方向。
-
文章利用多模态的方法,借助传统的图像识别(用深层语义特征判定图像是否为AI生成图像)与文字提取(基于图像中的文字特征判断,如:北极熊不太可能出现在草原)

🔗 链接汇总
- 📄 论文地址:https://arxiv.org/abs/2406.19435
- 💻 项目主页:https://github.com/shilinyan99/AIDE
- 📷 数据集地址(预计开放):Chameleon Dataset


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









