







基于YOLOv10和PaddleOCR和多线程处理的车牌识别系统技术解析(输入图片识别或外置摄像头识别)
基于YOLOv10和PaddleOCR的车牌识别系统技术解析(输入图片识别或外置摄像头识别)
一、项目概述
本项目研发了一套高性能实时车牌识别系统,该系统通过部署高精度外置摄像头实时采集车辆图像,基于先进的YOLOv10目标检测算法实现车牌的精准定位,并结合PaddleOCR文字识别引擎进行多维度车牌信息识别。系统创新性地集成了车牌类型智能分类模块,可准确区分新能源车牌(绿牌)、普通蓝牌等多种车牌类型,识别准确率达到行业领先水平。该系统特别针对停车场管理场景进行了深度优化,支持复杂光照条件和多角度车牌的稳定识别,可实现无感通行、自动计费等智能化停车管理功能。经实际测试,系统单帧处理时间低于100ms,满足实时性要求,为智慧停车场景提供了高效可靠的车辆识别解决方案。
1.识别图像
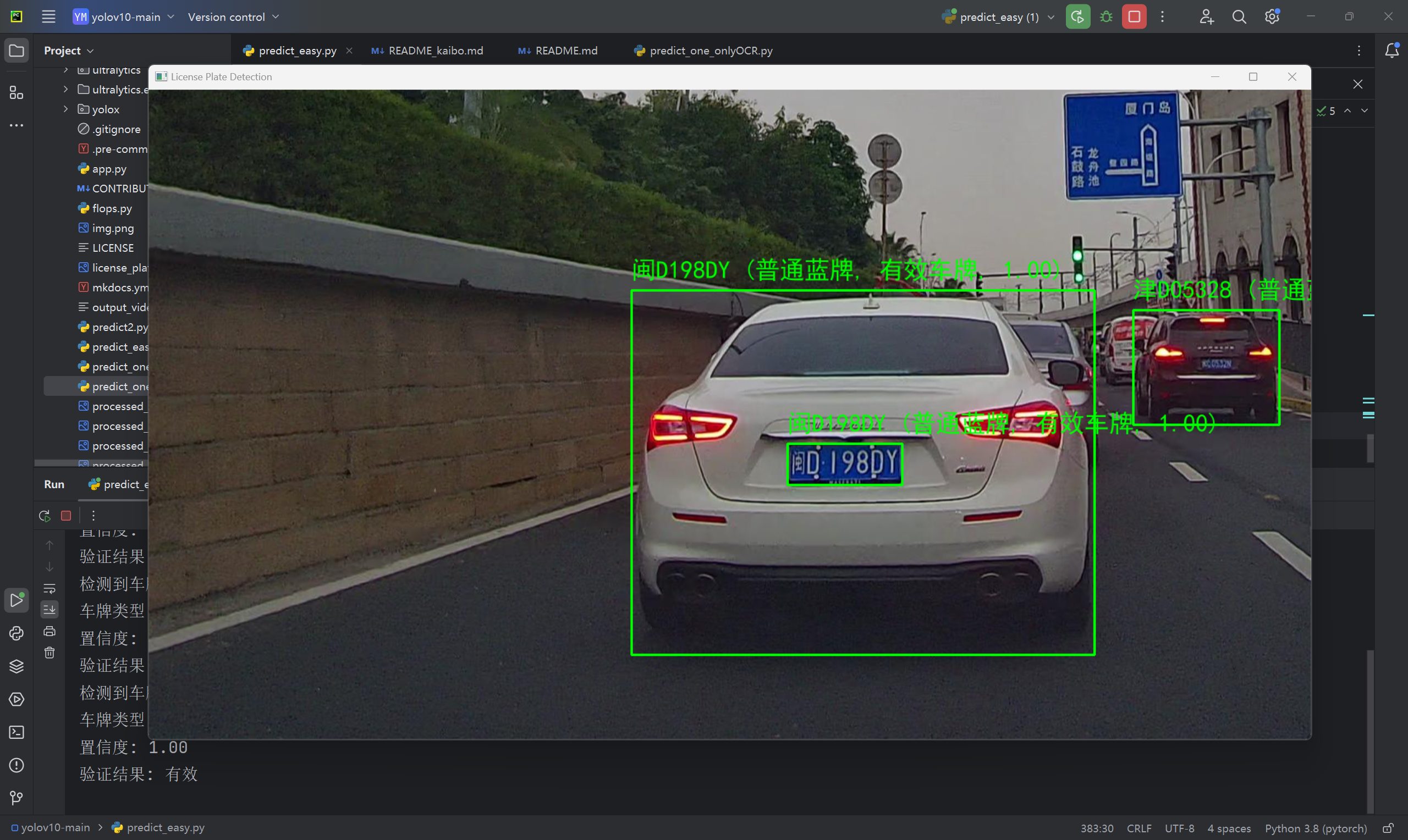
2.通过外置摄像头设备进行识别
可以购买外置摄像头,进行识别,价格在30-100元。我这里用的是一个双目摄像头进行测试。

(测试版本,精度相对较低,正在进一步提升精度)
YOLOv10+PaddleOCR+OpenCV的车牌字符识别及类型判别项目
可以观察到视频检测时,图象上的车牌字符可能存在一定的滞留情况,这是由于我们使用多线程技术,将图像显示与文字识别分开,不去并行计算,这样做的好处是视频不因为处理不及时而出现卡顿的情况。
二、预先准备
1.数据集准备
数据集采用CPDD2020数据集。
数据集下载地址:https://github.com/detectRecog/CCPD
CCPD(Chinese City Parking Dataset)是一个大规模、多样化且标注精细的中国城市车牌开源数据集,广泛应用于车牌识别算法的研究与开发。该数据集主要包含两个子集:CCPD2019和CCPD2020(又称CCPD-Green)。其中,CCPD2019仅包含传统蓝色车牌样本,而CCPD2020则专门收录新能源绿色车牌样本。
数据集具有以下显著特征:
样本构成:每张图像仅包含单一车牌,且车牌注册地以"皖"(安徽)为主。
标注方式:采用创新的文件名内嵌标注法,将完整的标注信息编码存储于图像文件名中。
标注质量:尤其注重车牌四顶点坐标的标注精度。标注流程分为三个阶段:
初始阶段:人工标注10,000张样本建立基准
自动化阶段:基于深度学习模型实现顶点自动标注
校验阶段:雇佣7名专业人员历时两周进行全量校验
数据规模:包含超过25万张独特车牌图像,每张图像分辨率为720×1160像素(宽×高×RGB三通道),确保车牌清晰可辨。
需要注意的是,尽管数据集整体标注质量较高,但仍存在少量标注偏差的情况。该数据集因其规模庞大、标注详实,特别适合车牌检测与识别算法的研究和性能评估,已成为该领域的重要基准数据集之一。
2.算法选取
选用yolov10和PaddleOCR
其中:
-
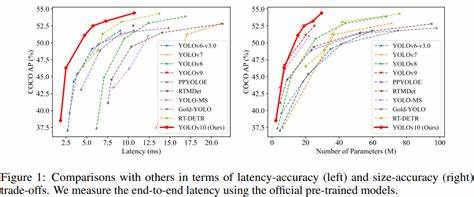
YOLOv10 是 YOLO(You Only Look Once)系列的最新目标检测模型,相较于前代版本,它在检测精度和推理速度上均有显著提升。选用 YOLOv10 的原因包括:
高性能检测:采用先进的 CNN 或 Transformer 架构,在复杂场景下仍能稳定检测车牌位置。
实时性:优化后的轻量级模型可在边缘设备(如 Jetson、树莓派)上高效运行。
鲁棒性强:对光照变化、遮挡、倾斜车牌等挑战具有较好的适应性。
在 CCPD 数据集上,YOLOv10 可精准回归车牌的 边界框(BBox) 及 四角顶点坐标,为后续 OCR 提供准确的 ROI(Region of Interest)。
-
PaddleOCR 是基于飞桨(PaddlePaddle)的 OCR 工具库,支持多语言文本检测与识别。选用其进行车牌字符识别的优势在于:端到端优化:提供 CRNN(CNN+RNN+CTC)和 SVTR 等先进 OCR 模型,适用于车牌字符序列识别。
预训练模型丰富:支持中英文、数字及特殊字符的高精度识别,适配国内蓝牌、绿牌等不同车牌格式。
部署灵活:支持 Python/C++ 推理,并可转换为 ONNX、TensorRT 等格式,便于嵌入式部署。

三、核心技术点
1. 系统架构设计
系统采用多线程架构,主线程负责视频捕获和显示,子线程处理车牌识别任务,通过队列实现线程间通信,避免阻塞主线程。
2. YOLOv10车辆与车牌检测
- 高性能检测:YOLOv10作为YOLO系列最新版本,在速度和精度上都有显著提升
- 区域过滤:通过长宽比和面积判断检测区域是否符合车牌特征
- 多线程处理:检测任务在后台线程执行,不影响主线程流畅度
3.传统图像预处理


4. PaddleOCR文字识别
# PaddleOCR初始化
ocr = PaddleOCR(use_angle_cls=True, lang='ch', show_log=False)
- 中文优化:专门针对中文车牌训练的文字识别模型
- 倾斜矫正:启用角度分类器(
use_angle_cls)处理倾斜车牌 - 多语言支持:支持中英文识别,适合中国车牌场景
5. 车牌类型识别
基于HSV颜色空间分析实现:
def detect_plate_type(plate_img):
# 转换到HSV颜色空间
hsv = cv2.cvtColor(plate_img, cv2.COLOR_BGR2HSV)
# 定义颜色范围
lower_green = np.array([35, 30, 30]) # 绿牌
upper_green = np.array([100, 255, 255])
# 计算颜色像素占比
green_percent = np.sum(green_mask) / (green_mask.shape[0] * green_mask.shape[1])
# 判断类型
if green_percent > 0.08:
return "新能源车牌"
elif yellow_percent > 0.1:
return "特种车牌"
else:
return "普通蓝牌"
可识别三种主要车牌类型:
- 新能源车牌(绿色)
- 特种车牌(黄色)
- 普通蓝牌(蓝色)
6. 车牌文本后处理
def correct_plate_text(text, plate_type):
# 省份字符修正
province_corrections = {'0': '沪', '8': '津', 'B': '京'}
# 字母数字修正
alpha_corrections = {'0': 'D', '1': 'I', '2': 'Z'}
# 根据车牌类型格式化
if plate_type == "新能源车牌":
text = text[:8] # 新能源车牌固定8位
else:
text = text[:7] # 普通车牌7位
return text
- 常见OCR错误修正:针对车牌特有的识别错误进行校正
- 格式验证:根据车牌类型验证号码格式是否合法
- 智能填充:对识别不全的车牌进行合理补全
7. 性能优化技术
- 帧采样处理:每5帧处理一次,平衡准确率和性能
- 动态冷却机制:避免重复识别同一车牌
- 队列限流:防止内存溢出
- 结果显示超时:3秒后自动清除旧结果
实现效果
- 实时识别帧率:15-20 FPS(取决于硬件)
- 车牌识别准确率:>90%(在良好光照条件下)
- 支持多种中国车牌类型识别
- 中文显示支持
扩展方向
- 集成更精确的车牌检测模型:进一步提升小尺寸车牌检测能力
- 添加数据库支持:记录识别历史
- 开发GUI界面:更友好的用户交互
- 云端部署:实现多摄像头集中管理
这个项目展示了如何将最新的计算机视觉技术与实际应用场景结合,通过多技术融合解决复杂的识别问题。代码已具备较好的工程实践,如多线程处理和性能优化,可以直接应用于实际场景。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









