







- 引言:本篇博客对影响力最大化领域在2023年CCFA顶会PMLR上发表的一篇论文–DeepIM 进行了介绍。主要围绕在论文的基本情况、DeepIM的主要框架进行介绍。
1. “Deep Graph Representation Learning and Optimization for Influence Maximization” 论文
- DeepIM论文信息概述:
- DeepIM是2023年,发表在CCF A 类会议 PMLR上的。(Proceedings of the 40 th International Conference on Machine Learning, Honolulu, Hawaii, USA. PMLR 202, 2023.)
- 论文链接为: DeepIM论文
- 论文pdf下载链接为: DeepIM论文pdf
- 代码链接为:https://github.com/triplej0079/DeepIM
- DeepIM论文内容简介
- 影响力最大化( Influence Maximization,IM )是指从社交网络中选择一组初始用户,以最大化预期的受影响用户数。研究人员在设计各种传统方法方面已经取得了很大的进展,其理论设计和性能增益已经接近极限。在过去的几年中,基于学习的IM方法已经出现,以实现比传统方法对未知图更强的泛化能力。然而,基于学习的IM方法的发展仍然受到根本性障碍的限制,包括1 )目标函数难以有效求解;2 )难以刻画多样化的底层扩散模式;3 )在各种节点中心性约束的IM变体下适应解决方案的难度。为了应对上述挑战,文章设计了一个新颖的框架DeepIM来生成式地表征种子集的潜在表示,并提出以数据驱动和端到端的方式来学习多样化的信息扩散模式。最后,文章设计了一个新的目标函数来推断灵活的基于节点中心性的预算约束下的最优种子集。在合成数据集和真实数据集上进行了广泛的分析,以证明DeepIM的整体性能。
2. Related Work
- 当前基于学习的IM方法的症结也很明显,基于学习的IM方法的模型复杂度和适应性仍无法与传统方法相提并论。特别是,当前基于ML的算法既不能处理多样化的扩散模式,也不能保证解决方案的质量和模型的可扩展性。“The crux of current learning-based IM methods is also obvious, the model complexity and adaptivity of learning-based IM methods are still not comparable to traditional methods. Particularly, current ML-based algorithms can neither handle the diversified diffusion patterns nor guarantee the quality of the solution as well as the model scalability.”
3. Problem Formulation
- 影响力最大化问题定义:

3.1基于GNN和强化学习的方法存在下述的挑战
-
挑战一:大多数现有的基于学习的IM框架通过计算潜在节点嵌入来选择高影响力的节点。但是他们的目标函数需要在每个动作/优化步迭代更新每个节点的潜在嵌入,无论它们是否包含在当前x中。这给我们处理百万级规模的网络带来了严重的可扩展性问题。
-
挑战二:其次,尽管我们利用深度节点/网络嵌入和各种奖励函数来指导节点选择过程,但现有框架仍然针对特定的扩散模型(例如,他们对M ( · )建模) (显式IC和LT模型)进行裁剪。然而,这些简单的扩散模型并不能满足实际应用的需求。
- 理解:现有的网络对IC、LT等传播模型有定制化的设计。
-
挑战三:此外,为了减轻P - hard影响估计的计算开销,基于学习的IM方法依赖于传统方法的技术,例如基于代理和基于采样的估计方式,这使得可扩展性和泛化性更差。
- 理解:基于采样的估计方式,来获取节点的边际效益。
-
挑战四:最后,存在大量节点中心性受限的IM变体。例如,除了调节种子节点的预算之外,我们可能还需要调节选择种子节点的总成本。基于学习的IM方案根据不同的应用场景设计了不同的目标函数,并且对于所有与节点中心性相关的约束都没有一个定义良好的方案。
4. DeepIM
-
该框架可以分为两个阶段:学习阶段用于表征观测种子集的概率并建模潜在的信息传播分布,推理阶段用于优化连续空间中种子的选择,以最大化影响力传播。
-
方法的整体pipeline如下图所示:
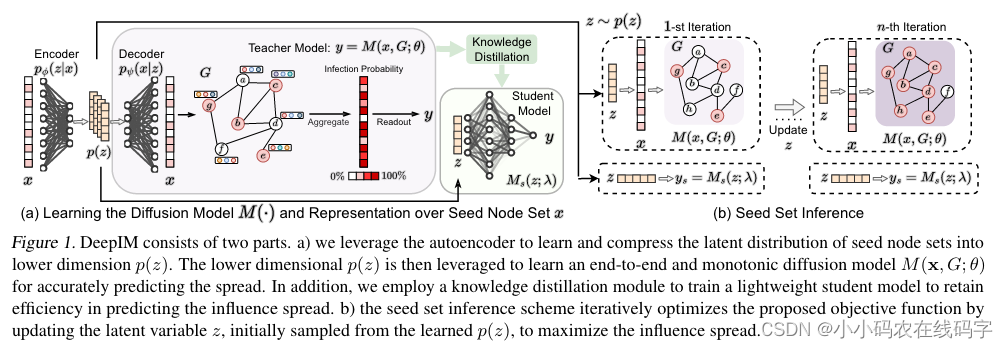
4.1 种子集的学习表示“Learning Representation of Seed Set”
4.1.1 种子节点上的学习概率 Learning Probability over Seed Nodes
-
引入中间嵌变量z,
则种子节点 x x x 出现的概率可以写为: p ( x ) = ∫ p ( x , z ) d z = ∫ p ( x ∣ z ) p ( z ) d z p(x) = \int p(x,z) dz = \int p(x|z)p(z)dz p(x)=∫p(x,z)dz=∫p(x∣z)p(z)dz,后验似然可以写为: p ( z ∣ x ) = p ( x ∣ z ) p ( z ) / p ( x ) p(z|x)=p(x|z)p(z)/p(x) p(z∣x)=p(x∣z)p(z)/p(x) 。 -
如图1所示,(a)图最左侧为一个Encoder和一个Decoder。编码器 f ϕ f_{\phi} fϕ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









