









基于Tensorflow框架的人脸检测总结附代码(持续更新)
基于Tensorflow框架的人脸匹配总结附代码(持续更新)
基于Tensorflow框架的人脸对齐、人脸关键点检测总结附代码(持续更新)
基于Tensorflow框架的人脸活体检测、人脸属性总结附代码(持续更新)
最近利用人脸开源数据库WIDER FACE、64_CASIA-FaceV5、CelebA、300W_LP以及自己做的一个近200张照片的私人数据集复现了人脸检测、人脸匹配、人脸对齐、人脸关键点检测、活体检测、人脸属性等功能,并且将其集成在微信小程序中,以上所有内容将用大概5篇博客来总结。所有数据集下载链接附在下方,所有完整代码附在GitHub链接

WIDER FACE 数据集,包括32203个图像和393703个人脸图像,其中在尺度、姿势、遮挡、表情、装扮、光照等均有所不同。
LFW数据集,是目前人脸识别的常用测试集,其中提供的人脸图片均来源于生活中的自然场景,因此识别难度会增大,尤其由于多姿态、光照、表情、年龄、遮挡等因素影响导致即使同一人的照片差别也很大。并且有些照片中可能不止一个人脸出现,对这些多人脸图像仅选择中心坐标的人脸作为目标,其他区域的视为背景干扰。LFW数据集共有13233张人脸图像,每张图像均给出对应的人名,共有5749人,且绝大部分人仅有一张图片。每张图片的尺寸为250X250,绝大部分为彩色图像,但也存在少许黑白人脸图片。
64_CASIA-FaceV5 该数据集包含了来自500个人的2500张亚洲人脸图片。
CelebA 包含10,177个名人身份的202,599张人脸图片,每张图片都做好了特征标记,包含人脸bbox标注框、5个人脸特征点坐标以及40个属性标记,广泛用于人脸相关的计算机视觉训练任务,可用于人脸属性标识训练、人脸检测训练以及landmark标记等。
300W_LP 该数据集是3DDFA团队基于现有的AFW,IBUG,HEPEP,FLWP等2D人脸对齐数据集,通过3DMM拟合得到的3DMM标注,并对姿态,光照,色彩等进行变化以及对原始图像进行flip(镜像)得到的一个大姿态3D人脸对齐数据集。
1. 人脸检测业务介绍
人脸检测:实际上是在包含人脸的图像中,能够精确识别人脸位置,并用检测框(矩形框)标记,检测框位置通常由(x,y,w,h)四个参数控制,(x,y)为检测框左上角位置坐标,(w,h)代表矩形框的大小;另外也可以由(x1,y1,x2,y2)来表示,(x1,y1)表示矩形框的左上角坐标,(x2,y2)表示矩形框的右下角坐标。人脸检测问题实际上属于目标检测问题,因此,与目标检测方法互通,同时检测人脸
也是图像检测以及图像分割的问题,在得到人脸之后,方便进行接下来的人脸关键点定位以及人脸属性分析等问题。
人脸检测评价指标:
(1)检测率、误报率
检测率:正确检出人脸数量 / 真实人脸数量 ; 误报率: 错误检测 / 总人脸数量
每一个标记只允许有一个检测与之相对应(使用NMS,非极大值抑制)且重复检测视为错误检测
(2)ROC曲线、PR曲线
ROC曲线: ROC的全名叫做Receiver Operating Characteristic,中文名字叫“受试者工作特征曲线”,其主要分析工具是一个画在二维平面上的曲线——ROC 曲线。平面的横坐标是false positive rate(FPR),纵坐标是true positive rate(TPR)。对某个分类器而言,我们可以根据其在测试样本上的表现得到一个TPR和FPR点对。这样,此分类器就可以映射成ROC平面上的一个点。调整这个分类器分类时候使用的阈值,我们就可以得到一个经过(0, 0),(1, 1)的曲线,这就是此分类器的ROC曲线。 什么是ROC曲线?为什么要使用ROC?以及 AUC的计算
PR曲线:PR曲线中的P代表的是precision(精准率),R代表的是recall(召回率),其代表的是精准率与召回率的关系,一般情况下,将recall设置为横坐标,precision设置为纵坐标。 PR曲线详解
(3)速度:FPS(帧率)
FPS:刷新率,帧率越大,画面越流畅;帧率越小,画面越有跳动感。
一些概念的定义
(4)IOU交并比:简单理解为 A∩B / A∪B

2. 人脸检测方法介绍
(1)传统人脸检测方法
VJ框架:利用了积分图特征,使用Adaboost分类器辨别是否为人脸,计算量偏大,参数多。走近人脸检测(2)——VJ人脸检测器及其发展
DPM:最早出现于是应用在目标检测当中,属于HOG算法(纹理特征)的改进,利用手工设计+分类器(SVM、Adaboost、随机森林)模型实现功能。DPM目标检测算法(毕业论文节选)
Casecade:JDA算法(级联人脸检测模型)主要进行边缘分布和条件分布的自适应,同时适配两个分布,然后非常精巧地规到了一个优化目标里。用弱分类器迭代,最后达到了很好的效果,具体详解参考:上手实践ICCV2013的JDA(Joint Distribution Adaptation)方法
《小王爱迁移》系列之二:联合分布适配(JDA)方法简介
(2)从粗粒度到细粒度的级联模型
Cascade CNN:使用尺度级联的方式检测人脸,通过不同尺寸的图片输入来达到较优效果,具体详解参考: 人脸检测——CascadeCNN
Faceness-Net:通过根据面部部位的空间结构和排列来对面部部位的反应进行评分,从而从新的角度寻找面部。考虑到仅部分可见面部的挑战性情况,精心制定了评分机制。根据这一点,网络可以检测到严重遮挡和不受约束的姿势变化下的人脸,这是大多数现有人脸检测方法的主要困难和瓶颈。
详解参考:人脸检测概述(不是人脸识别)
MTCNN/ICC-CNN:使用多尺度级联方式,同时融合人脸+关键点多任务,主题框架类似于cascade。总体可分为P-Net、R-Net、和O-Net三层网络结构。
详解参考:MTCNN工作原理
(3)通用目标检测算法 + 基于人脸问题的优化
随着目标检测算法的不断创新优化,各种基础网络层出不穷:Face RCNN → SSH/RSA → SFD/DSF/AFD → PyramidBox → FaceBoxes → FaceGAN
上述方法部分简介参考博客:
Face R-CNN
PyramidBox 人脸检测算法
人脸检测:Faceboxes(IJCB2017)
FACEGAN: Facial Attribute Controllable rEenactment GAN
3. 人脸检测遇到的问题以及解决方法
(1)人脸可能出现在图像中的任何一个位置;
解决方法:由于人脸可能出现在图像的任何位置,在检测时用固定大小的窗口对图像从上到下、从左到右扫描,判断窗口里的子图像是否为人脸,这称为滑动窗口技术(sliding window)。
(2)人脸可能有不同的大小;
解决方法:提取多尺度特征以及对尺度不敏感的特征,同时考虑Anchor使用;
(3)人脸在图像中可能有不同的视角和姿态;
解决方法:解决低头、侧脸、抬头下的人脸数据预处理问题,对算法进行拆解,对其主干网络、Anchor进行优化,同时挑选合适的loss达到提高性能的效果。
(4)人脸可能被部分遮挡;
解决方法:人群密集时采集的数据,首先选择合适的图像预处理手段,对算法进行拆解后,同样选择合适的主干网络进行优化,选择合适的Anchor参数,使用NMS等目标检测算法。
(5)小人脸检测问题
解决方法:解决感受野问题,进行数据增强处理,提取小尺度特征,择取合适的loss,以及选用改进的NMS算法等。
人脸检测算法综述
格灵深瞳:人脸识别最新进展以及工业级大规模人脸识别实践探讨 | 公开课笔记…

4. 基于Tensorflow + SSD编程实现
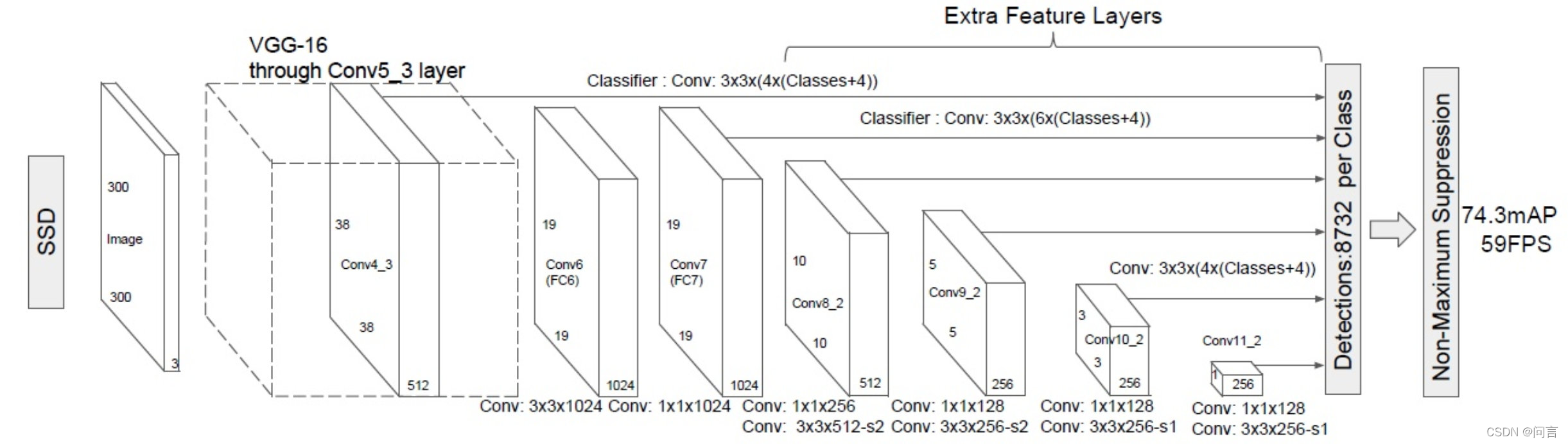
(1)SSD模型介绍
SSD模型是一种one-stage 方法,属于端对端的训练,直接回归目标类别和位置,主干网络为VGGNet,将VGGNet的最后两层替换为卷积层,之后执行多次下采样,得到不同尺度特征图,根据特征图进行目标区域定位并作为检测层的输入,同时在检测层中定义Default bounding boxes,然后完成对类别分数、偏移量的预测。
Anchor:特征图作为检测层的输入,在对其进行处理时,Anchor为特征图上的每一个点,每个点有C个通道,之后将Anchor映射到原图中,用以计算回归以及分类。
Default box:特征图(mn)上存在m * n个单元,每个单元便是一个Anchor,且每个单元生成多个固定尺度和不同长宽比的区域便是box;假设特征图有mn个单元,每个单元对应 k 个default box,每个default box预测 c 个类别概率分布和4个坐标,则会生成 k*(c+4)*(m)*n个输出值。
样本构造:
正样本:根据真实GT box 找到最匹配的piror box 放入候选正样本集,与GTbox满足IOU > 0.5;
负样本:难例挖掘(OHEM),正负样本比为1:3;
SSD(Single Shot MultiBox Detector)模型介绍
SSD模型详解
(2)人脸数据清洗以及数据打包
WIDER FACE数据集标注有很多标签,其中有部分标签在做人脸检测过程中时不需要的,因此在此要有一个数据清洗的过程,同时呢在数据集处理结束后要将数据进行打包,方便后续模型的训练。
数据清洗关键代码如下:
#首先定义各种路径
rootdir = "E:/Python/widerface"
gtfile = "E:/Python/widerface/wider_face_split/wider_face_test_filelist.txt";
im_folder = "E:/Python/widerface/WIDER_test/images";
##这里可以是test也可以是val
fwrite = open("E:/Python/widerface/Main/test.txt", "w")
#首先是读取数据
with open(gtfile, "r") as gt:
while(True):
gt_con = gt.readline()[:-1] #读取行内容
if gt_con is None or gt_con == "":
break
im_path = im_folder + "/" + gt_con; #利用路径拼接定义文件路径
print(im_path)
im_data = cv2.imread(im_path) #读取图片数据
if im_data is None:
continue
##需要注意的一点是,图片直接经过resize之后,会存在更多的长宽比例,所以我们直接加pad
sc = max(im_data.shape)
im_data_tmp = numpy.zeros([sc, sc, 3], dtype=numpy.uint8)
off_w = (sc - im_data.shape[1]) // 2
off_h = (sc - im_data.shape[0]) // 2
##对图片进行周围填充,填充为正方形
im_data_tmp[off_h:im_data.shape[0]+off_h, off_w:im_data.shape[1]+off_w, ...] = im_data
im_data = im_data_tmp
#cv2.imshow("1", im_data)
#cv2.waitKey(0)
numbox = int(gt.readline()) #定义numbox数量
#numbox = 0
bboxes = []
for i in range(numbox):
line = gt.readline()
infos = line.split(" ") #取坐标
#x y w h ---
#去掉最后一个(\n)
for j in range(infos.__len__() - 1):
infos[j] = int(infos[j])
##注意这里加入了数据清洗
##保留resize到640×640 尺寸在8×8以上的人脸
if infos[2] * 80 < im_data.shape[1] or infos[3] * 80 < im_data.shape[0]:
continue
bbox = (infos[0] + off_w, infos[1] + off_h, infos[2], infos[3])
#cv2.rectangle(im_data, (int(infos[0]) + off_w, int(infos[1]) + off_h),
#(int(infos[0]) + off_w + int(infos[2]), int(infos[1]) + off_h + int(infos[3])),
#color=(0, 0, 255), thickness=1)
bboxes.append(bbox)
#cv2.imshow("1", im_data)
#cv2.waitKey(0)
filename = gt_con.replace("/", "_")
fwrite.write(filename.split(".")[0] + "\n")
cv2.imwrite("{}/JPEGImages/{}".format(rootdir, filename), im_data)
xmlpath = "{}/Annotations/{}.xml".format(rootdir, filename.split(".")[0])
writexml(filename, im_data, bboxes, xmlpath)
fwrite.close()
在对数据进行打包时,利用了models-master中dataset_tools工具中create_pascal_tf_record.py文件,在进行微调之后,观察下面列出代码为数据打包的内容
example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(
data['filename'].encode('utf8')),
'image/source_id': dataset_util.bytes_feature(
data['filename'].encode('utf8')),
'image/key/sha256': dataset_util.bytes_feature(key.encode('utf8')),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature('jpeg'.encode('utf8')),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmin),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmax),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymin),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymax),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
'image/object/difficult': dataset_util.int64_list_feature(difficult_obj),
'image/object/truncated': dataset_util.int64_list_feature(truncated),
'image/object/view': dataset_util.bytes_list_feature(poses),
}))
return example
(3)人脸模型训练、调试与测试
模型训练使用models-master中的model_main.py文件,同时使用ssd_resnet_v1_fpn_feature_extractor.py文件进行训练;
修改ssd_resnet50_v1_fpn_shared_box_predictor_640x640_face_sync.config配置文件,代码如下:
#修改
train_config: {
#fine_tune_checkpoint: "PATH_TO_BE_CONFIGURED/model.ckpt"
batch_size: 12
sync_replicas: true
startup_delay_steps: 0
replicas_to_aggregate: 8
num_steps: 100000
data_augmentation_options {
random_horizontal_flip {
}
}
data_augmentation_options {
random_crop_image {
min_object_covered: 0.0
min_aspect_ratio: 0.75
max_aspect_ratio: 3.0
min_area: 0.75
max_area: 1.0
overlap_thresh: 0.0
}
}
optimizer {
momentum_optimizer: {
learning_rate: {
cosine_decay_learning_rate {
learning_rate_base: .04
total_steps: 1000 00
warmup_learning_rate: .013333
warmup_steps: 2000
}
}
momentum_optimizer_value: 0.9
}
use_moving_average: false
}
max_number_of_boxes: 100
unpad_groundtruth_tensors: false
}
model_main.py中的核心代码:
def extract_features(self, preprocessed_inputs):
"""Extract features from preprocessed inputs.
Args:
preprocessed_inputs: a [batch, height, width, channels] float tensor
representing a batch of images.
Returns:
feature_maps: a list of tensors where the ith tensor has shape
[batch, height_i, width_i, depth_i]
"""
preprocessed_inputs = shape_utils.check_min_image_dim(
129, preprocessed_inputs)
with tf.variable_scope(
self._resnet_scope_name, reuse=self._reuse_weights) as scope:
with slim.arg_scope(resnet_v1.resnet_arg_scope()):
with (slim.arg_scope(self._conv_hyperparams_fn())
if self._override_base_feature_extractor_hyperparams else
context_manager.IdentityContextManager()):
_, image_features = self._resnet_base_fn(
inputs=ops.pad_to_multiple(preprocessed_inputs,
self._pad_to_multiple),
num_classes=None,
is_training=None,
global_pool=False,
output_stride=None,
store_non_strided_activations=True,
min_base_depth=self._min_depth,
depth_multiplier=self._depth_multiplier,
scope=scope)
image_features = self._filter_features(image_features)
depth_fn = lambda d: max(int(d * self._depth_multiplier), self._min_depth)
with slim.arg_scope(self._conv_hyperparams_fn()):
with tf.variable_scope(self._fpn_scope_name,
reuse=self._reuse_weights):
base_fpn_max_level = min(self._fpn_max_level, 5)
feature_block_list = []
for level in range(self._fpn_min_level, base_fpn_max_level + 1):
feature_block_list.append('block{}'.format(level - 1))
fpn_features = feature_map_generators.fpn_top_down_feature_maps(
[(key, image_features[key]) for key in feature_block_list],
depth=depth_fn(self._additional_layer_depth),
use_native_resize_op=self._use_native_resize_op)
feature_maps = []
for level in range(self._fpn_min_level, base_fpn_max_level + 1):
feature_maps.append(
fpn_features['top_down_block{}'.format(level - 1)])
last_feature_map = fpn_features['top_down_block{}'.format(
base_fpn_max_level - 1)]
# Construct coarse features
for i in range(base_fpn_max_level, self._fpn_max_level):
last_feature_map = slim.conv2d(
last_feature_map,
num_outputs=depth_fn(self._additional_layer_depth),
kernel_size=[3, 3],
stride=2,
padding='SAME',
scope='bottom_up_block{}'.format(i))
feature_maps.append(last_feature_map)
return feature_maps
之后利用models-master → research → object_detection →export_inference_graph.py文件将模型转化为pb文件,后续调试、测试代码为test_model.py以及相关代码,GitHub
(4)人脸检测模型优化改进策略
更好的学习策略;
更好的损失函数;
更好的泛化技术;
更好的预测方案;
参考博客:调参:深度学习模型24种优化策略

总结:此部分代码基于tensorflow接口而进行训练、调试、测试等步骤,在之后模型训练中会改用其他方式。















 997
997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











