






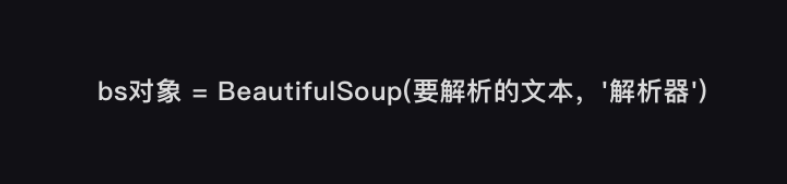
一、BeautifulSoup解析数据


import requests #调用requests库
res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
#获取网页源代码,得到的res是response对象
print(res.status_code) #检查请求是否正确响应
html = res.text #把res的内容以字符串的形式返回
print(html)#打印html
import requests
from bs4 import BeautifulSoup
#引入BS库
res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
html = res.text
soup = BeautifulSoup(html,'html.parser') #把网页解析为BeautifulSoup对象
print(type(soup)) #查看soup的类型
print(soup) # 打印soup


二、BeautifulSoup解析数据
1、find()与find_all()

import requests
from bs4 import BeautifulSoup
url = 'https://localprod.pandateacher.com/python-manuscript/crawler-html/spder-men0.0.html'
res = requests.get (url)
print(res.status_code)
soup = BeautifulSoup(res.text,'html.parser')
items = soup.find_all('div') #用find_all()把所有符合要求的数据提取出来,并放在变量items里
print(type(items)) #打印items的数据类型
print(items) #打印items

import requests
from bs4 import BeautifulSoup # 调用BeautifulSoup库
res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')# 返回一个Response对象,赋值给res
html = res.text# 把Response对象的内容以字符串的形式返回
soup = BeautifulSoup( html,'html.parser') # 把网页解析为BeautifulSoup对象
items = soup.find_all(class_='books') # 通过匹配标签和属性提取我们想要的数据
print(items) # 打印items
print(type(items)) #打印items的数据类型
2、取出列表的每一个值
import requests # 调用requests库
from bs4 import BeautifulSoup # 调用BeautifulSoup库
res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')# 返回一个Response对象,赋值给res
html= res.text# 把Response对象的内容以字符串的形式返回
soup = BeautifulSoup( html,'html.parser') # 把网页解析为BeautifulSoup对象
items = soup.find_all(class_='books') # 通过定位标签和属性提取我们想要的数据
for item in items:
print('想找的数据都包含在这里了:\n',item) # 打印item
3、Tag对象

import requests # 调用requests库
from bs4 import BeautifulSoup # 调用BeautifulSoup库
res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
# 返回一个response对象,赋值给res
html = res.text
# 把res的内容以字符串的形式返回
soup = BeautifulSoup( html,'html.parser')
# 把网页解析为BeautifulSoup对象
items = soup.find_all(class_='books') # 通过定位标签和属性提取我们想要的数据
for item in items:
kind = item.find('h2') # 在列表中的每个元素里,匹配标签<h2>提取出数据
title = item.find(class_='title') #在列表中的每个元素里,匹配属性class_='title'提取出数据
brief = item.find(class_='info') #在列表中的每个元素里,匹配属性class_='info'提取出数据
print(kind,'\n',title,'\n',brief) # 打印提取出的数据
print(type(kind),type(title),type(brief)) # 打印提取出的数据类型
print(kind.text,'\n',title.text,'\n',title['href'],'\n',brief.text) # 打印书籍的类型、名字、链接和简介的文字


三、对象的变化过程

















 1246
1246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









