






Python pandas库㈣
前言
python matplotlib库学习通道
python pandas库㈠学习通道
Python pandas库㈡学习通道
Python pandas库㈢学习通道
一、数据探索
①数据的统计计算
要对数据进行定量描述,就需要用到统计计算。pandas提供了丰富的统计计算方法,可以统计数据的和、平均值、最大/最小值、中位数、众位数、方差、标准差和分位数等。直接使用这些方法,可以使得数据的统计计算简单、高效。
(1)统计数据的和



(2)统计数据的均值


(3)统计数据的最大和最小值

(4)统计数据的中位数



(5)统计数据的众数

(6)统计数据的方差和标准差


(7)统计数据的分位数


(8)案例实现

import pandas as pd
df = pd.read_csv("data/成绩表.csv",engine='python',encoding='utf8')
df1 = df.loc[0:30]
df.loc[31]=['平均分',df1['Python'].mean()]
df.loc[32]=['最高分',df1['Python'].max()]
df.loc[33]=['最低分',df1['Python'].min()]
df.loc[34]=['标准差',df1['Python'].std()]
df.loc[35]=['中位数',df1['Python'].median()]
df.loc[36]=['众数',df1['Python'].mode().loc[0]]
df.loc[31:36]
df.to_csv('data/成绩表2.csv')
x = df.loc[0:30,'Python'].quantile(0.1)
x = df1['Python'].quantile(0.1)
df1[df1['Python'] <=x]



②数据的分组和聚合
在对数据处理的过程中,更多的工作是需要根据不同的分析需求对数据进行统计。比如需要统计某类数据的出现次数,或者需要按照不同级别来分别统计等等,为满足这些需求,比较常用的方法即分组和聚合。pandas中完美支持了这样的功能。
(1)数据的分组



(2)数据的聚合







(3)案例实现

import pandas as pd
df = pd.read_excel('data/Java.xls')
df1 = df.loc[0:29]
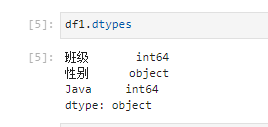
df1.groupby(['班级','性别'],as_index=False)['Java'].mean()
df1.dtypes
df2= df1.groupby(['班级','性别'],as_index=False).agg('count')
df2.columns=['班级','姓名','数量']
df2
df3=df1.groupby(['班级','性别'],as_index=False).agg({'Java':['mean','max','min','std']})
df3.columns=['班级','姓名','平均分','最高分','最低分','标准差']
df3
cont = pd.merge(df2,df3,how='inner')
cont['平均分'] = cont['平均分'].round(2)
cont




③数据的可视化
pandas结合matplotlib库,可以将数据以图表的形式可视化,反映出数据的各项特征。pandas数据的可视化的实现底层依赖于matplotlib,使用该框架前,必须先安装并导入它.

pandas的DataFrame和Series都自带生成各类图表的plot()方法,可以直接通过参数来配置标题,网格,样式等,更加方便和简洁。


(1)折线图





(2)条形图





(3)饼图
饼图常常用来显示数据各个部分占总体的百分比,例如男女性别的百分比,工资收入各项的百分比等等。利用DataFrame对象的plot()方法绘制饼图主要设置kind=‘pie’。


(4)案例实现

import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
df = pd.read_excel('data/期末考试成绩表.xls')
df.loc[26]=['最低分',df['Python'].min(),df['Java'].min()]
df.loc[27]=['最高分',df['Python'].max(),df['Java'].max()]
df.loc[28]=['平均分',df['Python'].mean(),df['Java'].mean()]
df.round(2)
df = df.loc[26:28].round(2)
df
df = df.loc[26:28].rename(columns={'学号':'成绩'})
df
df.plot(x='成绩',y=['Python','Java'],kind='bar',grid=True,title='期末成绩表',legend=True)
df.plot(x='成绩',y=['Python','Java'],kind='bar',subplots=True,layout=(1,2),figsize=(10,2),grid=True,title='期末成绩表',legend=True)
def Score(df):
if df >=90:
return '优秀';
elif df >= 80:
return '良好';
elif df >= 70:
return '中等';
elif df >= 60:
return '及格';
else:
return '不及格';
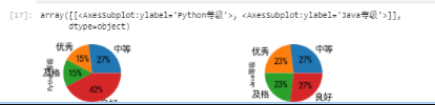
df3 = pd.DataFrame({'Python等级':df['Python'].apply(lambda x:Score(x)),
'Java等级':df['Java'].apply(lambda x:Score(x))})
df_python = df3.groupby('Python等级',as_index=False).c
df_python
df_python.index=['中等','优秀','及格','良好']
df_python.drop('Python等级',axis=1,inplace=True)
df_python.rename(columns={'Java等级':'Python等级'},inplace=True)
df_java= df3.groupby('Java等级',as_index=False).count()
df_java.index=['中等','优秀','及格','良好']
df_java.drop('Java等级',axis=1,inplace=True)
df_java.rename(columns={'Python等级':'Java等级'},inplace=True)
df_java
grade = pd.concat([df_python,df_java],axis=1)
grade
grade.plot(y=['Python等级','Java等级'],kind='pie',autopct='%.0f%%',subplots=True,layout=(1,2),figsize=(10,2),fontsize=14,legend=False)
#grade.plot(['Python等级','Java等级'],kind='pie',autopct='%.0f%%',subplots=True,layout=(1,2),figsize=(10,2),fontsize=14,legend=False)




二、综合案例
①用户职业数据描述

import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
df = pd.read_csv('data/u.data')
df1=df.groupby(['职业'],as_index=False)['年龄'].mean().round()
df1.columns=['职业','平均年龄']
df1=df1.drop(index=[18])
df1.sort_values(by='平均年龄',axis=0,ignore_index=True,ascending=False,inplace=True)
df1.plot(x='职业',y='平均年龄',kind='bar',grid=True,title="职业的平均年龄")
df2 = df.groupby(['职业'],as_index=False).agg('count')
df2.drop(['编号','年龄'],axis=1,inplace=True)
df2.columns=['职业','人数']
df2=df2.drop(index=[12,13,15,18])
df2.sort_values(by='人数',axis=0,ignore_index=True,ascending=False,inplace=True)
df2
df2.head()
df3 = df.groupby(['职业','性别'],as_index=False).agg('count')
df3.drop(['编号'],axis=1,inplace=True)
df3.columns=['性别','职业','人数']
df4=df3.loc[:1]
df5=df3.loc[5:6]
cont=pd.concat([df4,df5],ignore_index=True)
cont
cont.index=['ad-F','ad-M','ed-F','ed-M']
cont.plot(y='人数',kind='pie',autopct='%.0f%%',fontsize=14,legend=False)





②音乐综合项目

import pandas as pd
import jieba
from wordcloud import WordCloud, ImageColorGenerator
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#读取数据
df1 = pd.read_csv('data/music.csv')
df2 = pd.read_csv('data/record.csv')
df3 = pd.read_csv('data/user.csv')
#数据合并
cont = pd.merge(df1,df2,how='inner',on='歌曲名')
result = pd.merge(cont,df3,how='inner',on='id')
result
#数据清洗
result = result.dropna() #删除NAN
result=result[~(result['生日'] == '用户未填写') & ~(result['所在地区'] == '用户未填写')] #去除未填写
result=result.drop_duplicates() #去除重复值
#1.按月份展示用户对该歌单中歌曲的评论数量.
result['评论时间']=result['评论时间'].str.split(" ",1,expand=True)[0] #截取年月日
result['评论时间']=result['评论时间'].str.rsplit("-",1,expand=True)[0] #截取年月
res=result.groupby(['评论时间'],as_index=False).agg('count')
res=res[['评论时间','歌曲名']]
res.columns=['评论时间','评论数量']
res.plot(x='评论时间',y='评论数量',kind='barh',grid=True,title="不同年月歌曲评论数")
#2.最受欢迎的歌曲Top10
songlt = result.groupby(['歌曲名'],as_index=False).agg('count')
songlt=songlt[['歌曲名','歌手']]
songlt.columns=['歌曲名','受欢迎度']
songlt.sort_values(by='受欢迎度',axis=0,ascending=False,inplace=True)
songlt=songlt.head(10) #拿出top10歌曲
songlt=songlt.reset_index(drop=True) #重置标签值
songlt.plot(x='歌曲名',y='受欢迎度',kind='bar',grid=True,title='最受欢迎的歌曲Top10')
#3.最受欢迎的歌手Top10(不包括合唱团、群星)
singer= result.loc[~(result['歌手'].str.contains("群星") |result['歌手'].str.contains("合唱团") | result['歌手'].str.contains("合唱队")| result['歌手'].str.contains("军乐团") | result['歌手'].str.contains("凤凰传奇")|result['歌手'].str.contains("乐团"))]
#去除群星、乐队、合唱团、合唱队、军乐团、组合
singer =singer.groupby(['歌手'],as_index=False).agg('count')#获取歌手受欢迎数
singer=singer[['歌手','歌曲名']]
singer.columns=['歌手','受欢迎程度']
singer['歌手']=singer['歌手'].str.split(",",1,expand=True)[0] #拆分
singer['歌手']=singer['歌手'].str.split("、",1,expand=True)[0] #拆分
singer=singer.sort_values(by='受欢迎程度',ascending=False,ignore_index=True)#按受欢迎数排序
singer=singer.drop(index=[5]) #删除重复
singer.reset_index(drop=True) #重置标签
singer=singer.head(10) #提取最受欢迎top10歌手
singer['歌手']=singer['歌手'].str.strip("[]").str.lstrip("'").str.rstrip("'") #去除[] ''
singer.plot(x='歌手',y='受欢迎程度',kind='barh',grid=True,title='最受欢迎的歌手Top10')#最受欢迎的歌手Top10(不包括合唱团、群星)
#4.评论该歌单的用户的省份分布。
province = result.copy()
province['所在地区']=result['所在地区'].str.split("·",1,expand=True)[0] #去掉省份后面的市
pro=province.groupby(['所在地区'],as_index=False).agg('count') #得到用户的省份分布
pro=pro[['所在地区','歌曲名']]
pro.columns=['所在地区','用户的省份分布']
pro.plot(x='所在地区',y='用户的省份分布',kind='bar',grid=True,title='用户的省份分布')
#5.评论该歌单用户的年龄分布(按00,90,80,70统计)。
age = result.copy()
age['生日'] = pd.to_datetime(age['生日'],unit='s')
age["生日"] = age['生日'].apply(lambda x:x.year)
def Birthday(age):
if 1940<=age<1950:
return'40年代'
elif 1950<=age<1960:
return'50年代'
elif 1960<=age<1970:
return'60年代'
elif 1970<=age<1980:
return'70年代'
elif 1980<=age<1990:
return'80年代'
elif 1990<=age<2000:
return'90年代'
elif 2000<=age<2010:
return'00年代'
elif 2010<=age<2020:
return'10年代'
elif 2020<=age<2030:
return'20年代'
else:
return'错误'
age['生日'] = age['生日'].apply(lambda x:Birthday(x))
age[age['生日'] == '错误'] #筛选出有错误年代的值
age=age.drop(index=[2186]) #删除一个2100年错误值
bir = age.groupby(['生日'],as_index=False).agg('count') #得到用户的年龄分布总数
bir = bir[['生日','歌曲名']]
bir.columns = ['生日年代','人数']
bir=bir.drop(index=[1,2]) #删除10年代、20年代
bir
bir.index=['00年代','70年代','80年代','90年代']
bir.plot(x='生日年代',y='人数',kind='pie',autopct='%.0f%%',fontsize=14,legend=False,title='用户的年龄分布')
#6.用户愿意花钱听歌的省份分布。
member = result.copy()
member['所在地区']=result['所在地区'].str.split("·",1,expand=True)[0] #去掉省份后面的市
member=member.groupby(['所在地区','vip'],as_index=False).agg('count')
member=member[~member['vip'].isin(["普通用户"])]
member = member[['所在地区','vip','歌曲名']]
member.columns= ['所在地区','vip类型','人数']
member.reset_index(drop=True) #重置标签
meby=member[~member['vip类型'].isin(["黑胶会员"])] #音乐包用户
mebv=member[member['vip类型'].isin(["黑胶会员"])] #黑胶会员
mebType = pd.merge(mebv,meby,how='outer',on='所在地区') #交集
mebType['vip类型_y']=mebType['vip类型_y'].fillna('音乐包用户') #填充列为音乐包用户
mebType['人数_y'] = mebType['人数_y'].fillna(0) #填充NAN为0
mebType=mebType.astype({'人数_y':'int64'}) #变换类型为int64
mebType['总会员数'] = mebType.sum(axis=1) #统计总人数
mebType.columns=['所在省份','付费类型1','人数','付费类型2','人数','付费总人数']
mebType.plot(x='所在省份',y='付费总人数',kind='bar',grid=True,title="用户愿意花钱听歌的省份分布")
#7.用户愿意花钱听歌的年龄分布。
mebage=age.copy()
mebage['所在地区']=result['所在地区'].str.split("·",1,expand=True)[0] #去掉省份后面的市
mebage = mebage[~(mebage['vip'] == '普通用户')] #筛选出黑胶会员与付费音乐包
mebage = mebage.groupby(['生日'],as_index=False).agg('count')
mebage=mebage[['生日','歌曲名']]
mebage.columns=['年龄分布','人数']
mebage=mebage.drop(index=[1,2]) #删除10年代 20年代
mebage.columns=['年龄分布','付费总人数']
mebage.index=['00年代','70年代','80年代','90年代']
mebage.plot(x='年龄分布',y='付费总人数',kind='pie',autopct='%.0f%%',fontsize=14,legend=False,title="用户愿意花钱听歌的年龄分布")
#8.通过词云展示用户的评论情况。
wordle = age.copy()
wordle['所在地区']=wordle['所在地区'].str.split("·",1,expand=True)[0]
content = ''.join(wordle['评论'])
split_result = jieba.cut(content) #分词,返回结果为词的列表
text = ' '.join(split_result) #将分好的词连成字符串
mask = np.array(Image.open('panda.png'))
stop_words =['哈哈','我','我们','你','就','在','也','这个','里','这','是','多多','着哪','了','的', '负责', '优先', '有', '能','能够', '善于','熟悉', '和', '等', '及','数据分析','较','较强', '强','经验','良好','教','分析', '数据', '相关', '者', '或','工作','能力','以上','具备','具有','对','年','产品','以上学历'] #停用词(无意义的词,不计入词频统计)
# 使用WordCloud生成词云
wc = WordCloud(font_path='C:\Windows\Fonts\STZHONGS.TTF', #设置词云字体
mask=mask, #以该参数值作图绘制词云
stopwords=stop_words, #去掉的停词
collocations=False, #避免词重复
background_color='white') #设置背景颜色
image = wc.generate(text) #生成词云图像
image_colors = ImageColorGenerator(mask) #从背景图建立颜色方案
wc.recolor(color_func=image_colors) #将词云颜色设置为背景图方案
# 绘词云图展现结果,将matplotlib的图表直接嵌入到jupyter lab之中
%matplotlib
plt.axis('off') #去除坐标轴
plt.imshow(image)
plt.savefig('音乐评论.jpg') #保存为词云图











总结

















 1381
1381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









