







问题描述:
明明想在学校中请一些同学一起做一项问卷调查。
为了实验的客观性,他先用计算机生成了N个1到1000之间的随机整数,对于其中重复的数字,只保留一个,把其余相同的数去掉,不同的数对应着不同的学生的学号。
然后再把这些数从小到大排序,按照排好的顺序去找同学做调查。
请你协助明明完成“去重”与“排序”的工作。
输入格式:
输入文件包含2行,第1行为1个正整数,表示所生成的随机数的个数:N 。
第2行有N个用空格隔开的正整数,为所产生的随机数。
输出格式:
输出文件也是2行,第1行为1个正整数M,表示不相同的随机数的个数。
第2行为M个用空格隔开的正整数,为从小到大排好序的不相同的随机数。
数据范围
1≤N≤100
输入样例:
10
20 40 32 67 40 20 89 300 400 15
输出样例:
8
15 20 32 40 67 89 300 400
算法
(排序,去重) O ( n l o g n ) O(nlogn) O(nlogn);
考察了两个函数的使用:
思路:
1、读入数组
2、使用sort()函数排序数组
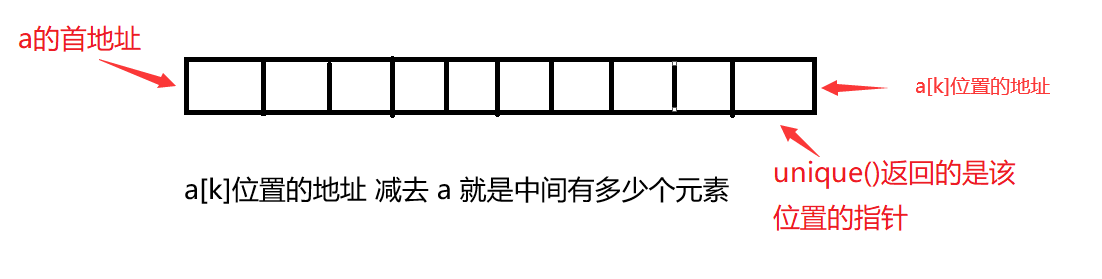
3、unique:可以将序列中所有相邻的重复元素删除(只保留一个)。此处的删除,并不是真的删除,而是指重复元素的位置被不重复的元素覆盖了。最后会返回不重复序列的后一个位置(的指针)
时间复杂度分析
sort()需要 O ( n l o g n ) O(nlogn) O(nlogn)的时间, unique需要 O ( n ) O(n) O(n)的时间,因此总时间复杂度是 O ( n l o g n ) O(nlogn) O(nlogn)
C++代码:
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 110;
int n;
int a[N];
int main()
{
cin >> n;
for (int i = 0; i < n; i++) cin >> a[i];
sort(a, a + n);
int k = unique(a, a + n) - a;
cout << k << endl;
for (int i = 0; i < k; i++) cout << a[i] << " ";
}
注:第18行的两个指针相减,会返回两个指针之间元素的个数。
假设一共有k个不同的元素,那么unique函数会返回a[k]的指针,因此减去a这个指针后,就得到k了。















 2265
2265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









