






Training of Multi-Layer Neural Network
反向传播算法(back-propagation algorithm)的意义在于它提供了一个系统的方法来确定隐藏节点的误差。
神经网络的输入数据通过输入层、隐藏层和输出层传输。相反,在反向传播算法中,输出错误从输出层开始向后移动,直到到达右边的下一个隐藏层到达输入层。 这个过程被称为反向传播,因为它类似于输出错误向后传播。即使在反向传播算法中,信号仍然通过连接线传递,权重也是相乘的。唯一的区别是输入和输出信号的方向相反。

Back-Propagation Algorithm
 节点的误差被定义为直接右层(本例中为输出层)反向传播的增量的加权和。
节点的误差被定义为直接右层(本例中为输出层)反向传播的增量的加权和。


如下式子全对照上图的标号



如果我们有额外的隐藏层,我们只需为每个隐藏层重复相同的反向过程,并计算所有的增量。一旦计算出所有的增量,我们就可以训练神经网络了。只要用下面的公式来调整各层的重量。

对应多层的单个点(第二层)图解:
 对应多层的单个点(第一层)图解:
对应多层的单个点(第一层)图解:

反向传播算法定义了隐藏层错误,因为它从输出层向后传播输出错误。一旦得到隐含层误差,利用 delta 规则调整各层的权重。反向传播算法的重要性在于它提供了一个系统的方法来定义隐藏节点的误差。
Momentum
然而,有各种权重调整方法可用。在神经网络的训练过程中,使用先进的权重调整公式的好处包括更高的稳定性和更快的速度。这些特点特别有利于深度学习,因为它很难训练。
这一节只涵盖了包含动量的公式,这些公式已经使用了很长时间。
动量 m 是增加到 delta 规则中用来调整重量的一个术语。动量项的使用在一定程度上推动权重向某个方向调整,而不是立即产生变化。它的作用类似于物理动量,阻碍物体对外力的反作用。
 m-是前一个动量,而 β 是小于1的正常数
m-是前一个动量,而 β 是小于1的正常数

Cost Function and Learning Rule
神经网络的监督式学习是一个调整权值以减少训练数据误差的过程。在这种情况下,衡量神经网络的误差是成本函数。神经网络的误差越大,代价函数的值越高。神经网络的监督式学习有两种主要的成本函数。
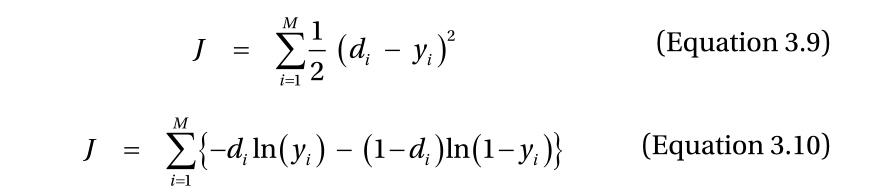
where yi is the output from the output node,
di is the correct output from the training data,
and M is the number of output nodes.
方程式3.9中的误差平方和。这个代价函数是神经网络输出 y 和正确输出 d 之差的平方,如果输出和正确输出相同,误差为零。相比之下,两个值之间的差异越大,错误就越大。
 前一章的 delta 规则不仅来自于这个函数,反向传播算法也是如此。回归问题仍然使用这个代价函数。
前一章的 delta 规则不仅来自于这个函数,反向传播算法也是如此。回归问题仍然使用这个代价函数。
现在,考虑公式3.10的成本函数。下面的公式,在花括号里面,叫做交叉熵函数。
简化版:
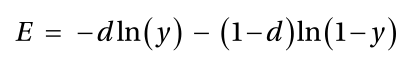
完整版:
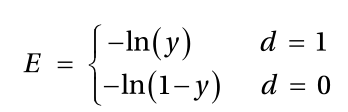
根据对数的定义,输出 y 应该在0和1之间。


交叉熵函数与方程3.9的二次函数的主要区别是它的几何增长。换句话说,交叉熵函数对误差更敏感。因此,从交叉熵函数导出的学习规则通常被认为具有更好的性能。建议您使用跨熵驱动的学习规则,除非不可避免的情况,如回归。
由于代价函数的选择影响到学习规则,即反向传播算法的公式,所以我们对代价函数有很长的介绍。具体来说,输出节点的增量计算略有变化。
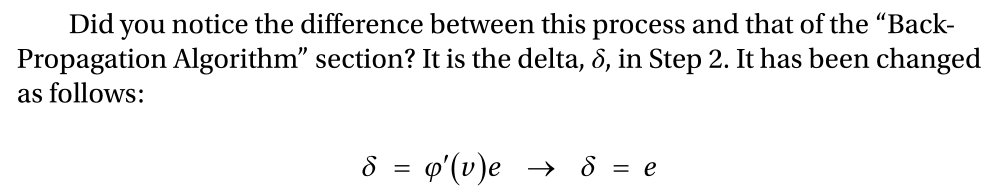
关键是当学习规则基于交叉熵和 Sigmoid形函数时,输出层和隐藏层使用了不同的 delta 计算公式。
与前面的示例代码不同,Sigmoid形函数的衍生物不再存在。这是因为,对于交叉熵函数的学习规则,如果输出节点的激活函数是 Sigmoid型,则增量等于输出错误。当然,隐藏节点遵循与前面的反向传播算法相同的过程。
 成本函数。你在第一章看到过拟合是机器学习的每一个技术都面临的一个挑战性问题。你也看到了克服过拟合的主要方法之一是使用正则化使模型尽可能简单。在数学意义上,正则化的本质是将权重之和加到成本函数中
成本函数。你在第一章看到过拟合是机器学习的每一个技术都面临的一个挑战性问题。你也看到了克服过拟合的主要方法之一是使用正则化使模型尽可能简单。在数学意义上,正则化的本质是将权重之和加到成本函数中

其中 λ 是决定多少连接权重反映在成本函数上的系数。
当其中一个输出错误和权重保持较大时,该代价函数保持较大的值。因此,仅仅使输出错误为零将不足以降低成本函数。为了降低成本函数的值,误差和权重都应尽可能地控制在最小。然而,如果一个权重变得足够小,相关的节点将实际上断开。因此,不必要的连接被消除,神经网络变得更简单。由于这个原因,神经网络的过度拟合可以通过增加权重和的成本函数,从而减少它。
总之,神经网络监督式学习的学习规则是从代价函数推导出来的。学习规则和神经网络的性能取决于代价函数的选择。交叉熵函数是近年来代价函数研究的热点。用于处理过拟合的正则化过程作为代价函数的变量来实现。
Example: Cross Entropy Function

 训练数据包含下表所示的 四个相同元素。当我们忽略输入数据的第三个数字时,这个训练数据集将显示一个 xor 逻辑操作。每个元素最右边的粗体字是正确的输出
训练数据包含下表所示的 四个相同元素。当我们忽略输入数据的第三个数字时,这个训练数据集将显示一个 xor 逻辑操作。每个元素最右边的粗体字是正确的输出
XOR:奇数个1是0,偶数个1是1

Comparison of Cost Functions
交叉熵驱动训练以更快的速度减少了训练误差。
换句话说,交叉熵驱动的学习规则产生更快的学习过程。
这就是为什么大多数深度学习的代价函数都采用交叉熵函数的原因。















 3902
3902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









