







一、计算列表中重复元素出现的次数
collections模块—— Counter - Eva_J - 博客园
1.普通
word_counts = Counter(word)#Counter({'R03': 8, 'C01': 6, 'L01': 4,})2.求最大
top_one = word_counts.most_common(n)#n为几就是最大的前几个二、对列表中的重复元素只保留一个
三、邻接表转化为邻接矩阵
import networkx as nx
import numpy as np
G = nx.read_weighted_edgelist("邻接表.txt")
A = nx.to_numpy_array(G)四、报错:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xff in position 0: illegal multibyte sequence
可能是编码错误,记得将txt文件中的编码换位UTF-8
with open(edge_file, 'r',encoding='UTF-8-sig') as fr:五、使用sklearn中的LabelEncoder将Label标准化的方法:
LabelEncoder可以将标签分配一个0—n_classes-1之间的编码
使用sklearn之LabelEncoder将Label标准化的方法_Python_脚本之家![]() http://www.zzvips.com/article/147551.html六、数据归一化 MinMaxScaler
http://www.zzvips.com/article/147551.html六、数据归一化 MinMaxScaler
将每个元素(特征,feature)转换成给定范围的值。
fit(self, X[, y]):计算给定数据集X的最大/小值用于之后的放缩(这一步没有进行放缩)
transform(self, X):将数据集X放缩至给定区间
(self, X[, y]):计算并将数据放缩至给定区间,相当于fit()+transform()
数据归一化 MinMaxScaler__Ronnie_的博客-CSDN博客_minmaxscaler
Python:sklearn数据预处理中fit(),transform()与fit_transform()的区别_anshuai_aw1的博客-CSDN博客_pca.fit_transform 七、PCA降维
PCA降维实例[GridSearchCV求最优参]_Doris_H_n_q的博客-CSDN博客
降维后通常会破坏归一化,需再次归一化
八、列表中的列表为字符串改为普通列表
1.内部是数字
如第二行改为第一行:

df = pd.read_excel('test_positive_onehot.xlsx')
label_list = list(df['label'])
result = [i[1 : -1].split(', ') for i in label_list]
new = []
for ne in result:
new.append(list(map(int, ne)))
print(new)2.内部是字符串
如第一行改为第二行
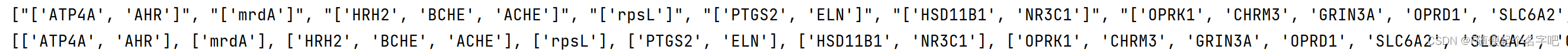
result = [i[1: -1].split(', ') for i in drug_gene['target_list'].to_list()]
all_gene_list = []
for gene_list in result:
temp_list = []
for gene in gene_list:
temp_list.append(gene.replace("'",""))
all_gene_list.append(temp_list)
print(all_gene_list)其中,gene.replace("'","")是去除字符串自带的引号,因为result的结果是这样的















 8298
8298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









