









前言
项目思路
百度指数能够反映不同地区对某关键词的搜索频率,因此可以作为不同地区对某关键词关注程度的代理变量。例如统计不同地区对财神信仰的虔诚程度,我们可以使用以下公式来衡量
然而,即使我们有了数据,单凭直观地数据浏览是难以把控其空间变化以及时间变化的,需要对其进行有效的可视化。使用百度开源的pyecharts可以将地域数据在地图上进行可视化,方便我们直观地观察数据的变动。因此,提出了本项目百度指数qdata + 地图可视化pyechart,在github可获取相关文件,项目仓库。
流程图
下图是本项目的构思图,以及对应使用的关键包
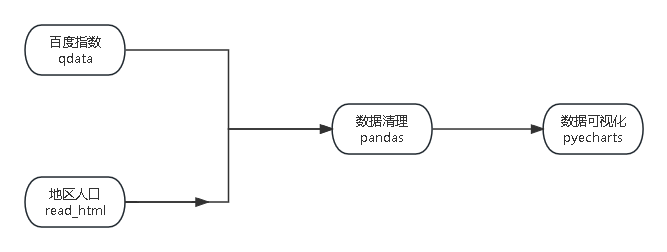
数据来源主要有两块:
- 百度指数:主要使用
qdata实现 - 地区人口:主要使用
pandas的read_html()方法实现
然后使用pandas对数据进行清晰,并将清洗后的数据用pyecharts进行可视化
一、数据获取
爬取百度指数
使用qdata这个包可以爬取到百度指数,不过需要使用自己在百度指数网站的cookie
该代码中有三个需要调整的地方
- 【
cookie】将自己的cookie复制到对应的变量中,可以多添加几个cookie来规避官网检测 - 【关键词】将自己需要的关键词填入到
keywords_list变量中,注意:有些关键词可能并没有收录到百度指数中 - 【间隔时间】
time.sleep(random.randint(10, 30))中的间隔时间调的更高,可以有效降低被检测的 风险,如果你有的cookie较少,建议调高间隔时间 - 运行该代码会自动在本机文件夹下创建一个名为
data_folder的新文件夹,并保留不同省域的数据。总表数据baidu.csv保留到脚本同级目录下。
import pandas as pd
from qdata.baidu_index import get_search_index
from qdata.baidu_index import PROVINCE_CODE, CITY_CODE
import time
import random
import os
import logging
current_path = os.path.dirname(os.path.abspath(__file__))
new_folder = "data_folder"
new_folder_path = os.path.join(current_path, new_folder)
if os.path.exists(new_folder_path):
print("文件夹已经存在")
else:
os.mkdir(new_folder_path)
keywords_list = [['财神'], ['财神方位'], ['财神爷图片']]
province = PROVINCE_CODE
print(province)
# 返回的是搜索指数,而不是资讯指数
start_date = '2011-01-01'
end_date = '2022-12-31'
cookie1 = 'your_cookies1' # 多添加几个cookie,降低被官网反扒的风险
cookie2 = 'your_cookies2'
cookies = [cookie1, cookie2]
data_all1 = pd.DataFrame()
# 按不同省请求数据
for key, value in province.items():
data_all = pd.DataFrame()
province_name = key
print('正在爬取{}'.format(province_name))
area = int(value)
cookie = random.choice(cookies)
if cookie == cookie1:
cookie_name = 'cookie1'
print('cookie1')
else:
cookie_name = 'cookie2'
print('cookie2')
try:
baidu_list = list(get_search_index(keywords_list=keywords_list,
start_date=start_date, end_date=end_date, cookies=cookie, area=area))
except:
logging.info("{}失效了".format(cookie_name))
cookies.remove(cookie)
data = pd.DataFrame(baidu_list)
data['province'] = province_name
data['keyword'] = data['keyword'].apply(lambda x: x[0])
data['index'] = data['index'].astype('int')
data['year'] = data.date.apply(lambda x: x.split('-')[0])
data.to_csv(
'{}\\{}.csv'.format(new_folder_path, province_name), index=False)
data.drop(['date'], axis=1, inplace=True)
data_all = data.groupby(['keyword', 'year', 'type'], as_index=False)['index'].agg(
{'mean': 'mean', 'max': 'max', 'sum': 'sum'})
data_all['province'] = province_name
temp_column = data_all.pop('province')
data_all.insert(0, 'province', temp_column)
data_all1 = pd.concat([data_all1, data_all], ignore_index=True)
time.sleep(random.randint(10, 30))
# 更新数据
data_all1.to_csv(
'{}\\baidu.csv'.format(current_path), index=False)
省级行政人口
各省级行政区的人口数据是在官网获取的,该网站收录了2003年到2022年的各省级行政区的人口数
- 使用
read_html爬取静态网站的表格数据是真的很方便 - 然后港澳等地只有2022年的人口数,其他年度使用2022年的数据进行插补
- 人口数据文件保存到该脚本同级目录下的
population.csv中
import pandas
import requests
from bs4 import BeautifulSoup
import pandas as pd
url2 = 'https://www.maigoo.com/news/480576.html' # 2021-2003
url3 = 'https://www.maigoo.com/top/431525.html' # 2022-2022
def adjust_porvince(x):
return x[0:2]
"""
url2
"""
df_list = pd.read_html(url2, encoding='utf-8', header=0)
df1 = df_list[0]
df2 = df_list[1]
df2.loc[len(df2)] = df2.sum()
df2.iloc[-1, 0] = '总人'
df1['地区'] = df1['地区'].apply(lambda x: adjust_porvince(x))
df2['地区'] = df2['地区'].apply(lambda x: adjust_porvince(x))
df2021_2003 = pd.merge(df1, df2, how='left', on='地区')
"""
url3
"""
df_list1 = pd.read_html(url3, encoding='utf-8', header=0)
df3 = df_list1[0]
df3.rename(columns={'省级行政区': '地区'}, inplace=True)
df3['地区'] = df3['地区'].apply(lambda x: adjust_porvince(x))
df3.loc[len(df3)] = df3.loc[0]
df2022 = df3[1:]
df_population = df2022[['地区', '2022年']].merge(df2021_2003, how='left', on='地区')
row_fillna = df_population.loc[(df_population['2022年'].notnull()) & (
df_population['2021年'].isnull()), '2022年']
# 使用2022年的数据为缺失值插补
for year in range(2003, 2022):
df_population.loc[df_population['{}年'.format(
year)].isnull(), '{}年'.format(year)] = row_fillna
print(df_population)
df_population.to_csv('population.csv', index=False)
数据清洗合并
由于不同地区的人口数不同,这就导致即使A地的百度指数比B地的百度指数高,但是就某关键词的实际关注度可能出现B地高于A地。所以我们需要使用各地人口数据对百度指数进行调整,也就是将百度指数调整为,关注程度
- 合并和清洗后的数据保存在脚本同级目录下的
data_all.csv文件中
import pandas as pd
index = pd.read_csv("baidu.csv", encoding='gbk')
population = pd.read_csv('population.csv', encoding='utf-8')
population.rename(columns={'地区': 'province'}, inplace=True)
df = pd.DataFrame()
for year in range(2003, 2023):
df_tmp = pd.DataFrame()
year_ = '{}年'.format(year)
df_tmp = population.loc[:, ['province', year_]]
df_tmp.rename(columns={'{}年'.format(year): 'population'}, inplace=True)
df_tmp['year'] = int(year)
df = pd.concat([df, df_tmp])
index_columns = index.province.unique().tolist()
index['province'] = index.province.apply(lambda x:str(x)[:2])
data_all = index.merge(df,how='left',on=['province','year'])
def adjust_province(x,index_columns):
for place in index_columns:
if place.startswith(x):
return place
data_all['province'] = data_all.province.apply(lambda x:adjust_province(x,index_columns))
data_all['mean'] = data_all['mean']/data_all['population']
data_all['max'] = data_all['max']/data_all['population']
data_all['sum'] = data_all['sum']/data_all['population']
data_all.to_csv('data_all.csv', index=False)
二、数据可视化
pyecharts是百度一个开源的可视化工具,能够高效的进行数据可视化,尤其是进行地域数据可视化。pyecharts的官网
可视化代码参考了该知乎博客,将整理后的数据进行可视化
- 可视化中会将关键词关注度的五等分点作为可视化色块的分界点
- 默认对分省域百度指数关注度的均值进行可视化,当然也可以调整
descri变量来将其他统计量如max、sum作为可视化标准 - 由于百度指数需要关键词,因此在本处的可视化代码中,也需要将对应的关键词填入到
keyword变量中
from pyecharts import options as opts
from pyecharts.charts import Map, Timeline
from pyecharts.faker import Faker
import pandas as pd
from pyecharts import options as opts
from pyecharts.globals import ThemeType
import numpy as np
# df = pd.read_csv("baidu.csv", encoding='gbk')
df = pd.read_csv('data_all.csv', encoding='utf-8')
df = df.loc[(df.keyword == '财神') & (df['type'] == 'all'),
['province', 'keyword', 'year', 'mean']]
print(df.head())
provinces = ['山东省', '贵州省', '江西省', '重庆市', '内蒙古自治区', '湖北省', '辽宁省', '湖南省', '福建省', '上海市', '北京市', '广西壮族自治区', '广东省', '四川省', '云南省', '江苏省',
'浙江省', '青海省', '宁夏回族自治区', '河北省', '黑龙江省', '吉林省', '天津市', '陕西省', '甘肃省', '新疆维吾尔自治区', '河南省', '安徽省', '山西省', '海南省', '台湾省', '西藏自治区', '香港特别行政区']
def change_province_name(x):
for i in provinces:
if i.startswith(x):
return i
df['province'] = df['province'].apply(lambda x: change_province_name(x))
def timeline_map(df, descri='mean', step=0.2, keyword='财神'):
df = df.loc[(df['keyword'] == keyword)]
visualmap_data = []
for i in np.arange(0, 1 + step, step):
visualmap_data.append(df[descri].quantile(i))
print(visualmap_data)
print(df['mean'].max())
# 切分多期数据
data_list = []
for year in range(df.year.min(), df.year.max() + 1):
data_list.append(df.loc[df.year == year, ['province', 'year', descri]])
tl = Timeline(init_opts=opts.InitOpts(page_title='',
theme=ThemeType.CHALK,
width='1000px', height='620px'))
for data in data_list:
year = data.year.unique()[0]
data.drop(['year'], axis=1, inplace=True)
f_map = (
Map(init_opts=opts.InitOpts(width='900px',
height='500px',
page_title='',
bg_color=None))
.add(series_name=keyword,
data_pair=data[['province', descri]].values.tolist(),
maptype='china',
is_map_symbol_show=False)
.set_global_opts(
title_opts=opts.TitleOpts(title='全国各省级行政区{}百度指数'.format(keyword),
pos_left='center',),
legend_opts=opts.LegendOpts(
is_show=True, pos_top="40px", pos_right="30px"),
visualmap_opts=opts.VisualMapOpts(
is_piecewise=True, range_text=['高', '低'], pieces=[
{"min": visualmap_data[4],
"max": visualmap_data[5], "color": "#751d0d"},
{"min": visualmap_data[3],
"max": visualmap_data[4], "color": "#ae2a23"},
{"min": visualmap_data[2],
"max": visualmap_data[3], "color": "#d6564c"},
{"min": visualmap_data[1],
"max": visualmap_data[2], "color": "#f19178"},
{"min": visualmap_data[0], "max": visualmap_data[1], "color": "#f7d3a6"}]),
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=True),
markpoint_opts=opts.MarkPointOpts(
symbol_size=[90, 90], symbol='circle'),
effect_opts=opts.EffectOpts(is_show='True',)
)
)
tl.add(f_map, "{}年".format(year))
tl.add_schema(is_timeline_show=True,
play_interval=1000,
symbol=None,
is_loop_play=True)
return tl
timeline_map(df).render("{}.html".format(keyword))
最后拖拽渲染文件到浏览器中,这里是财神.html即可看见对应的可视化结果
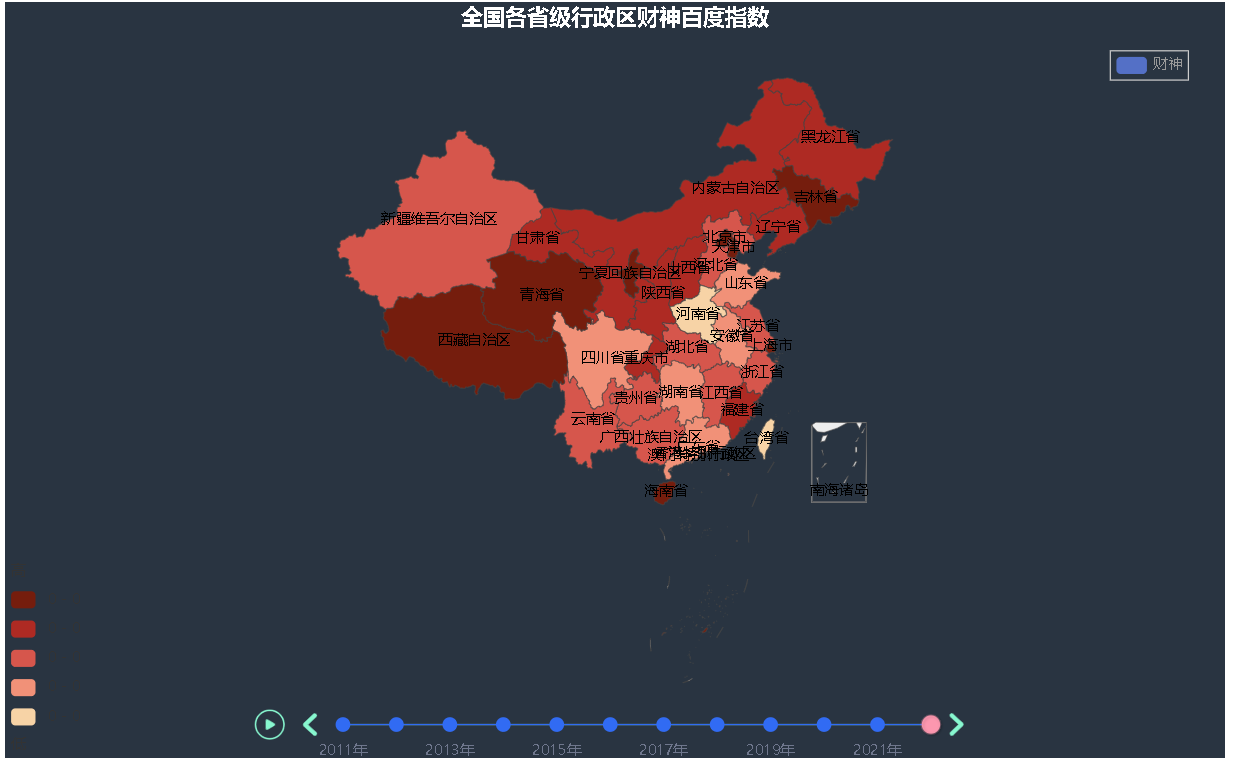
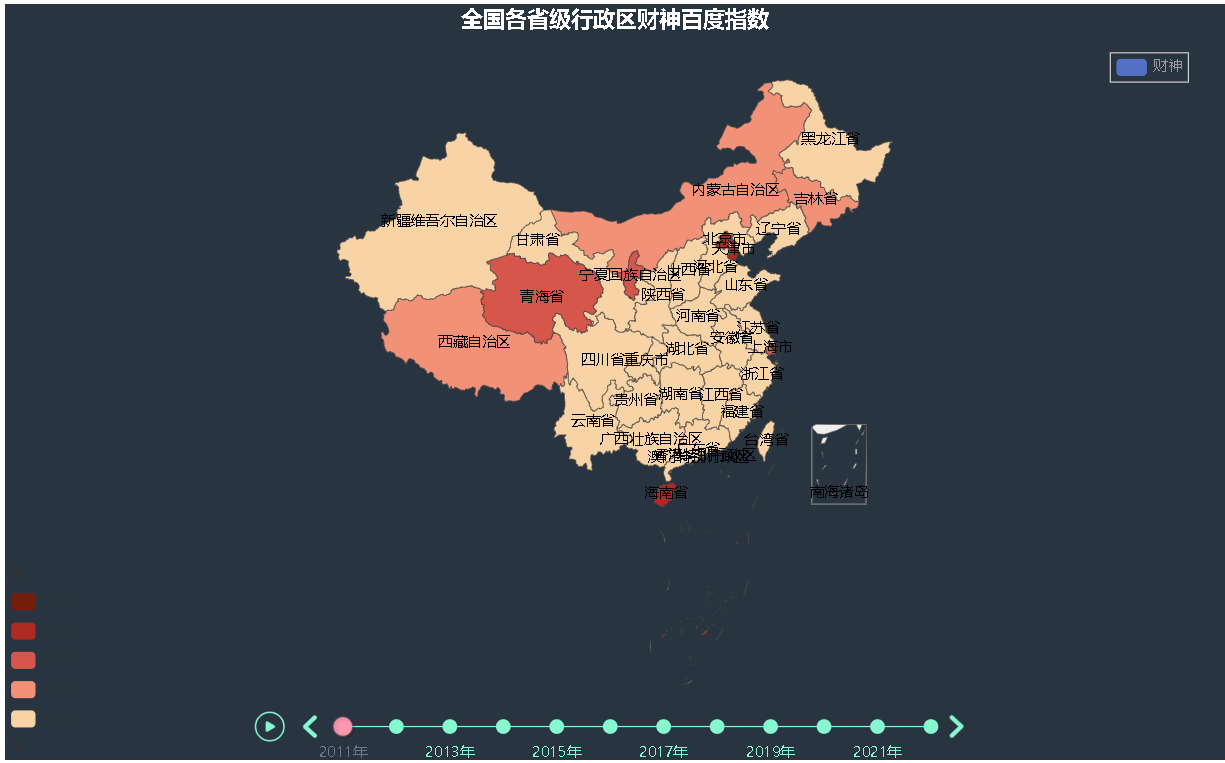

















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









