









概述
定义: 如果一个样本在特征空间汇总的 k 个最相似 (即特征空间中最邻近) 的样本中的大多数属于某一个类别, 则该样本属于这个类别.
k-近邻算法采用测量不同特征值之间的距离来进行分类.
- 优点: 精度高, 对异常值不敏感, 无数据输入假定
- 缺点: 计算复杂度高, 空间复杂度高
- 使用数据范围: 数值型和标称型
例子
电影可以按照题材分类, 那每个题材又是如何定义的呢?
假如两种类型的电影, 动作片和爱情片. 我们发现动作片中打斗镜头次数较多, 而爱情片中接吻镜头相对更多. 当然动作片中也有一些接吻镜头, 爱情片中也有一些打斗镜头. 所以不能单纯通过是否存在打斗镜头或者接吻镜头来判断影片的类别. 那么现在我们有 6 部影片已经明确了类别, 也有打斗镜头和接吻镜头的次数, 还有一部电影类型未知.
| 电影名称 | 打斗镜头 | 接吻镜头 | 电影类型 |
|---|---|---|---|
| California Man | 3 | 104 | 爱情片 |
| He’s not Really into dues | 2 | 100 | 爱情片 |
| Beautiful Woman | 1 | 81 | 爱情片 |
| Kevin Longblade | 101 | 10 | 动作片 |
| Robo Slayer 3000 | 99 | 5 | 动作片 |
| Amped II | 98 | 2 | 动作片 |
| ? | 18 | 90 | 未知 |
那么我们使用 K- 近邻算法来分类爱情片和动作片: 存在一个样本数据集合, 也叫训练样本即, 样本个数 M 个, 知道每一个数据特征与类别的对应关系, 然后存在未知类型数据集合 1 个. 那么我们要选择一个测试样本数据域训练样本中 M 个的距离, 排序过后选出最近的 K 个, 这个取值一般不大于 20 个. 选择 K 个最相近数据中次数最多的分类. 那我们我们更加这个原则去判断未知电影的分类.
| 电影名称 | 与未知电影的距离 |
|---|---|
| California Man | 20.5 |
| He’s not Really into dues | 18.7 |
| Beautiful Woman | 19.2 |
| Kevin Longblade | 115.3 |
| Robo Slayer 3000 | 117.4 |
| Amped II | 118.9 |
我们假设 K 为 3, 那么排名前三个电影的类型都是爱情片, 所以我们判定这个位置电影也是一个爱情片. 那么距离是怎么样计算的呢?
欧式距离
欧式距离: 对于两个向量点 a1 和 a2 之间的距离, 可以通过该公式表示:
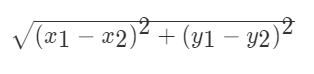
如果是输入变量有四个特征, 例如 (1, 3, 5, 2) 和 (7, 6, 9, 4) 之间的距离计算为:
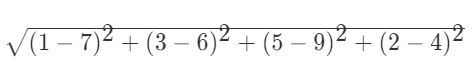
练习
Facebook 入住地点
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
import pandas as pd
def knncls():
"""
K-近邻预测用户签到位置
:return: None
"""
# 读取数据
data = pd.read_csv("train.csv")
print(data)
# 处理数据
# 1. 缩小数据, 查询数据筛选
data = data.query("x > 1.0 & x < 1.25 & y > 2.5 & y< 2.75")
# 2. 处理时间的数据
time_value = pd.to_datetime(data["time"], unit="s")
print(time_value.head())
# 3. 把时间格式转换成字典格式
time_value = pd.DatetimeIndex(time_value)
print(time_value)
# 4. 构造一些特征
data["day"] = time_value.day
data["hour"] = time_value.hour
data["weekday"] = time_value.weekday
print(data.head(10))
# 5. 把时间戳特征删除
data = data.drop(["time"], axis=1)
print(data.head(10))
# 6. 删除row_id小于3的数据
place_count = data.groupby("place_id").count()
print(place_count)
tf = place_count[place_count.row_id > 10].reset_index()
print(tf)
data = data[data["place_id"].isin(tf.place_id)]
data = data.drop(["row_id"], axis=1)
print(data)
# 7. 取出数当中的特征值和目标值
y = data["place_id"]
x = data.drop(["place_id"], axis=1)
# 8. 进行数据分割训练集合和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
# 特征工程 (标准化)
std = StandardScaler()
# 1. 对测试集和训练集的特征进行标准化
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 1. 进行算法流程
knn = KNeighborsClassifier(n_neighbors=5)
# 2. fit
knn.fit(x_train, y_train)
# 3. 得出预测结果
y_predict = knn.predict(x_test)
print("预测的目标签到位置为: ", y_predict)
# 4. 得出准确率
print("预测的准确率: ", knn.score(x_test, y_test))
return None
if __name__ == "__main__":
knncls()
输出结果:
预测的目标签到位置为: [6603539415 2355236719 6766324666 ... 6683426742 7707808405 3312463746]
预测的准确率: 0.5055147058823529














 403
403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









