







前言
参考教材:《机器学习 python实战》《机器学习》
一、肉眼观察(print)
我们用鸢尾花数据来完成本文的工作
首先在导入数据前,我们需要得到鸢尾花数据的CSV:

数据集可以通过以下指令自动下载到对应的环境文件夹中
from sklearn import datasets #导入数据集模块
iris = datasets.load_iris()#加载鸢尾花数据集
比如我电脑上自动下载的位置是:D:\Anaconda3\envs\python36\lib\site-packages\sklearn\datasets\data\iris.csv
紧接着我们粗暴观察一下数据集:
import pandas as pd
file_name='D:/数学建模2022/算法/数据集观察/iris.csv'
names=['separ-length','separ-width','petal_length','petal_width','class']
data=pd.read_csv(file_name,names=names)
print(data)
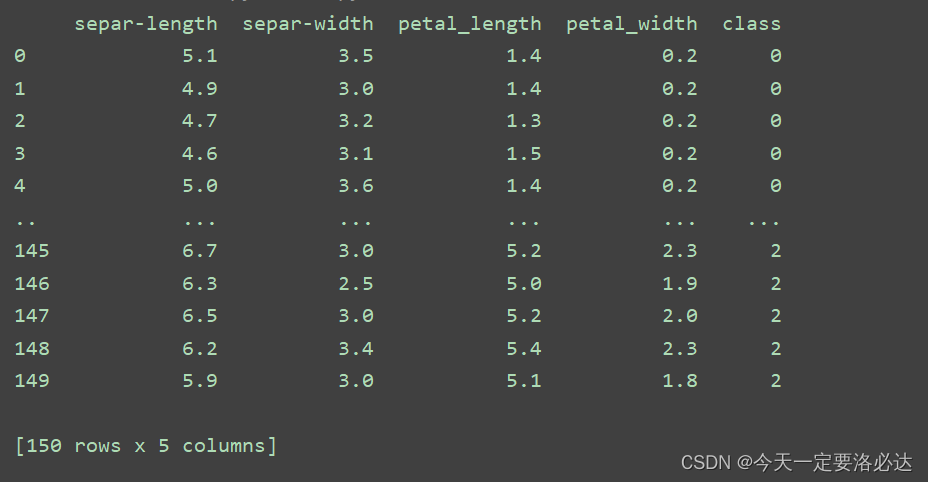
从图中可以看出,有行名也有列名,还有行数和列数。
现在,我们用直方图直观画出它的数据分布:
import pandas as pd
import matplotlib.pyplot as plt
file_name='D:/数学建模2022/算法/数据集观察/iris.csv'
names=['separ-length','separ-width','petal_length','petal_width','class']
data=pd.read_csv(file_name,names=names)
print(data)
data.hist(bins=50) #bins用来调整直方图的宽度
plt.show()
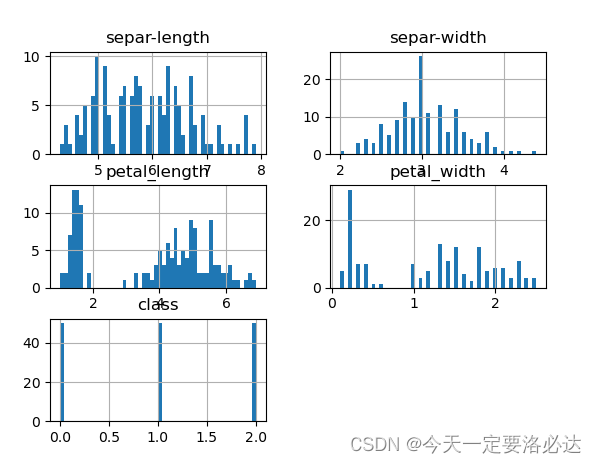
我们再画出它的密度图:
import pandas as pd
import matplotlib.pyplot as plt
file_name='D:/数学建模2022/算法/数据集观察/iris.csv'
names=['separ-length','separ-width','petal_length','petal_width','class']
data=pd.read_csv(file_name,names=names)
print(data)
data.plot(kind='density',subplots=True,layout=(2,3),sharex=False)#layout类似于matlab里的subplot
plt.show()
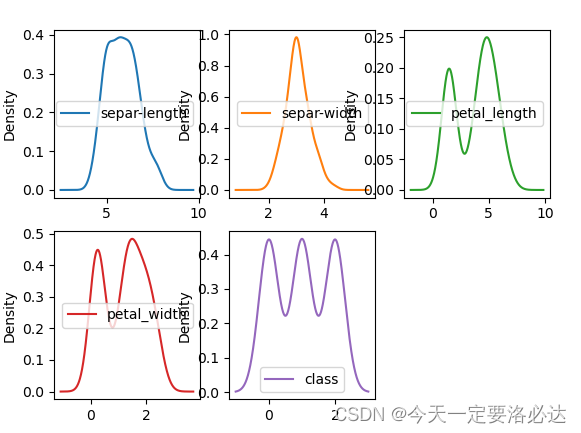
我们再画出它的箱线图:
import pandas as pd
import matplotlib.pyplot as plt
file_name='D:/数学建模2022/算法/数据集观察/iris.csv'
names=['separ-length','separ-width','petal_length','petal_width','class']
data=pd.read_csv(file_name,names=names)
print(data)
data.plot(kind='box',subplots=True,layout=(2,3),sharex=False)#layout类似于matlab里的subplot
plt.show()

二、数据类型
得到每一种数据的类型,是浮点数还是整数还是什么
import pandas as pd
file_name='D:/数学建模2022/算法/数据集观察/iris.csv'
names=['separ-length','separ-width','petal_length','petal_width','class']
data=pd.read_csv(file_name,names=names)
print(data.dtypes)
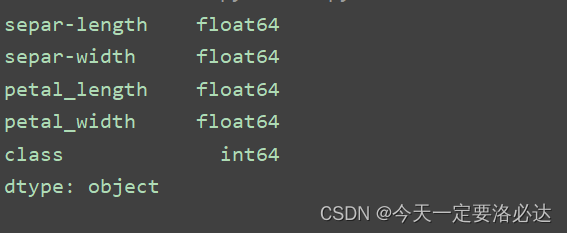
三、统计数据(平均值,方差等等)
import pandas as pd
file_name='D:/数学建模2022/算法/数据集观察/iris.csv'
names=['separ-length','separ-width','petal_length','petal_width','class']
data=pd.read_csv(file_name,names=names)
print(data.describe())
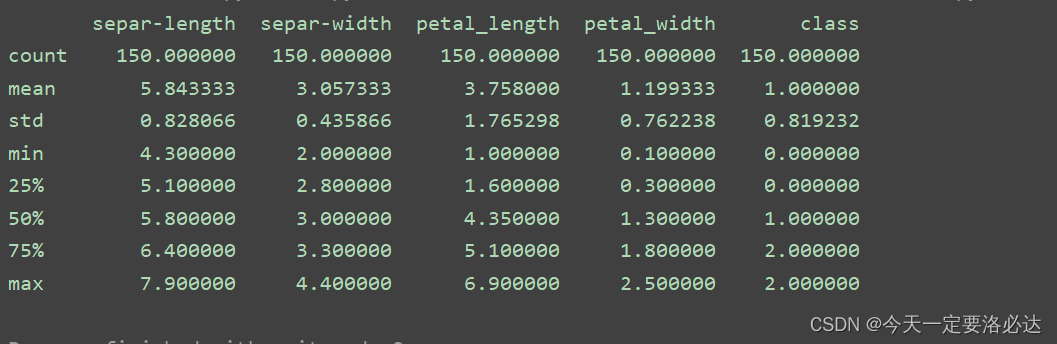
从上往下依次是:
记录数,平均值,标准方差,最小值,下四分位数,中位数,上四分位数,最大值。
四.数据种类分布
左边那列是列名,右边是个数
import pandas as pd
file_name='D:/数学建模2022/算法/数据集观察/iris.csv'
names=['separ-length','separ-width','petal_length','petal_width','class']
data=pd.read_csv(file_name,names=names)
print(data.groupby('class').size())

import pandas as pd
file_name='D:/数学建模2022/算法/数据集观察/iris.csv'
names=['separ-length','separ-width','petal_length','petal_width','class']
data=pd.read_csv(file_name,names=names)
print(data.groupby('class').size())
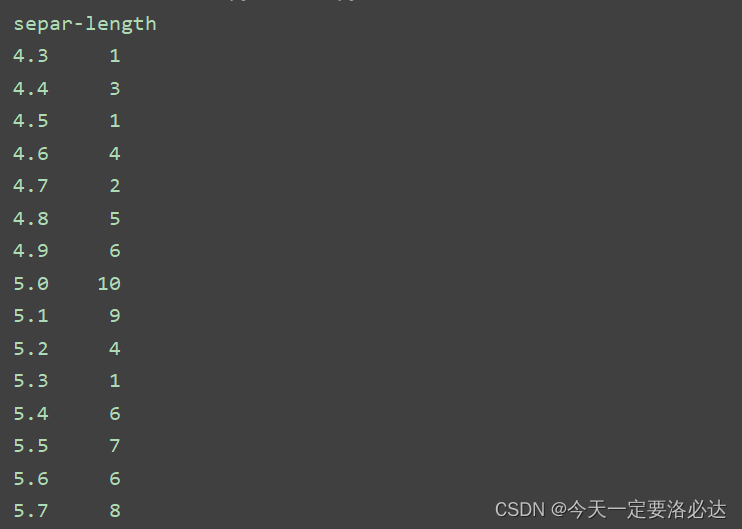
上面这张图只显示了一部分
五.相关性——肉眼
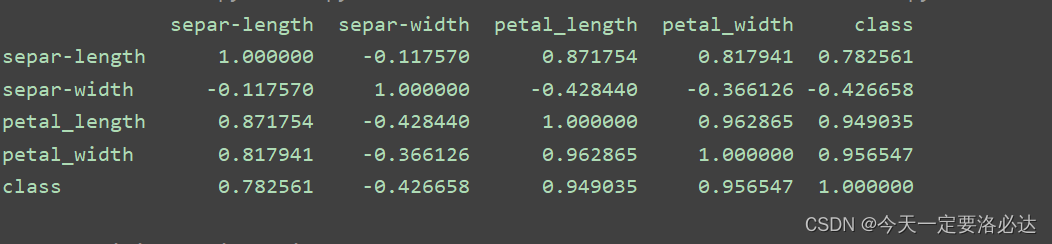
根据教材上的说法,如果数据特征的相关性比较高,那么某些算法的性能会降低。对于某些相关性高的变量,可以进行降维。
0表示无关,1表示完全正相关,-1表示完全负相关
import pandas as pd
file_name='D:/数学建模2022/算法/数据集观察/iris.csv'
names=['separ-length','separ-width','petal_length','petal_width','class']
data=pd.read_csv(file_name,names=names)
print(data.corr())
六.相关性——数据散点图
数据散点图可以很直观的看出因变量和自变量的大致变化趋势,而且可以瞬间画出所有图(巴适的很)
import pandas as pd
import matplotlib.pyplot as plt
from pandas.plotting import scatter_matrix
file_name='D:/数学建模2022/算法/数据集观察/iris.csv'
names=['separ-length','separ-width','petal_length','petal_width','class']
data=pd.read_csv(file_name,names=names)
array=data.values #从dataframe数据格式转为矩阵格式,重要的一步
X=array[:,:4] #输入特征
Y=array[:,4] #标签label
print(Y)
scatter_matrix(data,marker='o',c=Y,hist_kwds={'bins':50}) #marker是图片中数据类型,c是颜色用标签label就行,hist_kwds用来调整直方图宽度
plt.show()

七.相关性——热力图
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
file_name='D:/数学建模2022/算法/数据集观察/iris.csv'
names=['separ-length','separ-width','petal_length','petal_width','class']
data=pd.read_csv(file_name,names=names)
print(data.corr())
sns.heatmap(data.corr(),linewidths=0.1,vmax=1.0, square=True,linecolor='white', annot=True)
plt.show()
















 1396
1396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









