







参考教材:《机器学习python实践》
一、主成分分析法(PCA)
1.基本原理
按照以下逻辑分析:
1)一个数据集中有多个特征,但并不是每一个特征都“有用”
2)有些特征的方差小,所包含的信息量较少,这样特征可以忽略掉(这就是降维);而有些特征的方差大,包含信息量较大,这种特征就需要保留下来
3)以上的思路就是主成分分析法。
补充:方差小为什么代表“包含信息量较少呢”:比如一个数据集里有个特征是“男”,正好整个数据集里所有人都是男性(方差为0),相当这个特征没啥用了。
2.实现代码
from sklearn import datasets #导入数据集模块
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt #画图
import pandas as pd
import numpy as np
file_name='D:/数学建模2022/算法/数据集观察/iris.csv'
names=['separ-length','separ-width','petal_length','petal_width','class']
data=pd.read_csv(file_name,names=names)
iris = data.values#加载鸢尾花数据集
X = iris[:,0:4] #输入特征
Y = iris[:,4] #标签(输出特征)
pca=PCA(n_components=4)
fit=pca.fit(X)
print('解释方差是如下:')
print(fit.explained_variance_ratio_)
print('解释方差的累加矩阵如下:')
print(np.cumsum(fit.explained_variance_ratio_))
#开始降维
pca=PCA(n_components=2)
fit=pca.fit(X)
after_pca = pca.transform(X)
print('降维后(降到二维)序列如下:')
print(after_pca)
这里PCA里的参数n_components=4的意思是,我们原本的鸢尾花数据集有4个特征,所以这里取4,返回4个主成分,先看看大家各自的贡献度,后面根据情况再调整n_components的值(比如后面我推理出前两个特征就够了,就可以取为2)
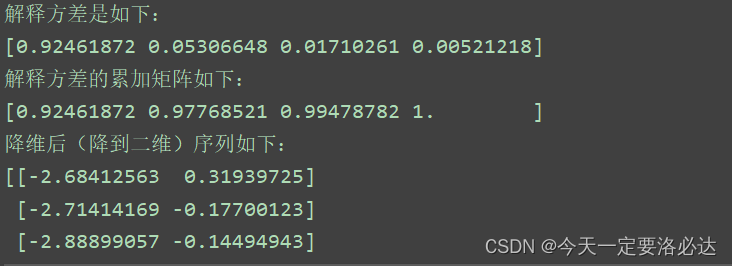
最后降维后的序列也给出了,两列,但是已经不再是以前的样子,数据发生了变化(当时我想了半天没明白,这和RFE,卡方检验有区别)
二、递归特征消除(RFE)
from sklearn import datasets #导入数据集模块
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt #画图
from sklearn.linear_model import LogisticRegression #导入SVM支持向量机
from sklearn.feature_selection import RFE
import pandas as pd
file_name = 'D:/数学建模2022/算法/数据集观察/iris.csv'
names = ['separ-length', 'separ-width', 'petal_length', 'petal_width', 'class']
data = pd.read_csv(file_name, names=names)
iris = data.values # 加载鸢尾花数据集
X = iris[:, 0:4] # 输入特征
Y = iris[:, 4] # 标签(输出特征)
model=LogisticRegression()
rfe=RFE(model,2)
fit=rfe.fit(X,Y)
print("特征个数:")
print(fit.n_features_)
print("被选定的特征:")
print(fit.support_)
print("特征排名:")
print(fit.ranking_)

三、SelectKBest 卡方检验
import matplotlib.pyplot as plt #画图
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
import pandas as pd
file_name = 'D:/数学建模2022/算法/数据集观察/iris.csv'
names = ['separ-length', 'separ-width', 'petal_length', 'petal_width', 'class']
data = pd.read_csv(file_name, names=names)
iris = data.values # 加载鸢尾花数据集
X = iris[:, 0:4] # 输入特征
Y = iris[:, 4] # 标签(输出特征)
test=SelectKBest(score_func=chi2,k=2)
fit=test.fit(X,Y) #‘训练’
print(fit.scores_)
features=fit.transform(X)#筛选过后的特征
print(features)
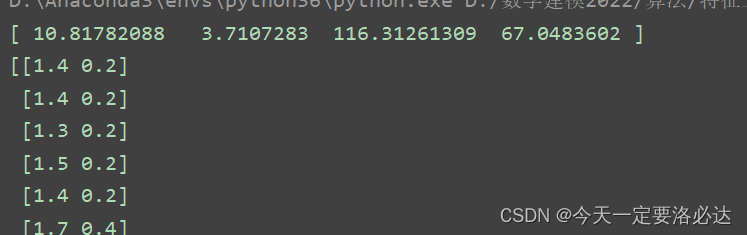
第三列和第四列值最大,最后筛选出的也是第三列和第四列的数据(卡方检验是统计样本的实际观测值和理论推断值之间的偏离程度,卡方值值越大偏离程度越大)
k=2意思是保留两个特征















 5437
5437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









