






工作中,当你需要对某个文件夹或多个文件夹内的大量类似文件做相同操作(增删改查)时,你还在拼命加班做一个没有感情的工具人嘛?掌握以下几个操作,瞬间完成任务,然后你就可以摸鱼去了。
运用Python进行批量处理,无疑是减少了无限的工作量,将枯燥无味,重复性工作交给机器。你只需要花几分钟时间编写几行代码,轻松摆脱工具人,这就是办公自动化的魅力所在。

在介绍批量处理文件之前,先介绍下Python文件IO的一般操作。
OS模块常用方法
import os
os.getcwd( )
方法获取代码当前工作路径
os.listdir(path)
获取当前工作文件夹内的文件夹或文件。
用于返回指定的文件夹包含的文件或文件夹的名字的列表。这个列表以字母顺序。它不包括 '.' 和'..'即使它在文件夹中。
path -- 需要列出的目录路径
os.makedirs(path, mode=0o777)
用于递归创建目录。
如果子目录创建失败或者已经存在,会抛出一个 OSError 的异常,Windows上Error 183 即为目录已经存在的异常错误。
path -- 需要递归创建的目录,可以是相对或者绝对路径。
mode -- 权限模式。
如果第一个参数 path 只有一级,则 mkdir() 函数相同。
os.mkdir(path[, mode])
用于以数字权限模式创建目录。
默认的模式为 0777 (八进制)。如果目录有多级,则创建最后一级,如果最后一级目录的上级目录有不存在的,则会抛出一个 OSError。
path -- 要创建的目录,可以是相对或者绝对路径。
mode -- 要为目录设置的权限数字模式
os.walk(top[, topdown=True[, οnerrοr=None[, followlinks=False]]])
是一个简单易用的文件、目录遍历器,可以帮助我们高效的处理文件、目录方面的事情。
可以创建一个生成器,用以生成所要查找的目录及其子目录下的所有文件。
用于通过在目录树中游走输出在目录中的文件名,向上或者向下。
top -- 根目录下的每一个文件夹(包含它自己), 产生3-元组
(dirpath, dirnames, filenames)【文件夹路径, 文件夹名字, 文件名】。topdown --可选,为
True或者没有指定, 一个目录的的3-元组将比它的任何子文件夹的3-元组先产生 (目录自上而下)。如果topdown为 False, 一个目录的3-元组将比它的任何子文件夹的3-元组后产生 (目录自下而上)。onerror -- 可选,是一个函数; 它调用时有一个参数, 一个OSError实例。报告这错误后,继续walk,或者抛出exception终止walk。
followlinks -- 设置为
True,则通过软链接访问目录。
os.chdir(path)
用于改变当前工作目录到指定的路径。
path -- 要切换到的新路径
os.path.abspath(path)
返回绝对路径
os.path.dirname(path)
返回文件路径
os.path.join(path1[, path2[, ...]])
把目录和文件名合成一个路径
os.path.split(path)
把路径分割成 dirname 和 basename,返回一个元组
os.path.splitext(path)
分割路径中的文件名与拓展名
os.path.walk(path, visit, arg)
遍历path,进入每个目录都调用visit函数,visit函数必须有3个参数(arg, dirname, names),dirname表示当前目录的目录名,names代表当前目录下的所有文件名,args则为walk的第三个参数。
os.path.exists(path)
路径存在则返回True,路径损坏返回False。
获取指定后缀名的文件
当一个文件夹中含有多种类型的文件,以下列举几个,有时候实际情况比这更多更复杂,我们需要找到需要的格式文件比较困难,因此批量获取指定后缀名的文件显得尤其重要。

import os
def find_file(work_dir, extension='jpg'):
"""
获取指定后缀名的文件
:param work_dir:传递当前目录
:param extension:指定的后缀名
:return: 返回所有目录下的文件
"""
# 空列表用以存储获取到的文件名
lst = []
for filename in os.listdir(work_dir):
# 指定文件夹中的文件名逐一打印
print(filename)
# 获取得到文件后缀
splits = os.path.splitext(filename)
file_ext = splits[1] # 拿到扩展名
if file_ext == '.' + extension:
lst.append(filename)
return lst
函数运用
>>> In: find_file('./批处理')
.ipynb_checkpoints
Data STUDIO.jpg
logger.py
MySQL.zip
svm.pptx
test.csv
text.xls
text.xlsx
关注《数据STUDIO》.gif
成都市地图.html
批处理.ipynb
控规图.dwg
>>> Out: ['Data STUDIO.jpg']
xls批量转换成xlsx
此方法是获取指定后缀名的文件的一个应用,获取到指定后缀名的文件后对相应文件作一个修改。
import os
def batch_rename(work_dir, old_ext ='.xls', new_ext='.xlsx'):
"""
批量重命名后缀
:param work_dir:传递当前目录
:param old_ext:原来后缀名
:param new_ext:新的后缀名后
"""
for filename in os.listdir(work_dir):
# 获取得到文件后缀
split_file = os.path.splitext(filename)
file_ext = split_file[1]
# 定位后缀名为old_ext 的文件
if old_ext == file_ext:
# 修改后文件的完整名称
newfile = split_file[0] + new_ext
# 实现重命名操作
os.rename(
os.path.join(work_dir, filename),
os.path.join(work_dir, newfile)
) print("完成重命名")
print(os.listdir(work_dir))
如果将其中的file_ext = split_file[1]改为file_name = split_file[0],后面再做相应的修改,可以变成批量修改文件名称。
批量获取文件修改时间
这里演示os.walk(path) 的应用。有时我们需要获取某个具有好几个层级的目录下的所有文件,根据条件筛选出某个目标文件,对其做相应的操作。这里演示获取文件的修改时间。
# 获取目录下文件的修改时间
import os
from datetime import datetime
print(f"当前时间:{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
def get_modify_time(indir):
for root, _, files in os.walk(indir): # 循环D:\批处理目录和子目录
for file in files:
absfile = os.path.join(root, file)
modtime = datetime.fromtimestamp(os.path.getmtime(absfile))
now = datetime.now()
difftime = now-modtime
if difftime.days < 20: # 条件筛选超过指定时间的文件
print(f"""{absfile}
修改时间[{modtime.strftime('%Y-%m-%d %H:%M:%S')}]
距今[{difftime.days:3d}天{difftime.seconds//3600:2d}时
{difftime.seconds%3600//60:2d}]"""
) # 打印相关信息
get_modify_time('./批处理')
输出
当前时间:2021-02-05 19:21:48
./MySQL.zip修改时间[2021-01-29 16:46:13]距今[ 7天 3时35]
./svm.pptx修改时间[2021-01-21 10:22:12]距今[ 15天 8时59]
./test.csv修改时间[2021-01-25 18:36:40]距今[ 11天 0时45]
./关注《数据STUDIO》.gif修改时间[2021-02-04 11:14:07]距今[ 1天 8时 7]
./批处理.ipynb修改时间[2021-02-05 19:21:44]距今[ 0天 0时 0]
./.ipynb_checkpoints\批处理-checkpoint.ipynb修改时间[2021-02-05 19:57:42]距今[ 0天 0时24]
批量压缩文件
这里同样运用到os.path.walk(path) 。
另外一个用来做压缩和解压的Python模块--zipfile
压缩文件
zipfile.ZipFile(file[, mode[, compression[, allowZip64]]])
file -- 文件的路径或类文件对象(file-like object)
mode -- 指示打开zip文件的模式,默认值为
'r',表示读已经存在的zip文件,也可以为'w'或'a','w'表示新建一个zip文档或覆盖一个已经存在的zip文档,'a'表示将数据附加到一个现存的zip文档中;compression -- 在写zip文档时使用的压缩方法,它的值可以是
zipfile.ZIP_STORED或zipfile.ZIP_DEFLATED。如果要操作的zip文件大小超过2G,应该将allowZip64设置为True。
有如下常用方法
ZipFile.infolist()获取zip文档内所有文件的信息,返回一个zipfile.ZipInfo的列表
ZipFile.namelist()获取zip文档内所有文件的名称列表
ZipFile.printdir()将zip文档内的信息打印到控制台上
import zipfile
# 加载压缩文件,创建ZipFile对象
file_dir = './Data STUDIO.zip'
zipFile = zipfile.ZipFile(file_dir)
print('info:',zipFile.infolist())
print('name:',zipFile.namelist())
print('dir:',zipFile.printdir())
输出
info: [<ZipInfo filename='Data STUDIO.jpg' compress_type=deflate external_attr=0x20 file_size=791106 compress_size=336551>]
name: ['Data STUDIO.jpg']
File Name Modified Size
Data STUDIO.jpg 2020-11-03 10:01:00 791106
dir: None
解压文件
ZipFile.extract(member[, path[, pwd]])
将zip文档内的指定文件解压到当前目录。
member -- 指定要解压的文件名称或对应的ZipInfo对象;
path -- 指定了解析文件保存的文件夹;
pwd -- 为解压密码。
下面一个例子将保存在程序根目录下的text.zip内的所有文件解压到D:/Work 目录
import zipfile
import os
zipFile = zipfile.ZipFile(file_dir)
for file in zipFile.namelist():
zipFile.extract(file, 'd:/Work')
zipFile.close()
另一种解压zip文档中的所有文件到当前目录:
ZipFile.extractall([path[, members[, pwd]]])
members的默认值为zip文档内的所有文件名称列表,也可以自己设置,选择要解压的文件名称
批量压缩文件
import zipfile # 导入zipfile,这个是用来做压缩和解压的Python模块;
import os
import time
def batch_zip(start_dir):
start_dir = start_dir # 要压缩的文件夹路径
file_news = start_dir + '.zip' # 压缩后文件夹的名字
z = zipfile.ZipFile(file_news, 'w', zipfile.ZIP_DEFLATED)
for dir_path, dir_names, file_names in os.path.walk(start_dir):
print(dir_path)
print(dir_names)
print(file_names)
# 这一句很重要,不replace的话,就从根目录开始复制
f_path = dir_path.replace(start_dir, '')
# 实现当前文件夹以及包含的所有文件的压缩
f_path = f_path and f_path + os.sep
for filename in file_names:
z.write(os.path.join(dir_path, filename), f_path + filename)
z.close()
return file_news
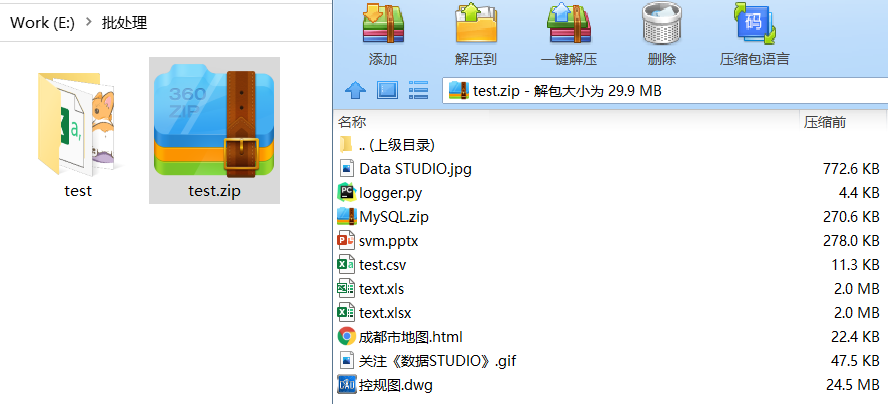
batch_zip('E:/批处理/test')
输出
E:/批处理/test
[]
['Data STUDIO.jpg', 'logger.py', 'MySQL.zip', 'svm.pptx', 'test.csv', 'text.xls', 'text.xlsx', '关注《数据STUDIO》.gif', '成都市地图.html', '控规图.dwg']
'E:/批处理/test.zip'
检验压缩效果。
 -- 数据STUDIO --
-- 数据STUDIO --
















 454
454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









