







案例背景
最近就业难都是有目共识的,不仅是应届生,工作了很多年的人也是一样的,大家现在都在想自己能找到多少钱的工作。不去市场看看是真不知道,有的以为很高,有的以为很低。这些都要看数据的。
正好手上有这么一个数据集,包含了学校层次,学历,岗位名称,技能关键词,工作时长还有工资区间的一个数据集。那就用来训练机器学习模型,然后我们输入自己的信息,就大概知道自己的工资有多少啦。
所以这个模型需要精确的画像每个求职者自身的情况和对应的岗位技能掌握,机器学习模型就能很好的做到,
这个模型可以用来预测还没工作的应届生的工资,也可以预测刚上班了的同学 想知道自己过几年工资能涨到多少,也可以预测老员工对自己这个岗位不满意跳到另外一个类型岗位工资大概会怎么变化,所以还是很有实际应用价值的。
数据介绍
该数据来自某些招聘网站的爬取和统计,统计了很多岗位的要求和工资区间
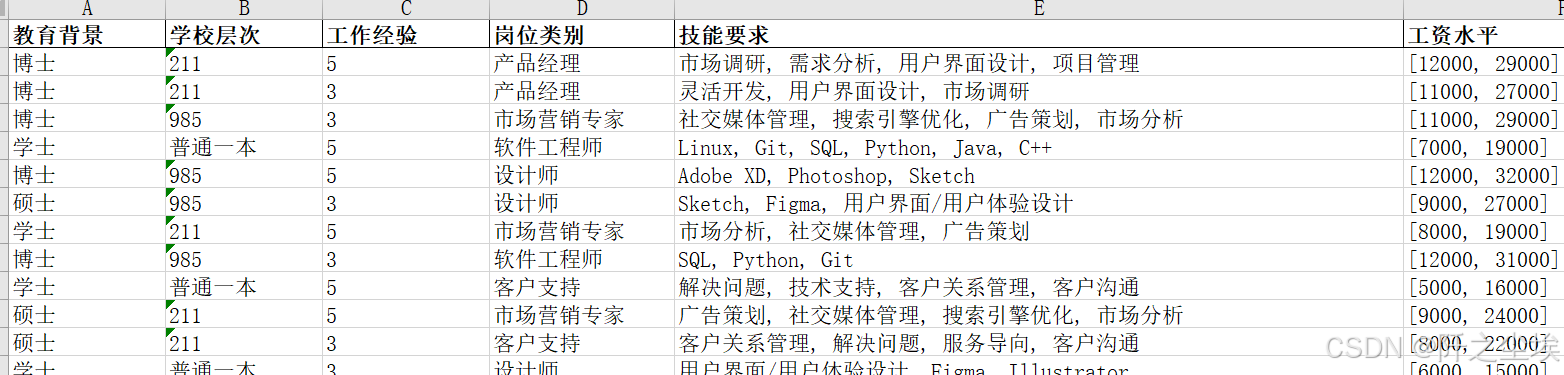
对不同岗位的教育背景和学校层次,工作经验,岗位类别,技能要求关键词都进行了统计。
不过很奇怪的是现在招聘软件上要求应该都是写的重点大学,不知道这是985和211是怎么分开的.....
其实这个数据集也可以用来研究不同学校层次,不同教育学历,不同岗位,不同工资时长对的工资的差异合影响,不过这不是这个案例的重点,有兴趣的同学可以研究。
我们的目标是预测工资的区间,所以我们就用最后一列作为y,前面都作为X,很多同学说这些X很多都是文本啊,怎么处理? 没事类别变量我们独立热编码,文字就用词袋模型。可以看看我下面代码知道了。
当然,需要这个案例数据和全部代码文件的同学还是可以参考:岗位工资数据
代码实现
数据分析,先导包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['KaiTi'] #指定默认字体 SimHei黑体
plt.rcParams['axes.unicode_minus'] = False #解决保存图像是负号'读取数据
# 载入数据、
data = pd.read_excel('岗位匹配数据.xlsx')
data.head()
我们画个图看看分类变量的分布吧
# 创建2x2的子图
fig, axs = plt.subplots(2, 2, figsize=(8, 6),dpi=128)
plt.subplot(2, 2, 1)
sns.countplot(x='教育背景', data=data)
plt.title('教育背景')
plt.subplot(2, 2, 2)
sns.countplot(x='学校层次', data=data)
plt.title('学校层次')
plt.subplot(2, 2, 3)
sns.countplot(x='工作经验', data=data)
plt.title('工作经验')
plt.subplot(2, 2, 4)
sns.countplot(x='岗位类别', data=data)
plt.title('岗位类别')
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()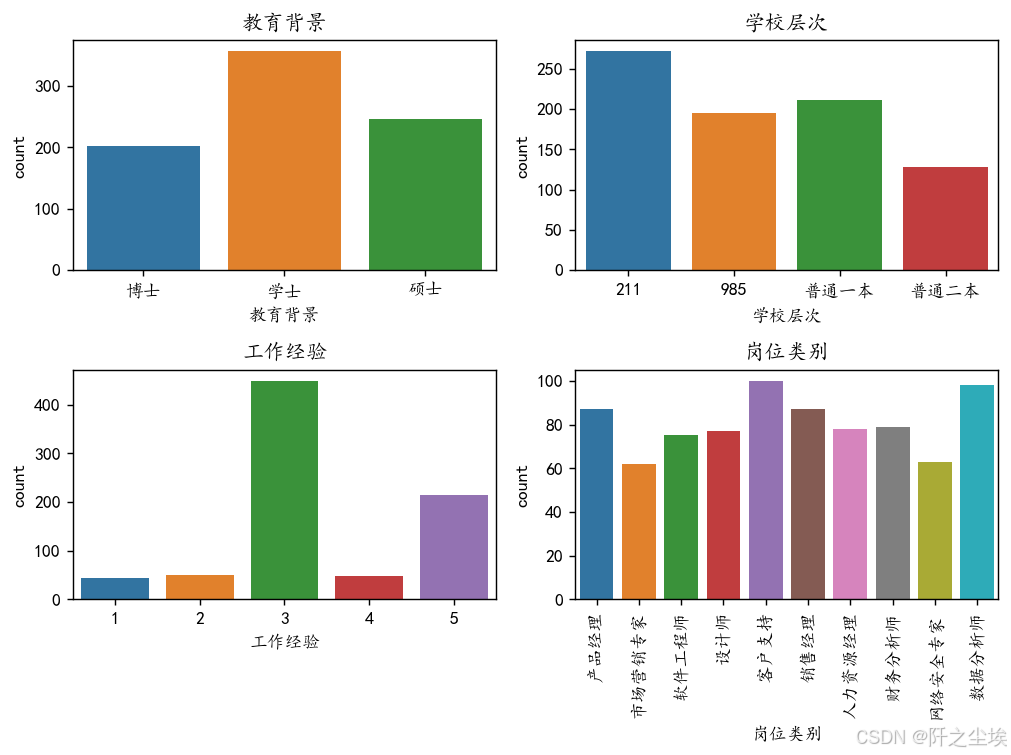
本科学士的岗位最多,岗位现在要求211的最多,其次是普通本科和985,工作经验基本都是要3年,岗位类别是客户支持和数据分析师较多。
数据预处理
下面来处理数据,对于学历,学校层次,工作岗位,使用独立热编码,对于工作经验,我们使用直接除以最大值进行归一化。然后查看不同的特征独立热编码出来的形状。
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_absolute_error, mean_squared_error,r2_score
education_encoder = OneHotEncoder()
job_type_encoder = OneHotEncoder()
school_encoder = OneHotEncoder()
education_onehot = education_encoder.fit_transform(data[['教育背景']]).toarray()
school_onehot = school_encoder.fit_transform(data[['学校层次']]).toarray()
position_onehot = job_type_encoder.fit_transform(data[['岗位类别']]).toarray()
experience_normalized = data['工作经验'] / data['工作经验'].max()
print("Education onehot shape:", education_onehot.shape)
print("Position onehot shape:", position_onehot.shape)
# 获取岗位标签
position_labels = job_type_encoder.categories_[0]
print("Position labels:", position_labels)
下面我们都对y进行处理。
由于y具有最大值跟最小值两列,很多模型只能接受一个y,所以我们计算他们的均值也就是工资区间的中位数去作为需要预测的目标来查看比较哪些模型的效果比较好。
同时我们还对y进行一个标准化的处理,防止有的模型对于数据的尺寸比较敏感受到训练的影响
salay=np.array([eval(i)for i in data['工资水平'].to_list()])
salay=salay.mean(axis=1)
scaler_y = MinMaxScaler()
scaler_y.fit(salay.reshape(-1,1))
salay = scaler_y.transform(salay.reshape(-1,1)).reshape(-1,)
salay.shape
接下来我们对工作技能要求这一列的文本型数据采用磁带进行处理编码。
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
data['技能要求']=data['技能要求'].apply(lambda x: ' '.join(x.split(',')))
#使用Tfidf将文本转化为向量
skills_padded= vectorizer.fit_transform(data['技能要求'])
#看看特征形状
skills_padded.shape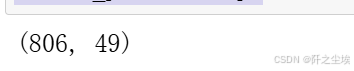
所谓的变量的处理好了。下面我们对x进行特征的拼接,然后再把y放在一起划分训练集和验证集
X = np.hstack((education_onehot, school_onehot,position_onehot,experience_normalized.values.reshape(-1, 1),skills_padded.toarray()))#skills_padded,
y = salay
# 分割数据集
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
y_val=scaler_y.inverse_transform(y_val.reshape(-1,1)).reshape(-1,)
print(X_train.shape, X_val.shape, y_train.shape, y_val.shape)
我们取出其中的三个进行查看。
## 查看3个
print(X_train[100:103])
print(y_val[100:103])
没什么问题,数据形状都是对的,而且都是数值型变量我们下面可以开始进行机器学习了。
机器学习
老观众都知道常见的做法了,会采用10种机器学习的模型进行对比。
#采用十种模型,对比验证集精度
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import ElasticNet
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from xgboost.sklearn import XGBRegressor
from lightgbm import LGBMRegressor
from sklearn.svm import SVR
from sklearn.neural_network import MLPRegressor进行实例化,模型都装入一个列表
#线性回归
model1 = LinearRegression()
#弹性网回归
model2 = ElasticNet(alpha=0.05, l1_ratio=0.05)
#K近邻
model3 = KNeighborsRegressor(n_neighbors=5)
#决策树
model4 = DecisionTreeRegressor(random_state=77)
#随机森林
model5= RandomForestRegressor(n_estimators=100, max_features=int(X_train.shape[1]/3) , random_state=0)
#梯度提升
model6 = GradientBoostingRegressor(n_estimators=100,random_state=123)
#极端梯度提升
model7 = XGBRegressor(objective='reg:squarederror', n_estimators=100, random_state=0)
#轻量梯度提升
model8 = LGBMRegressor(n_estimators=100,objective='regression', verbosity=-1,
random_state=0,force_row_wise=True)
#支持向量机
model9 = SVR(kernel="rbf")
#神经网络
model10 = MLPRegressor(hidden_layer_sizes=(32,8,), random_state=7, max_iter=10000)
model_list=[model1,model2,model3,model4,model5,model6,model7,model8,model9,model10]
model_name=['线性回归','惩罚回归','K近邻','决策树','随机森林','梯度提升','极端梯度提升','轻量梯度提升','支持向量机','神经网络']自定义评价指标函数,采用回归问题常用的几个评价指标。mae,mse,mape还有拟合优度R2
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error,r2_score
def evaluation(y_test, y_predict):
mae = mean_absolute_error(y_test, y_predict)
mse = mean_squared_error(y_test, y_predict)
rmse = np.sqrt(mean_squared_error(y_test, y_predict))
mape=(abs(y_predict -y_test)/ y_test).mean()
r_2=r2_score(y_test, y_predict)
return mae, rmse, mape,r_2 #mse由于这些模型都具有统一的接口,所以我们可以使用循环同样的方式都进行训练,然后预测评价。
df_eval=pd.DataFrame(columns=['MAE','RMSE','MAPE','R2'])
for i in range(len(model_list)):
model_C=model_list[i]
name=model_name[i]
print(f'{name}正在训练...')
model_C.fit(X_train, y_train)
pred=model_C.predict(X_val)
pred =scaler_y.inverse_transform(pred.reshape(-1,1)).reshape(-1,)
s=evaluation(y_val,pred)
df_eval.loc[name,:]=list(s)
查看不同模型的评价指标
df_eval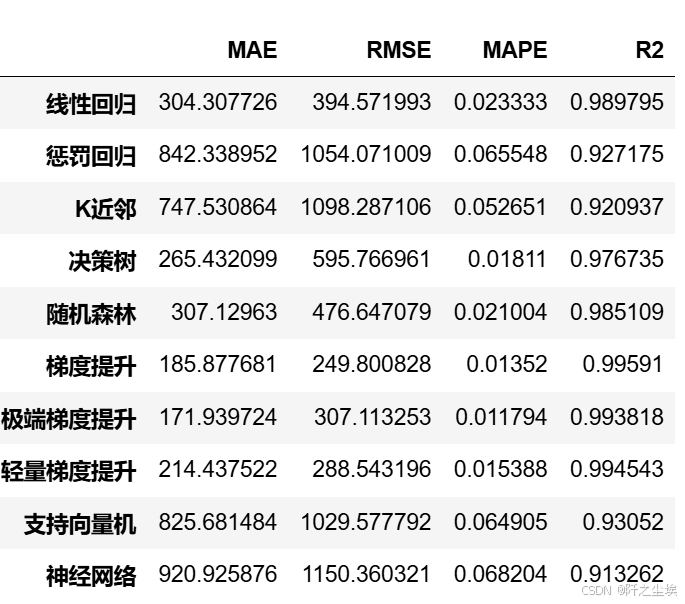
从上面的表可以看到梯度提升的效果最好,其次就是xgboost,lgbm这些,都是集成树模型的效果是最好的。几乎所有的模型预测的准确率都能够达到百分之九十以上还是表现效果非常好的说明这个数及质量也挺高。
可视化:
bar_width = 0.4
colors=['c', 'b', 'g', 'tomato', 'm', 'y', 'lime', 'k','orange','pink','grey','tan','purple']
fig, ax = plt.subplots(2,2,figsize=(7,5),dpi=256)
for i,col in enumerate(df_eval.columns):
n=int(str('22')+str(i+1))
plt.subplot(n)
df_col=df_eval[col]
m =np.arange(len(df_col))
#hatch=['-','/','+','x'],
plt.bar(x=m,height=df_col.to_numpy(),width=bar_width,color=colors)
#plt.xlabel('Methods',fontsize=12)
names=df_col.index
plt.xticks(range(len(df_col)),names,fontsize=8)
plt.xticks(rotation=40)
if col=='R2':
plt.ylabel(r'$R^{2}$',fontsize=14)
else:
plt.ylabel(col,fontsize=14)
plt.tight_layout()
#plt.savefig('柱状图.jpg',dpi=512)
plt.show()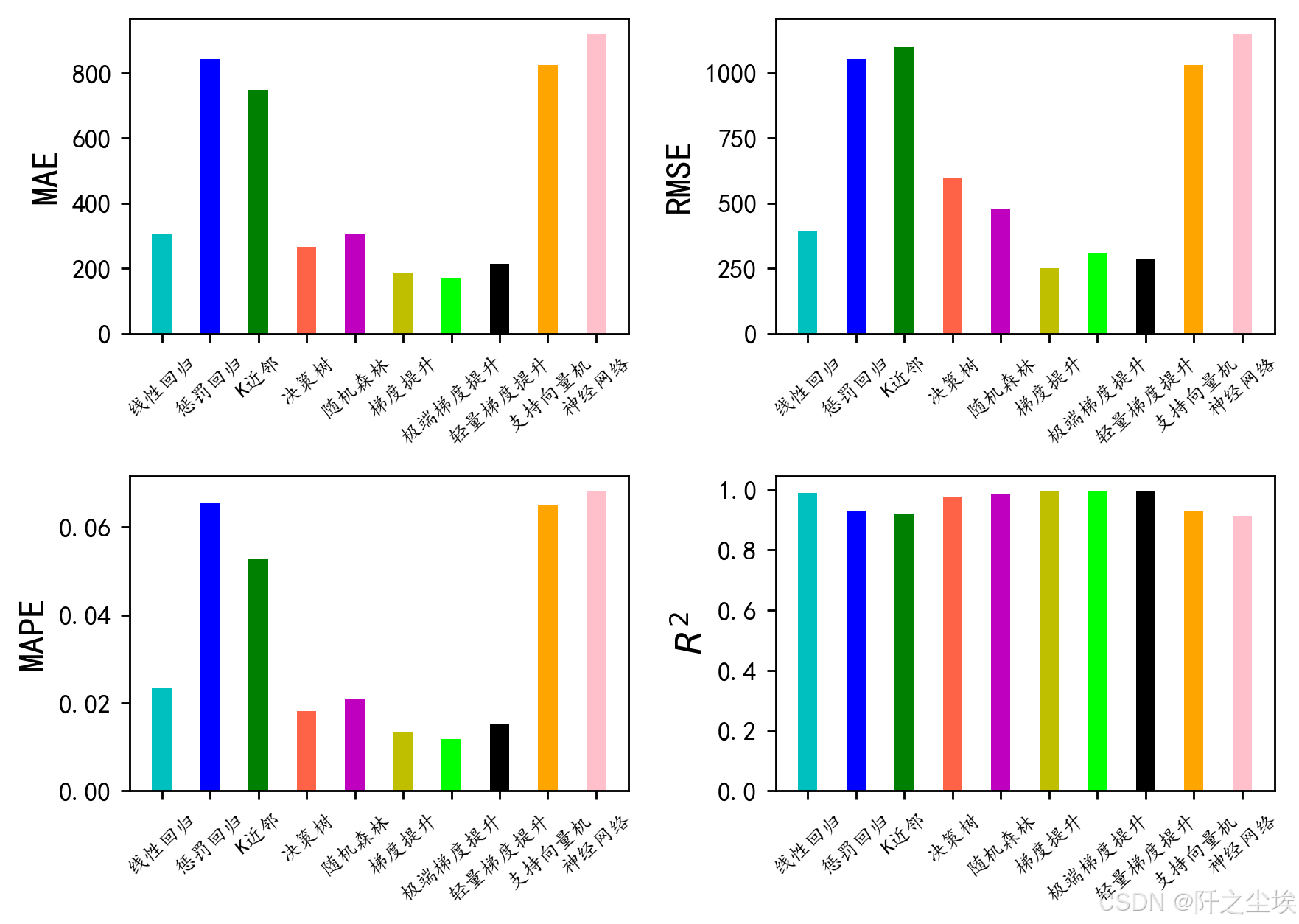
上面的图可以清晰的反映出哪些模型的效果比较好了。其实基于决策树的这些集成模型,随机森林梯度提升,xg,lgbm 这些模型的效果都挺好的,但是我们下面最终选用的模型还是随机森林,因为它可以接受多个y作为响应变量,也就是我们可以同时把工资的最大值和最小值都放入模型进行训练,并且从上面的图也可以看到随机森林的效果是非常好的(虽然不是最好)。。所以我们采用随机森林作为最后的模型去预测工资的区间。。
使用随机森林进行工资区间预测
重新训练模型,我们首先把y改一下,把y变成一个两列的数组。
### 将y改为区间
salay=np.array([eval(i)for i in data['工资水平'].to_list()])
salay.shape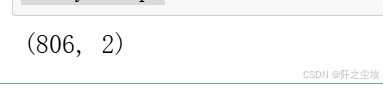
然后我们使用之前的x和现在的y放入随机森林模型进行训练
salay=np.array([eval(i)for i in data['工资水平'].to_list()])
RFM=RandomForestRegressor(n_estimators=100,random_state=1)
RFM.fit(X, salay) 
下面要进行预测了,我们直接过来的数据都是文本,当然不能直接丢入模型去预测,我们要把现在的要预测的数据跟上面的x要进行一样特征工程处理,因此我打包成一个函数统一进行的处理,我们只需要输入数据,然后它就会输出工资的区间了,这样用起来会很方便。
def preprocess_data(new_data, education_encoder, job_type_encoder, school_encoder, vectorizer):
# 对新的数据进行编码和归一化
education_onehot = education_encoder.transform(new_data[['教育背景']]).toarray()
position_onehot = job_type_encoder.transform(new_data[['岗位类别']]).toarray()
school_onehot = school_encoder.transform(new_data[['学校层次']]).toarray()
experience_normalized = new_data['工作经验'] / data['工作经验'].max()
skills_padded = vectorizer.transform(new_data['技能要求'])
# 拼接特征
X_new = np.hstack((education_onehot, school_onehot, position_onehot,
experience_normalized.values.reshape(-1, 1), skills_padded.toarray()))
return X_new
def predict_salary(X_new,model=RFM):
X_new = preprocess_data(X_new, education_encoder=education_encoder, job_type_encoder=job_type_encoder, school_encoder=school_encoder, vectorizer=vectorizer)
predictions = model.predict(X_new)
return predictions下面用一个数据框随机装几个样例进去,看看能不能预测出工资的区间。
test_data = pd.DataFrame({
'教育背景': ['博士', '硕士', '学士','硕士','硕士'],
'学校层次': ['211', '985', '普通一本', '普通一本','普通一本'],
'工作经验': [5, 3, 2, 0 ,0],
'岗位类别': ['产品经理', '数据分析师', '软件工程师','数据分析师','财务分析师'],
'技能要求': ['市场调研, 需求分析, 用户界面设计, 项目管理', '成本分析, Excel, 预算编制, 审计',
'编程, 软件开发, 数据结构, 算法' , '数据挖掘, 统计分析, 机器学习, 数据可视化',
'财务分析, Excel, 报表审核, 审计',]
})
test_data进行预测
predict_salary(test_data)
可以看到上面随机生成的5个。大概的岗位的信息的工资区间都预测出来了。
应用
千辛万苦搭建的模型肯定要用我首先拿自己的情况测一测
### 博主情况
predict_salary(pd.DataFrame({ '教育背景': ['硕士'],'学校层次': ['普通一本'], '工作经验': [0],
'岗位类别': ['数据分析师'],'技能要求': ['Python,SQL,数据挖掘, 统计分析, 机器学习, 深度学习,数据可视化']}))![]()
诶还不错,我的工资好像正好是这个区间的中位数。
下面我们测试一下中国文科里面最多的最常见的经管类的学生他们的工资的情况。
### 常见的经管会计的情况
predict_salary(pd.DataFrame({ '教育背景': ['硕士'],'学校层次': ['普通一本'], '工作经验': [0],
'岗位类别': ['财务分析师'],'技能要求': ['财务分析, Excel, 报表审核, 审计,成本分析, 预算编制, 财务报告']})) 
差不多,我觉得挺合理的吧,我感觉我身边读会计的同学大概都是这个工资。嗯,虽然他上线肯定有的也特别高,但是还是偏区间的中低端的工资是比较多的。
下面我想看一下,如果我干了个10年,我的工资会变成啥情况?预测一下。
### 博主干个10年工资情况
predict_salary(pd.DataFrame({ '教育背景': ['硕士'],'学校层次': ['普通一本'], '工作经验': [10],
'岗位类别': ['数据分析师'],'技能要求': ['Python,SQL,数据挖掘, 统计分析, 机器学习, 深度学习,数据可视化']}))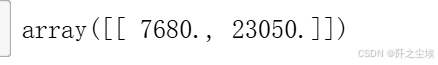
好吧确实涨了一些。。希望十年之后不会比这个差吧。。
总结
当然上面的代码都是进行了所有的训练和预测的,没有把它打包成一个程序,可以把上面所有训练出来的词表以及独立热的一些类和模型,都给他打包到一个程序里面,我们只要输入信息,就可以输出自己的工资区间了。这个是还可以进行美化的。
同时我觉得这个工资预测可能还缺少一个比较重要的因素,就是地区,中国不同地区的工资差异还是较大,就算是一样的层次的学校,一样的学历,一样的岗位,在不同的地区差异还是较大的,当然这个也是数据的缺陷,没有带地区,希望以后能有更好更高质量的数据去进行预测。
总体而言,这个区间还是挺可以进行参考的,虽然它的范围有点大,但是基本上真实的数值还是能够落入这个区间的。应届生的同学可以用这个程序,输入自己的真实情况以及自己想干的岗位和一些自己的技能的关键词来参考自己的工资区间大概是多少,以及预测一下自己大概过个五年十年工资会变成什么样的一个情况。
当然这个数据集还有更多的作用,比如可以研究不同的工作时长的工资的变化的一个情况,以及不同岗位,不同学校层次,不同专业的一种工资的影响的程度什么进行分析,也可以对技能要求里面出现的一些词汇,画一些词云图去研究这些不同的技能所影响的工资的情况,看看哪些技能是可以找到比较高薪的工作。还可以从模型的角度入手,去把这么些效果比较好的模型采用融合模型来进行预测。
创作不易,看官觉得写得还不错的话点个关注和赞吧,本人会持续更新python数据分析领域的代码文章~(需要定制类似的代码可私信)


















 1090
1090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











