






一、Redis中数据结构层面的源码解析
1.1、Redis键值对中的字符串是使用char *还是使用结构体来实现的
字符串的实现在我们平时中还是很常见发,就比如说我们要记录用户的信息、商品信息等,这些操作都会用到字符串。
而我们在Redis中,键值对的中的键是字符串的,值有时也是字符串来实现的。
Redsi实例和客户端进行交互的命令和数据也是用字符串来进行表示的。
我们使用字符串尽量要满足以下三个条件:
1)能支持丰富高效的字符串操作,比如说字符串的追加,拷贝,比较,获取长度等
2)能保持任意的二进制数据,比如照片等
3)能尽可能地节省内存的开销
我们可能在学习Redis的时候,或多或少都有听说过Redis的底层代码是使用C语言来进行编写的。那么我们可不可以觉得Redis也复用了C语言中对字符串的实现呢?
事实并不是的,在C语言中操作字符串,经常需要手动检查和分配字符串的空间,这样子就会增加代码开发的工作量。并且在C语言中,图片等数据并不能通过字符串来进行保存,这样子就限制了它的应用范围。而Redis是通过设计了一种**简单的动态字符串(SDS)**的结构来操作字符串的,这种结构可以提升字符串的操作效率,并且也可以用来保存二进制的数据(即图片等数据)。
首先我们先了解一下为什么Redis不使用char *的结构设计
在这开始之前我们得先知道char *的数据结构
其实char *就是申请一块连续的内存来进行存放字符串中的每一个字符。
如上图是字符串”Redis“的char *的数据结构。我们可以从中看出字符串的最后一个字符是\0,我们在学习C语言的时候都知道,当一个字符数组的结尾位置就使用”\0“来进行表示,就是指该字符串的结束。
而我们也知道在C语言中,字符串的操作函数,就会通过检查字符数组中是否含有”\0“,来进行判断该字符串是否结束。
我们可以通过一段代码,更直观的观察一下"\0“结束字符对字符串长度的影响。如下:
#include<stdio.h>
#include<string.h>
int main() {
char *a = "red\0is";
char *b = "redis\0";
printf("%lu\n",strlen(a));\\3
printf("%lu\n",strlen(b));\\5
}从结果我们可以看出在遇到”\0“ 结束符的时候,就会停止计算该字符串的长度,并返回结果。
也就是说,char 字符串以“\0”来表示字符串的结束,其实这样子就会给我们保存数据带来一定的负面影响。如果我们要保存的数据中,本身就存在“\0”,那么数据就会在“\0”处被截断,而这样子就不符合*Redis希望能保存任意二进制数据的需求了**。
操作函数复杂度
char *除了字符数组结构的设计问题外,使用“\0”作为字符串的结束字符,虽然可以让字符串操作函数判断字符串的结束位置,但也有负面影响,就是会导致操作函数的复杂度增加。
就比如说以strlen函数来说,该函数需要遍历字符数组中的每一个字符,才能得到字符串的长度,所以它的复杂度就是O(N);
以及比如说在追加字符串的时候,需要先进行遍历字符串才能得到字符串的末尾,然后还需要再进行遍历字符串才能完成追加,另外,它在把字符串追加到目标字符串的末尾时,还需要确认目标字符串是否具有足够的空间,否则就不能进行追加。
所以这就需要开发在调用strcat函数时,进行判断是否有足够的空间,不然就需要动态进行分配空间了,从而增加了编程的复杂度。操作函数的复杂度一旦增加,就会影响到字符串的操作效率,这就不符合Redis对字符串高效操作的需求了。
所以Redis在进行操作字符串就采用SDS的方法。
SDS的设计思想:
由于Redis是使用C语言进行开发的,所以在保证能尽量复用C语言标准库走的字符串操作函数,Redis保留了使用字符数组来保存实际的数据。Redis还专门设计了SDS的数据结构来进行操作字符串。
SDS结构设计
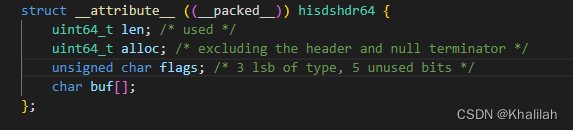
我们从源码中,可以看出,SDS结构中包含了一个字符数组buf[],用来保存实际数据。同时,SDS结构中还包含了三个元数据,字符数组现有长度len、字符数组已分配空间,不包括结构体和"\0"结束符alloc,已经SDS类型flags。
在源代码中的位置:
Redis中关于SDS的定义,我们可以发现Redis使用typedef来进行定义一个别名的,这个别名就是hisis,如下图:
typedef char *hisds;其实,这是因为SDS本质上还是字符数组,只是在字符数组基础上增加了额外的元数据。在Redis中需要用到字符数组时,就直接使用hisds这个别名。
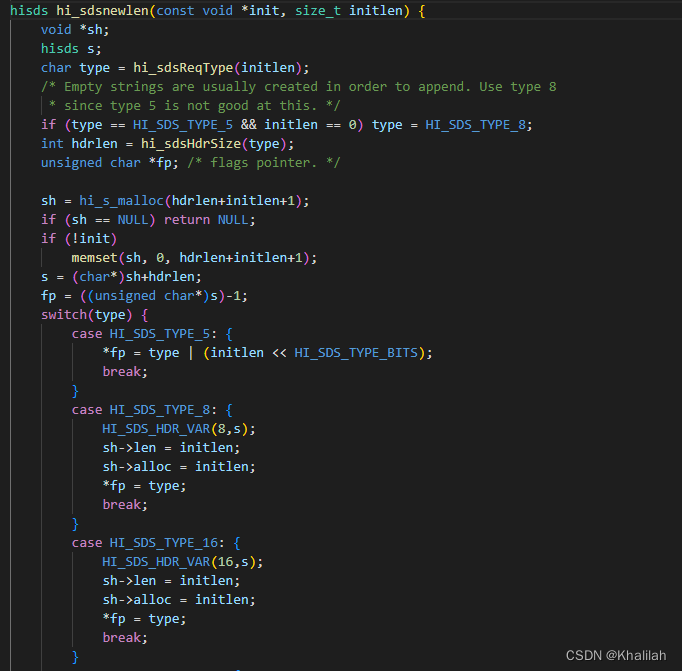
同时,在创建新的字符串时,Redis会调用SDS创建函数hi_sdsnewlen。如下:

SDS操作效率
因为SDS结构中记录了字符数组已占用的空间和被分配的空间,这就比传统C语言实现的字符串能带来更高的操作效率。
就比如是hi_sdscatlen函数
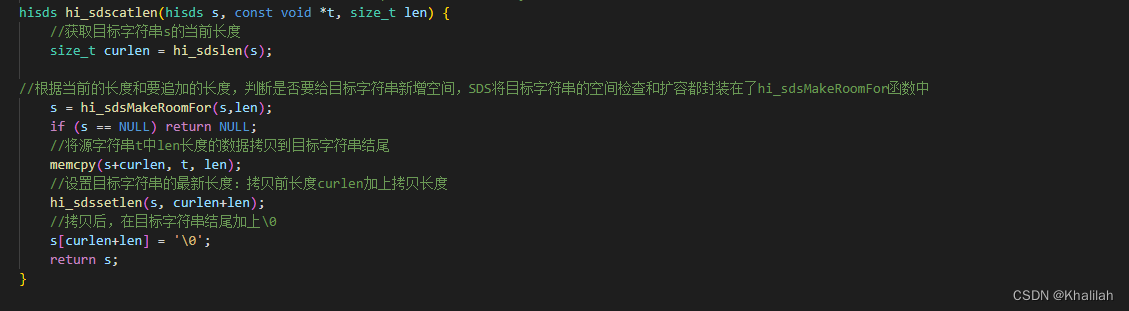
通过观察这个函数的源码,我们可以看到它的实现还是较为简单的。
如下图显示了hi_sdscatlen的执行过程:
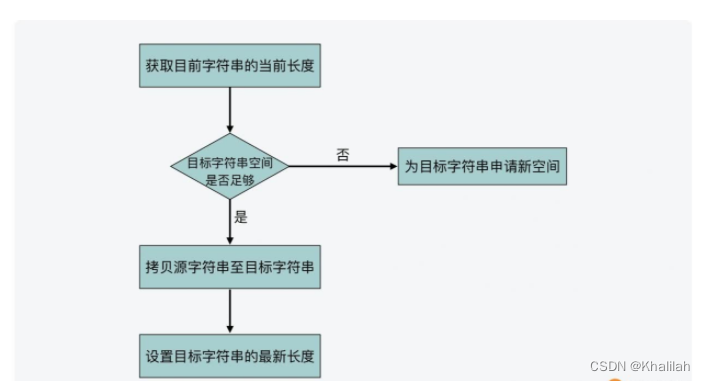
我们可以发现SDS通过记录字符数组的使用长度和分配空间大小,避免了对字符串的遍历操作,降低了对字符串的遍历操作,降低了操作的开销,进行一步就可以帮助诸多字符串操作更加高效地完成。
另外SDS把目标字符串的空间检查和扩容封装在了hi_sdsMakeRoomFor函数中,并且在涉及字符串空间变化的操作中就会调用该函数。
这一设计的实现,可以避免开发人员因忘记给目标字符串扩容,从而导致操作失败的情况。就比如说在进行函数strcpy时,发现后一个字符串的长度大于前一个字符串的长度,代码中我们也没有做检查的话,就会造成内存的溢出。所以这种封装操作的设计思想,同样值得我们学习的。
通过紧凑型字符串结构的编程技巧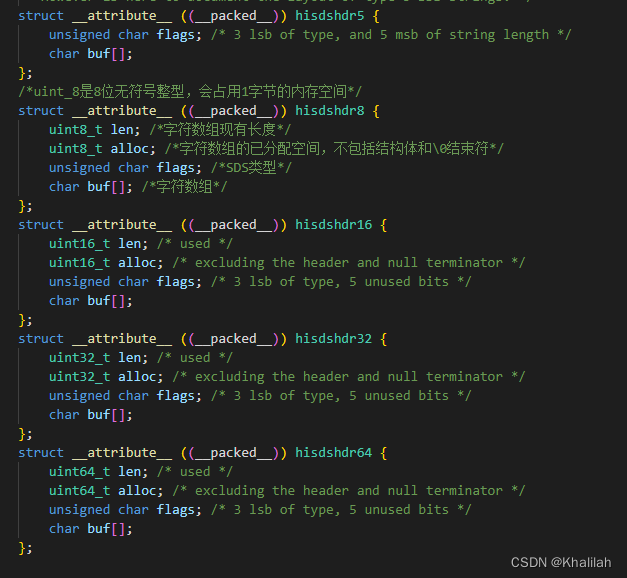
Redis中SDS设计了5种类型,如上图。它们的主要区别就在于,他们的数据结构中的字符数组现有长度len和分配空间长度alloc,这两个元数据的数据类型不同。
就比如说unint8_t是8位无符号整型,会占用1字节的内存空间。它能表示的字符数组长度(包括数组最后一位\0)不会超过2的8次方。
其余的可以类比。
实际上,SDS之所以设计不同的结构头,就是为了能灵活保存不同大小的字符串,从而有效节省内存空间。Redis在编程上还使用了专门的编译优化来节省内存空间。就比如使用了
__attribute__ ((__packed__))采用这个就是为了告诉编译器,不要使用字符对齐的方式,而是采用紧凑的方式来进行分配内存。
#include<stdio.h>
int main(){
struct s1 {
char a;
int b;
}ts1;
printf("%lu\n",sizeof(ts1));//8
return 0;
}上面这段代码运行的结果是8,这就是因为在默认的情况下,编译器会给s1这个结构体分配8个字节的空间,而这样子其中就有三个字节被浪费了。
为了节省空间,Redis就采用了
__attribute__ ((__packed__))属性来定义结构体,这样子,结构体实际占用多少内存空间,编译器就分配多少空间。
#include<stdio.h>
int main(){
struct __attribute__ ((__packed__)) {
char a;
int b;
}ts1;
printf("%lu\n",sizeof(ts1));//5
return 0;
}如上图所示,编译器给其分配就是5个字节的空间,这样子就不会造成空间的浪费。
如果我们在进行开发程序时,希望能够节省数据结构的内存开销,就可以把
__attribute__ ((__packed__))这个方法给使用起来。















 779
779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









