







Selenium是自动化测试工具,可以驱动浏览器执行特定的动作,如单击、下拉等,同时可以获取浏览器当前呈现的源代码,做到可见即可爬,便捷的获取网站中动态加载的数据,便捷实现模拟登录
安装:pip install selenium
一、环境配置
以Chrome浏览器为例:首先需要安装好Chrome浏览器并且配置好ChromeDriver。ChromeDriver文件在网址http://npm.taobao.org/mirrors/chromedriver/中下载,下载Chrome浏览器对应的版本,在Chrome浏览器中,选择设置->帮助->关于chrome可以查看其版本
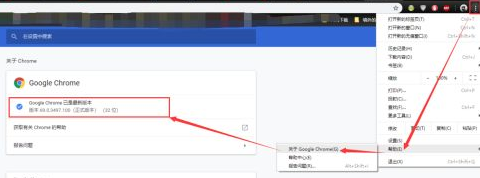
找到后在网址中下载对应版本的文件下载,最后解压复制到python软件对应的文件中
二、使用selenium解析源码
from selenium import webdriver
from lxml import etree
# 实例化一个浏览器对象(传入浏览器的驱动),打开浏览器
bro = webdriver.Chrome()
# 让浏览器对制定URL发送请求
bro.get('https://www.baidu.com/')
# 获取浏览器当前页面源码数据
page_text = bro.page_source
# 解析源码
tree = etree.HTML(page_text)
# 解析获取li节点
li_list = tree.xpath('//li')
print(li_list)
关于Xpath的使用介绍请看https://blog.csdn.net/weixin_46287157/article/details/116432393
三、基本函数
先举个例子:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 初始化
browser = webdriver.Chrome()
# 发出请求
browser.get('http://www.baidu.com')
# 输出源码
print(browser.page_source)
# 延时,便于观看效果
time.sleep(2)
# 根据ID值获取输入框节点
# 获取第一个ID为kw的节点,这个地方刚好是第一个且为唯一,find_element获取所有符合要求的节点
info = browser.find_element(By.ID, 'kw')
# 输出该节点的id值
print(info.id)
# 在输入框中输入Python
info.send_keys('Python')
time.sleep(2)
# 获取搜索按钮
button = browser.find_element(By.ID, 'su')
# 点击搜索按钮
button.click()
time.sleep(2)
# 返回上一个页面
browser.back()
time.sleep(2)
# 创建新选项卡
browser.execute_script('window.open()')
time.sleep(2)
# 切换到新选项卡
browser.switch_to.window(browser.window_handles[1])
time.sleep(2)
# 请求URL
browser.get('http://www.zhihu.com')
time.sleep(2)
# 执行一组js程序,移动滚轮使页面滑到底部
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(2)
# 关闭页面
browser.close()
常用函数如下
| 函数 | 含义 | 举例 | |
|---|---|---|---|
基本使用 | 导库 | from selenium import webdriver | |
| webdriver.Chrome() | 初始化 | browser = webdriver.Chrome() | |
| 初始化 | browser = webdriver.Firefox() | ||
| 初始化 | browser = webdriver.Edge() | ||
| get() | 请求URL | browser.get(url) | |
| page_source | 输出源码 | browser.page_source | |
| current_url | 输出请求的URL | browser.current_url | |
| get_cookies() | 获取cookies | browser.get_cookies() | |
| add_cookie() | 添加cookies | browser.add_cookie({‘name’:‘name’,‘domain’:‘www.zhihu.com’}) | |
| delete_all_cookies() | 删除cookies | browser.delete_all_cookies() | |
获取节点信息 | |||
| browser.find_element() | 获取节点 | loge = browser.find_element(‘AppHeader-login’) | |
| get_attribute() | 获取节点的属性值(class) | loge.get_attribute(‘class’) | |
| text | 文本 | loge.text | |
| id | 获取id属性 | loge.id | |
| location | 获取节点相对位置 | loge.location | |
| tag_name | 获取标签名称 | loge.tag_name | |
| size | 获取节点大小 | loge.size | |
前进回退 | |||
| back() | 后退 | browser.back() | |
| forward() | 前进 | browser.forward() | |
选项卡 | |||
| execute_script() | 开启新的选项卡 | browser.execute_script(‘window.open()’) | |
| browser.window_handles | 所有窗口句柄 | print(browser.window_handles) | |
| browser.switch_to.window() | 切换到新选项卡,参数为选项卡代号 | browser.switch_to.window(browser.window_handles[1]) | |
进度条 | |||
| execute_script() | 滑到底部 | browser.execute_script(‘window.scrollTo(0, document.body.scrollHeight)’) | |
| 弹出提示框 | browser.execute_script(‘alert(“To Bottom”)’) | ||
节点定位 | 导库 | from selenium.webdriver.common.by import By | |
find_element(定位方法,value) | 查找一个节点 | info = browser.find_element(By.ID, ‘kw’) | |
find_elements(定位方法,value) | 查找一组节点 | info = browser.find_elements(By.ID, ‘kw’) | |
定位方法 | |||
| 定位元素 | 定位方式 | 定位方法 | |
| id | 通过属性id定位元素 | By.ID | |
| name | 通过属性name定位元素 | By.NAME | |
| class_name | 通过属性class name定位元素 | By.CLASS_NAME | |
| tag_name | 通过标签名称定位元素 | By.TAG_NAME | |
| link_text | 通过链接文本定位元素 | By.LINK_TEXT | |
| partial_link_text | 通过部分链接文本定位元素 | By.PARTIAL_LINK_TEXT | |
| css_selector | 通过css选择器定位元素 | By.CSS_SELECTOR | |
| xpath | 通过相对/绝对路径定位元素 | By.XPATH | |
节点交互 | 定位标签 | info = browser.find_element(By.ID, 'kw') | |
| send_keys() | 输入文字 | info.send_keys(‘iPhone’) | |
| clear() | 清空文字 | info.clear() | |
| click() | 点击 | button.click() |
更多操作在https://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.remote.webelement中
四、子页面(ifFrame)(动作链,拖拽)
页面中有一种节点叫作ifFrame,也就是子Frame,相当于页面的子页面,结构与外部网页的结构完全一致,Selenium打开页面后,默认在父级Frame里面操作,如果页面中还有子Frame,它是不能获取子Frame里面的节点,这时需要使用switch_to.frame()方法来切换到子页面Frame
动作链没有特定的执行对象,比如鼠标拖拽、键盘按键等。
现在实现一个节点的拖拽操作,将某节点从一处拖拽到另一处:
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
# 初始化
browser = webdriver.Chrome()
# 发起请求
browser.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
# 切换到页面的frame标签中进行(该标签的id为iframeResult)
browser.switch_to.frame('iframeResult')
# 定位标签
source = browser.find_element(By.CSS_SELECTOR, '#draggable')
target = browser.find_element(By.CSS_SELECTOR, '#droppable')
# 声明对象
actions = ActionChains(browser)
# 执行拖拽
actions.drag_and_drop(source, target)
# 释放动作链
action.release()
'''或者使用如下方法
# 动作链(拖动操作)
action = ActionChains(browser)
# 点击长按指定的标签
action.click_and_hold(source)
for i in range(5):
# perform()立即执行动作链操作
# move_by_offset(x, y): x水平方向,y垂直方向
action.move_by_offset(17,0).perform()
sleep(0.3)
# 释放动作链
action.release()
'''
# 回到父页面
browser.switch_to.parent_frame()
# 关闭页面
browser.close()
更多动作链在https://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.common.action_chains
五、实现无可视化界面,规避被检测的风险(反反爬)
和正常操作一样,只是没有将操作的页面显示出来,有操作无页面显示
实现无可视化界面
from selenium import webdriver
# 实现无可视化界面
from selenium.webdriver.chrome.options import Options
# 创建一个对象,用来控制chrome以无界面模式打开
option = Options()
option.add_argument('--headless')
option.add_argument('--disable-gpu')
# 无头浏览器(无界面浏览器)
bro = webdriver.Chrome(options=option)
# 让浏览器对制定URL发送请求
bro.get('https://www.baidu.com')
# 关闭浏览器
bro.quit()
规避被检测的风险(反反爬)
from selenium import webdriver
# 实现规避检测
from selenium.webdriver import ChromeOptions
# 让selenium规避被检测到的风险(反反爬)
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
# 无头浏览器(无界面浏览器),规避被检测到的风险
bro = webdriver.Chrome(options=option)
# 让浏览器对制定URL发送请求
bro.get('https://www.baidu.com')
# 关闭浏览器
bro.quit()
六、等待
延时等待
获取的源码不一定是加载完全的页面,如果有额外的Ajax请求,在网页源码中也不一定成功获取到,这里需要延时等待一定的时间,确保节点已经加载出来
隐式等待
没有找到节点时将继续等待,超过设定时间后,抛出找不到节点的异常,默认为0
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
# 设定等待时间
browser.implicitly_wait(10)
# 发起请求
browser.get('https://www.zhihu.com/explore')
# 获取节点
info = browser.find_element(By.NAME, 'AppHeader')
print(info)
隐式等待不太好,只设定一个固定时间,页面的加载时间会受到网络条件的影响
显式等待
指定要查找的节点,然后指定最长等待时间,加载出来了则返回该节点,没加载出来则抛出异常
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get('https://www.taobao.com/')
# 等待最长时间
wait = WebDriverWait(browser,10)
# 传入要等待的条件,这个条件是代表节点出现的意思,参数是节点定位元组,也就是ID为q的节点搜索框
info = wait.until(EC.presence_of_element_located((By.ID, 'q')))
# 对于按钮,这里element_to_be_clickable,也就是可点击,规定时间内如果加载出来可点击则返回该按钮,否则抛出异常
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.btn-search')))
print(info, button)
| 等待条件 | 含义 |
|---|---|
| presence_of_element_located | 节点加载出来,传入定位元组,如(By.ID,‘p’) |
| element_to_be_clickable | 节点可点击 |
| title_is | 标题是某内容 |
| title_contains | 标题包含某内容 |
| visibility_of_element_lcated | 节点可见,传入定位元组 |
| visibility_of | 可见,传入节点对象 |
| presence_of_all_elements_located | 所有节点加载出来 |
| text_to_be_present_in_element | 某节点文本包含某文字 |
| text_to_be_present_in_element_value | 某节点值包含某文字 |
| frame_to_be_available_and_switch_to_it | 加载并切换 |
| invisibility_of_element_located | 节点不可见 |
| staleness_of | 判断一个节点是否仍在DOM,可判断页面是否已经更新 |
| element_to_be_selected | 节点可选择,传节点对象 |
| element_located_to_be_selected | 节点可选择,传定位元组 |
| element_selection_state_to_be | 传入节点对象及其状态,相等返回True,否则返回False |
| element_located_selection_state_to_be | 传入定位元组及其状态,相等返回True,否则返回False |
| alert_is_present | 是否出现警告 |
七、异常处理
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, NoSuchElementException
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
# 请求超时异常处理
try:
browser.get('https://www.baidu.com/')
except TimeoutException:
print('Time Out')
# 无该id节点异常
try:
browser.find_element(By.ID, 'hello')
except NoSuchElementException:
print('No Element')
finally:
browser.close()















 677
677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









