







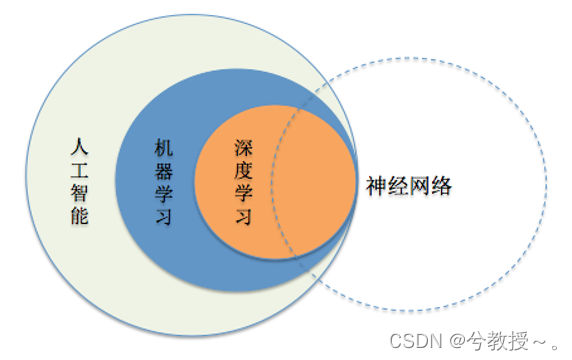
1.上网查资料明确人工智能(AI)、机器学习、深度学习这三个概念,以及相互包含关系。
答:
(1) 概念:
人工智能:人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门技术科学。
机器学习:机器学习是一门多学科交叉专业,涵盖概率论知识,统计学知识,近似理论知识和复杂算法知识,使用计算机作为工具并致力于真实实时的模拟人类学习方式,并将现有内容进行知识结构划分来有效提高学习效率。
机器学习有下面几种定义:
A.机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能。
B.机器学习是对能通过经验自动改进的计算机算法的研究。
C.机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。
深度学习:深度学习是机器学习的一种,而机器学习是实现人工智能的必经路径。深度学习的概念源于人工神经网络的研究,含多个隐藏层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。研究深度学习的动机在于建立模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本等。
(2) 关系:
机器学习是一种实现人工智能的方法。
深度学习是一种实现机器学习的技术。
2.了解图像卷积计算、CNN网络。
答:
(1)图像卷积计算:
深度学习所谓的卷积运算是互相关( cross-correlation )运算
我们以二维数据为例(高 x 宽),不考虑图像的通道个数,假设输入的高度为3、宽度为3的二维张量,卷积核的高度和宽度都是2,而卷积核窗口的形状由内核的高度和宽度决定:
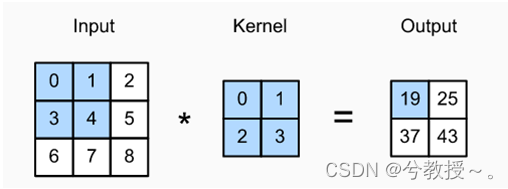
二维的互相关运算。阴影部分是第一个输出元素,以及用于计算这个输出的输入和核张量元素: 0 x 0 + 1x1 + 3x2 +4x3 = 19。由此可见互相关运算就是一个乘积求和的过程。在二维互相关运算中,卷积窗口从输入张量的左上角开始,从左到右、从上到下滑动。这里我们设置步长为1,即每次跨越一个距离。当卷积窗口滑到新一个位置时,包含在该窗口中的部分张量与卷积核张量进行按元素相乘,得到的张量再求和得到一个单一的标量值,由此我们得到了这一位置的输出张量值。(张量(Tensor)是一个多维数组,它是标量、向量、矩阵的高维拓展)
对于卷积操作,我们有一个统一的计算公式。且学会相关的计算对于了解感受野和网络的搭建至关重要。学会相关的计算,我们在搭建自己的网络或者复现别人的网络,才能够确定好填充padding、步长stride以及卷积核kernel size的参数大小。一般这里有一个统一的公式:
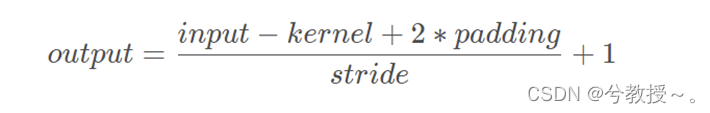
(2)CNN网络:
CNN是一种人工神经网络,CNN的结构可以分为3层:
卷积层(Convolutional Layer) - 主要作用是提取特征。
池化层(Max Pooling Layer) - 主要作用是下采样(downsampling),却不会损坏识别结果。
全连接层(Fully Connected Layer) - 主要作用是分类。
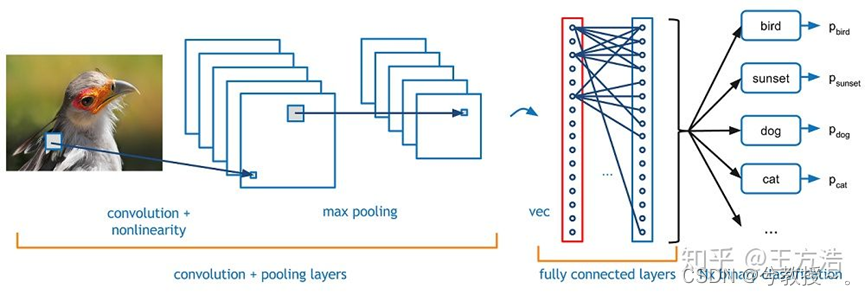
我们可以拿人类来做类比,比如你现在看到上图中的小鸟,人类如何识别它就是鸟的呢?首先你判断鸟的嘴是尖的,全身有羽毛和翅膀,有尾巴。然后通过这些联系起来判断这是一只鸟。而CNN的原理也类似,通过卷积层来查找特征,然后通过全连接层来做分类判断这是一只鸟,而池化层则是为了让训练的参数更少,在保持采样不变的情况下,忽略掉一些信息。
3.以pytoech为主,了解目前主要的AI平台,如:tensorflow,paddle,mindspore…都是哪些公司的。
答:
pytorch:是由Facebook开源的神经网络框架,专门针对 GPU 加速的深度神经网络编程。
Tensorflow:TensorFlow 最初是由 Google 机器智能研究部门的 Google Brain 团队开发,基于Google 2011年开发的深度学习基础架构DistBelief构建起来的 ,主要用于进行机器学习和深度神经网络研究。
Paddle:PaddlePaddle的前身是百度于2013年自主研发的深度学习平台Paddle。而现在,PaddlePaddle在深度学习框架方面,覆盖了搜索、图像识别、语音语义识别理解、情感分析、机器翻译、用户画像推荐等多领域的业务和技术。
Mindspore:华为公司推出的新一代深度学习框架,是源于全产业的最佳实践,最佳匹配昇腾处理器算力,支持终端、边缘、云全场景灵活部署。
MNN(阿里):MNN是一个高效、轻量的深度学习框架。支持深度模型推理与训练,尤其在端侧的推理与训练性能在业界处于领先地位。目前应用覆盖直播、短视频、搜索推荐、商品图像搜索、互动营销、权益发动、安全风控等多个场景。
TNN(腾讯):TNN由腾讯优图实验室开源的高性能、轻量级神经网络推理框架,同时拥有跨平台、高性能、模型压缩、代码裁剪等众多突出优势。
MACE(小米): Mobile AI Compute Engine是一个专为移动端异构计算平台优化的神经网络计算框架。
DELTA(滴滴):DELTA是深度学习模型训练框架,旨在进一步降低开发者创建、部署自然语言处理系统和语言模型的难度。主要基于TensorFlow构建,同时支持NLP(自然语言处理)和语音任务及数值型特征的训练。
4.搭建pytorch环境,并跑通mnist例子。
参考资料1:
https://wjrsbu.smartapps.cn/zhihu/article?id=445381875&isShared=1&bdswankey=vivobrowser%3A%2F%2Fswan%2FoFx3nbdDN6GWF3Vb0Wh7EDBMBxRTTcfe%2Fzhihu%2Farticle%3Fid%3D445381875&oauthType=search&searchParams=%257B%2522failUrl%2522%253A%2522https%253A%252F%252Fzhuanlan.zhihu.com%252Fp%252F445381875%2522%252C%2522logParams%2522%253A%2522pu%253D%2524pu%2526baiduid%253D%2524baiduid%2526tcreq4log%253D1%2526isAtom%253D1%2526cyc%253D1%2526clk_info%253D%257B%255C%2522tplname%255C%2522%253A%255C%2522www_normal%255C%2522%252C%255C%2522srcid%255C%2522%253A1599%252C%255C%2522ivkStatus%255C%2522%253A%255C%2522new_ivk_success%255C%2522%252C%255C%2522type%255C%2522%253A%255C%2522xcx%255C%2522%252C%255C%2522naType%255C%2522%253A%255C%2522%255C%2522%252C%255C%2522ivkSource%255C%2522%253A%255C%2522h5_schema%255C%2522%252C%255C%2522jumpType%255C%2522%253A%255C%2522xcx%255C%2522%252C%255C%2522jumpId%255C%2522%253A110%252C%255C%2522xcx_path%255C%2522%253A%255C%2522https%2525253A%2525252F%2525252Fwjrsbu.smartapps.cn%2525252Fzhihu%2525252Farticle%2525253Fid%2525253D445381875%255C%2522%252C%255C%2522xcx_id%255C%2522%253A%255C%2522oFx3nbdDN6GWF3Vb0Wh7EDBMBxRTTcfe%255C%2522%252C%255C%2522xcx_from%255C%2522%253A%255C%25221081000810003000%255C%2522%257D%2526lid%253D7541697109161095945%2526l%253D1%2526t%253Diphone%2526ref%253Dwww_iphone%2526from%253D1020786s%2526order%253D4%2526w%253D0_10_pytorch%25E6%2589%258B%25E5%2586%2599%25E4%25BD%2593%25E8%25AF%2586%25E5%2588%25AB%2526tj%253Dwww_normal_4_0_10_l%2526src%253Dhttps%2525253A%2525252F%2525252Fzhuanlan.zhihu.com%2525252Fp%2525252F445381875%2522%257D&useTpl=1&_swebfr=1&_swebFromHost=vivobrowser
参考资料2:
https://blog.csdn.net/weixin_43485035/article/details/115693919?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22115693919%22%2C%22source%22%3A%22weixin_46288319%22%7D&ctrtid=mbpWn
答:
(1)搭建环境(搭建pytorch环境过程在我前面博客有)
(2)代码运行结果
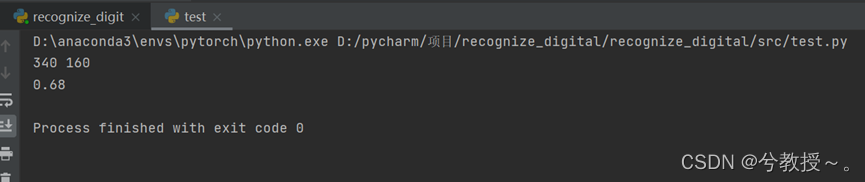
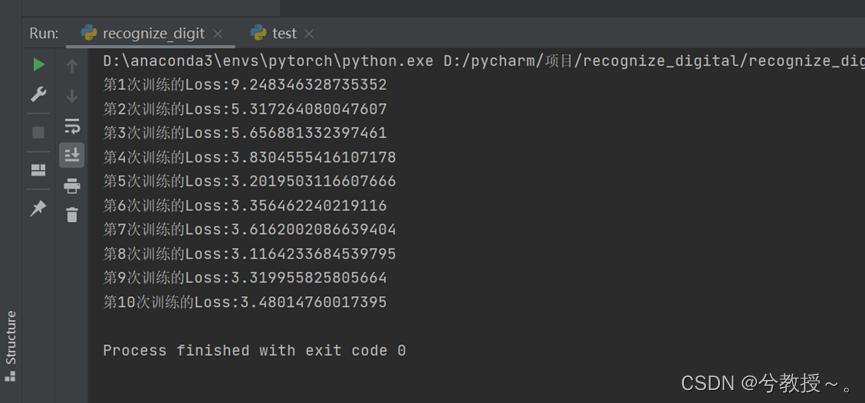















 4621
4621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









