






EDA
EDA全称是Exploratory Data Analysis,即探索性数据分析。
一开始我以为EDA是一个算法,但是查了一下资料发现,EDA是指对已有的数据在尽量少的先验假定下进行探索,通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法。
这没有一个固定的做法,按我的理解是,观察数据,然后通过统计让自己快速对数据熟悉起来,做到心中有数,然后可以对其中观察到的特点进行有针对性的建模
开始分析

这次比赛的数据我感觉相对简单,原始数据只有三列,除却id和label只有一列特征了。
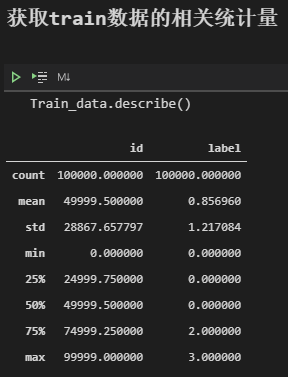
describe
教材里面写到用describe去统计一下train。emmm,这个操作应该算是比较常规的,但是我觉得不太适合我们这次比赛的数据,可以看到结果,因为heartbeat_signals是一个序列不是数值,所以不能继续计算平均值、方差这类的。
describe中能提出较为有用的信息就是:label为0这个类别占到了整个训练数据的一半有多。

info
info函数用来查看数据的类型,还有是否有空值。
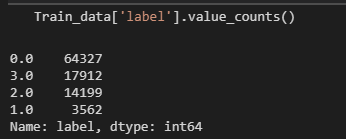
label类别的比例
这个就很重要了,这个是观察我们label类别的比例情况。
0类最多
1类最少
大致比例:0:1:2:3 = 21:1:5 :6
这里就要小心是否类别差异会影响模型的训练效果,会不会导致识别label_1会比较困难?
接着会引出问题:时序序列的数据如何做数据争强呢?
无界约翰逊分布
import scipy.stats as st
y = Train_data['label']
plt.figure(1); plt.title('Default')
sns.distplot(y, rug=True, bins=20)
plt.figure(2); plt.title('Normal')
sns.distplot(y, kde=False, fit=st.norm)
plt.figure(3); plt.title('Log Normal')
sns.distplot(y, kde=False, fit=st.lognorm)

说真的,没太看懂这3个图是什么意思,百度也比较缺少这些图的含义。我这能看出类别不均匀…
画出数据趋势图
我在想我们做的是心电信号的分析,那我们平时在电视剧看到的心电信号就是长这个样子:

那我们可不可以将heartbeat_signals可视化看看呢?
先看效果

这个是label为0的前一百条数据

这个是label为1的前一百条数据

这个是label为2的前一百条数据

这个是label为3的前一千条数据

这个是将4个label全部画在一起做了一些对比观察:
红色是label_0,黑色是label_1,蓝色是label_2,黄色是label_3
通过观察上面的所有图,每个label的特征其实是相对明显的,每个label都有自己独特的特征,时序信息的挖掘和提取我认为对这次的分类任务真的很重要,同时我觉得可以考虑一些关联规则。
代码
import pandas as pd
from pandas import DataFrame, Series
import matplotlib.pyplot as plt
Train_data = pd.read_csv('../data/train.csv')
def reduce_mem_usage(df):
start_mem = df.memory_usage().sum() / 1024**2
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
train = Train_data
train_list = []
for items in train.values:
train_list.append([items[0]] + [float(i) for i in items[1].split(',')] + [items[2]])#将数据以列表嵌套到列表中:[[],[],[]] +号代表着list拼接
train = pd.DataFrame(np.array(train_list))#数据转dataframe格式
train.columns = ['id'] + ['s_'+str(i) for i in range(len(train_list[0])-2)] + ['label']# s_第几个
train = reduce_mem_usage(train)
label_0 = train[train['label']==0]
x = list(train.columns[1:-1])
plt.figure(figsize=(25,5))
my_x_ticks = np.arange(0,len(x),5)#修改横坐标间距
plt.xticks(my_x_ticks,rotation=270)
for i in range(100):
y = list(label_0.iloc[i][1:-1])
plt.plot(x,y)
plt.show()
label_1 = train[train['label']==1]
x = list(train.columns[1:-1])
plt.figure(figsize=(25,5))
my_x_ticks = np.arange(0,len(x),5)#修改横坐标间距
plt.xticks(my_x_ticks,rotation=270)
for i in range(100):
y = list(label_1.iloc[i][1:-1])
plt.plot(x,y)
plt.show()
label_2 = train[train['label']==2]
x = list(train.columns[1:-1])
plt.figure(figsize=(25,5))
my_x_ticks = np.arange(0,len(x),5)#修改横坐标间距
plt.xticks(my_x_ticks,rotation=270)
for i in range(100):
y = list(label_2.iloc[i][1:-1])
plt.plot(x,y)
plt.show()
label_3 = train[train['label']==3]
x = list(train.columns[1:-1])
plt.figure(figsize=(25,5))
my_x_ticks = np.arange(0,len(x),5)#修改横坐标间距
plt.xticks(my_x_ticks,rotation=270)
for i in range(1000):
y = list(label_3.iloc[i][1:-1])
plt.plot(x,y)
plt.show()
# 4个label画在一起
x = list(train.columns[1:-1])
plt.figure(figsize=(25,5))
my_x_ticks = np.arange(0,len(x),5)#修改横坐标间距
plt.xticks(my_x_ticks,rotation=270)
for i in range(1000):
if(train.iloc[i][-1]==0):
y = list(train.iloc[i][1:-1])
plt.plot(x,y,color='r',)
if(train.iloc[i][-1]==1):
y = list(train.iloc[i][1:-1])
plt.plot(x,y,color='black')
if(train.iloc[i][-1]==2):
y = list(train.iloc[i][1:-1])
plt.plot(x,y,color='b')
if(train.iloc[i][-1]==3):
y = list(train.iloc[i][1:-1])
plt.plot(x,y,color='y')
plt.show()















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









